Scalable Unseen Objects 6-DoF Absolute Pose Estimation with Robotic Integration
Pith reviewed 2026-05-23 00:13 UTC · model grok-4.3
The pith
A single pose-labeled RGB-D reference image enables 6-DoF absolute pose estimation for unseen objects after synthetic pre-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SinRef-6D shows that iterative object-space point-wise alignment driven by Point SSM and RGB SSM backbones, after pre-training on synthetic data, produces accurate 6-DoF absolute poses for unseen objects from one pose-labeled reference RGB-D image despite large discrepancies between views.
What carries the argument
Iterative object-space point-wise alignment that uses Point and RGB state space models to capture long-range spatial dependencies from a single view.
Load-bearing premise
One reference RGB-D image supplies enough geometric and spatial detail for reliable iterative alignment even when the query view differs substantially in pose.
What would settle it
Measure whether estimation error rises sharply on test pairs whose relative rotation exceeds 90 degrees or whose translation distance exceeds half the object diameter.
Figures









read the original abstract
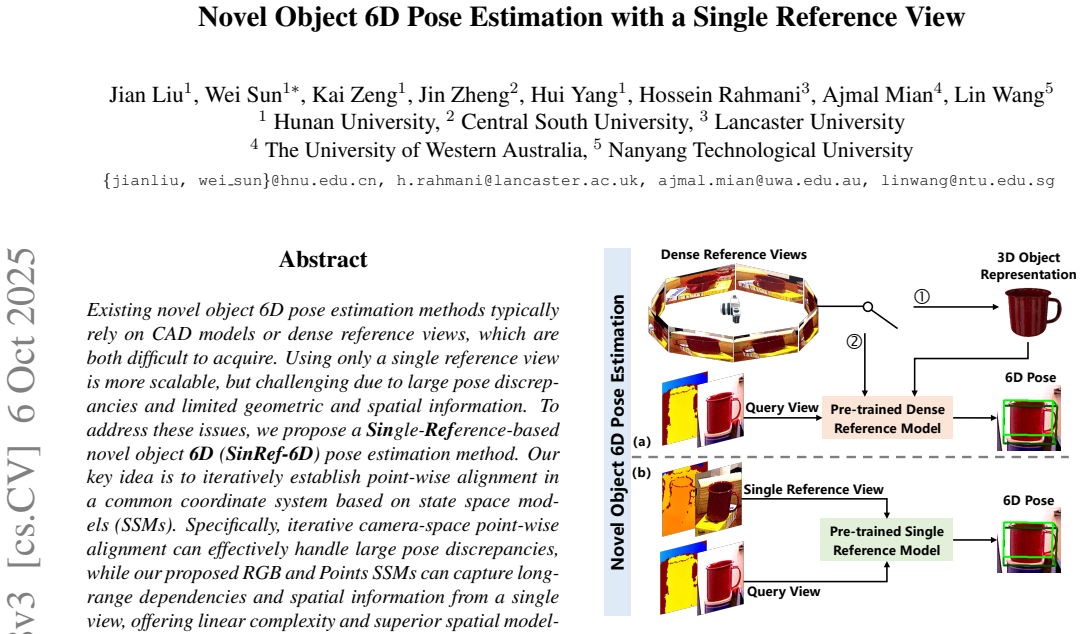
Pose estimation-guided unseen object 6-DoF robotic manipulation is a key task in robotics. However, the scalability of current pose estimation methods to unseen objects remains a fundamental challenge, as they generally rely on CAD models or dense reference views of unseen objects, which are difficult to acquire, ultimately limit their scalability. In this paper, we introduce a novel task setup, referred to as SinRef-6D, which addresses 6-DoF absolute pose estimation for unseen objects using only a single pose-labeled reference RGB-D image captured during robotic manipulation. This setup is more scalable yet technically nontrivial due to large pose discrepancies and the limited geometric and spatial information contained in a single view. To address these issues, our key idea is to iteratively establish point-wise alignment in a common coordinate system with state space models (SSMs) as backbones. Specifically, to handle large pose discrepancies, we introduce an iterative object-space point-wise alignment strategy. Then, Point and RGB SSMs are proposed to capture long-range spatial dependencies from a single view, offering superior spatial modeling capability with linear complexity. Once pre-trained on synthetic data, SinRef-6D can estimate the 6-DoF absolute pose of an unseen object using only a single reference view. With the estimated pose, we further develop a hardware-software robotic system and integrate the proposed SinRef-6D into it in real-world settings. Extensive experiments on six benchmarks and in diverse real-world scenarios demonstrate that our SinRef-6D offers superior scalability. Additional robotic grasping experiments further validate the effectiveness of the developed robotic system. The code and robotic demos are available at https://paperreview99.github.io/SinRef-6DoF-Robotic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SinRef-6D, a method for 6-DoF absolute pose estimation of unseen objects that requires only a single pose-labeled reference RGB-D image. It proposes an iterative object-space point-wise alignment strategy using Point and RGB state space models (SSMs) as backbones to capture long-range dependencies with linear complexity, pre-trains on synthetic data, and integrates the estimator into a hardware-software robotic manipulation system. Claims of superior scalability are supported by experiments on six benchmarks plus real-world robotic grasping scenarios, with code and demos released.
Significance. If the central claims hold, the work would meaningfully advance scalable unseen-object pose estimation for robotics by eliminating the need for CAD models or dense multi-view references. The open release of code and robotic demos is a clear strength that supports reproducibility. The significance is reduced, however, by the absence of any quantitative results, ablations, or convergence analysis that would allow verification of whether the SSM components actually enable reliable alignment from a single incomplete view.
major comments (2)
- [Method (iterative object-space alignment and SSM construction)] The central claim (abstract) that a single reference RGB-D view suffices for accurate 6-DoF estimation after synthetic pre-training rests on the untested assumption that Point/RGB SSMs recover missing geometry and prevent drift under large pose gaps; no section supplies a convergence analysis, regularization for self-occlusions, or empirical test of this assumption despite it being load-bearing for the iterative alignment strategy.
- [Experiments] The experiments section asserts superior performance on six benchmarks and real-world scenarios, yet the manuscript provides no quantitative tables, error metrics, ablation studies, or baseline comparisons; without these, the scalability claim cannot be evaluated and the soundness assessment remains limited to the abstract.
minor comments (2)
- [Method] Notation for the Point SSM and RGB SSM is introduced without an explicit equation defining their state-space recurrence or complexity; adding this would improve clarity.
- [Robotic System] The robotic integration description would benefit from a diagram showing the data flow between the pose estimator and the manipulation controller.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important aspects of the method assumptions and experimental presentation that we will address in the revision to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Method (iterative object-space alignment and SSM construction)] The central claim (abstract) that a single reference RGB-D view suffices for accurate 6-DoF estimation after synthetic pre-training rests on the untested assumption that Point/RGB SSMs recover missing geometry and prevent drift under large pose gaps; no section supplies a convergence analysis, regularization for self-occlusions, or empirical test of this assumption despite it being load-bearing for the iterative alignment strategy.
Authors: We agree that the manuscript would benefit from more explicit verification of the iterative alignment's behavior. The design relies on progressive refinement in object space to bridge large pose gaps, with SSMs providing linear-complexity long-range modeling to compensate for single-view incompleteness. In the revised version we will add a dedicated analysis subsection that includes: (i) convergence plots of pose error versus iteration count on held-out synthetic sequences, (ii) an empirical study measuring performance degradation as initial pose discrepancy increases, and (iii) qualitative and quantitative discussion of how the state-space recurrence implicitly regularizes self-occluded regions. These additions will directly test the load-bearing assumption. revision: yes
-
Referee: [Experiments] The experiments section asserts superior performance on six benchmarks and real-world scenarios, yet the manuscript provides no quantitative tables, error metrics, ablation studies, or baseline comparisons; without these, the scalability claim cannot be evaluated and the soundness assessment remains limited to the abstract.
Authors: We acknowledge that the current manuscript version does not contain the quantitative tables, error metrics, ablation studies, or baseline comparisons needed to substantiate the scalability claims. In the revision we will expand Section 4 with: full tables reporting ADD, ADD-S, rotation and translation errors on all six benchmarks together with comparisons to relevant baselines; ablation tables isolating the iterative alignment and the Point/RGB SSM components; and quantitative success rates for the real-world robotic grasping trials. All metrics and statistical details will be presented clearly so that the experimental support for the claims can be directly assessed. revision: yes
Circularity Check
No significant circularity; claims rest on pre-training and external benchmarks
full rationale
The paper describes pre-training on synthetic data then applying the model to real unseen objects with a single reference RGB-D view, using iterative point-wise alignment via Point/RGB SSMs. No equations, fitted parameters, or self-citations are shown that reduce any central prediction (e.g., pose output) to an input quantity by construction. Performance is reported against six external benchmarks and real-world robotic scenarios, making the derivation self-contained rather than tautological. This matches the default case of a normal, non-circular paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
OneViewAll: Semantic Prior Guided One-View 6D Pose Estimation for Novel Objects
OneViewAll achieves 92.5% ADD-0.1 accuracy on LINEMOD for novel object 6D pose estimation using only one real reference view by integrating category, symmetry, and patch-level semantic priors in a projection-equivaria...
Reference graph
Works this paper leans on
-
[1]
Learning 6d object pose estimation using 3d object coordinates
Eric Brachmann, Alexander Krull, Frank Michel, Stefan Gumhold, Jamie Shotton, and Carsten Rother. Learning 6d object pose estimation using 3d object coordinates. InEuro- pean Conference on Computer Vision, pages 536–551, 2014. 5, 7, 9, 2, 3
work page 2014
-
[2]
Gs-pose: Cas- caded framework for generalizable segmentation-based 6d object pose estimation
Dingding Cai, Janne Heikkil ¨a, and Esa Rahtu. Gs-pose: Cas- caded framework for generalizable segmentation-based 6d object pose estimation. InInternational Conference on 3D Vision, 2025. 3
work page 2025
-
[3]
Dgecn: A depth-guided edge convolutional network for end-to-end 6d pose estimation
Tuo Cao, Fei Luo, Yanping Fu, Wenxiao Zhang, Shengjie Zheng, and Chunxia Xiao. Dgecn: A depth-guided edge convolutional network for end-to-end 6d pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 3783–3792, 2022. 1
work page 2022
-
[4]
Freeze: Training-free zero-shot 6d pose estimation with geometric and vision foundation models
Andrea Caraffa, Davide Boscaini, Amir Hamza, and Fabio Poiesi. Freeze: Training-free zero-shot 6d pose estimation with geometric and vision foundation models. InEuropean Conference on Computer Vision, 2024. 2
work page 2024
-
[5]
Posematcher: One-shot 6d object pose estimation by deep feature matching
Pedro Castro and Tae-Kyun Kim. Posematcher: One-shot 6d object pose estimation by deep feature matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2148–2157, 2023. 2
work page 2023
-
[6]
Zeropose: Cad-model-based zero-shot pose estimation.arXiv preprint arXiv:2305.17934,
Jianqiu Chen, Mingshan Sun, Tianpeng Bao, Rui Zhao, Li- wei Wu, and Zhenyu He. Zeropose: Cad-model-based zero-shot pose estimation.arXiv preprint arXiv:2305.17934,
-
[7]
Sim-to-real 6d object pose estimation via iterative self-training for robotic bin picking
Kai Chen, Rui Cao, Stephen James, Yichuan Li, Yun-Hui Liu, Pieter Abbeel, and Qi Dou. Sim-to-real 6d object pose estimation via iterative self-training for robotic bin picking. InEuropean Conference on Computer Vision, pages 533– 550, 2022. 1
work page 2022
-
[8]
Secondpose: Se (3)- consistent dual-stream feature fusion for category-level pose estimation
Yamei Chen, Yan Di, Guangyao Zhai, Fabian Manhardt, Chenyangguang Zhang, Ruida Zhang, Federico Tombari, Nassir Navab, and Benjamin Busam. Secondpose: Se (3)- consistent dual-stream feature fusion for category-level pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9959– 9969, 2024. 1
work page 2024
-
[9]
Open-vocabulary object 6d pose estimation
Jaime Corsetti, Davide Boscaini, Changjae Oh, Andrea Cav- allaro, and Fabio Poiesi. Open-vocabulary object 6d pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18071– 18080, 2024. 1
work page 2024
-
[10]
Zheng Dang, Lizhou Wang, Yu Guo, and Mathieu Salzmann. Match normalization: Learning-based point cloud registra- tion for 6d object pose estimation in the real world.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(06):4489–4503, 2024. 1
work page 2024
-
[11]
So-pose: Exploiting self- occlusion for direct 6d pose estimation
Yan Di, Fabian Manhardt, Gu Wang, Xiangyang Ji, Nassir Navab, and Federico Tombari. So-pose: Exploiting self- occlusion for direct 6d pose estimation. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 12396–12405, 2021. 1
work page 2021
-
[12]
Gpv-pose: Category-level object pose estimation via geometry-guided point-wise voting
Yan Di, Ruida Zhang, Zhiqiang Lou, Fabian Manhardt, Xi- angyang Ji, Nassir Navab, and Federico Tombari. Gpv-pose: Category-level object pose estimation via geometry-guided point-wise voting. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6781–6791, 2022. 1
work page 2022
-
[13]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021. 8
work page 2021
-
[14]
Recovering 6d object pose and predicting next-best-view in the crowd
Andreas Doumanoglou, Rigas Kouskouridas, Sotiris Malas- siotis, and Tae-Kyun Kim. Recovering 6d object pose and predicting next-best-view in the crowd. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3583–3592, 2016. 5, 7, 2, 4
work page 2016
-
[15]
Introducing mvtec itodd-a dataset for 3d object recognition in industry
Bertram Drost, Markus Ulrich, Paul Bergmann, Philipp Hartinger, and Carsten Steger. Introducing mvtec itodd-a dataset for 3d object recognition in industry. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion Workshops, pages 2200–2208. 8
-
[16]
Pizza: A powerful image-only zero-shot zero- cad approach to 6 dof tracking
Yuming Du, Yang Xiao, Michael Ramamonjisoa, Vincent Lepetit, et al. Pizza: A powerful image-only zero-shot zero- cad approach to 6 dof tracking. InInternational Conference on 3D Vision, pages 515–525, 2022. 3
work page 2022
-
[17]
Pope: 6-dof promptable pose estimation of any object in any scene with one reference
Zhiwen Fan, Panwang Pan, Peihao Wang, Yifan Jiang, De- jia Xu, and Zhangyang Wang. Pope: 6-dof promptable pose estimation of any object in any scene with one reference. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 7771–7781, 2024. 1
work page 2024
-
[18]
6d robotic assembly based on rgb-only object pose esti- mation
Bowen Fu, Sek Kun Leong, Xiaocong Lian, and Xiangyang Ji. 6d robotic assembly based on rgb-only object pose esti- mation. InIEEE/RSJ International Conference on Intelligent Robots and Systems, pages 4736–4742, 2022. 1
work page 2022
-
[19]
Sa6d: Self-adaptive few-shot 6d pose estimator for novel and occluded objects
Ning Gao, Vien Anh Ngo, Hanna Ziesche, and Gerhard Neu- mann. Sa6d: Self-adaptive few-shot 6d pose estimator for novel and occluded objects. In7th Annual Conference on Robot Learning, 2023. 3 9
work page 2023
-
[20]
Unseen object 6d pose es- timation: A benchmark and baselines.arXiv preprint arXiv:2206.11808, 2022
Minghao Gou, Haolin Pan, Hao-Shu Fang, Ziyuan Liu, Cewu Lu, and Ping Tan. Unseen object 6d pose es- timation: A benchmark and baselines.arXiv preprint arXiv:2206.11808, 2022. 1
-
[21]
Mamba: Linear-time sequence mod- eling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence mod- eling with selective state spaces. InConference on Language Modeling, 2024. 4, 5
work page 2024
-
[22]
Efficiently mod- eling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher R´e. Efficiently mod- eling long sequences with structured state spaces. InInter- national Conference on Learning Representations, 2022. 4
work page 2022
-
[23]
Key- matchnet: Zero-shot pose estimation in 3d point clouds by generalized keypoint matching
Frederik Hagelskjær and Rasmus Laurvig Haugaard. Key- matchnet: Zero-shot pose estimation in 3d point clouds by generalized keypoint matching. InIEEE International Con- ference on Automation Science and Engineering, pages 870– 877, 2024. 1
work page 2024
-
[24]
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask r-cnn. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 2961–2969,
-
[25]
Onepose++: Keypoint-free one- shot object pose estimation without cad models
Xingyi He, Jiaming Sun, Yuang Wang, Di Huang, Hujun Bao, and Xiaowei Zhou. Onepose++: Keypoint-free one- shot object pose estimation without cad models. InAdvances in Neural Information Processing Systems, pages 35103– 35115, 2022. 2, 6
work page 2022
-
[26]
Ffb6d: A full flow bidirectional fusion network for 6d pose estimation
Yisheng He, Haibin Huang, Haoqiang Fan, Qifeng Chen, and Jian Sun. Ffb6d: A full flow bidirectional fusion network for 6d pose estimation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 3003–3013, 2021. 1
work page 2021
-
[27]
Fs6d: Few-shot 6d pose estimation of novel objects
Yisheng He, Yao Wang, Haoqiang Fan, Jian Sun, and Qifeng Chen. Fs6d: Few-shot 6d pose estimation of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6814–6824, 2022. 2, 6
work page 2022
-
[28]
Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes
Stefan Hinterstoisser, Stefan Holzer, Cedric Cagniart, Slobo- dan Ilic, Kurt Konolige, Nassir Navab, and Vincent Lepetit. Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 858–865, 2011. 5, 6, 7, 2
work page 2011
-
[29]
Stefan Hinterstoisser, Vincent Lepetit, Slobodan Ilic, Ste- fan Holzer, Gary Bradski, Kurt Konolige, and Nassir Navab. Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes. InAsian Conference on Computer Vision, pages 548–562, 2013. 5
work page 2013
-
[30]
T-less: An rgb- d dataset for 6d pose estimation of texture-less objects
Tom ´aˇs Hodan, Pavel Haluza, ˇStep´an Obdrˇz´alek, Jiri Matas, Manolis Lourakis, and Xenophon Zabulis. T-less: An rgb- d dataset for 6d pose estimation of texture-less objects. In Proceedings of the IEEE/CVF Winter Conference on Appli- cations of Computer Vision, pages 880–888, 2017. 8
work page 2017
-
[31]
Bop challenge 2023 on detection segmentation and pose estimation of seen and unseen rigid objects
Tomas Hodan, Martin Sundermeyer, Yann Labbe, Van Nguyen Nguyen, Gu Wang, Eric Brachmann, Bertram Drost, Vincent Lepetit, Carsten Rother, and Jiri Matas. Bop challenge 2023 on detection segmentation and pose estimation of seen and unseen rigid objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5610–5619, 202...
work page 2023
-
[32]
Matchu: Matching unseen objects for 6d pose estimation from rgb-d images
Junwen Huang, Hao Yu, Kuan-Ting Yu, Nassir Navab, Slo- bodan Ilic, and Benjamin Busam. Matchu: Matching unseen objects for 6d pose estimation from rgb-d images. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10095–10105, 2024. 2
work page 2024
-
[33]
Predator: Registration of 3d point clouds with low overlap
Shengyu Huang, Zan Gojcic, Mikhail Usvyatsov, Andreas Wieser, and Konrad Schindler. Predator: Registration of 3d point clouds with low overlap. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4267–4276, 2021. 6
work page 2021
-
[34]
HyunJun Jung, Shun-Cheng Wu, Patrick Ruhkamp, et al. Housecat6d–a large-scale multi-modal category level 6d ob- ject pose dataset with household objects in realistic scenar- ios. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 22498–22508,
-
[35]
Homebreweddb: Rgb-d dataset for 6d pose esti- mation of 3d objects
Roman Kaskman, Sergey Zakharov, Ivan Shugurov, and Slo- bodan Ilic. Homebreweddb: Rgb-d dataset for 6d pose esti- mation of 3d objects. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision Workshops, 2019. 5, 7, 2
work page 2019
-
[36]
Ominnocs: A unified nocs dataset and model for 3d lifting of 2d objects
Akshay Krishnan, Abhijit Kundu, Kevis-Kokitsi Maninis, James Hays, and Matthew Brown. Ominnocs: A unified nocs dataset and model for 3d lifting of 2d objects. InEuropean Conference on Computer Vision, pages 127–145, 2024. 1
work page 2024
-
[37]
Megapose: 6d pose estimation of novel objects via render & compare
Yann Labb ´e, Lucas Manuelli, Arsalan Mousavian, Stephen Tyree, Stan Birchfield, Jonathan Tremblay, Justin Carpentier, Mathieu Aubry, Dieter Fox, and Josef Sivic. Megapose: 6d pose estimation of novel objects via render & compare. In Proceedings of the 6th Conference on Robot Learning, 2022. 2, 5, 6, 7, 8
work page 2022
-
[38]
Mfos: Model-free & one-shot ob- ject pose estimation
JongMin Lee, Yohann Cabon, Romain Br ´egier, Sungjoo Yoo, and Jerome Revaud. Mfos: Model-free & one-shot ob- ject pose estimation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2911–2919, 2024. 2
work page 2024
-
[39]
Tta-cope: Test-time adaptation for category-level object pose estimation
Taeyeop Lee, Jonathan Tremblay, Valts Blukis, Bowen Wen, Byeong-Uk Lee, Inkyu Shin, Stan Birchfield, In So Kweon, and Kuk-Jin Yoon. Tta-cope: Test-time adaptation for category-level object pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21285–21295, 2023. 1
work page 2023
-
[40]
Dcl-net: Deep corre- spondence learning network for 6d pose estimation
Hongyang Li, Jiehong Lin, and Kui Jia. Dcl-net: Deep corre- spondence learning network for 6d pose estimation. InEuro- pean Conference on Computer Vision, pages 369–385, 2022. 1
work page 2022
-
[41]
Sam-6d: Segment anything model meets zero-shot 6d object pose es- timation
Jiehong Lin, Lihua Liu, Dekun Lu, and Kui Jia. Sam-6d: Segment anything model meets zero-shot 6d object pose es- timation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27906– 27916, 2024. 2, 6, 7
work page 2024
-
[42]
Ist-net: Prior-free category-level pose estimation with im- plicit space transformation
Jianhui Liu, Yukang Chen, Xiaoqing Ye, and Xiaojuan Qi. Ist-net: Prior-free category-level pose estimation with im- plicit space transformation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13978– 13988, 2023. 1
work page 2023
-
[43]
Deep learning-based object pose estimation: A comprehensive survey.arXiv preprint arXiv:2405.07801,
Jian Liu, Wei Sun, Hui Yang, Zhiwen Zeng, Chongpei Liu, Jin Zheng, Xingyu Liu, Hossein Rahmani, Nicu Sebe, and 10 Ajmal Mian. Deep learning-based object pose estimation: A comprehensive survey.arXiv preprint arXiv:2405.07801,
-
[44]
Jian Liu, Wei Sun, Hui Yang, Pengchao Deng, Chong- pei Liu, Nicu Sebe, Hossein Rahmani, and Ajmal Mian. Diff9d: Diffusion-based domain-generalized category-level 9-dof object pose estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(7):5520–5537, 2025. 1
work page 2025
-
[45]
Catre: It- erative point clouds alignment for category-level object pose refinement
Xingyu Liu, Gu Wang, Yi Li, and Xiangyang Ji. Catre: It- erative point clouds alignment for category-level object pose refinement. InEuropean Conference on Computer Vision, pages 499–516, 2022. 1
work page 2022
-
[46]
Unopose: Un- seen object pose estimation with an unposed rgb-d reference image
Xingyu Liu, Gu Wang, Ruida Zhang, Chenyangguang Zhang, Federico Tombari, and Xiangyang Ji. Unopose: Un- seen object pose estimation with an unposed rgb-d reference image. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22023–22034, 2025. 2
work page 2025
-
[47]
Gen6d: Generalizable model-free 6-dof object pose estimation from rgb images
Yuan Liu, Yilin Wen, Sida Peng, Cheng Lin, Xiaoxiao Long, Taku Komura, and Wenping Wang. Gen6d: Generalizable model-free 6-dof object pose estimation from rgb images. In European Conference on Computer Vision, pages 298–315,
-
[48]
Vmamba: Visual state space model
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. Vmamba: Visual state space model. InAdvances in Neural Information Processing Systems, 2024. 5
work page 2024
-
[49]
Genflow: Generalizable recurrent flow for 6d pose refinement of novel objects
Sungphill Moon, Hyeontae Son, Dongcheol Hur, and Sang- wook Kim. Genflow: Generalizable recurrent flow for 6d pose refinement of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10039–10049, 2024. 2
work page 2024
-
[50]
Van Nguyen Nguyen, Yinlin Hu, Yang Xiao, Mathieu Salz- mann, and Vincent Lepetit. Templates for 3d object pose es- timation revisited: Generalization to new objects and robust- ness to occlusions. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6771–6780, 2022. 1
work page 2022
-
[51]
Cnos: A strong base- line for cad-based novel object segmentation
Van Nguyen Nguyen, Thibault Groueix, Georgy Ponimatkin, Vincent Lepetit, and Tomas Hodan. Cnos: A strong base- line for cad-based novel object segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 2134–2140, 2023. 4, 7, 8
work page 2023
-
[52]
Nope: Novel object pose estimation from a sin- gle image
Van Nguyen Nguyen, Thibault Groueix, Georgy Ponimatkin, Yinlin Hu, Renaud Marlet, Mathieu Salzmann, and Vincent Lepetit. Nope: Novel object pose estimation from a sin- gle image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17923– 17932, 2024. 1
work page 2024
-
[53]
Gigapose: Fast and robust novel object pose estimation via one correspondence
Van Nguyen Nguyen, Thibault Groueix, Mathieu Salzmann, and Vincent Lepetit. Gigapose: Fast and robust novel object pose estimation via one correspondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9903–9913, 2024. 2, 4, 6, 7
work page 2024
-
[54]
Zephyr: Zero-shot pose hypothesis rating
Brian Okorn, Qiao Gu, Martial Hebert, and David Held. Zephyr: Zero-shot pose hypothesis rating. InIEEE In- ternational Conference on Robotics and Automation, pages 14141–14148, 2021. 1
work page 2021
-
[55]
Dinov2: Learning robust visual features without supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. Transactions on Machine Learning Research, 2024. 8
work page 2024
-
[56]
Found- pose: Unseen object pose estimation with foundation fea- tures
Evin Pınar ¨Ornek, Yann Labb ´e, Bugra Tekin, Lingni Ma, Cem Keskin, Christian Forster, and Tomas Hodan. Found- pose: Unseen object pose estimation with foundation fea- tures. InEuropean Conference on Computer Vision, pages 163–182, 2024. 2
work page 2024
-
[57]
Panwang Pan, Zhiwen Fan, Brandon Y Feng, Peihao Wang, Chenxin Li, and Zhangyang Wang. Learning to estimate 6dof pose from limited data: A few-shot, generalizable ap- proach using rgb images. InInternational Conference on 3D Vision, pages 1059–1071, 2024. 1
work page 2024
-
[58]
Keunhong Park, Arsalan Mousavian, Yu Xiang, and Dieter Fox. Latentfusion: End-to-end differentiable reconstruction and rendering for unseen object pose estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10710–10719, 2020. 3, 6
work page 2020
-
[59]
Pvnet: Pixel-wise voting network for 6dof pose estimation
Sida Peng, Yuan Liu, Qixing Huang, Xiaowei Zhou, and Hu- jun Bao. Pvnet: Pixel-wise voting network for 6dof pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4561– 4570, 2019. 1
work page 2019
-
[60]
Cornet: Generic 3d corners for 6d pose estimation of new objects without retraining
Giorgia Pitteri, Slobodan Ilic, and Vincent Lepetit. Cornet: Generic 3d corners for 6d pose estimation of new objects without retraining. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision Workshops, 2019. 1
work page 2019
-
[61]
Giorgia Pitteri, Aur ´elie Bugeau, Slobodan Ilic, and Vincent Lepetit. 3d object detection and pose estimation of unseen objects in color images with local surface embeddings. In Proceedings of the Asian Conference on Computer Vision,
-
[62]
Geometric transformer for fast and robust point cloud registration
Zheng Qin, Hao Yu, Changjian Wang, Yulan Guo, Yuxing Peng, and Kai Xu. Geometric transformer for fast and robust point cloud registration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11143–11152, 2022. 5
work page 2022
-
[63]
Osop: A multi-stage one shot object pose estimation frame- work
Ivan Shugurov, Fu Li, Benjamin Busam, and Slobodan Ilic. Osop: A multi-stage one shot object pose estimation frame- work. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 6835–6844,
-
[64]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 8922–8931, 2021. 6
work page 2021
-
[65]
Onepose: One-shot object pose estimation without cad mod- els
Jiaming Sun, Zihao Wang, Siyu Zhang, Xingyi He, Hongcheng Zhao, Guofeng Zhang, and Xiaowei Zhou. Onepose: One-shot object pose estimation without cad mod- els. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 6825–6834,
-
[66]
Multi-path learning for object pose estimation across domains
Martin Sundermeyer, Maximilian Durner, En Yen Puang, Zoltan-Csaba Marton, Narunas Vaskevicius, Kai O Arras, 11 and Rudolph Triebel. Multi-path learning for object pose estimation across domains. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13916–13925, 2020. 1
work page 2020
-
[67]
Stephen Tyree, Jonathan Tremblay, Thang To, Jia Cheng, Terry Mosier, Jeffrey Smith, and Stan Birchfield. 6-dof pose estimation of household objects for robotic manipulation: An accessible dataset and benchmark. InIEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems, pages 13081–13088, 2022. 1
work page 2022
-
[68]
Self6d: Self- supervised monocular 6d object pose estimation
Gu Wang, Fabian Manhardt, Jianzhun Shao, Xiangyang Ji, Nassir Navab, and Federico Tombari. Self6d: Self- supervised monocular 6d object pose estimation. InEuro- pean Conference on Computer Vision, pages 108–125, 2020. 1
work page 2020
-
[69]
Gdr-net: Geometry-guided direct regression net- work for monocular 6d object pose estimation
Gu Wang, Fabian Manhardt, Federico Tombari, and Xi- angyang Ji. Gdr-net: Geometry-guided direct regression net- work for monocular 6d object pose estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16611–16621, 2021. 1
work page 2021
-
[70]
Normalized object coordinate space for category-level 6d object pose and size estimation
He Wang, Srinath Sridhar, Jingwei Huang, Julien Valentin, Shuran Song, and Leonidas J Guibas. Normalized object coordinate space for category-level 6d object pose and size estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2642– 2651, 2019. 1
work page 2019
-
[71]
Object pose estimation via the aggregation of diffusion features
Tianfu Wang, Guosheng Hu, and Hongguang Wang. Object pose estimation via the aggregation of diffusion features. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 10238–10247, 2024. 2
work page 2024
-
[72]
Se(3)-tracknet: Data-driven 6d pose tracking by cal- ibrating image residuals in synthetic domains
Bowen Wen, Chaitanya Mitash, Baozhang Ren, and Kostas E Bekris. Se(3)-tracknet: Data-driven 6d pose tracking by cal- ibrating image residuals in synthetic domains. InIEEE/RSJ International Conference on Intelligent Robots and Systems, pages 10367–10373, 2020. 1
work page 2020
-
[73]
Bundlesdf: Neural 6-dof tracking and 3d reconstruction of unknown objects
Bowen Wen, Jonathan Tremblay, Valts Blukis, Stephen Tyree, Thomas M ¨uller, Alex Evans, Dieter Fox, Jan Kautz, and Stan Birchfield. Bundlesdf: Neural 6-dof tracking and 3d reconstruction of unknown objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 606–617, 2023. 1
work page 2023
-
[74]
Foundationpose: Unified 6d pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17868– 17879, 2024. 2, 3, 6
work page 2024
-
[75]
Captra: Category-level pose tracking for rigid and articulated objects from point clouds
Yijia Weng, He Wang, Qiang Zhou, Yuzhe Qin, Yueqi Duan, Qingnan Fan, Baoquan Chen, Hao Su, and Leonidas J Guibas. Captra: Category-level pose tracking for rigid and articulated objects from point clouds. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13209–13218, 2021. 1
work page 2021
-
[76]
Unseen object pose estimation via registration
Jun Wu, Yue Wang, and Rong Xiong. Unseen object pose estimation via registration. InIEEE International Confer- ence on Real-time Computing and Robotics, pages 974–979,
-
[77]
V ote from the center: 6 dof pose estimation in rgb-d images by radial keypoint voting
Yangzheng Wu, Mohsen Zand, Ali Etemad, and Michael Greenspan. V ote from the center: 6 dof pose estimation in rgb-d images by radial keypoint voting. InEuropean Con- ference on Computer Vision, pages 335–352, 2022. 1
work page 2022
-
[78]
Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes
Yu Xiang, Tanner Schmidt, Venkatraman Narayanan, and Dieter Fox. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. InRobotics: Science and Systems, 2018. 5, 6, 7, 8, 9, 2, 4
work page 2018
-
[79]
6d-diff: A keypoint diffusion framework for 6d object pose estimation
Li Xu, Haoxuan Qu, Yujun Cai, and Jun Liu. 6d-diff: A keypoint diffusion framework for 6d object pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9676–9686, 2024. 1
work page 2024
-
[80]
Omni6dpose: A benchmark and model for universal 6d object pose esti- mation and tracking
Jiyao Zhang, Weiyao Huang, Bo Peng, Mingdong Wu, Fei Hu, Zijian Chen, Bo Zhao, and Hao Dong. Omni6dpose: A benchmark and model for universal 6d object pose esti- mation and tracking. InEuropean Conference on Computer Vision, 2024. 1
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.