Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
Pith reviewed 2026-05-19 09:17 UTC · model grok-4.3
The pith
Training large language models to reason step-by-step about time series improves forecasting accuracy over direct pattern mapping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
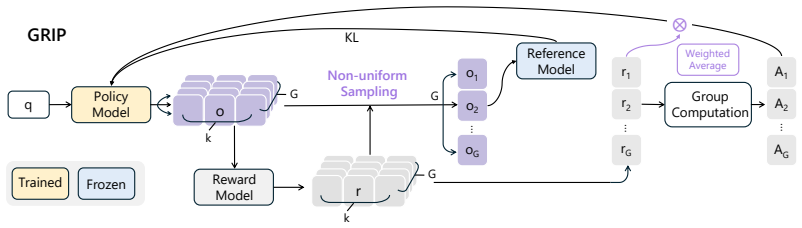
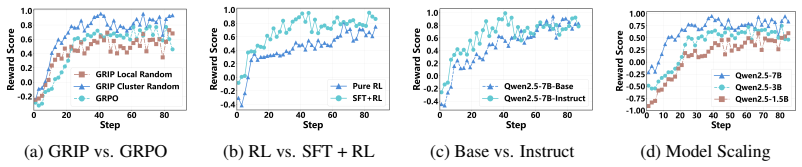
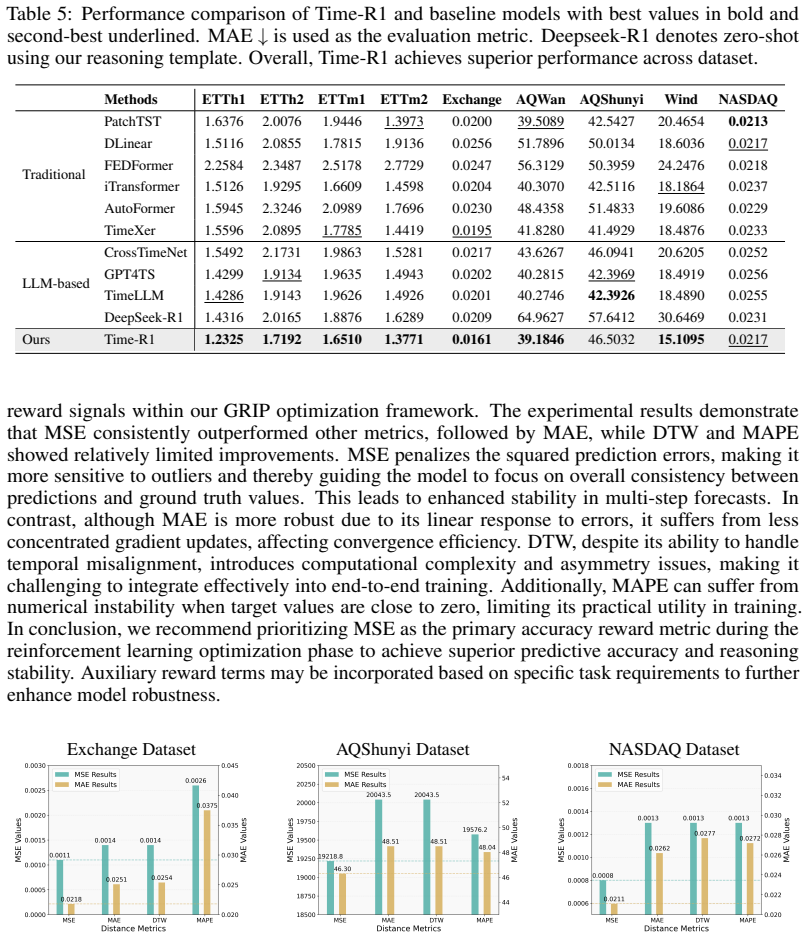
Time-R1 is a two-stage reinforcement fine-tuning framework in which supervised fine-tuning first warms up the model for time series tasks and reinforcement learning then optimizes it using a fine-grained multi-objective reward tailored to forecasting plus GRIP non-uniform sampling that encourages exploration of effective reasoning paths, yielding higher forecast accuracy on diverse datasets.
What carries the argument
The Time-R1 two-stage framework, where the second stage applies reinforcement learning guided by a multi-objective time-series reward and GRIP group-based sampling to discover and reinforce useful reasoning sequences.
If this is right
- Forecasting models gain accuracy when they produce and evaluate intermediate reasoning steps instead of mapping inputs directly to outputs.
- The reinforcement stage with the custom reward improves generalization beyond what supervised adaptation alone achieves.
- Non-uniform sampling during policy updates helps the model discover a wider range of effective reasoning strategies.
- Explicit reasoning paths make the forecasting process more transparent and potentially easier to debug or correct.
Where Pith is reading between the lines
- The same reinforcement recipe could be tested on other sequential prediction tasks such as demand planning or sensor anomaly detection to check whether slow reasoning helps there too.
- Extracting and inspecting the reasoning traces produced by the trained model might reveal which time-series features humans should prioritize in manual analysis.
- If the reward design proves stable, it could serve as a template for adding domain-specific objectives to language-model training on other scientific data types.
Load-bearing premise
The assumption that a specially designed multi-objective reward plus non-uniform sampling will reliably steer the model toward useful reasoning paths instead of unstable training or reward exploitation.
What would settle it
Training and testing the full Time-R1 pipeline on a fresh collection of time series datasets and finding no accuracy gain over strong non-reasoning baselines or over the supervised-fine-tuning stage alone would falsify the central claim.
Figures






read the original abstract
To advance time series forecasting (TSF), various methods have been proposed to improve prediction accuracy, evolving from statistical techniques to data-driven deep learning architectures. Despite their effectiveness, most existing methods still adhere to a fast thinking paradigm-relying on extracting historical patterns and mapping them to future values as their core modeling philosophy, lacking an explicit thinking process that incorporates intermediate time series reasoning. Meanwhile, emerging slow-thinking LLMs (e.g., OpenAI-o1) have shown remarkable multi-step reasoning capabilities, offering an alternative way to overcome these issues. However, prompt engineering alone presents several limitations - including high computational cost, privacy risks, and limited capacity for in-depth domain-specific time series reasoning. To address these limitations, a more promising approach is to train LLMs to develop slow thinking capabilities and acquire strong time series reasoning skills. For this purpose, we propose Time-R1, a two-stage reinforcement fine-tuning framework designed to enhance multi-step reasoning ability of LLMs for time series forecasting. Specifically, the first stage conducts supervised fine-tuning for warmup adaptation, while the second stage employs reinforcement learning to improve the model's generalization ability. Particularly, we design a fine-grained multi-objective reward specifically for time series forecasting, and then introduce GRIP (group-based relative importance for policy optimization), which leverages non-uniform sampling to further encourage and optimize the model's exploration of effective reasoning paths. Experiments demonstrate that Time-R1 significantly improves forecast performance across diverse datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Time-R1, a two-stage reinforcement fine-tuning framework for LLMs aimed at time series forecasting. Stage 1 performs supervised fine-tuning (SFT) as warmup adaptation; Stage 2 applies reinforcement learning with a custom fine-grained multi-objective reward function designed for time series and the GRIP (group-based relative importance for policy optimization) sampler that uses non-uniform sampling to promote exploration of effective reasoning paths. The central claim is that this slow-thinking approach yields significant forecast improvements over prior methods across diverse datasets.
Significance. If the empirical gains prove robust and causally attributable to the reasoning mechanism rather than extra training steps or dataset exposure, the work could meaningfully extend LLM-based methods into sequential forecasting by treating prediction as explicit multi-step reasoning. The multi-objective reward and GRIP sampler represent concrete technical contributions that, if validated, would be of interest to both the time-series and RL-for-LLMs communities.
major comments (3)
- [Experiments] Experiments section: no SFT-only baseline is reported on the identical LLM backbone and data regime. Without this control, observed gains cannot be confidently attributed to the RL stage, multi-objective reward, or GRIP rather than additional gradient updates or data exposure.
- [Method] Method (GRIP and reward definition): the paper does not provide an ablation replacing GRIP with uniform sampling or report training curves / seed-wise variance. These controls are required to substantiate that non-uniform sampling improves exploration of reasoning paths without introducing instability or reward hacking.
- [Experiments] Experiments: the multi-objective reward components (e.g., how accuracy, trend, and seasonality terms are weighted and normalized) are described at a high level only; concrete formulas or pseudocode are needed to assess whether the reward is well-specified for time-series data.
minor comments (2)
- [Abstract] Abstract: states 'significantly improves forecast performance' without any numerical deltas, dataset names, or baseline references, reducing its utility as a standalone summary.
- [Method] Notation: the distinction between the SFT warmup objective and the subsequent RL objective could be clarified with explicit loss equations in the method section.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive comments. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: no SFT-only baseline is reported on the identical LLM backbone and data regime. Without this control, observed gains cannot be confidently attributed to the RL stage, multi-objective reward, or GRIP rather than additional gradient updates or data exposure.
Authors: We agree that an SFT-only baseline on the identical LLM backbone and data regime is necessary to isolate the contribution of the RL stage. In the revised manuscript we will add this control experiment and report the corresponding forecasting results for direct comparison. revision: yes
-
Referee: [Method] Method (GRIP and reward definition): the paper does not provide an ablation replacing GRIP with uniform sampling or report training curves / seed-wise variance. These controls are required to substantiate that non-uniform sampling improves exploration of reasoning paths without introducing instability or reward hacking.
Authors: We acknowledge the value of these additional controls. We will include an ablation that replaces GRIP with uniform sampling and will report training curves together with performance statistics across multiple random seeds to demonstrate stability and the benefits of non-uniform sampling. revision: yes
-
Referee: [Experiments] Experiments: the multi-objective reward components (e.g., how accuracy, trend, and seasonality terms are weighted and normalized) are described at a high level only; concrete formulas or pseudocode are needed to assess whether the reward is well-specified for time-series data.
Authors: We thank the referee for this request for greater precision. In the revised version we will supply the explicit mathematical formulas for weighting and normalizing the accuracy, trend, and seasonality terms, along with pseudocode for the overall reward computation. revision: yes
Circularity Check
No circularity: empirical RL training procedure with independent experimental claims
full rationale
The paper presents Time-R1 as a two-stage empirical framework (SFT warmup followed by RL using a custom multi-objective reward and GRIP non-uniform sampling) to train LLMs for time-series reasoning. No equations, fitted parameters, or first-principles derivations are described that reduce reported performance gains to a self-definition, renamed input, or self-citation chain. The central claims rest on experimental results across datasets rather than any mathematical reduction or uniqueness theorem imported from prior author work. The method is self-contained as a training procedure whose validity is assessed externally via forecast metrics, with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we design a fine-grained multi-objective reward specifically for time series forecasting, and then introduce GRIP (group-based relative importance for policy optimization)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage reinforcement fine-tuning framework... SFT for warmup adaptation, while the second stage employs reinforcement learning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 8 Pith papers
-
Distribution-Aware Reward: Reinforcement Learning over Predictive Distributions for LLM Regression
Distribution-Aware Reward optimizes LLM regression by treating rollouts as empirical predictive distributions and rewarding marginal improvements in CRPS quality rather than point accuracy alone.
-
CastFlow: Learning Role-Specialized Agentic Workflows for Time Series Forecasting
CastFlow introduces a role-specialized agentic workflow with memory retrieval and multi-view toolkit for iterative ensemble time series forecasting, using two-stage SFT+RLVR training on a domain-specific LLM to outper...
-
LLaTiSA: Towards Difficulty-Stratified Time Series Reasoning from Visual Perception to Semantics
LLaTiSA is a vision-language model trained on a new 83k-sample hierarchical time series reasoning dataset that shows superior performance and out-of-distribution generalization on stratified TSR tasks.
-
STReasoner: Empowering LLMs for Spatio-Temporal Reasoning in Time Series via Spatial-Aware Reinforcement Learning
STReasoner uses S-GRPO reinforcement learning to let LLMs integrate time series, graphs, and text for spatio-temporal reasoning, delivering 17-135% accuracy gains over baselines on a new four-task benchmark at 0.004X ...
-
GeoDecider: A Coarse-to-Fine Agentic Workflow for Explainable Lithology Classification
GeoDecider introduces a coarse-to-fine agentic workflow using LLMs for explainable lithology classification from well logs, combining a base classifier, tool-augmented reasoning, and geological refinement to outperfor...
-
GeoMind: An Agentic Workflow for Lithology Classification with Reasoned Tool Invocation
GeoMind applies an agentic workflow with tool-augmented modules and process supervision to outperform static models on lithology classification from well logs while producing traceable decisions.
-
Reasoning through Verifiable Forecast Actions: Consistency-Grounded RL for Financial LLMs
StockR1 unifies LLM-based financial reasoning and time-series forecasting by emitting verifiable forecast actions that condition a decoder, optimized via consistency-grounded RL to improve accuracy on QA and prediction tasks.
-
TimeRFT: Stimulating Generalizable Time Series Forecasting for TSFMs via Reinforcement Finetuning
TimeRFT applies reinforcement learning with multi-faceted step-wise rewards and informative sample selection to improve generalization and accuracy in TSFM adaptation beyond supervised fine-tuning.
Reference graph
Works this paper leans on
-
[1]
A comprehensive survey of time series forecasting: Concepts, challenges, and future directions,
M. Cheng, Z. Liu, X. Tao, Q. Liu, J. Zhang, T. Pan, S. Zhang, P. He, X. Zhang, D. Wanget al., “A comprehensive survey of time series forecasting: Concepts, challenges, and future directions,” Authorea Preprints, 2025
work page 2025
-
[2]
A survey on table mining with large language models: Challenges, advancements and prospects,
M. Cheng, Q. Mao, Q. Liu, Y . Zhou, Y . Li, J. Wang, J. Lin, J. Cao, and E. Chen, “A survey on table mining with large language models: Challenges, advancements and prospects,” Authorea Preprints, 2025
work page 2025
-
[3]
Time series forecasting using a hybrid arima and neural network model,
G. P. Zhang, “Time series forecasting using a hybrid arima and neural network model,”Neuro- computing, vol. 50, pp. 159–175, 2003
work page 2003
-
[4]
R. Hyndman, A. B. Koehler, J. K. Ord, and R. D. Snyder, Forecasting with exponential smoothing: the state space approach. Springer Science & Business Media, 2008
work page 2008
-
[5]
The theta model: a decomposition approach to forecasting,
V . Assimakopoulos and K. Nikolopoulos, “The theta model: a decomposition approach to forecasting,”International journal of forecasting, vol. 16, no. 4, pp. 521–530, 2000
work page 2000
-
[6]
Xgboost: A scalable tree boosting system,
T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” in Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016, pp. 785–794
work page 2016
-
[7]
Lightgbm: A highly efficient gradient boosting decision tree,
G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y . Liu, “Lightgbm: A highly efficient gradient boosting decision tree,” Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[8]
Instructime: Advancing time series classification with multimodal language modeling,
M. Cheng, Y . Chen, Q. Liu, Z. Liu, Y . Luo, and E. Chen, “Instructime: Advancing time series classification with multimodal language modeling,” in Proceedings of the Eighteenth ACM International Conference on Web Search and Data Mining, 2025, pp. 792–800
work page 2025
-
[9]
J. Wang, M. Cheng, Q. Mao, Q. Liu, F. Xu, X. Li, and E. Chen, “Tabletime: Reformulating time series classification as zero-shot table understanding via large language models,”arXiv preprint arXiv:2411.15737, 2024
-
[10]
Recurrent neural networks for time series forecasting: Current status and future directions,
H. Hewamalage, C. Bergmeir, and K. Bandara, “Recurrent neural networks for time series forecasting: Current status and future directions,” International Journal of Forecasting, vol. 37, no. 1, pp. 388–427, 2021
work page 2021
-
[11]
Deepar: Probabilistic forecasting with autoregressive recurrent networks,
D. Salinas, V . Flunkert, J. Gasthaus, and T. Januschowski, “Deepar: Probabilistic forecasting with autoregressive recurrent networks,”International journal of forecasting, vol. 36, no. 3, pp. 1181–1191, 2020
work page 2020
-
[12]
P. Hewage, A. Behera, M. Trovati, E. Pereira, M. Ghahremani, F. Palmieri, and Y . Liu, “Temporal convolutional neural (tcn) network for an effective weather forecasting using time-series data from the local weather station,”Soft Computing, vol. 24, pp. 16 453–16 482, 2020
work page 2020
-
[13]
Convtimenet: A deep hierarchical fully convolutional model for multivariate time series analysis,
M. Cheng, J. Yang, T. Pan, Q. Liu, Z. Li, and S. Wang, “Convtimenet: A deep hierarchical fully convolutional model for multivariate time series analysis,” inCompanion Proceedings of the ACM on Web Conference 2025, 2025, pp. 171–180
work page 2025
-
[14]
Timemae: Self-supervised rep- resentations of time series with decoupled masked autoen- coders
M. Cheng, Q. Liu, Z. Liu, H. Zhang, R. Zhang, and E. Chen, “Timemae: Self- supervised representations of time series with decoupled masked autoencoders,” arXiv preprint arXiv:2303.00320, 2023
-
[15]
Can slow-thinking llms reason over time? empirical studies in time series forecasting,
J. Wang, M. Cheng, and Q. Liu, “Can slow-thinking llms reason over time? empirical studies in time series forecasting,”arXiv preprint arXiv:2505.24511, 2025
-
[16]
H. Liu, Z. Zhao, S. Li, and B. A. Prakash, “Evaluating system 1 vs. 2 reasoning approaches for zero-shot time series forecasting: A benchmark and insights,” arXiv preprint arXiv:2503.01895, 2025
-
[17]
Generative pretrained hierarchical transformer for time series forecasting,
Z. Liu, J. Yang, M. Cheng, Y . Luo, and Z. Li, “Generative pretrained hierarchical transformer for time series forecasting,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 2003–2013. 11
work page 2024
-
[18]
Llm4ts: Two-stage fine-tuning for time-series forecast- ing with pre-trained llms,
C. Chang, W.-C. Peng, and T.-F. Chen, “Llm4ts: Two-stage fine-tuning for time-series forecast- ing with pre-trained llms,”CoRR, 2023
work page 2023
-
[19]
Align and fine-tune: Enhancing llms for time-series forecasting,
C. Chang, W.-Y . Wang, W.-C. Peng, T.-F. Chen, and S. Samtani, “Align and fine-tune: Enhancing llms for time-series forecasting,” in NeurIPS Workshop on Time Series in the Age of Large Models, 2024
work page 2024
-
[20]
Calf: Aligning llms for time series forecasting via cross-modal fine-tuning,
P. Liu, H. Guo, T. Dai, N. Li, J. Bao, X. Ren, Y . Jiang, and S.-T. Xia, “Calf: Aligning llms for time series forecasting via cross-modal fine-tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 18, 2025, pp. 18 915–18 923
work page 2025
-
[22]
Large language models are zero-shot time series forecasters,
N. Gruver, M. Finzi, S. Qiu, and A. G. Wilson, “Large language models are zero-shot time series forecasters,”Advances in Neural Information Processing Systems, vol. 36, pp. 19 622–19 635, 2023
work page 2023
-
[23]
Time-ffm: Towards lm-empowered federated foundation model for time series forecasting,
Q. Liu, X. Liu, C. Liu, Q. Wen, and Y . Liang, “Time-ffm: Towards lm-empowered federated foundation model for time series forecasting,”arXiv preprint arXiv:2405.14252, 2024
-
[24]
Forecastpfn: Synthetically- trained zero-shot forecasting,
S. Dooley, G. S. Khurana, C. Mohapatra, S. V . Naidu, and C. White, “Forecastpfn: Synthetically- trained zero-shot forecasting,” Advances in Neural Information Processing Systems, vol. 36, pp. 2403–2426, 2023
work page 2023
-
[25]
Are language models actually useful for time series forecasting?
M. Tan, M. Merrill, V . Gupta, T. Althoff, and T. Hartvigsen, “Are language models actually useful for time series forecasting?” Advances in Neural Information Processing Systems, vol. 37, pp. 60 162–60 191, 2024
work page 2024
-
[27]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
M. Jin, S. Wang, L. Ma, Z. Chu, J. Y . Zhang, X. Shi, P.-Y . Chen, Y . Liang, Y .-F. Li, S. Panet al., “Time-llm: Time series forecasting by reprogramming large language models,”arXiv preprint arXiv:2310.01728, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Position: Empowering time series reasoning with multimodal llms,
Y . Kong, Y . Yang, S. Wang, C. Liu, Y . Liang, M. Jin, S. Zohren, D. Pei, Y . Liu, and Q. Wen, “Position: Empowering time series reasoning with multimodal llms,”arXiv preprint arXiv:2502.01477, 2025
-
[29]
Openai o1 models - FAQ [ChatGPT enterprise and edu],
OpenAI, “Openai o1 models - FAQ [ChatGPT enterprise and edu],” 2025, ac- cessed 23 January 2025. [Online]. Available: https://help.openai.com/en/articles/ 9855712-openai-o1-models-faq-chatgptenterprise-and-edu
work page 2025
-
[30]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song et al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Mean absolute percentage error for regression models,
A. De Myttenaere, B. Golden, B. Le Grand, and F. Rossi, “Mean absolute percentage error for regression models,”Neurocomputing, vol. 192, pp. 38–48, 2016
work page 2016
-
[32]
Informer: Beyond efficient transformer for long sequence time-series forecasting,
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang, “Informer: Beyond efficient transformer for long sequence time-series forecasting,” in Proceedings of the AAAI conference on artificial intelligence, vol. 35, no. 12, 2021, pp. 11 106–11 115
work page 2021
-
[33]
Modeling long-and short-term temporal patterns with deep neural networks,
G. Lai, W.-C. Chang, Y . Yang, and H. Liu, “Modeling long-and short-term temporal patterns with deep neural networks,” inThe 41st international ACM SIGIR conference on research & development in information retrieval, 2018, pp. 95–104
work page 2018
-
[34]
Cautionary tales on air-quality improvement in beijing,
S. Zhang, B. Guo, A. Dong, J. He, Z. Xu, and S. X. Chen, “Cautionary tales on air-quality improvement in beijing,” Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 473, no. 2205, p. 20170457, 2017. 12
work page 2017
-
[35]
Temporal relational ranking for stock prediction,
F. Feng, X. He, X. Wang, C. Luo, Y . Liu, and T.-S. Chua, “Temporal relational ranking for stock prediction,”ACM Transactions on Information Systems (TOIS), vol. 37, no. 2, pp. 1–30, 2019
work page 2019
-
[36]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A time series is worth 64 words: Long-term forecasting with transformers,”arXiv preprint arXiv:2211.14730, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Are transformers effective for time series forecasting?
A. Zeng, M. Chen, L. Zhang, and Q. Xu, “Are transformers effective for time series forecasting?” in Proceedings of the AAAI conference on artificial intelligence , vol. 37, no. 9, 2023, pp. 11 121–11 128
work page 2023
-
[38]
Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting,
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin, “Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting,” in International conference on machine learning. PMLR, 2022, pp. 27 268–27 286
work page 2022
-
[39]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “itransformer: Inverted transformers are effective for time series forecasting,”arXiv preprint arXiv:2310.06625, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Autoformer: Decomposition transformers with auto- correlation for long-term series forecasting,
H. Wu, J. Xu, J. Wang, and M. Long, “Autoformer: Decomposition transformers with auto- correlation for long-term series forecasting,”Advances in neural information processing systems, vol. 34, pp. 22 419–22 430, 2021
work page 2021
-
[41]
Timexer: Empowering transformers for time series fore- casting with exogenous variables,
Y . Wang, H. Wu, J. Dong, G. Qin, H. Zhang, Y . Liu, Y . Qiu, J. Wang, and M. Long, “Timexer: Empowering transformers for time series forecasting with exogenous variables,”arXiv preprint arXiv:2402.19072, 2024
-
[42]
Cross-domain pre-training with language models for transferable time series representations,
M. Cheng, X. Tao, Q. Liu, H. Zhang, Y . Chen, and D. Lian, “Cross-domain pre-training with language models for transferable time series representations,” in Proceedings of the Eighteenth ACM International Conference on Web Search and Data Mining, 2025, pp. 175–183
work page 2025
-
[43]
One fits all: Power general time series analysis by pretrained lm,
T. Zhou, P. Niu, L. Sun, R. Jin et al., “One fits all: Power general time series analysis by pretrained lm,” Advances in neural information processing systems, vol. 36, pp. 43 322–43 355, 2023
work page 2023
-
[44]
HybridFlow: A Flexible and Efficient RLHF Framework
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu, “Hybrid- flow: A flexible and efficient rlhf framework,”arXiv preprint arXiv:2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Some recent advances in forecasting and control,
G. E. Box and G. M. Jenkins, “Some recent advances in forecasting and control,”Journal of the Royal Statistical Society. Series C (Applied Statistics), vol. 17, no. 2, pp. 91–109, 1968
work page 1968
-
[46]
Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting,
S. Li, X. Jin, Y . Xuan, X. Zhou, W. Chen, Y .-X. Wang, and X. Yan, “Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting,” Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[47]
Q. Wen, Z. Zhang, Y . Li, and L. Sun, “Fast robuststl: Efficient and robust seasonal-trend decomposition for time series with complex patterns,” inProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020, pp. 2203–2213
work page 2020
-
[48]
Film: Frequency improved legendre memory model for long-term time series forecasting,
T. Zhou, Z. Ma, Q. Wen, L. Sun, T. Yao, W. Yin, R. Jin et al., “Film: Frequency improved legendre memory model for long-term time series forecasting,” Advances in neural information processing systems, vol. 35, pp. 12 677–12 690, 2022
work page 2022
-
[49]
Y . Zhang and J. Yan, “Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting,” in The eleventh international conference on learning representations, 2023
work page 2023
-
[50]
X. Zhang, R. R. Chowdhury, R. K. Gupta, and J. Shang, “Large language models for time series: A survey,”arXiv preprint arXiv:2402.01801, 2024
-
[51]
2024, arXiv e-prints, arXiv:2402.03182, 10.48550/arXiv.2402.03182
Y . Jiang, Z. Pan, X. Zhang, S. Garg, A. Schneider, Y . Nevmyvaka, and D. Song, “Empowering time series analysis with large language models: A survey,”arXiv preprint arXiv:2402.03182, 2024
-
[52]
Position: What can large language models tell us about time series analysis,
M. Jin, Y . Zhang, W. Chen, K. Zhang, Y . Liang, B. Yang, J. Wang, S. Pan, and Q. Wen, “Position: What can large language models tell us about time series analysis,” inForty-first International Conference on Machine Learning, 2024. 13
work page 2024
-
[53]
Lstprompt: Large language models as zero-shot time series forecasters by long-short-term prompting,
H. Liu, Z. Zhao, J. Wang, H. Kamarthi, and B. A. Prakash, “Lstprompt: Large language models as zero-shot time series forecasters by long-short-term prompting,” arXiv preprint arXiv:2402.16132, 2024
-
[54]
Time series forecasting with llms: Understanding and enhancing model capabilities,
H. Tang, C. Zhang, M. Jin, Q. Yu, Z. Wang, X. Jin, Y . Zhang, and M. Du, “Time series forecasting with llms: Understanding and enhancing model capabilities,” ACM SIGKDD Explorations Newsletter, vol. 26, no. 2, pp. 109–118, 2025
work page 2025
-
[55]
Reinforcement learning: A survey,
L. P. Kaelbling, M. L. Littman, and A. W. Moore, “Reinforcement learning: A survey,”Journal of artificial intelligence research, vol. 4, pp. 237–285, 1996
work page 1996
-
[56]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
work page 2022
-
[57]
A survey of reinforcement learning from human feedback.arXiv preprint arXiv:2312.14925,
T. Kaufmann, P. Weng, V . Bengs, and E. Hüllermeier, “A survey of reinforcement learning from human feedback,”arXiv preprint arXiv:2312.14925, vol. 10, 2023
-
[58]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Advances in Neural Information Processing Systems, vol. 36, pp. 53 728–53 741, 2023
work page 2023
-
[59]
Simpo: Simple preference optimization with a reference-free reward,
Y . Meng, M. Xia, and D. Chen, “Simpo: Simple preference optimization with a reference-free reward,”Advances in Neural Information Processing Systems, vol. 37, pp. 124 198–124 235, 2024
work page 2024
-
[60]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu et al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,” arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
A. Ahmadian, C. Cremer, M. Gallé, M. Fadaee, J. Kreutzer, O. Pietquin, A. Üstün, and S. Hooker, “Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms,”arXiv preprint arXiv:2402.14740, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Survey on large language model-enhanced reinforcement learning: Concept, taxonomy, and methods,
Y . Cao, H. Zhao, Y . Cheng, T. Shu, Y . Chen, G. Liu, G. Liang, J. Zhao, J. Yan, and Y . Li, “Survey on large language model-enhanced reinforcement learning: Concept, taxonomy, and methods,”IEEE Transactions on Neural Networks and Learning Systems, 2024
work page 2024
-
[63]
Z. Lin, M. Lin, Y . Xie, and R. Ji, “Cppo: Accelerating the training of group relative policy optimization-based reasoning models,”arXiv preprint arXiv:2503.22342, 2025
-
[64]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
J. Hu, Y . Zhang, Q. Han, D. Jiang, X. Zhang, and H.-Y . Shum, “Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model,”arXiv preprint arXiv:2503.24290, 2025. 14 Appendix A Related Work A.1 TimeSeries Forcasting Time series forecasting has evolved from classical models like ARIMA, effective under ideal condi- ti...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Advantage, which assesses the value of a completion in improving expected returns through the advantage function. A higher advantage indicates stronger reward alignment, making the completion more influential in guiding policy updates
-
[66]
Probability ratio, wich compares the likelihood of an action under the current policy πθ to that under the old policy πθold. It amplifies actions favored by the new policy and suppresses those preferred by the old one, guiding the policy toward higher rewards. A higher ratio signifies greater confidence in the action, influencing the optimization process ...
-
[67]
KL divergence, which measures the deviation of the current policy from the reference model. It enforces stability during training by penalizing excessive changes, but does not directly contribute to reasoning pattern formation
-
[68]
Policy model gradient, which indicates the direction of parameter updates. Previous research [64] has shown that removing the KL divergence constraint does not significantly affect the model’s reasoning performance, as the core learning signal primarily comes from the advantage term aligned with rewards. Furthermore, we decompose the core expression for p...
-
[69]
Basic Patterns and Trends in the Data: The HUFL dataset spans 96 hours from July 1 to July 4, 2016, with values ranging from 4.2 to 12.7. Daily maximums increase from 7.4 to 12.7 over four days, showing an upward trend despite varying peak times
work page 2016
-
[70]
Morning peaks occur between 6–8 AM, midday peaks around 11 AM–noon, both increasing daily
Observed Seasonality or Daily Fluctuations: Daily patterns show lower values at night (00:00–5:00) and higher values during mornings and midday. Morning peaks occur between 6–8 AM, midday peaks around 11 AM–noon, both increasing daily. Evening rises (6–10 PM) also show growth but with some irregularity in peak timing and magnitude
-
[71]
Forecasting Methods and Assumptions Made: Forecasting assumes daily seasonality and a slowing upward trend based on observed data. Using July 4th as a base, each subsequent day’s hourly values are incremented by small amounts (0.1–0.3 or 2–5%), more for peak hours. Trend may plateau after recent highs; alternative patterns like reversals were considered b...
-
[72]
Potential Limitations or Uncertainties: Only four days of data limit identification of long- term trends or weekly cycles. Trend continuation is speculative, external factors are unknown, and inherent variability reduces forecast accuracy. Conclusion: The forecast extends observed daily seasonality and recent upward trends, incre- mentally adjusting July ...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.