Recognition: unknown
TimeRFT: Stimulating Generalizable Time Series Forecasting for TSFMs via Reinforcement Finetuning
Pith reviewed 2026-05-10 07:11 UTC · model grok-4.3
The pith
TimeRFT uses reinforcement finetuning with step-wise rewards and difficulty-based sample selection to improve time series foundation model adaptation beyond supervised fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
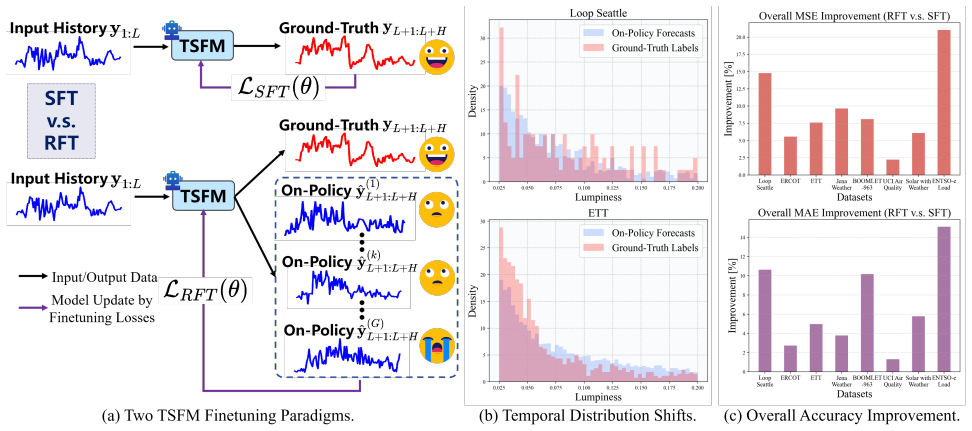
The TimeRFT paradigm replaces supervised fine-tuning of time series foundation models with two reinforcement-learning components: a forecasting quality-based temporal reward that scores the contribution of every prediction step to overall accuracy and a forecasting difficulty-based data selection strategy that surfaces time series carrying transferable predictive patterns.
What carries the argument
Forecasting quality-based temporal reward mechanism together with difficulty-based data selection strategy inside the reinforcement finetuning loop.
If this is right
- Forecast accuracy rises on diverse real-world tasks even when training data is limited.
- Models maintain performance when future data deviates from historical statistics.
- Adaptation works reliably across high-data and low-data forecasting regimes.
- Overfitting to recent training windows is reduced without extra regularization terms.
Where Pith is reading between the lines
- The same reward-and-selection logic could be tested on other sequential foundation models such as those for audio or text.
- If the method scales, practitioners might need fewer labeled examples per new forecasting domain.
- Online versions could allow continuous model updates as new observations arrive without full retraining.
Load-bearing premise
The temporal reward and difficulty selection rules will improve robustness to distribution shifts without introducing their own biases or demanding heavy per-task tuning.
What would settle it
A controlled experiment on a dataset with documented abrupt distribution shift where TimeRFT accuracy equals or falls below standard supervised fine-tuning after the same number of training steps.
Figures



read the original abstract
Time Series Foundation Models (TSFMs) advance generalization and data efficiency in time series forecasting by unified large-scale pretraining. But TSFMs remain lacking when adapting to specific downstream forecasting tasks for two reasons. First, the non-stationary and uncertain nature of time series data lead to inevitable temporal distribution shifts between historical training and future testing data, while current Supervised FineTuning (SFT)-based methods are prone to overfitting and may degrade generalization. Second, training data availability varies across forecasting tasks, requiring TSFMs to generalize well under diverse data regimes. To address these challenges, we introduce the Time series Reinforcement Finetuning (TimeRFT) paradigm for TSFM downstream adaptation, which consists of two task-specific training recipes: i) A forecasting quality-based temporal reward mechanism that conducts a multi-faceted evaluation of the contribution of each prediction step to overall forecasting accuracy. ii) A forecasting difficulty-based data selection strategy to identify time series samples with generalizable predictive patterns and informative training signals. Extensive experiments demonstrate TimeRFT can consistently outperform SFT-based adaptation methods across various real-world forecasting tasks and training data regimes, enhancing prediction accuracy and generalization against unforeseen distribution shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Supervised FineTuning (SFT) of Time Series Foundation Models (TSFMs) is prone to overfitting under temporal distribution shifts and varying data regimes. It proposes TimeRFT, a reinforcement finetuning paradigm consisting of (i) a forecasting quality-based temporal reward mechanism that performs multi-faceted evaluation of each prediction step's contribution to accuracy and (ii) a difficulty-based data selection strategy that identifies samples with generalizable patterns. The central empirical claim is that TimeRFT consistently outperforms SFT-based adaptation across real-world forecasting tasks and training data regimes, improving accuracy and robustness to unforeseen shifts.
Significance. If the empirical results hold under rigorous scrutiny, the work could meaningfully advance TSFM adaptation by replacing brittle SFT with an RL-based recipe that directly targets temporal non-stationarity. The two task-specific mechanisms are logically motivated from SFT limitations and represent a concrete, reproducible direction for improving generalization in non-stationary forecasting; credit is due for framing the problem around both distribution shift and data-regime diversity.
major comments (1)
- [Experimental section] Experimental section (likely §4 or §5): The central claim of 'consistent outperformance' across tasks and regimes is load-bearing, yet the manuscript provides no details on the TSFM backbones, exact SFT baselines, forecasting metrics (MAE/MSE/etc.), number of runs, statistical significance tests, or how temporal distribution shifts were operationalized in the test sets. Without these, the strength of the evidence cannot be evaluated against the abstract's assertion.
minor comments (2)
- [Abstract] Abstract: The description of the two recipes is high-level; adding one sentence on whether the reward formulation or selection threshold involves any tunable hyperparameters would immediately clarify the generalization claim.
- [Method section] Method section: The temporal reward is described as 'multi-faceted' but the precise aggregation (e.g., weighting of accuracy, uncertainty, or step-wise contributions) is not shown; an equation or pseudocode would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential contribution of TimeRFT. We address the major comment below and will revise the manuscript to improve experimental transparency.
read point-by-point responses
-
Referee: [Experimental section] Experimental section (likely §4 or §5): The central claim of 'consistent outperformance' across tasks and regimes is load-bearing, yet the manuscript provides no details on the TSFM backbones, exact SFT baselines, forecasting metrics (MAE/MSE/etc.), number of runs, statistical significance tests, or how temporal distribution shifts were operationalized in the test sets. Without these, the strength of the evidence cannot be evaluated against the abstract's assertion.
Authors: We agree that the experimental section requires more explicit documentation to support rigorous evaluation of the central claims. In the revised manuscript we will expand the relevant subsections to specify the TSFM backbones used, the precise SFT baseline implementations, the forecasting metrics (MAE, MSE and any others), the number of independent runs, the statistical significance tests performed, and the exact procedure for operationalizing temporal distribution shifts via temporal train-test splits. These additions will be placed in the experimental setup and results sections. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents TimeRFT as an empirical RL-based adaptation method for TSFMs, consisting of a forecasting quality-based temporal reward and a difficulty-based data selection strategy. No equations, derivations, or mathematical claims appear in the abstract or description. Claims of outperformance rest on experimental comparisons to SFT baselines across tasks and regimes, without any reduction to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The central argument flows from stated SFT limitations to the proposed recipes without internal circularity or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Maddix, Hao Wang, Michael W
Abdul Fatir Ansari, Lorenzo Stella, Ali Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebas- tian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Bernie Wang. 2024. Chronos: Learning t...
2024
-
[3]
Andreas Auer, Patrick Podest, Daniel Klotz, Sebastian Böck, Günter Klambauer, and Sepp Hochreiter. 2025. TiRex: Zero-Shot Forecasting Across Long and Short Horizons. In1st ICML Workshop on Foundation Models for Structured Data
2025
-
[4]
Jialin Chen, Jan Eric Lenssen, Aosong Feng, Weihua Hu, Matthias Fey, Leandros Tassiulas, Jure Leskovec, and Rex Ying. 2024. From similarity to superiority: Channel clustering for time series forecasting.Advances in Neural Information Processing Systems37 (2024), 130635–130663
2024
-
[5]
Mouxiang Chen, Lefei Shen, Zhuo Li, Xiaoyun Joy Wang, Jianling Sun, and Chenghao Liu. 2025. VisionTS: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters. InForty-second International Conference on Machine Learning
2025
-
[6]
Yunyao Cheng, Peng Chen, Chenjuan Guo, Kai Zhao, Qingsong Wen, Bin Yang, and Christian S Jensen. 2023. Weakly Guided Adaptation for Robust Time Series Forecasting.Proceedings of the VLDB Endowment17, 4 (2023), 766–779. 12
2023
-
[7]
Yunyao Cheng, Chenjuan Guo, Bin Yang, Haomin Yu, Kai Zhao, and Christian S Jensen. 2024. A Memory Guided Transformer for Time Series Forecasting. Proceedings of the VLDB Endowment18, 2 (2024), 239–252
2024
-
[8]
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al . 2025. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456(2025)
work page internal anchor Pith review arXiv 2025
-
[9]
Yue Cui, Kai Zheng, Dingshan Cui, Jiandong Xie, Liwei Deng, Feiteng Huang, and Xiaofang Zhou. 2021. METRO: a generic graph neural network framework for multivariate time series forecasting.Proceedings of the VLDB Endowment15, 2 (2021), 224–236
2021
-
[10]
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. 2024. A decoder- only foundation model for time-series forecasting. InInternational Conference on Machine Learning. PMLR, 10148–10167
2024
-
[11]
Vijay Ekambaram, Arindam Jati, Pankaj Dayama, Sumanta Mukherjee, Nam Nguyen, Wesley M Gifford, Chandra Reddy, and Jayant Kalagnanam. 2024. Tiny time mixers (ttms): Fast pre-trained models for enhanced zero/few-shot fore- casting of multivariate time series.Advances in Neural Information Processing Systems37 (2024), 74147–74181
2024
-
[12]
Christos Faloutsos, Jan Gasthaus, Tim Januschowski, and Yuyang Wang. 2018. Forecasting Big Time Series: Old and New.Proceedings of the VLDB Endowment 11, 12 (2018)
2018
-
[13]
Yisong Fu, Zezhi Shao, Chengqing Yu, Yujie Li, Zhulin An, Cheems Wang, Yongjun Xu, and Fei Wang. 2025. Selective Learning for Deep Time Series Forecasting. InThe Thirty-ninth Annual Conference on Neural Information Pro- cessing Systems
2025
- [14]
-
[15]
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. 2024. MOMENT: A Family of Open Time-series Foundation Models. InInternational Conference on Machine Learning. PMLR, 16115–16152
2024
-
[16]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al . 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review arXiv 2024
-
[18]
Divij Gupta, Anubhav Bhatti, and Surajsinh Parmar. 2024. Beyond LoRA: Ex- ploring Efficient Fine-Tuning Techniques for Time Series Foundational Models. InNeurIPS Workshop on Time Series in the Age of Large Models
2024
-
[19]
Alexander Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Nalm- pantis, Jane Dwivedi-Yu, Eric Hambro, Sainbayar Sukhbaatar, and Roberta Raileanu. 2024. Teaching Large Language Models to Reason with Reinforcement Learning. InAI for Math Workshop @ ICML 2024
2024
-
[20]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review arXiv 2024
-
[21]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. 2024. Openai o1 system card.arXiv preprint arXiv:2412.16720(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sor- doni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. 2025. VinePPO: Refining Credit Assignment in RL Training of LLMs. InForty-second International Confer- ence on Machine Learning
2025
-
[23]
Taesung Kim, Jinhee Kim, Yunwon Tae, Cheonbok Park, Jang-Ho Choi, and Jaegul Choo. 2022. Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift. InInternational Conference on Learning Representations
2022
-
[24]
Dilfira Kudrat, Zongxia Xie, Yanru Sun, Tianyu Jia, and Qinghua Hu. 2025. Patch- wise Structural Loss for Time Series Forecasting. InInternational Conference on Machine Learning. PMLR, 31841–31859
2025
-
[25]
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. 2024. Tulu 3: Pushing frontiers in open language model post-training. arXiv preprint arXiv:2411.15124(2024)
work page internal anchor Pith review arXiv 2024
-
[26]
Hao Li, Bowen Deng, Chang Xu, ZhiYuan Feng, Viktor Schlegel, Yu-Hao Huang, Yizheng Sun, Jingyuan Sun, Kailai Yang, Yiyao Yu, and Jiang Bian. 2025. MIRA: Medical Time Series Foundation Model for Real-World Health Data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[27]
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, et al. 2025. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674 (2025)
work page internal anchor Pith review arXiv 2025
-
[28]
Ruikun Li, Dai Shi, Ye Xiao, and Junbin Gao. 2025. UFGTime: Mining Intertwined Dependencies in Multivariate Time Series via an Efficient Pure Graph Approach. Proceedings of the VLDB Endowment18, 9 (2025), 3175–3188
2025
- [29]
-
[30]
Yuxin Li, Wenchao Chen, Xinyue Hu, Bo Chen, Baolin Sun, and Mingyuan Zhou
-
[31]
InThe Twelfth International Conference on Learning Representations
Transformer-modulated diffusion models for probabilistic multivariate time series forecasting. InThe Twelfth International Conference on Learning Representations
-
[32]
Zhe Li, Xiangfei Qiu, Peng Chen, Yihang Wang, Hanyin Cheng, Yang Shu, Jilin Hu, Chenjuan Guo, Aoying Zhou, Christian S Jensen, et al. 2025. Tsfm-bench: A comprehensive and unified benchmark of foundation models for time series forecasting. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5595–5606
2025
-
[33]
Yuxuan Liang, Haomin Wen, Yuqi Nie, Yushan Jiang, Ming Jin, Dongjin Song, Shirui Pan, and Qingsong Wen. 2024. Foundation models for time series analysis: A tutorial and survey. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining. 6555–6565
2024
-
[34]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations
2023
- [35]
-
[36]
Haoxin Liu, Harshavardhan Kamarthi, Lingkai Kong, Zhiyuan Zhao, Chao Zhang, and B Aditya Prakash. 2024. Time-Series Forecasting for Out-of-Distribution Generalization Using Invariant Learning. InInternational Conference on Machine Learning. PMLR, 31312–31325
2024
-
[37]
Jijia Liu, Feng Gao, Bingwen Wei, Xinlei Chen, Qingmin Liao, Yi Wu, Chao Yu, and Yu Wang. 2025. What Can RL Bring to VLA Generalization? An Empirical Study. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[38]
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al
-
[39]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization.arXiv preprint arXiv:2601.05242(2026)
work page internal anchor Pith review arXiv 2026
-
[40]
Xu Liu, Taha Aksu, Juncheng Liu, Qingsong Wen, Yuxuan Liang, Caiming Xiong, Silvio Savarese, Doyen Sahoo, Junnan Li, and Chenghao Liu. 2025. Empowering Time Series Analysis with Synthetic Data: A Survey and Outlook in the Era of Foundation Models.arXiv preprint arXiv:2503.11411(2025)
-
[41]
Xu Liu, Juncheng Liu, Gerald Woo, Taha Aksu, Yuxuan Liang, Roger Zimmer- mann, Chenghao Liu, Junnan Li, Silvio Savarese, Caiming Xiong, et al . 2025. Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts. InInternational Conference on Machine Learning. PMLR, 38940–38962
2025
-
[42]
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. 2024. iTransformer: Inverted Transformers Are Effective for Time Series Forecasting. InThe Twelfth International Conference on Learning Representations
2024
-
[43]
Yong Liu, Guo Qin, Zhiyuan Shi, Zhi Chen, Caiyin Yang, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. 2025. Sundial: A Family of Highly Capable Time Series Foundation Models. InForty-second International Conference on Machine Learning
2025
-
[44]
Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. 2024. Timer: Generative Pre-trained Transformers Are Large Time Series Models. InInternational Conference on Machine Learning. PMLR, 32369–32399
2024
-
[45]
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. 2025. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783(2025)
work page Pith review arXiv 2025
-
[46]
Yucong Luo, Yitong Zhou, Mingyue Cheng, Jiahao Wang, Daoyu Wang, Tingyue Pan, and Jintao Zhang. 2025. Time series forecasting as reasoning: A slow- thinking approach with reinforced llms.arXiv preprint arXiv:2506.10630(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tür, and Hao Peng. 2025. Rein- forcement Learning Finetunes Small Subnetworks in Large Language Models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[48]
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. 2023. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. In The Eleventh International Conference on Learning Representations
2023
-
[49]
Wenzhe Niu, Zongxia Xie, Yanru Sun, Wei He, Man Xu, and Chao Hao. 2025. LangTime: A Language-Guided Unified Model for Time Series Forecasting with Proximal Policy Optimization. InInternational Conference on Machine Learning. PMLR, 46712–46734
2025
-
[50]
Zhongzheng Qiao, Chenghao Liu, Yiming Zhang, Ming Jin, Quang Pham, Qing- song Wen, Ponnuthurai Nagaratnam Suganthan, Xudong Jiang, and Savitha Ramasamy. 2025. Multi-Scale Finetuning for Encoder-based Time Series Foun- dation Models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[51]
Xiangfei Qiu, Xingjian Wu, Hanyin Cheng, Xvyuan Liu, Chenjuan Guo, Jilin Hu, and Bin Yang. 2025. DBLoss: Decomposition-based Loss Function for Time 13 Series Forecasting. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[52]
Xiangfei Qiu, Xingjian Wu, Yan Lin, Chenjuan Guo, Jilin Hu, and Bin Yang
-
[53]
In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Duet: Dual clustering enhanced multivariate time series forecasting. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 1185–1196
-
[54]
Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Arian Khorasani, George Adamopoulos, Rishika Bhagwatkar, Marin Biloš, Hena Ghonia, Nadhir Hassen, Anderson Schneider, Sahil Garg, Alexandre Drouin, Nicolas Chapados, Yuriy Nevmyvaka, and Irina Rish. 2023. Lag-Llama: Towards Foundation Models for Time Series Forecasting. InR0-FoMo:Robustness of Few-shot an...
2023
-
[55]
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. 2025. Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning. In The Thirteenth International Conference on Learning Representations
2025
-
[56]
Zezhi Shao, Yujie Li, Fei Wang, Chengqing Yu, Yisong Fu, Tangwen Qian, Bin Xu, Boyu Diao, Yongjun Xu, and Xueqi Cheng. 2025. Blast: Balanced sampling time series corpus for universal forecasting models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 2502–2513
2025
-
[57]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [58]
- [59]
-
[60]
Xiaoming Shi, Shiyu Wang, Yuqi Nie, Dianqi Li, Zhou Ye, Qingsong Wen, and Ming Jin. 2025. Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts. InThe Thirteenth International Conference on Learning Repre- sentations
2025
-
[61]
Yifan Sun, Jingyan Shen, Yibin Wang, Tianyu Chen, Zhendong Wang, Mingyuan Zhou, and Huan Zhang. 2025. Improving Data Efficiency for LLM Reinforce- ment Fine-tuning Through Difficulty-targeted Online Data Selection and Rollout Replay. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[62]
1998.Reinforcement learning: An introduction
Richard S Sutton, Andrew G Barto, et al . 1998.Reinforcement learning: An introduction. Vol. 1. MIT press Cambridge
1998
- [63]
-
[64]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. 2025. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599(2025)
work page internal anchor Pith review arXiv 2025
-
[65]
Luong Trung, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li
-
[66]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Reft: Reasoning with reinforced fine-tuning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7601–7614
-
[67]
Shihao Tu, Yupeng Zhang, Jing Zhang, Zhendong Fu, Yin Zhang, and Yang Yang
-
[68]
Powerpm: Foundation model for power systems.Advances in Neural Information Processing Systems37 (2024), 115233–115260
2024
-
[69]
Eric Wang, Licheng Pan, Yuan Lu, Zi Ciu Chan, Tianqiao Liu, Shuting He, Zhixuan Chu, Qingsong Wen, Haoxuan Li, and Zhouchen Lin. 2026. Quadratic Direct Forecast for Training Multi-Step Time-Series Forecast Models. InThe Fourteenth International Conference on Learning Representations
2026
-
[70]
Hao Wang, Lichen Pan, Yuan Shen, Zhichao Chen, Degui Yang, Yifei Yang, Sen Zhang, Xinggao Liu, Haoxuan Li, and Dacheng Tao. 2025. FreDF: Learning to Forecast in the Frequency Domain. InThe Thirteenth International Conference on Learning Representations
2025
-
[71]
Zhang, and JUN ZHOU
Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Y. Zhang, and JUN ZHOU. 2024. TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting. InThe Twelfth International Conference on Learning Representations
2024
-
[72]
Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Yong Liu, Chen Wang, Mingsheng Long, and Jianmin Wang. 2024. Deep time series models: A comprehensive survey and benchmark.arXiv preprint arXiv:2407.13278(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. 2024. Unified Training of Universal Time Series Forecasting Transformers. InInternational Conference on Machine Learning. PMLR, 53140– 53164
2024
-
[74]
Xingjian Wu, Xiangfei Qiu, Hanyin Cheng, Zhengyu Li, Jilin Hu, Chenjuan Guo, and Bin Yang. 2025. Enhancing Time Series Forecasting through Selective Rep- resentation Spaces: A Patch Perspective. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
- [75]
-
[76]
Zhe Xie, Zeyan Li, Xiao He, Longlong Xu, Xidao Wen, Tieying Zhang, Jianjun Chen, Rui Shi, and Dan Pei. 2025. ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning.Proceedings of the VLDB Endowment18, 8 (2025), 2385–2398
2025
-
[77]
Yixuan Even Xu, Yash Savani, Fei Fang, and J Zico Kolter. 2025. Not all rollouts are useful: Down-sampling rollouts in llm reinforcement learning.arXiv preprint arXiv:2504.13818(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. 2025. Learning to Reason under Off-Policy Guidance. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[79]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. 2024. Qwen2. 5- math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122(2024)
work page internal anchor Pith review arXiv 2024
-
[80]
Yuxuan Yang, Dalin Zhang, Yuxuan Liang, Hua Lu, Gang Chen, and Huan Li
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.