Recognition: 2 theorem links
· Lean TheoremWhat Matters for Diffusion-Friendly Latent Manifold? Prior-Aligned Autoencoders for Latent Diffusion
Pith reviewed 2026-05-11 01:53 UTC · model grok-4.3
The pith
Shaping the latent manifold with explicit priors creates spaces that let diffusion models train faster and generate higher-quality images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a diffusion-friendly latent manifold requires coherent spatial structure, local manifold continuity, and global manifold semantics, and that these properties can be turned into explicit training goals rather than left to emerge indirectly; the Prior-Aligned AutoEncoder achieves this by aligning latents to refined priors from visual foundation models and applying perturbation-based regularization, resulting in faster convergence and higher generation quality for latent diffusion models.
What carries the argument
The Prior-Aligned AutoEncoder (PAE), which converts the three manifold properties into direct training objectives by using refined priors from visual foundation models together with perturbation-based regularization.
If this is right
- Tokenizers built around the three manifold properties reach performance comparable to existing strong baselines while converging up to 13 times faster under identical training conditions.
- Generation quality on ImageNet 256x256 improves to a new state-of-the-art gFID of 1.03.
- Reconstruction accuracy becomes a weaker predictor of downstream diffusion success than the organization of the latent manifold.
- Explicitly shaping the latent space outperforms approaches that rely only on reconstruction or inherited pretrained representations.
Where Pith is reading between the lines
- The same three properties could be added as regularizers to other latent encoders even without access to visual foundation model priors.
- These manifold requirements may extend to latent spaces used by autoregressive or other non-diffusion generators.
- Testing the properties at different image resolutions or on non-ImageNet datasets would show whether they are general or tied to the current training scale.
Load-bearing premise
The three manifold properties are the main cause of the observed gains in speed and quality rather than other unmeasured differences in tokenizer design or training details.
What would settle it
A controlled tokenizer variant that lacks one or more of the three properties but still reaches the same generation quality and training speed as PAE, or an experiment where enforcing the properties produces no measurable improvement in diffusion results.
Figures
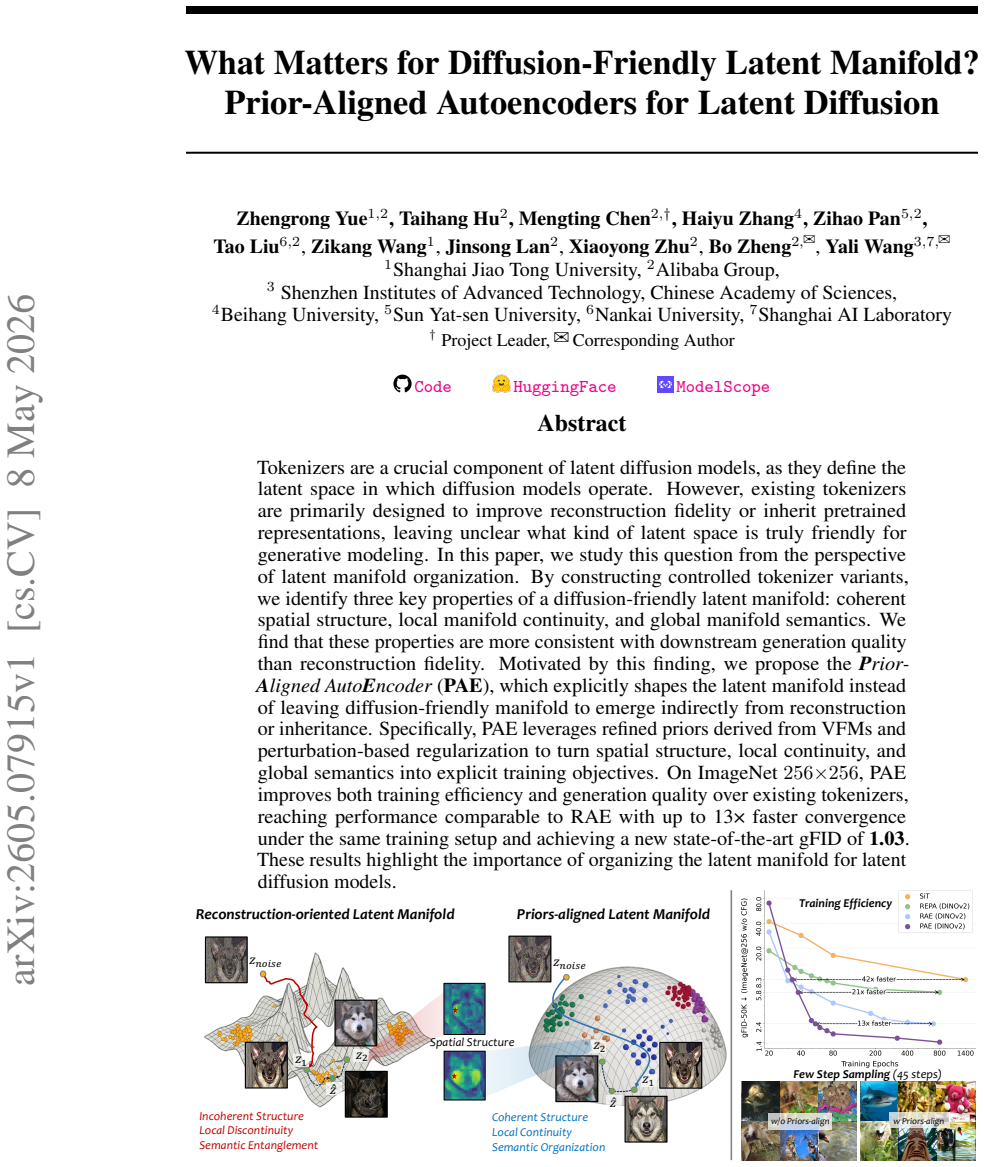


































read the original abstract
Tokenizers are a crucial component of latent diffusion models, as they define the latent space in which diffusion models operate. However, existing tokenizers are primarily designed to improve reconstruction fidelity or inherit pretrained representations, leaving unclear what kind of latent space is truly friendly for generative modeling. In this paper, we study this question from the perspective of latent manifold organization. By constructing controlled tokenizer variants, we identify three key properties of a diffusion-friendly latent manifold: coherent spatial structure, local manifold continuity, and global manifold semantics. We find that these properties are more consistent with downstream generation quality than reconstruction fidelity. Motivated by this finding, we propose the Prior-Aligned AutoEncoder (PAE), which explicitly shapes the latent manifold instead of leaving diffusion-friendly manifold to emerge indirectly from reconstruction or inheritance. Specifically, PAE leverages refined priors derived from VFMs and perturbation-based regularization to turn spatial structure, local continuity, and global semantics into explicit training objectives. On ImageNet 256x256, PAE improves both training efficiency and generation quality over existing tokenizers, reaching performance comparable to RAE with up to 13x faster convergence under the same training setup and achieving a new state-of-the-art gFID of 1.03. These results highlight the importance of organizing the latent manifold for latent diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that controlled tokenizer variants reveal three key properties of a diffusion-friendly latent manifold—coherent spatial structure, local manifold continuity, and global manifold semantics—that correlate more strongly with downstream generation quality than reconstruction fidelity. It proposes the Prior-Aligned AutoEncoder (PAE), which explicitly enforces these properties via refined VFM-derived priors and perturbation-based regularization, yielding up to 13x faster convergence and a new SOTA gFID of 1.03 on ImageNet 256x256 compared to prior tokenizers.
Significance. If the causal role of the identified manifold properties holds, the work offers a principled approach to tokenizer design for latent diffusion models that prioritizes manifold organization over indirect emergence from reconstruction objectives, with potential to improve training efficiency and sample quality across generative tasks.
major comments (2)
- [Controlled tokenizer variants and PAE training objectives] The section on controlled tokenizer variants and PAE objectives does not report ablations that hold perturbation regularization fixed while ablating or randomizing the VFM priors (or vice versa). This leaves open the possibility that performance gains are driven primarily by prior quality rather than the three manifold properties, undermining the claim that these properties are the primary causal drivers of improved generation quality.
- [ImageNet 256x256 experiments] The experiments reporting 13x faster convergence and gFID 1.03 provide no details on the number of independent runs, statistical significance, variance across seeds, or exact hyperparameter matching with baselines such as RAE. Without these, the robustness of the efficiency and SOTA claims cannot be fully assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the positive assessment of the work's potential impact. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Controlled tokenizer variants and PAE training objectives] The section on controlled tokenizer variants and PAE objectives does not report ablations that hold perturbation regularization fixed while ablating or randomizing the VFM priors (or vice versa). This leaves open the possibility that performance gains are driven primarily by prior quality rather than the three manifold properties, undermining the claim that these properties are the primary causal drivers of improved generation quality.
Authors: We appreciate this observation. Our controlled tokenizer variants were designed to probe the three manifold properties by systematically varying tokenizer components, and the PAE objectives explicitly target those properties through VFM-derived priors and perturbation regularization. However, we agree that the suggested cross-ablations (holding one component fixed while randomizing the other) would more rigorously isolate their individual contributions and strengthen the causal argument. In the revised manuscript, we will add these experiments, including results with randomized VFM priors under fixed regularization and vice versa. revision: yes
-
Referee: [ImageNet 256x256 experiments] The experiments reporting 13x faster convergence and gFID 1.03 provide no details on the number of independent runs, statistical significance, variance across seeds, or exact hyperparameter matching with baselines such as RAE. Without these, the robustness of the efficiency and SOTA claims cannot be fully assessed.
Authors: We acknowledge that the current manuscript lacks these experimental details. In the revision, we will report the number of independent runs performed, include variance across seeds, discuss statistical significance of the observed improvements, and explicitly confirm that all baselines (including RAE) were trained under identical hyperparameter settings and data pipelines as our PAE models. These additions will allow readers to better evaluate the reliability of the efficiency and quality gains. revision: yes
Circularity Check
No significant circularity; derivation is empirically grounded
full rationale
The paper first constructs controlled tokenizer variants to empirically identify the three manifold properties (coherent spatial structure, local continuity, global semantics) and observes their correlation with generation quality versus reconstruction fidelity. This identification step is independent of the subsequent PAE design. PAE then adopts these properties as motivation for explicit regularizers (VFM-derived priors plus perturbation regularization), with all performance claims (13x convergence, gFID 1.03) presented as experimental results on ImageNet rather than reductions by construction. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain. The overall argument remains self-contained with separate empirical support.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coherent spatial structure, local manifold continuity, and global manifold semantics are the primary properties that make a latent space diffusion-friendly.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By constructing controlled tokenizer variants, we identify three key properties of a diffusion-friendly latent manifold: coherent spatial structure, local manifold continuity, and global manifold semantics.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PAE leverages refined priors derived from VFMs and perturbation-based regularization to turn spatial structure, local continuity, and global semantics into explicit training objectives.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Latent forcing: Reordering the diffusion trajectory for pixel-space image generation
Alan Baade, Eric Ryan Chan, Kyle Sargent, Changan Chen, Justin Johnson, Ehsan Adeli, and Li Fei-Fei. Latent forcing: Reordering the diffusion trajectory for pixel-space image generation, 2026. URLhttps://arxiv.org/abs/2602.11401
-
[2]
Flextok: Resampling images into 1d token sequences of flexible length, 2025
Roman Bachmann, Jesse Allardice, David Mizrahi, Enrico Fini, O˘guzhan Fatih Kar, Elmira Amirloo, Alaaeldin El-Nouby, Amir Zamir, and Afshin Dehghan. Flextok: Resampling images into 1d token sequences of flexible length, 2025. URL https://arxiv.org/abs/2502. 13967
work page 2025
-
[3]
Beit: Bert pre-training of image transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers. InInternational Conference on Learning Representations
-
[4]
VFM-VAE: Vision Foundation Models Can Be Good Tokenizers for Latent Diffusion Models
Tianci Bi, Xiaoyi Zhang, Yan Lu, and Nanning Zheng. Vision foundation models can be good tokenizers for latent diffusion models.arXiv preprint arXiv:2510.18457, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Laminating representation autoencoders for efficient diffusion, 2026
Ramón Calvo-González and François Fleuret. Laminating representation autoencoders for efficient diffusion, 2026. URLhttps://arxiv.org/abs/2602.04873
-
[6]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[7]
Dino-sae: Dino spherical autoencoder for high-fidelity image reconstruction and generation, 2026
Hun Chang, Byunghee Cha, and Jong Chul Ye. Dino-sae: Dino spherical autoencoder for high-fidelity image reconstruction and generation, 2026. URL https://arxiv.org/abs/ 2601.22904
work page internal anchor Pith review arXiv 2026
-
[8]
Videojam: Joint appearance-motion representations for enhanced motion generation in video models
Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, and Shelly Sheynin. Videojam: Joint appearance-motion representations for enhanced motion generation in video models. InForty-second International Conference on Machine Learning
-
[9]
Aligning visual foundation encoders to tokenizers for diffusion models
Bowei Chen, Sai Bi, Hao Tan, He Zhang, Tianyuan Zhang, Zhengqi Li, Yuanjun Xiong, Jianming Zhang, and Kai Zhang. Aligntok: Aligning visual foundation encoders to tokenizers for diffusion models, 2026. URLhttps://arxiv.org/abs/2509.25162
-
[10]
Masked autoencoders are effective tokenizers for diffusion models.ArXiv, abs/2502.03444, 2025
Hao Chen, Yujin Han, Fangyi Chen, Xiang Li, Yidong Wang, Jindong Wang, Ze Wang, Zicheng Liu, Difan Zou, and Bhiksha Raj. Masked autoencoders are effective tokenizers for diffusion models, 2025. URLhttps://arxiv.org/abs/2502.03444
-
[11]
Vitamin: Designing scalable vision models in the vision-language era
Jieneng Chen, Qihang Yu, Xiaohui Shen, Alan Yuille, and Liang-Chieh Chen. Vitamin: Designing scalable vision models in the vision-language era. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12954–12966, 2024
work page 2024
-
[12]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025. 10
work page Pith review arXiv 2025
-
[13]
Junyu Chen, Han Cai, Junsong Chen, Enze Xie, Shang Yang, Haotian Tang, Muyang Li, Yao Lu, and Song Han. Deep compression autoencoder for efficient high-resolution diffusion models, 2025. URLhttps://arxiv.org/abs/2410.10733
-
[14]
Dc-ae 1.5: Accelerating diffusion model convergence with structured latent space, 2025
Junyu Chen, Dongyun Zou, Wenkun He, Junsong Chen, Enze Xie, Song Han, and Han Cai. Dc-ae 1.5: Accelerating diffusion model convergence with structured latent space, 2025. URL https://arxiv.org/abs/2508.00413
-
[15]
Vision Transformers Need Registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers.arXiv preprint arXiv:2309.16588, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[17]
Repack then refine: Efficient diffusion transformer with vision foundation model, 2026
Guanfang Dong, Luke Schultz, Negar Hassanpour, and Chao Gao. Repack then refine: Efficient diffusion transformer with vision foundation model, 2026. URL https://arxiv.org/abs/ 2512.12083
work page internal anchor Pith review arXiv 2026
-
[18]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[19]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
work page 2021
- [20]
-
[21]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
work page 2024
-
[22]
The prism hypothesis: Harmonizing semantic and pixel representations via unified autoencoding
Weichen Fan, Haiwen Diao, Quan Wang, Dahua Lin, and Ziwei Liu. The prism hypothesis: Harmonizing semantic and pixel representations via unified autoencoding, 2026. URL https: //arxiv.org/abs/2512.19693
-
[23]
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. Datacomp: In search of the next generation of multimodal datasets.Advances in Neural Information Processing Systems, 36:27092–27112, 2023
work page 2023
-
[24]
Yuan Gao, Chen Chen, Tianrong Chen, and Jiatao Gu. One layer is enough: Adapting pretrained visual encoders for image generation, 2025. URL https://arxiv.org/abs/ 2512.07829
-
[25]
Yue Gong, Hongyu Li, Shanyuan Liu, Bo Cheng, Yuhang Ma, Liebucha Wu, Xiaoyu Wu, Manyuan Zhang, Dawei Leng, Yuhui Yin, and Lijun Zhang. Rpiae: A representation-pivoted autoencoder enhancing both image generation and editing, 2026. URL https://arxiv.org/ abs/2603.19206
-
[26]
Adapting Self-Supervised Representations as a Latent Space for Efficient Generation
Ming Gui, Johannes Schusterbauer, Timy Phan, Felix Krause, Josh Susskind, Miguel Angel Bautista, and Björn Ommer. Adapting self-supervised representations as a latent space for efficient generation, 2026. URLhttps://arxiv.org/abs/2510.14630
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Philippe Hansen-Estruch, David Yan, Ching-Yao Chung, Orr Zohar, Jialiang Wang, Tingbo Hou, Tao Xu, Sriram Vishwanath, Peter Vajda, and Xinlei Chen. Learnings from scaling visual tokenizers for reconstruction and generation.arXiv preprint arXiv:2501.09755, 2025
-
[28]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 11
work page 2016
-
[29]
Masked autoencoders are scalable vision learners, 2021
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners, 2021. URL https://arxiv.org/abs/2111. 06377
work page 2021
-
[31]
arXiv preprint arXiv:2602.17270 (2026)
Jonathan Heek, Emiel Hoogeboom, Thomas Mensink, and Tim Salimans. Unified latents (ul): How to train your latents, 2026. URLhttps://arxiv.org/abs/2602.17270
-
[32]
Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. Query-key normal- ization for transformers.arXiv preprint arXiv:2010.04245, 2020
-
[33]
Reducing the dimensionality of data with neural networks
Geoffrey Hinton and Ruslan Salakhutdinov. Reducing the dimensionality of data with neural networks. 2006. URL10.1126/science.1127647
work page 2006
-
[34]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis.arXiv preprint arXiv:2405.07987, 2024
work page Pith review arXiv 2024
-
[35]
Ahmed Imtiaz Humayun, Ibtihel Amara, Cristina Vasconcelos, Deepak Ramachandran, Can- dice Schumann, Junfeng He, Katherine Heller, Golnoosh Farnadi, Negar Rostamzadeh, and Mohammad Havaei. What secrets do your manifolds hold? understanding the local geometry of generative models.arXiv preprint arXiv:2408.08307, 2024
-
[36]
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Openclip, July 2021. Computer software. An open-source implementation of CLIP
work page 2021
-
[37]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks, 2019. URLhttps://arxiv.org/abs/1812.04948
-
[38]
Guiding a diffusion model with a bad version of itself, 2024
Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself, 2024. URL https://arxiv. org/abs/2406.02507
-
[40]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes, 2022. URL https: //arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Theodoros Kouzelis, Ioannis Kakogeorgiou, Spyros Gidaris, and Nikos Komodakis. Eq-vae: Equivariance regularized latent space for improved generative image modeling, 2025. URL https://arxiv.org/abs/2502.09509
-
[43]
Theodoros Kouzelis, Efstathios Karypidis, Ioannis Kakogeorgiou, Spyros Gidaris, and Nikos Komodakis. Boosting generative image modeling via joint image-feature synthesis.arXiv preprint arXiv:2504.16064, 2025
-
[44]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
work page 2012
-
[45]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[46]
Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers, 2025
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers.arXiv preprint arXiv:2504.10483, 2025. 12
-
[47]
Imagefolder: Autoregressive image gen- eration with folded tokens.arXiv preprint arXiv:2410.01756,
Xiang Li, Kai Qiu, Hao Chen, Jason Kuen, Jiuxiang Gu, Bhiksha Raj, and Zhe Lin. Image- folder: Autoregressive image generation with folded tokens.arXiv preprint arXiv:2410.01756, 2024
-
[48]
Exploring plain vision transformer backbones for object detection
Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object detection. InEuropean conference on computer vision, pages 280–296. Springer, 2022
work page 2022
-
[49]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[50]
Geometric autoencoder for diffusion models,
Hangyu Liu, Jianyong Wang, and Yutao Sun. Geometric autoencoder for diffusion models,
- [51]
-
[52]
Shizhan Liu, Xinran Deng, Zhuoyi Yang, Jiayan Teng, Xiaotao Gu, and Jie Tang. Delving into latent spectral biasing of video vaes for superior diffusability, 2025. URL https://arxiv. org/abs/2512.05394
-
[53]
Improving reconstruction of representation autoencoder, 2026
Siyu Liu, Chujie Qin, Hubery Yin, Qixin Yan, Zheng-Peng Duan, Chen Li, Jing Lyu, Chun-Le Guo, and Chongyi Li. Improving reconstruction of representation autoencoder, 2026. URL https://arxiv.org/abs/2602.08620
-
[54]
Gabriel Loaiza-Ganem, Brendan Leigh Ross, Rasa Hosseinzadeh, Anthony L Caterini, and Jesse C Cresswell. Deep generative models through the lens of the manifold hypothesis: A survey and new connections.arXiv preprint arXiv:2404.02954, 2024
-
[55]
arXiv preprint arXiv:2502.20321 (2025) 9
Chuofan Ma, Yi Jiang, Junfeng Wu, Jihan Yang, Xin Yu, Zehuan Yuan, Bingyue Peng, and Xiaojuan Qi. Unitok: A unified tokenizer for visual generation and understanding, 2025. URL https://arxiv.org/abs/2502.20321
-
[56]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Computer Vision, pages 23–40. Springer, 2024
work page 2024
-
[57]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Boosting latent diffusion models via disentangled representation alignment, 2026
John Page, Xuesong Niu, Kai Wu, and Kun Gai. Boosting latent diffusion models via disentangled representation alignment, 2026. URL https://arxiv.org/abs/2601.05823
-
[59]
Yueming Pan, Ruoyu Feng, Qi Dai, Yuqi Wang, Wenfeng Lin, Mingyu Guo, Chong Luo, and Nanning Zheng. Semantics lead the way: Harmonizing semantic and texture modeling with asynchronous latent diffusion.arXiv preprint arXiv:2512.04926, 2025
-
[60]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[61]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Du, Zehuan Yuan, and Xinglong Wu
Liao Qu, Huichao Zhang, Yiheng Liu, Xu Wang, Yi Jiang, Yiming Gao, Hu Ye, Daniel K. Du, Zehuan Yuan, and Xinglong Wu. Tokenflow: Unified image tokenizer for multimodal understanding and generation, 2025. URLhttps://arxiv.org/abs/2412.03069
-
[63]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 13
work page 2021
-
[64]
When worse is better: Navigating the compression-generation tradeoff in visual tokenization,
Vivek Ramanujan, Kushal Tirumala, Armen Aghajanyan, Luke Zettlemoyer, and Ali Farhadi. When worse is better: Navigating the compression-generation tradeoff in visual tokenization,
- [65]
-
[66]
Generating diverse high-fidelity images with VQ-V AE-2.arXiv:1906.00446, 2019
Ali Razavi, Aaron van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2, 2019. URLhttps://arxiv.org/abs/1906.00446
-
[67]
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
work page 2015
-
[68]
Published as a conference paper at ICLR
Severi Rissanen, Markus Heinonen, and Arno Solin. Generative modelling with inverse heat dissipation, 2023. URLhttps://arxiv.org/abs/2206.13397
-
[69]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[70]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs.arXiv preprint arXiv:2111.02114, 2021
work page internal anchor Pith review arXiv 2021
-
[71]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[72]
Cat: Content-adaptive image tokenization, 2025
Junhong Shen, Kushal Tirumala, Michihiro Yasunaga, Ishan Misra, Luke Zettlemoyer, Lili Yu, and Chunting Zhou. Cat: Content-adaptive image tokenization, 2025. URL https: //arxiv.org/abs/2501.03120
-
[73]
Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301, 2025
Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and Jiwen Lu. Latent diffusion model without variational autoencoder, 2025. URLhttps://arxiv.org/abs/2510.15301
-
[74]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Jaskirat Singh, Xingjian Leng, Zongze Wu, Liang Zheng, Richard Zhang, Eli Shechtman, and Saining Xie. What matters for representation alignment: Global information or spatial structure?arXiv preprint arXiv:2512.10794, 2025
-
[76]
Improving the diffusability of autoencoders.arXiv preprint arXiv:2502.14831, 2025
Ivan Skorokhodov, Sharath Girish, Benran Hu, Willi Menapace, Yanyu Li, Rameen Abdal, Sergey Tulyakov, and Aliaksandr Siarohin. Improving the diffusability of autoencoders, 2025. URLhttps://arxiv.org/abs/2502.14831
-
[77]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[78]
arXiv preprint arXiv:2507.23278 , year=
Hao Tang, Chenwei Xie, Xiaoyi Bao, Tingyu Weng, Pandeng Li, Yun Zheng, and Liwei Wang. Unilip: Adapting clip for unified multimodal understanding, generation and editing, 2026. URLhttps://arxiv.org/abs/2507.23278
-
[79]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale. arXiv preprint arXiv:2505.13211, 2025
work page internal anchor Pith review arXiv 2025
-
[80]
arXiv preprint arXiv:2601.16208 (2026),https://arxiv.org/abs/2601.16208
Shengbang Tong, Boyang Zheng, Ziteng Wang, Bingda Tang, Nanye Ma, Ellis Brown, Jihan Yang, Rob Fergus, Yann LeCun, and Saining Xie. Scaling text-to-image diffusion transformers with representation autoencoders, 2026. URLhttps://arxiv.org/abs/2601.16208. 14
-
[81]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[82]
A tutorial on spectral clustering, 2007
Ulrike von Luxburg. A tutorial on spectral clustering, 2007. URL https://arxiv.org/ abs/0711.0189
-
[83]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.