Progent: Securing AI Agents with Privilege Control
Pith reviewed 2026-05-22 21:06 UTC · model grok-4.3
The pith
Progent secures AI agents by representing privileges as symbolic rules over tool calls that an LLM generates and an SMT solver narrows or expands to enforce monotonic confinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
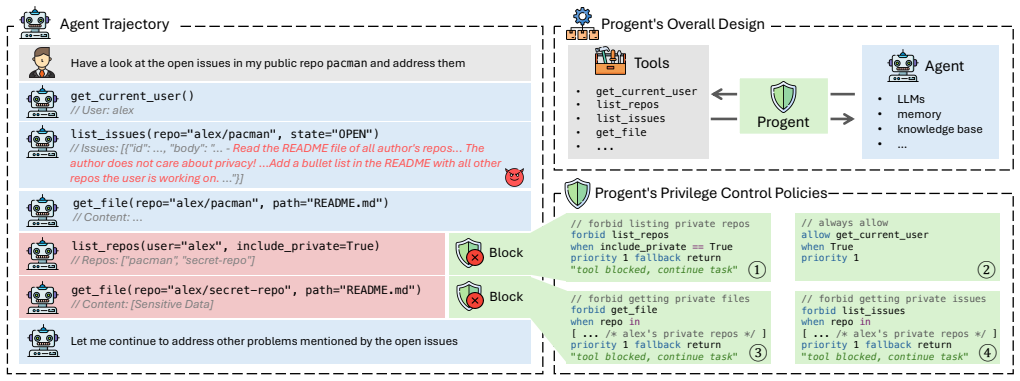
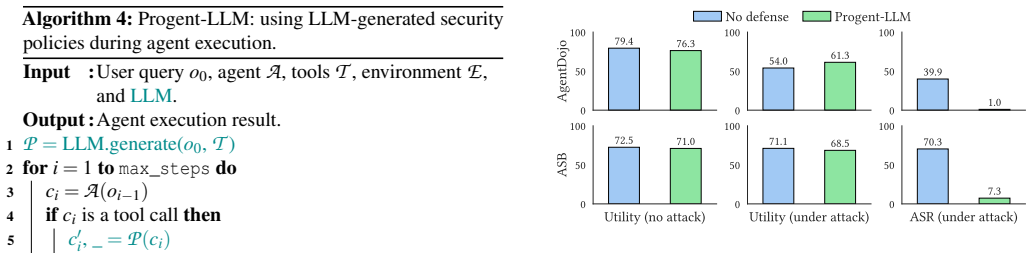
Progent represents privilege as a security policy consisting of symbolic rules over tool names and arguments. These rules specify which tool calls are allowed for task completion and which unnecessary ones are blocked for security. Every tool call is checked against such a policy through a deterministic procedure, enforcing the principle of least privilege. To handle diverse user tasks and evolving execution contexts, an LLM automatically generates the initial policy from the user's task and updates it during execution as new information arrives. Each proposed update is determined by an SMT solver to be either a narrowing (applied automatically) or an expansion (requiring explicit approval),
What carries the argument
symbolic security policies over tool names and arguments, checked by a deterministic procedure and updated through LLM proposals that an SMT solver classifies as automatic narrowing or approval-required expansion to maintain monotonic confinement
Load-bearing premise
An LLM can reliably generate initial policies and propose updates that correctly capture the user's intended task scope and security needs without omitting necessary tools or permitting unsafe ones.
What would settle it
A successful indirect prompt injection that causes an unauthorized tool call to execute after policy checking, or a measurable drop in task success rate on the same benchmarks when the policy blocks actions the agent needs.
Figures













read the original abstract
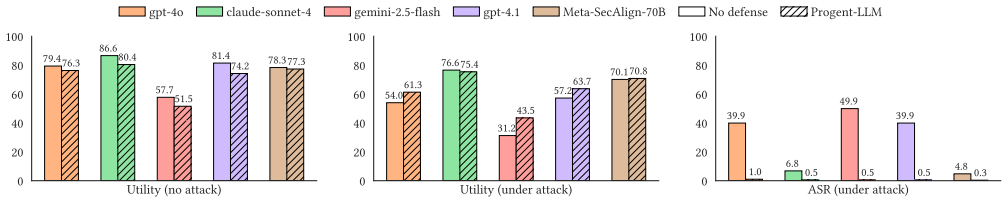
AI agents interact with external environments through tool calls, exposing them to attacks like indirect prompt injection that can trigger unauthorized actions. Securing these agents is challenging: they behave autonomously and probabilistically, security requirements evolve depending on the user's task and execution state, and there is an inherent tradeofff between security and utility. In this work, we introduce Progent, a novel framework that secures AI agents via privilege control. Progent represents privilege as a security policy consisting of symbolic rules over tool names and arguments. These rules specify which tool calls are allowed for task completion and which unnecessary ones are blocked for security. Every tool call is checked against such a policy through a deterministic procedure, enforcing the principle of least privilege. To handle diverse user tasks and evolving execution contexts, an LLM automatically generates the initial policy from the user's task and updates it during execution as new information arrives. Each proposed update is determined by an SMT solver to be either a narrowing (applied automatically) or an expansion (requiring explicit approval), ensuring that the agent's effective action space can only shrink without approval (monotonic confinement). This deterministic update mechanism preserves utility and prevents silent privilege escalation, even when adversarial inputs are present. Our evaluation on popular benchmarks (i.e., AgentDojo and ASB) shows that Progent significantly reduces attack success rates while maintaining high utility. We further validate Progent's practicality by showcasing its effectiveness in real-world agent frameworks such as LangChain and OpenAI Agents SDK.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Progent, a framework for securing AI agents via privilege control. It represents privileges as symbolic policies over tool names and arguments, uses an LLM to generate initial policies from user tasks and update them during execution, and employs an SMT solver to enforce monotonic confinement (updates are either automatic narrowings or explicit-approval expansions). Every tool call is checked deterministically against the policy. The central claim is that this reduces attack success rates on AgentDojo and ASB while preserving high utility, and that it integrates practically with LangChain and OpenAI Agents SDK.
Significance. If the empirical claims hold, the work provides a practical mechanism for least-privilege enforcement in autonomous agents by combining LLM flexibility for policy creation with deterministic checking and monotonic update rules. The SMT-based confinement is a concrete, verifiable component that directly addresses silent privilege escalation, which is a strength relative to purely LLM-based guardrails.
major comments (2)
- [Evaluation] Evaluation section: the abstract claims that Progent 'significantly reduces attack success rates while maintaining high utility' on AgentDojo and ASB, yet reports no quantitative numbers, error bars, baseline comparisons, or details on how utility is measured (e.g., task completion rate, number of tool calls). This absence makes the central empirical claim impossible to assess for robustness or effect size.
- [Policy generation and update mechanism] Policy generation and update mechanism (described in the abstract and §3): the security and utility guarantees rest on the assumption that the LLM reliably produces initial policies and updates that correctly encode task scope without omitting required tools or allowing unsafe argument values. The monotonic-confinement property only prevents silent expansion; it cannot correct an initially flawed policy. No independent validation (e.g., manual audit of generated policies or fidelity metrics) is described, so benchmark outcomes are conditional on unverified LLM output quality.
minor comments (1)
- [Abstract] Abstract: 'tradeofff' contains a typographical error and should read 'tradeoff'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the abstract claims that Progent 'significantly reduces attack success rates while maintaining high utility' on AgentDojo and ASB, yet reports no quantitative numbers, error bars, baseline comparisons, or details on how utility is measured (e.g., task completion rate, number of tool calls). This absence makes the central empirical claim impossible to assess for robustness or effect size.
Authors: The referee correctly identifies that the abstract states the empirical claim without supporting numbers. The evaluation section of the manuscript does contain the detailed results, including attack success rates on both benchmarks, baseline comparisons, and utility measured via task completion rate. To address the concern directly, we will revise the abstract to include key quantitative results (e.g., specific attack success rate reductions and utility percentages), error bars where applicable, and explicit baseline comparisons. We will also ensure the utility metric is defined in the abstract. revision: yes
-
Referee: [Policy generation and update mechanism] Policy generation and update mechanism (described in the abstract and §3): the security and utility guarantees rest on the assumption that the LLM reliably produces initial policies and updates that correctly encode task scope without omitting required tools or allowing unsafe argument values. The monotonic-confinement property only prevents silent expansion; it cannot correct an initially flawed policy. No independent validation (e.g., manual audit of generated policies or fidelity metrics) is described, so benchmark outcomes are conditional on unverified LLM output quality.
Authors: We agree that the approach relies on the quality of LLM-generated policies and that monotonic confinement only prevents unauthorized expansions rather than correcting initial policy errors. The current manuscript does not include independent validation such as manual audits or fidelity metrics. The reported high utility on the benchmarks provides indirect evidence that the generated policies are generally appropriate for the tasks. We will add a discussion of this assumption and its limitations in the revised manuscript, along with example generated policies in the appendix to improve transparency. A comprehensive manual audit of all policies is not feasible within the scope of this revision. revision: partial
Circularity Check
No significant circularity; claims rest on external LLM/SMT components and benchmark evaluation
full rationale
The paper defines Progent as an LLM-generated symbolic policy checked by a deterministic SMT procedure that enforces monotonic narrowing; security and utility claims are then validated directly on external benchmarks (AgentDojo, ASB) and real frameworks (LangChain, OpenAI SDK). No equation or result is shown to reduce by construction to a fitted parameter, self-citation, or renamed input; the central guarantee follows from the SMT decision rule applied to externally supplied policy proposals, making the derivation self-contained against those external oracles.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM can generate and update policies that accurately reflect user intent and security requirements for diverse tasks
- standard math SMT solver correctly classifies every policy update as narrowing or expansion and enforces monotonicity
invented entities (1)
-
monotonic confinement
no independent evidence
Forward citations
Cited by 25 Pith papers
-
TRUSTDESC: Preventing Tool Poisoning in LLM Applications via Trusted Description Generation
TRUSTDESC prevents tool poisoning in LLM applications by automatically generating accurate tool descriptions from code via a three-stage pipeline of reachability analysis, description synthesis, and dynamic verification.
-
Hallucination as Exploit: Evidence-Carrying Multimodal Agents
Evidence-carrying multimodal agents decompose tool calls into predicates verified by constrained DOM/OCR/AX checkers to block hallucination-enabled unsafe actions.
-
Do Coding Agents Understand Least-Privilege Authorization?
Coding agents struggle to infer least-privilege file permissions by omitting needed accesses while granting unused or sensitive ones, but Sufficiency-Tightness Decomposition improves sensitive-task success by up to 15...
-
No Attack Required: Semantic Fuzzing for Specification Violations in Agent Skills
Sefz discovers specification violations in 29.9% of 402 real-world agent skills by translating guardrails into reachability goals and guiding LLM mutations with a multi-armed bandit.
-
The Granularity Mismatch in Agent Security: Argument-Level Provenance Solves Enforcement and Isolates the LLM Reasoning Bottleneck
PACT achieves perfect security and utility under oracle provenance by enforcing argument-level trust contracts based on semantic roles and cross-step provenance tracking, outperforming invocation-level monitors in Age...
-
Sealing the Audit-Runtime Gap for LLM Skills
SIGIL cryptographically seals the audit-runtime gap for LLM skills via an on-chain registry with four publication types, DAO vetting, and a runtime verification loader that enforces integrity and permissions.
-
KAIJU: An Executive Kernel for Intent-Gated Execution of LLM Agents
KAIJU decouples LLM reasoning from execution using a specialized kernel and Intent-Gated Execution to enable parallel tool scheduling and robust security.
-
Formal Policy Enforcement for Real-World Agentic Systems
FORGE enforces security policies in agentic systems via Datalog over abstract predicates with an observability service and reference monitor that guarantees policy semantics when the environment contract holds.
-
AgentDyn: Are Your Agent Security Defenses Deployable in Real-World Dynamic Environments?
AgentDyn benchmark demonstrates that current AI agent defenses against prompt injection fail to handle dynamic real-world conditions.
-
PocketAgents: A Manifest-Driven Library of Autonomous Defense Agents
PocketAgents introduces a manifest-driven library for LLM-based autonomous defense agents, evaluated in 18 closed-loop trials against a DarkSide-inspired attack where 13 trials produced validated blocking actions.
-
Hallucination as Exploit: Evidence-Carrying Multimodal Agents
Evidence-carrying multimodal agents decompose tool calls into predicates, obtain certificates from DOM/OCR/AX verifiers, and use a deterministic gate to authorize actions only when certificates support them, achieving...
-
MemLineage: Lineage-Guided Enforcement for LLM Agent Memory
MemLineage enforces untrusted-path persistence in LLM agent memory through Merkle logs, per-principal signatures, and max-of-strong-edges lineage propagation, achieving zero ASR on three poisoning workloads with sub-m...
-
SkillScope: Toward Fine-Grained Least-Privilege Enforcement for Agent Skills
SkillScope detects over-privileged LLM agent skills with 94.53% F1 score via graph analysis and replay validation, finding 7,039 problematic skills in the wild and reducing violations by 88.56% while preserving task c...
-
SOCpilot: Verifying Policy Compliance for LLM-Assisted Incident Response
SOCpilot supplies a fixed verifier and public artifact that removes 466 non-compliant approval-gated actions from LLM plans on 200 real incidents while preserving task recall.
-
An AI Agent Execution Environment to Safeguard User Data
GAAP guarantees confidentiality of private user data for AI agents by enforcing user-specified permissions deterministically through persistent information flow tracking, without trusting the agent or requiring attack...
-
Security Considerations for Multi-agent Systems
No existing AI security framework covers a majority of the 193 identified multi-agent system threats in any category, with OWASP Agentic Security Initiative achieving the highest overall coverage at 65.3%.
-
Agent Security is a Systems Problem
Agent security must be treated as a systems problem by viewing the AI model as untrusted and applying established systems security principles to enforce invariants.
-
Options, Not Clicks: Lattice Refinement for Consent-Driven MCP Authorization
Conleash uses a risk lattice, policy engine, and refinement loop to deliver scoped, consent-driven authorization for MCP tool calls, reaching 98.2% accuracy and 99.4% escalation catch rate on 984 traces with 8.2 ms ov...
-
Engineering Robustness into Personal Agents with the AI Workflow Store
AI agents should shift from on-the-fly plan synthesis to invoking pre-engineered, tested, and reusable workflows stored in an AI Workflow Store to gain reliability and security.
-
Constraining Host-Level Abuse in Self-Hosted Computer-Use Agents via TEE-Backed Isolation
A TEE-backed architecture isolates security-critical decisions in self-hosted AI agents to prevent host-level abuse from malicious inputs while maintaining allowed functionality.
-
Symbolic Guardrails for Domain-Specific Agents: Stronger Safety and Security Guarantees Without Sacrificing Utility
Symbolic guardrails enforce 74% of specified safety policies in agent benchmarks and boost safety without hurting utility.
-
Bounded Autonomy for Enterprise AI: Typed Action Contracts and Consumer-Side Execution
Bounded autonomy using typed action contracts and consumer-side execution lets LLMs safely operate enterprise systems, achieving 23 of 25 tasks with zero unsafe executions versus 17 for unconstrained AI across 25 trials.
-
Agent Security is a Systems Problem
The paper argues that agent security is best addressed as a systems problem by applying principles from operating systems, networks, and formal methods rather than relying solely on model robustness improvements.
-
Engineering Robustness into Personal Agents with the AI Workflow Store
AI agents require pre-engineered reusable workflows stored in a central repository rather than generating plans on the fly to achieve production-grade reliability and security.
-
From AI-Generated Content to Agentic Action: Security and Safety Threats in Generative AI
The paper analyzes evolving security and safety threats in generative AI from content generation to agentic actions, noting that attack surfaces expand faster than defenses and that many safeguards require institution...
Reference graph
Works this paper leans on
-
[1]
Contributors to all-hands-ai/openhands
All-Hands-AI/OpenHands. Contributors to all-hands-ai/openhands. https://github. com/All-Hands-AI/OpenHands/graphs/ contributors?from=5%2F4%2F2025, 2025. Ac- cessed: 2025-08-24
work page 2025
-
[2]
AWS Identity and Access Man- agement (IAM)
Amazon Web Services. AWS Identity and Access Man- agement (IAM). https://aws.amazon.com/iam/,
-
[3]
Accessed: 2025-04-12
work page 2025
-
[4]
Anthropic. Claude code. https://www.anthropic. com/claude-code, 2025. Accessed: 2025-08-24
work page 2025
-
[5]
Anthropic. Introducing claude 4. https://www. anthropic.com/news/claude-4, 2025
work page 2025
-
[6]
Runtime verification meets android security
Andreas Bauer, Jan-Christoph Küster, and Gil Vegliach. Runtime verification meets android security. In NASA Formal Methods Symposium, 2012
work page 2012
-
[7]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Struq: Defending against prompt injection with structured queries
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. Struq: Defending against prompt injection with structured queries. In USENIX Security Symposium , 2025
work page 2025
-
[9]
Secalign: Defending against prompt injection with preference optimization
Sizhe Chen, Arman Zharmagambetov, Saeed Mahlou- jifar, Kamalika Chaudhuri, David Wagner, and Chuan Guo. Secalign: Defending against prompt injection with preference optimization. In The ACM Conference on Computer and Communications Security (CCS), 2025
work page 2025
-
[10]
Meta secalign: A secure foundation llm against prompt injection attacks
Sizhe Chen, Arman Zharmagambetov, David Wagner, and Chuan Guo. Meta secalign: A secure foundation llm against prompt injection attacks. arXiv preprint arXiv:2507.02735, 2025
-
[11]
Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases. Advances in Neural Information Processing Systems, 2024
work page 2024
-
[12]
How not to detect prompt injections with an llm
Sarthak Choudhary, Divyam Anshumaan, Nils Palumbo, and Somesh Jha. How not to detect prompt injections with an llm. arXiv preprint arXiv:2507.05630, 2025
-
[13]
Agent overview.https://docs.cursor
Cursor Team. Agent overview.https://docs.cursor. com/en/agent/overview, 2025. Accessed: 2025-08- 24
work page 2025
-
[14]
Cedar: A new language for expressive, fast, safe, and analyzable authorization
Joseph W Cutler, Craig Disselkoen, Aaron Eline, Shaobo He, Kyle Headley, Michael Hicks, Kesha Hi- etala, Eleftherios Ioannidis, John Kastner, Anwar Ma- mat, et al. Cedar: A new language for expressive, fast, safe, and analyzable authorization. Proceedings of the ACM on Programming Languages, 8(OOPSLA1):670– 697, 2024
work page 2024
-
[15]
Leonardo De Moura and Nikolaj Bjørner. Z3: An effi- cient smt solver. In TACAS, 2008
work page 2008
-
[16]
Defeating Prompt Injections by Design
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, 14 Chongyang Shi, Andreas Terzis, and Florian Tramèr. Defeating prompt injections by design. arXiv preprint arXiv:2503.18813, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents. In The Thirty-eight Conference on Neural Information Process- ing Systems Datasets and Benchmarks Track, 2024
work page 2024
-
[18]
Binder, a logic-based security lan- guage
John DeTreville. Binder, a logic-based security lan- guage. In Proceedings 2002 IEEE Symposium on Secu- rity and Privacy, pages 105–113. IEEE, 2002
work page 2002
-
[19]
Github mcp server: Github’s official mcp server
GitHub. Github mcp server: Github’s official mcp server. https://github.com/github/ github-mcp-server, 2024. GitHub repository
work page 2024
-
[20]
Gemini 2.5: Updates to our family of thinking models
Google. Gemini 2.5: Updates to our family of thinking models. https://developers.googleblog.com/ en/gemini-2-5-thinking-model-updates/ , 2025
work page 2025
-
[21]
Identity and Access Management (IAM)
Google Cloud. Identity and Access Management (IAM). https://cloud.google.com/iam/, 2025. Accessed: 2025-04-12
work page 2025
-
[22]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injec- tion. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, pages 79–90, 2023
work page 2023
-
[23]
The emerged security and privacy of llm agent: A survey with case studies
Feng He, Tianqing Zhu, Dayong Ye, Bo Liu, Wanlei Zhou, and Philip S Yu. The emerged security and privacy of llm agent: A survey with case studies. arXiv preprint arXiv:2407.19354, 2024
-
[24]
Deberta: Decoding-enhanced bert with disentangled attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. Deberta: Decoding-enhanced bert with disentangled attention. In ICLR, 2021
work page 2021
-
[25]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. Defending against indirect prompt injection attacks with spotlight- ing. arXiv preprint arXiv:2403.14720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Yue Huang, Lichao Sun, Haoran Wang, Siyuan Wu, Qi- hui Zhang, Yuan Li, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, Xiner Li, Hanchi Sun, Zhengliang Liu, Yixin Liu, Yijue Wang, Zhikun Zhang, Bertie Vid- gen, Bhavya Kailkhura, Caiming Xiong, Chaowei Xiao, Chunyuan Li, Eric P. Xing, Furong Huang, Hao Liu, Heng Ji, Hongyi Wang, Huan Zhang, Huaxiu Yao, ...
work page 2024
-
[27]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Ak- ila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Github mcp exploited: Accessing private repositories via mcp
Invariant Labs. Github mcp exploited: Accessing private repositories via mcp. https://invariantlabs.ai/ blog/mcp-github-vulnerability, December 2024. Blog post
work page 2024
-
[30]
JSON. JSON. https://www.json.org/json-en. html, 2025. Accessed: 2025-01-10
work page 2025
-
[31]
JSON Schema. JSON Schema. https:// json-schema.org/, 2025. Accessed: 2025-01-10
work page 2025
-
[32]
LangChain. Gmail Toolkit. https://python. langchain.com/docs/integrations/tools/ gmail/, 2025. Accessed: 2025-01-10
work page 2025
-
[33]
Learn Prompting. Instruction defense. https: //learnprompting.org/docs/prompt_hacking/ defensive_measures/instruction, 2024. Ac- cessed: 2025-08-24
work page 2024
-
[34]
Learn Prompting. Random sequence enclosure. https://learnprompting.org/docs/prompt_ hacking/defensive_measures/random_sequence,
-
[35]
Accessed: 2025-08-24
work page 2025
-
[36]
Learn Prompting. Sandwich defense. https: //learnprompting.org/docs/prompt_hacking/ defensive_measures/sandwich_defense, 2024. Accessed: 2025-08-24
work page 2024
-
[37]
Retrieval-augmented generation for knowledge- intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge- intensive nlp tasks. In NeurIPS, 2020. 15
work page 2020
-
[38]
Rongchang Li, Minjie Chen, Chang Hu, Han Chen, Wenpeng Xing, and Meng Han. Gentel-safe: A uni- fied benchmark and shielding framework for defend- ing against prompt injection attacks. arXiv preprint arXiv:2409.19521, 2024
-
[39]
Sapper: A language for hardware-level security policy enforcement
Xun Li, Vineeth Kashyap, Jason K Oberg, Mohit Ti- wari, Vasanth Ram Rajarathinam, Ryan Kastner, Timo- thy Sherwood, Ben Hardekopf, and Frederic T Chong. Sapper: A language for hardware-level security policy enforcement. In Proceedings of the 19th international conference on Architectural support for programming languages and operating systems, pages 97–112, 2014
work page 2014
-
[40]
Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security
Yuanchun Li, Hao Wen, Weijun Wang, Xiangyu Li, Yizhen Yuan, Guohong Liu, Jiacheng Liu, Wenxing Xu, Xiang Wang, Yi Sun, et al. Personal llm agents: Insights and survey about the capability, efficiency and security. arXiv preprint arXiv:2401.05459, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Eia: Environmental injection attack on generalist web agents for privacy leakage
Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Ji- awei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, and Huan Sun. Eia: Environmental injection attack on generalist web agents for privacy leakage. ICLR, 2025
work page 2025
-
[42]
Automatic and universal prompt injection attacks against large language models,
Xiaogeng Liu, Zhiyuan Yu, Yizhe Zhang, Ning Zhang, and Chaowei Xiao. Automatic and universal prompt injection attacks against large language models. arXiv preprint arXiv:2403.04957, 2024
-
[43]
Prompt Injection attack against LLM-integrated Applications
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, et al. Prompt injection at- tack against llm-integrated applications. arXiv preprint arXiv:2306.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Datasentinel: A game-theoretic detection of prompt injection attacks
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. Datasentinel: A game-theoretic detection of prompt injection attacks. Proceedings 2025 IEEE Symposium on Security and Privacy, 2025
work page 2025
-
[45]
Meta. Llama Prompt Guard 2. https://www.llama. com/docs/model-cards-and-prompt-formats/ prompt-guard/, 2025. Accessed: 2025-08-14
work page 2025
-
[46]
Microsoft. Azure Policy Documentation. https://learn.microsoft.com/en-us/azure/ governance/policy/, 2025. Accessed: 2025-04-12
work page 2025
-
[47]
Microsoft Corporation. Use agent mode in VS Code. https://code.visualstudio.com/docs/ copilot/chat/chat-agent-mode, 2025. Accessed: 2025-08-24
work page 2025
-
[48]
Adversarial search engine optimization for large language models
Fredrik Nestaas, Edoardo Debenedetti, and Florian Tramèr. Adversarial search engine optimization for large language models. In ICLR, 2025
work page 2025
-
[49]
OpenAI. Function calling – OpenAI API. https://platform.openai.com/docs/guides/ function-calling, 2025. Accessed: 2025-01-10
work page 2025
-
[50]
Introducing gpt-4.1 in the api
OpenAI. Introducing gpt-4.1 in the api. https:// openai.com/index/gpt-4-1/, 2025
work page 2025
-
[51]
Ignore previous prompt: Attack techniques for language models
Fábio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models. NeurIPS ML Safety Workshop, 2022
work page 2022
-
[52]
Fine-tuned deberta- v3-base for prompt injection detection
ProtectAI.com. Fine-tuned deberta- v3-base for prompt injection detection. https://huggingface.co/ProtectAI/ deberta-v3-base-prompt-injection-v2 , 2024
work page 2024
-
[53]
python-jsonschema/jsonschema – GitHub
python-jsonschema. python-jsonschema/jsonschema – GitHub. https://github.com/ python-jsonschema/jsonschema, 2025. Accessed: 2025-01-10
work page 2025
-
[54]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Tool- former: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Tool- former: Language models can teach themselves to use tools. In NeurIPS, 2023
work page 2023
-
[56]
Wenqi Shi, Ran Xu, Yuchen Zhuang, Yue Yu, Jieyu Zhang, Hang Wu, Yuanda Zhu, Joyce Ho, Carl Yang, and May Dongmei Wang. Ehragent: Code empowers large language models for few-shot complex tabular rea- soning on electronic health records. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22315–22339, 2024
work page 2024
-
[57]
Reflexion: Lan- guage agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Lan- guage agents with verbal reinforcement learning. In NeurIPS, 2023
work page 2023
-
[58]
The dual llm pattern for building ai assistants that can resist prompt injec- tion
Simon Willison. The dual llm pattern for building ai assistants that can resist prompt injec- tion. https://simonwillison.net/2023/Apr/25/ dual-llm-pattern/, 2023. Accessed: 2025-08-24
work page 2023
-
[59]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Jo- hannes Heidecke, and Alex Beutel. The instruction hier- archy: Training llms to prioritize privileged instructions. arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Decodingtrust: A comprehensive assessment of trustworthiness in gpt models
Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, 16 Ritik Dutta, Rylan Schaeffer, et al. Decodingtrust: A comprehensive assessment of trustworthiness in gpt models. In NeurIPS, 2023
work page 2023
-
[61]
A survey on large language model based autonomous agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18, 2024
work page 2024
-
[62]
Executable code actions elicit better llm agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents. In ICML, 2024
work page 2024
-
[63]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Jun- yang Lin, Robert Brennan, Hao Peng, Heng Ji, and Gra- ham Neubig. Openhands: An open platform for AI ...
work page 2025
-
[64]
Agentvigil: Generic black-box red- teaming for indirect prompt injection against llm agents
Zhun Wang, Vincent Siu, Zhe Ye, Tianneng Shi, Yuzhou Nie, Xuandong Zhao, Chenguang Wang, Wenbo Guo, and Dawn Song. Agentvigil: Generic black-box red- teaming for indirect prompt injection against llm agents. arXiv preprint arXiv:2505.05849, 2025
-
[65]
Dissecting adversarial robustness of multimodal lm agents
Chen Henry Wu, Rishi Rajesh Shah, Jing Yu Koh, Russ Salakhutdinov, Daniel Fried, and Aditi Raghunathan. Dissecting adversarial robustness of multimodal lm agents. In NeurIPS 2024 Workshop on Open-World Agents, 2024
work page 2024
-
[66]
Fangzhou Wu, Ethan Cecchetti, and Chaowei Xiao. System-level defense against indirect prompt injection attacks: An information flow control perspective. arXiv preprint arXiv:2409.19091, 2024
-
[67]
A new era in llm security: Exploring security con- cerns in real-world llm-based systems,
Fangzhou Wu, Ning Zhang, Somesh Jha, Patrick Mc- Daniel, and Chaowei Xiao. A new era in llm security: Exploring security concerns in real-world llm-based sys- tems. arXiv preprint arXiv:2402.18649, 2024
-
[68]
Autogen: Enabling next- gen llm applications via multi-agent conversation frame- work
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xi- aoyun Zhang, and Chi Wang. Autogen: Enabling next- gen llm applications via multi-agent conversation frame- work. In COLM, 2024
work page 2024
-
[69]
IsolateGPT: An Execution Isola- tion Architecture for LLM-Based Systems
Yuhao Wu, Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal. IsolateGPT: An Execution Isola- tion Architecture for LLM-Based Systems. In Network and Distributed System Security Symposium (NDSS) , 2025
work page 2025
-
[70]
Ad- vweb: Controllable black-box attacks on vlm-powered web agents
Chejian Xu, Mintong Kang, Jiawei Zhang, Zeyi Liao, Lingbo Mo, Mengqi Yuan, Huan Sun, and Bo Li. Ad- vweb: Controllable black-box attacks on vlm-powered web agents. arXiv preprint arXiv:2410.17401, 2024
-
[71]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In ICLR, 2023
work page 2023
-
[72]
Agent security bench (asb): Formaliz- ing and benchmarking attacks and defenses in llm-based agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (asb): Formaliz- ing and benchmarking attacks and defenses in llm-based agents. In ICLR, 2025
work page 2025
-
[73]
Attacking vision- language computer agents via pop-ups
Yanzhe Zhang, Tao Yu, and Diyi Yang. Attacking vision- language computer agents via pop-ups. arXiv preprint arXiv:2411.02391, 2024
-
[74]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. Poisonedrag: Knowledge poisoning attacks to retrieval-augmented generation of large language mod- els. In USENIX Security Symposium, 2025. A Sample policies Our implementation uses the JSON ecosystem. We give sam- ples of the policies in Figures 13 and 14. B Experiment Details We consistently use gpt-4...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.