LLM-FE: Automated Feature Engineering for Tabular Data with LLMs as Evolutionary Optimizers
Pith reviewed 2026-05-22 23:34 UTC · model grok-4.3
The pith
LLM-FE treats feature engineering for tabular data as an evolutionary program search guided by LLM proposals and validation feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM-FE formulates feature engineering as a program search problem in which large language models iteratively propose feature transformation programs, and validation scores from the downstream tabular model supply the selection pressure that evolves higher-performing programs across generations, yielding consistent gains over state-of-the-art baselines on diverse classification and regression benchmarks.
What carries the argument
Evolutionary search loop in which LLMs serve as the variation operators that generate candidate feature transformation programs and validation performance ranks them for retention and further refinement.
If this is right
- Tabular models obtain higher predictive performance on standard benchmarks without requiring hand-crafted features.
- The search process incorporates dataset-specific domain knowledge that static operator libraries cannot supply.
- Feature discovery adapts over multiple rounds using concrete performance data rather than relying on a single LLM call.
- Both classification and regression tasks benefit from the same iterative program-evolution procedure.
Where Pith is reading between the lines
- The same evolutionary prompting pattern could be applied to other program-synthesis settings such as data preprocessing pipelines or model architecture search.
- Generated features might serve as interpretable artifacts that reveal which data relationships the LLM has surfaced.
- Efficiency gains could come from caching high-performing program fragments across related datasets rather than restarting evolution each time.
Load-bearing premise
Validation scores supply a sufficiently clean and informative ranking signal so that LLM-proposed programs improve over generations rather than being dominated by invalid or unhelpful outputs.
What would settle it
On a held-out collection of tabular classification and regression datasets, LLM-FE produces no statistically significant accuracy lift relative to the strongest fixed-space or non-evolutionary LLM baseline after multiple independent runs.
Figures






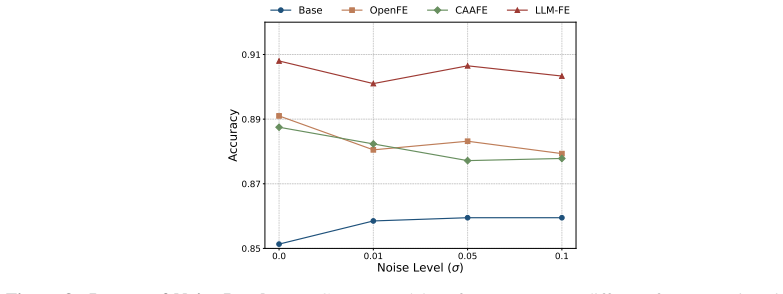




read the original abstract
Automated feature engineering plays a critical role in improving predictive model performance for tabular learning tasks. Traditional automated feature engineering methods are limited by their reliance on pre-defined transformations within fixed, manually designed search spaces, often neglecting domain knowledge. Recent advances using Large Language Models (LLMs) have enabled the integration of domain knowledge into the feature engineering process. However, existing LLM-based approaches use direct prompting or rely solely on validation scores for feature selection, failing to leverage insights from prior feature discovery experiments or establish meaningful reasoning between feature generation and data-driven performance. To address these challenges, we propose LLM-FE, a novel framework that combines evolutionary search with the domain knowledge and reasoning capabilities of LLMs to automatically discover effective features for tabular learning tasks. LLM-FE formulates feature engineering as a program search problem, where LLMs propose new feature transformation programs iteratively, and data-driven feedback guides the search process. Our results demonstrate that LLM-FE consistently outperforms state-of-the-art baselines, significantly enhancing the performance of tabular prediction models across diverse classification and regression benchmarks. The code is available at: https://github.com/nikhilsab/LLMFE
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LLM-FE, a framework that casts automated feature engineering for tabular data as an evolutionary program search problem. LLMs iteratively propose feature transformation programs, with data-driven validation scores providing the selection signal to guide the search and incorporate domain knowledge. The central claim is that this approach consistently outperforms state-of-the-art baselines and improves downstream tabular prediction performance on diverse classification and regression benchmarks.
Significance. If the empirical results and the reliability of the LLM-driven evolutionary loop hold, the work could meaningfully advance automated feature engineering by moving beyond fixed, manually designed transformation spaces to leverage LLM reasoning in an iterative, feedback-guided manner. The public code release is a positive contribution for reproducibility.
major comments (2)
- [Method (program search formulation)] The central claim that LLM-proposed programs yield reliable evolutionary improvement depends on validation scores supplying directional signal. The method description states that LLMs propose programs iteratively and data-driven feedback guides the search, yet no quantitative results are supplied on proposal validity rate, syntax/runtime error frequency, or the fraction of programs filtered before scoring. If a substantial fraction of proposals are non-executable or produce degenerate features, the ranking step supplies little signal and observed gains could be attributable to the base learner rather than the LLM-evolution loop.
- [Abstract] Abstract asserts that LLM-FE 'consistently outperforms state-of-the-art baselines' and 'significantly enhancing the performance' across benchmarks, but supplies no quantitative results, baseline names, dataset list, statistical tests, or ablation details on the evolutionary component versus random search or direct prompting. Without these, the data-to-claim link cannot be evaluated.
minor comments (1)
- [Abstract / Method] The abstract and method overview would benefit from a concise diagram or pseudocode of the evolutionary loop (proposal, execution, scoring, selection) to clarify the exact feedback mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will revise the manuscript to strengthen the empirical grounding of the claims.
read point-by-point responses
-
Referee: [Method (program search formulation)] The central claim that LLM-proposed programs yield reliable evolutionary improvement depends on validation scores supplying directional signal. The method description states that LLMs propose programs iteratively and data-driven feedback guides the search, yet no quantitative results are supplied on proposal validity rate, syntax/runtime error frequency, or the fraction of programs filtered before scoring. If a substantial fraction of proposals are non-executable or produce degenerate features, the ranking step supplies little signal and observed gains could be attributable to the base learner rather than the LLM-evolution loop.
Authors: We agree that the current manuscript does not report these intermediate statistics on proposal validity and error rates. In the revised version we will add a dedicated analysis (new subsection or appendix) that quantifies, across the experimental runs, the fraction of LLM-proposed programs that are syntactically valid and executable, the frequency of runtime errors, and the proportion filtered before scoring. This will directly demonstrate that validation scores supply meaningful selection signal. All reported gains are measured against baselines that employ identical base learners on the same data splits, which already isolates the contribution of the LLM-driven evolutionary loop from the base model itself. revision: yes
-
Referee: [Abstract] Abstract asserts that LLM-FE 'consistently outperforms state-of-the-art baselines' and 'significantly enhancing the performance' across benchmarks, but supplies no quantitative results, baseline names, dataset list, statistical tests, or ablation details on the evolutionary component versus random search or direct prompting. Without these, the data-to-claim link cannot be evaluated.
Authors: The abstract is intentionally concise and high-level. The full manuscript supplies the requested details: baseline names and implementations, the complete dataset list, performance tables with statistical significance tests, and ablations that compare the evolutionary loop against random search and direct-prompting variants. To improve the abstract-to-claim linkage we will revise the abstract to include a short quantitative statement (e.g., average relative improvement and number of benchmarks) while preserving length constraints. revision: partial
Circularity Check
No circularity; empirical method with external validation
full rationale
The paper describes an LLM-driven evolutionary search for feature programs, guided by validation scores on held-out data. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the abstract or method outline. Performance claims rest on benchmark comparisons rather than any internal reduction to the method's own inputs. This is the common case of a self-contained empirical framework.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models encode useful domain knowledge that can be elicited to propose feature transformations
Forward citations
Cited by 7 Pith papers
-
Memory-Augmented LLM-based Multi-Agent System for Automated Feature Generation on Tabular Data
MALMAS is a memory-augmented multi-agent LLM system that generates diverse, high-quality features for tabular data via agent decomposition, routing, and iterative memory-guided refinement.
-
BoostLLM: Boosting-inspired LLM Fine-tuning for Few-shot Tabular Classification
BoostLLM trains sequential PEFT adapters as weak learners in a residual process, using decision-tree paths as a second input view, to improve few-shot tabular classification over standard LLM fine-tuning and match or ...
-
BoostLLM: Boosting-inspired LLM Fine-tuning for Few-shot Tabular Classification
BoostLLM trains sequential PEFT adapters in a boosting framework with tree path inputs to improve LLM performance on few-shot tabular classification, matching or exceeding XGBoost.
-
TriAlignGR: Triangular Multitask Alignment with Multimodal Deep Interest Mining for Generative Recommendation
TriAlignGR proposes a triangular multitask alignment framework with cross-modal semantic alignment, deep interest mining via chain-of-thought, and joint training on eight tasks to address content degradation and seman...
-
FELA: A Multi-Agent Evolutionary System for Feature Engineering of Industrial Event Log Data
FELA deploys specialized LLM agents in an evolutionary framework to generate, validate, and refine explainable features from heterogeneous industrial event logs, improving downstream model performance.
-
RelAgent: LLM Agents as Data Scientists for Relational Learning
RelAgent uses an LLM agent to autonomously generate SQL feature programs paired with classical models for interpretable relational learning predictions that execute efficiently on standard databases.
-
TriAlignGR: Triangular Multitask Alignment with Multimodal Deep Interest Mining for Generative Recommendation
TriAlignGR integrates visual content and latent user interests into Semantic IDs via cross-modal alignment, CoT-based interest mining, and triangular multitask training to address content degradation and semantic opac...
Reference graph
Works this paper leans on
-
[1]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2623–2631, 2019
work page 2019
-
[2]
The state of data science 2020
Anaconda. The state of data science 2020. Website, 2020
work page 2020
-
[3]
Uci machine learning repository, 2007
Arthur Asuncion, David Newman, et al. Uci machine learning repository, 2007
work page 2007
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[5]
Evoprompting: language models for code-level neural architecture search
Angelica Chen, David Dohan, and David So. Evoprompting: language models for code-level neural architecture search. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[6]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016
work page 2016
-
[7]
Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl
Miles Cranmer. Interpretable machine learning for science with pysr and symbolicregression. jl. arXiv preprint arXiv:2305.01582, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Michael De La Maza and Bruce Tidor. Increased flexibility in genetic algorithms: The use of variable boltzmann selective pressure to control propagation. In Computer Science and Operations Research, pages 425–440. Elsevier, 1992
work page 1992
-
[9]
Lift: Language-interfaced fine-tuning for non-language machine learning tasks
Tuan Dinh, Yuchen Zeng, Ruisu Zhang, Ziqian Lin, Michael Gira, Shashank Rajput, Jy-yong Sohn, Dimitris Papailiopoulos, and Kangwook Lee. Lift: Language-interfaced fine-tuning for non-language machine learning tasks. Advances in Neural Information Processing Systems, 35:11763–11784, 2022
work page 2022
-
[10]
A few useful things to know about machine learning
Pedro Domingos. A few useful things to know about machine learning. Communications of the ACM, 55(10):78–87, 2012
work page 2012
-
[11]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Openml-python: an extensible python api for openml
Matthias Feurer, Jan N Van Rijn, Arlind Kadra, Pieter Gijsbers, Neeratyoy Mallik, Sahithya Ravi, Andreas Müller, Joaquin Vanschoren, and Frank Hutter. Openml-python: an extensible python api for openml. Journal of Machine Learning Research, 22(100):1–5, 2021
work page 2021
-
[13]
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data.Advances in Neural Information Processing Systems, 34:18932– 18943, 2021
work page 2021
-
[14]
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? Advances in neural information processing systems, 35:507–520, 2022. 10
work page 2022
-
[15]
EvoPrompt: Connecting LLMs with Evolutionary Algorithms Yields Powerful Prompt Optimizers
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. arXiv preprint arXiv:2309.08532, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Language models can teach themselves to program better
Patrick Haluptzok, Matthew Bowers, and Adam Tauman Kalai. Language models can teach themselves to program better. arXiv preprint arXiv:2207.14502, 2022
-
[17]
Large language models can automatically engineer features for few-shot tabular learning
Sungwon Han, Jinsung Yoon, Sercan O Arik, and Tomas Pfister. Large language models can automatically engineer features for few-shot tabular learning. arXiv preprint arXiv:2404.09491, 2024
-
[18]
Tabllm: Few-shot classification of tabular data with large language models
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Sontag. Tabllm: Few-shot classification of tabular data with large language models. In International Conference on Artificial Intelligence and Statistics, pages 5549–5581. PMLR, 2023
work page 2023
-
[19]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second. arXiv preprint arXiv:2207.01848, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Noah Hollmann, Samuel Müller, and Frank Hutter. Large language models for automated data science: Introducing caafe for context-aware automated feature engineering. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[21]
The autofeat python library for automated feature engineering and selection
Franziska Horn, Robert Pack, and Michael Rieger. The autofeat python library for automated feature engineering and selection. In Machine Learning and Knowledge Discovery in Databases: International Workshops of ECML PKDD 2019, Würzburg, Germany, September 16–20, 2019, Proceedings, Part I, pages 111–120. Springer, 2020
work page 2019
-
[22]
Deep feature synthesis: Towards automating data science endeavors
James Max Kanter and Kalyan Veeramachaneni. Deep feature synthesis: Towards automating data science endeavors. In 2015 IEEE international conference on data science and advanced analytics (DSAA), pages 1–10. IEEE, 2015
work page 2015
-
[23]
Feature engineering for predictive modeling using reinforcement learning
Udayan Khurana, Horst Samulowitz, and Deepak Turaga. Feature engineering for predictive modeling using reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
work page 2018
-
[24]
Cognito: Automated feature engineering for supervised learning
Udayan Khurana, Deepak Turaga, Horst Samulowitz, and Srinivasan Parthasrathy. Cognito: Automated feature engineering for supervised learning. In 2016 IEEE 16th international conference on data mining workshops (ICDMW), pages 1304–1307. IEEE, 2016
work page 2016
-
[25]
Large language models engineer too many simple features for tabular data
Jaris Küken, Lennart Purucker, and Frank Hutter. Large language models engineer too many simple features for tabular data. arXiv preprint arXiv:2410.17787, 2024
-
[26]
Large language models as evolution strategies
Robert Lange, Yingtao Tian, and Yujin Tang. Large language models as evolution strategies. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, pages 579–582, 2024
work page 2024
-
[27]
Evolution through large models
Joel Lehman, Jonathan Gordon, Shawn Jain, Kamal Ndousse, Cathy Yeh, and Kenneth O Stanley. Evolution through large models. In Handbook of Evolutionary Machine Learning, pages 331–366. Springer, 2023
work page 2023
-
[28]
Large language models to enhance bayesian optimization
Tennison Liu, Nicolás Astorga, Nabeel Seedat, and Mihaela van der Schaar. Large language models to enhance bayesian optimization. arXiv preprint arXiv:2402.03921, 2024
-
[29]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[30]
Language model crossover: Variation through few-shot prompting
Elliot Meyerson, Mark J Nelson, Herbie Bradley, Adam Gaier, Arash Moradi, Amy K Hoover, and Joel Lehman. Language model crossover: Variation through few-shot prompting. ACM Transactions on Evolutionary Learning, 4(4):1–40, 2024
work page 2024
-
[31]
Optimized feature generation for tabular data via llms with decision tree reasoning
Jaehyun Nam, Kyuyoung Kim, Seunghyuk Oh, Jihoon Tack, Jaehyung Kim, and Jinwoo Shin. Optimized feature generation for tabular data via llms with decision tree reasoning. arXiv preprint arXiv:2406.08527, 2024
-
[32]
Stunt: Few-shot tabular learning with self-generated tasks from unlabeled tables
Jaehyun Nam, Jihoon Tack, Kyungmin Lee, Hankook Lee, and Jinwoo Shin. Stunt: Few-shot tabular learning with self-generated tasks from unlabeled tables. arXiv preprint arXiv:2303.00918, 2023. 11
-
[33]
Learning feature engineering for classification
Fatemeh Nargesian, Horst Samulowitz, Udayan Khurana, Elias B Khalil, and Deepak S Turaga. Learning feature engineering for classification. In Ijcai, volume 17, pages 2529–2535, 2017
work page 2017
-
[34]
R OpenAI. Gpt-4 technical report. arxiv 2303.08774. View in Article, 2(5), 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024
work page 2024
-
[36]
LLM-SR: Scientific Equation Discovery via Programming with Large Language Models
Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K Reddy. Llm-sr: Scientific equation discovery via programming with large language models. arXiv preprint arXiv:2404.18400, 2024
-
[37]
Openml: networked science in machine learning
Joaquin Vanschoren, Jan N Van Rijn, Bernd Bischl, and Luis Torgo. Openml: networked science in machine learning. ACM SIGKDD Explorations Newsletter, 15(2):49–60, 2014
work page 2014
-
[38]
A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems, 2017
work page 2017
-
[39]
Anypredict: Foundation model for tabular prediction
Zifeng Wang, Chufan Gao, Cao Xiao, and Jimeng Sun. Anypredict: Foundation model for tabular prediction. CoRR, 2023
work page 2023
-
[40]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[41]
Evolutionary computation in the era of large language model: Survey and roadmap
Xingyu Wu, Sheng-hao Wu, Jibin Wu, Liang Feng, and Kay Chen Tan. Evolutionary computation in the era of large language model: Survey and roadmap. arXiv preprint arXiv:2401.10034, 2024
-
[42]
Making pre-trained language models great on tabular prediction
Jiahuan Yan, Bo Zheng, Hongxia Xu, Yiheng Zhu, Danny Z Chen, Jimeng Sun, Jian Wu, and Jintai Chen. Making pre-trained language models great on tabular prediction. arXiv preprint arXiv:2403.01841, 2024
-
[43]
Le, Denny Zhou, and Xinyun Chen
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V . Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers, 2024
work page 2024
-
[44]
Automatic feature engineering by deep reinforcement learning
Jianyu Zhang, Jianye Hao, Françoise Fogelman-Soulié, and Zan Wang. Automatic feature engineering by deep reinforcement learning. InProceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, pages 2312–2314, 2019
work page 2019
-
[45]
Openfe: automated feature generation with expert-level performance
Tianping Zhang, Zheyu Aqa Zhang, Zhiyuan Fan, Haoyan Luo, Fengyuan Liu, Qian Liu, Wei Cao, and Li Jian. Openfe: automated feature generation with expert-level performance. In International Conference on Machine Learning, pages 41880–41901. PMLR, 2023
work page 2023
-
[46]
Can GPT -4 Perform Neural Architecture Search ?, August 2023
Mingkai Zheng, Xiu Su, Shan You, Fei Wang, Chen Qian, Chang Xu, and Samuel Albanie. Can gpt-4 perform neural architecture search? arXiv preprint arXiv:2304.10970, 2023
-
[47]
""Improved version of modify_features_v0
Zhaocheng Zhu, Yuan Xue, Xinyun Chen, Denny Zhou, Jian Tang, Dale Schuurmans, and Hanjun Dai. Large language models can learn rules. arXiv preprint arXiv:2310.07064, 2023. Impact Statement The introduction of LLM-FE as a framework for leveraging LLMs in automated feature engineering has the potential to significantly impact the field of machine learning b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.