LingoLoop Attack: Trapping MLLMs via Linguistic Context and State Entrapment into Endless Loops
Pith reviewed 2026-05-19 09:15 UTC · model grok-4.3
The pith
LingoLoop traps MLLMs in endless loops by delaying end tokens with part-of-speech cues and limiting hidden states to force repetition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By first establishing that part-of-speech tags strongly affect the probability of emitting an end-of-sentence token, the authors construct a POS-Aware Delay Mechanism that shifts attention weights to postpone stopping. They then add a Generative Path Pruning Mechanism that caps the size of hidden states, steering the model into persistent repetitive sequences. Together these components trap the model in generative loops, driving it to its maximum length and, when that limit is lifted, producing up to 367 times more tokens than a clean input while causing a matching rise in energy use.
What carries the argument
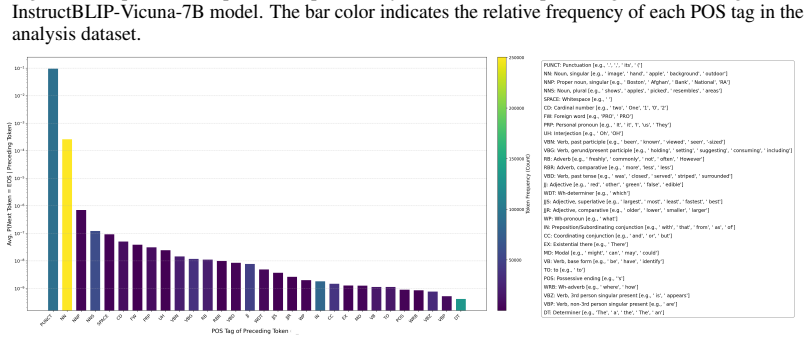
The POS-Aware Delay Mechanism adjusts attention weights using part-of-speech information to postpone EOS token generation, paired with the Generative Path Pruning Mechanism that restricts hidden-state magnitudes to sustain repetitive output loops.
Load-bearing premise
The part-of-speech tag of a token exerts a strong influence on the model's likelihood of producing an end-of-sentence token.
What would settle it
Measure whether altering the part-of-speech labels of prompt tokens changes the probability of EOS generation in the direction predicted by the delay mechanism, or whether removing the state-magnitude limit eliminates the sustained loops.
Figures





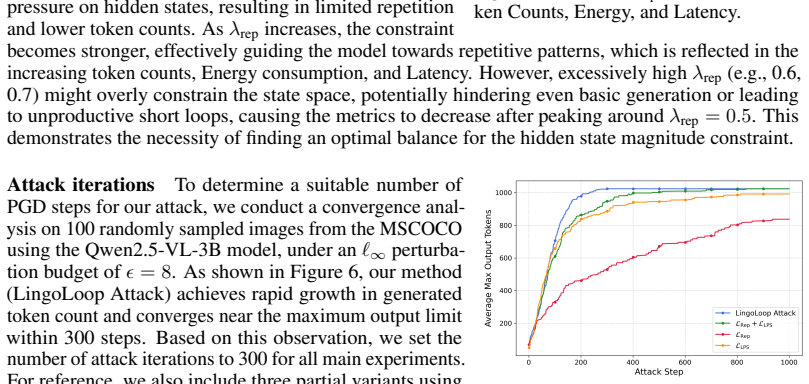








read the original abstract
Multimodal Large Language Models (MLLMs) have shown great promise but require substantial computational resources during inference. Attackers can exploit this by inducing excessive output, leading to resource exhaustion and service degradation. Prior energy-latency attacks aim to increase generation time by broadly shifting the output token distribution away from the EOS token, but they neglect the influence of token-level Part-of-Speech (POS) characteristics on EOS and sentence-level structural patterns on output counts, limiting their efficacy. To address this, we propose LingoLoop, an attack designed to induce MLLMs to generate excessively verbose and repetitive sequences. First, we find that the POS tag of a token strongly affects the likelihood of generating an EOS token. Based on this insight, we propose a POS-Aware Delay Mechanism to postpone EOS token generation by adjusting attention weights guided by POS information. Second, we identify that constraining output diversity to induce repetitive loops is effective for sustained generation. We introduce a Generative Path Pruning Mechanism that limits the magnitude of hidden states, encouraging the model to produce persistent loops. Extensive experiments on models like Qwen2.5-VL-3B demonstrate LingoLoop's powerful ability to trap them in generative loops; it consistently drives them to their generation limits and, when those limits are relaxed, can induce outputs with up to 367x more tokens than clean inputs, triggering a commensurate surge in energy consumption. These findings expose significant MLLMs' vulnerabilities, posing challenges for their reliable deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LingoLoop, an attack on MLLMs to induce excessive verbose and repetitive generation. It introduces a POS-Aware Delay Mechanism that adjusts attention weights based on the claim that POS tags strongly influence EOS token likelihood, and a Generative Path Pruning Mechanism that constrains hidden states to promote persistent loops. Experiments on Qwen2.5-VL-3B report up to 367x more output tokens than clean inputs when generation limits are relaxed, with corresponding energy increases.
Significance. If the empirical results hold under proper controls, the work identifies a concrete vulnerability in MLLM inference that could enable resource-exhaustion attacks, with direct implications for deployment reliability and energy costs. The reported token multiplier provides a quantifiable measure of attack potency.
major comments (2)
- [Abstract and §3] Abstract and §3 (POS-Aware Delay Mechanism): The premise that 'the POS tag of a token strongly affects the likelihood of generating an EOS token' is stated as an empirical finding but lacks any reported effect size, statistical test, correlation analysis, or ablation against simpler EOS-suppression baselines. This directly underpins the attention-weight adjustment rule and is load-bearing for the first component; without it the mechanism reduces to an unmotivated heuristic.
- [Experiments] Experiments section: The central claim of a 367x token multiplier on Qwen2.5-VL-3B is presented without baseline attack comparisons, multiple-model evaluation, statistical controls across runs, or variance reporting. This leaves the magnitude and robustness of the result only moderately supported.
minor comments (2)
- [§3.1] Clarify the precise mathematical form of the POS-guided attention adjustment (e.g., the scaling factor and how POS tags are mapped to weights) with an equation or pseudocode.
- [Experiments] Specify the exact generation-length limits used in the 'relaxed' setting and how they compare to default model configurations.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and constructive feedback on our paper. Their comments highlight important areas where we can improve the clarity and rigor of our presentation. We address each major comment below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (POS-Aware Delay Mechanism): The premise that 'the POS tag of a token strongly affects the likelihood of generating an EOS token' is stated as an empirical finding but lacks any reported effect size, statistical test, correlation analysis, or ablation against simpler EOS-suppression baselines. This directly underpins the attention-weight adjustment rule and is load-bearing for the first component; without it the mechanism reduces to an unmotivated heuristic.
Authors: We thank the referee for pointing this out. While our development process involved observing the influence of POS tags on EOS generation probabilities through targeted experiments, the submitted manuscript does not include the quantitative details such as effect sizes or statistical tests. To address this, we will revise the manuscript to include a dedicated analysis subsection under §3, presenting correlation coefficients, effect sizes, and an ablation study comparing our POS-aware approach to simpler EOS-suppression methods. This will provide stronger empirical grounding for the mechanism. revision: yes
-
Referee: [Experiments] Experiments section: The central claim of a 367x token multiplier on Qwen2.5-VL-3B is presented without baseline attack comparisons, multiple-model evaluation, statistical controls across runs, or variance reporting. This leaves the magnitude and robustness of the result only moderately supported.
Authors: We agree that additional experimental rigor would enhance the credibility of our results. The current evaluation demonstrates the attack on Qwen2.5-VL-3B to highlight its effectiveness in a practical setting. In the revision, we will incorporate baseline comparisons with prior energy-latency attacks, report results with standard deviations across multiple independent runs, and include statistical significance tests. We will also expand the discussion of model choice and generalizability. revision: partial
Circularity Check
No circularity; empirical observations drive mechanisms with independent experimental validation
full rationale
The paper's derivation consists of two empirical observations (POS-EOS correlation and hidden-state magnitude effects on repetition) followed by proposed mechanisms and extensive experimental results on models such as Qwen2.5-VL-3B. The 367x token multiplier and energy claims are reported outcomes of those experiments rather than quantities algebraically entailed by the mechanism definitions. No equations or steps reduce a claimed result to a fitted parameter or self-referential definition; the chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- POS-guided attention adjustment strength
axioms (1)
- domain assumption POS tag of a token strongly affects EOS generation probability
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
First, we find that the POS tag of a token strongly affects the likelihood of generating an EOS token. Based on this insight, we propose a POS-Aware Delay Mechanism to postpone EOS token generation by adjusting attention weights guided by POS information.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a Generative Path Pruning Mechanism that limits the magnitude of hidden states, encouraging the model to produce persistent loops.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Decoding by Perturbation: Mitigating MLLM Hallucinations via Dynamic Textual Perturbation
DeP mitigates MLLM hallucinations by dynamically perturbing text prompts to identify and reinforce stable visual evidence regions while counteracting language prior biases using attention variance and logit statistics.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Ming-Hsuan Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Natural Language Processing with Python
Steven Bird, Ewan Klein, and Edward Loper. Natural Language Processing with Python. O’Reilly, 2009
work page 2009
-
[3]
Nirschl, Laura Bravo-Sánchez, Alejandro Lozano, Sanket Rajan Gupte, Jesus G
James Burgess, Jeffrey J. Nirschl, Laura Bravo-Sánchez, Alejandro Lozano, Sanket Rajan Gupte, Jesus G. Galaz-Montoya, Yuhui Zhang, Yuchang Su, Disha Bhowmik, Zachary Coman, Sarina M. Hasan, Alexandra Johannesson, William D. Leineweber, Malvika G. Nair, Ridhi Yarlagadda, Connor Zuraski, Wah Chiu, Sarah Cohen, Jan N. Hansen, Manuel D. Leonetti, Chad Liu, Em...
-
[4]
Nmtsloth: understanding and testing efficiency degradation of neural machine translation systems
Simin Chen, Cong Liu, Mirazul Haque, Zihe Song, and Wei Yang. Nmtsloth: understanding and testing efficiency degradation of neural machine translation systems. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, Singapore, Singapore, November 14-18, 2022, pa...
work page 2022
-
[5]
Nicgslowdown: Evaluating the efficiency robustness of neural image caption generation models
Simin Chen, Zihe Song, Mirazul Haque, Cong Liu, and Wei Yang. Nicgslowdown: Evaluating the efficiency robustness of neural image caption generation models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 15344–15353. IEEE, 2022
work page 2022
-
[6]
Yiming Chen, Simin Chen, Zexin Li, Wei Yang, Cong Liu, Robby T. Tan, and Haizhou Li. Dynamic transformers provide a false sense of efficiency. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 7164–7180. Association for Computational Linguis...
work page 2023
-
[8]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, Lixin Gu, Xuehui Wang, Qingyun Li, Yimin Ren, Zixuan Chen, Jiapeng Luo, Jiahao Wang, Tan Jiang, Bo Wang, Conghui He, Botian Shi, Xingcheng Zhang, Han Lv, Yi Wang, Wenqi Shao, Pei Chu, Zhongying Tu, Tong He, Zhiyong Wu, Huipeng Deng, Jia...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023
work page 2023
-
[10]
Energy- latency attacks via sponge poisoning
Antonio Emanuele Cinà, Ambra Demontis, Battista Biggio, Fabio Roli, and Marcello Pelillo. Energy- latency attacks via sponge poisoning. Inf. Sci., 702:121905, 2025
work page 2025
-
[11]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven C. H. Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Proc...
work page 2023
-
[12]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA, pages 248–255. IEEE Computer Society, 2009
work page 2009
-
[13]
An engorgio prompt makes large language model babble on
Jianshuo Dong, Ziyuan Zhang, Qingjie Zhang, Han Qiu, Tianwei Zhang, Hao Wang, Hewu Li, Qi Li, Chao Zhang, and Ke Xu. An engorgio prompt makes large language model babble on. CoRR, abs/2412.19394, 2024. 10
-
[14]
Inducing high energy-latency of large vision-language models with verbose images
Kuofeng Gao, Yang Bai, Jindong Gu, Shu-Tao Xia, Philip Torr, Zhifeng Li, and Wei Liu. Inducing high energy-latency of large vision-language models with verbose images. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
work page 2024
-
[15]
Energy-latency manipulation of multi-modal large language models via verbose samples
Kuofeng Gao, Jindong Gu, Yang Bai, Shu-Tao Xia, Philip Torr, Wei Liu, and Zhifeng Li. Energy-latency manipulation of multi-modal large language models via verbose samples. CoRR, abs/2404.16557, 2024
-
[16]
Denial-of- service poisoning attacks against large language models,
Kuofeng Gao, Tianyu Pang, Chao Du, Yong Yang, Shu-Tao Xia, and Min Lin. Denial-of-service poisoning attacks against large language models. CoRR, abs/2410.10760, 2024
-
[17]
Junqi Ge, Ziyi Chen, Jintao Lin, Jinguo Zhu, Xihui Liu, Jifeng Dai, and Xizhou Zhu. V2PE: improving multimodal long-context capability of vision-language models with variable visual position encoding. CoRR, abs/2412.09616, 2024
-
[18]
Coercing llms to do and reveal (almost) anything
Jonas Geiping, Alex Stein, Manli Shu, Khalid Saifullah, Yuxin Wen, and Tom Goldstein. Coercing llms to do and reveal (almost) anything. CoRR, abs/2402.14020, 2024
-
[19]
Onellm: One framework to align all modalities with language
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, and Xiangyu Yue. Onellm: One framework to align all modalities with language. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 26574–26585. IEEE, 2024
work page 2024
-
[20]
Antinode: Evaluating efficiency robustness of neural odes
Mirazul Haque, Simin Chen, Wasif Arman Haque, Cong Liu, and Wei Yang. Antinode: Evaluating efficiency robustness of neural odes. In IEEE/CVF International Conference on Computer Vision, ICCV 2023 - Workshops, Paris, France, October 2-6, 2023, pages 1499–1509. IEEE, 2023
work page 2023
-
[21]
A panda? no, it’s a sloth: Slowdown attacks on adaptive multi-exit neural network inference
Sanghyun Hong, Yigitcan Kaya, Ionut-Vlad Modoranu, and Tudor Dumitras. A panda? no, it’s a sloth: Slowdown attacks on adaptive multi-exit neural network inference. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
work page 2021
-
[22]
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Madry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alexis Conneau,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
MM-SOC: benchmarking multi- modal large language models in social media platforms
Yiqiao Jin, Minje Choi, Gaurav Verma, Jindong Wang, and Srijan Kumar. MM-SOC: benchmarking multi- modal large language models in social media platforms. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, pages 6192–6210. Association for Computational Linguistics, 2024
work page 2024
-
[25]
Sparsity turns adversarial: Energy and latency attacks on deep neural networks
Sarada Krithivasan, Sanchari Sen, and Anand Raghunathan. Sparsity turns adversarial: Energy and latency attacks on deep neural networks. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst., 39(11):4129–4141, 2020
work page 2020
-
[26]
Efficiency attacks on spiking neural networks
Sarada Krithivasan, Sanchari Sen, Nitin Rathi, Kaushik Roy, and Anand Raghunathan. Efficiency attacks on spiking neural networks. In DAC ’22: 59th ACM/IEEE Design Automation Conference, San Francisco, California, USA, July 10 - 14, 2022, pages 373–378. ACM, 2022
work page 2022
-
[27]
Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C
Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: common objects in context. In Computer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V, volume 8693 of Lecture Notes in Computer Science, pages 740–755...
work page 2014
-
[28]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In 6th International Conference on Learning Repre- sentations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018
work page 2018
-
[29]
K. L. Navaneet, Soroush Abbasi Koohpayegani, Essam Sleiman, and Hamed Pirsiavash. Slowformer: Adversarial attack on compute and energy consumption of efficient vision transformers. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 24786–24797. IEEE, 2024
work page 2024
-
[30]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy P. Lillicrap, Jean-Baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, Ioannis Antonoglou, Rohan Anil, Sebastian Borgeaud, Andrew M. Dai, Katie Millican, Ethan Dyer, Mia Glaese, Thibault Sottiaux, Benjamin Lee, Fabio Viola, Malcolm Reynolds, Yuanzho...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Failures to find transferable image jailbreaks between vision-language models, 2024
Rylan Schaeffer, Dan Valentine, Luke Bailey, James Chua, Cristóbal Eyzaguirre, Zane Durante, Joe Benton, Brando Miranda, Henry Sleight, John Hughes, Rajashree Agrawal, Mrinank Sharma, Scott Emmons, Sanmi Koyejo, and Ethan Perez. Failures to find transferable image jailbreaks between vision-language models, 2024
work page 2024
-
[32]
Phantom sponges: Exploiting non-maximum suppression to attack deep object detectors
Avishag Shapira, Alon Zolfi, Luca Demetrio, Battista Biggio, and Asaf Shabtai. Phantom sponges: Exploiting non-maximum suppression to attack deep object detectors. In IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2023, Waikoloa, HI, USA, January 2-7, 2023, pages 4560–4569. IEEE, 2023
work page 2023
-
[33]
Ilia Shumailov, Yiren Zhao, Daniel Bates, Nicolas Papernot, Robert D. Mullins, and Ross Anderson. Sponge examples: Energy-latency attacks on neural networks. In IEEE European Symposium on Security and Privacy, EuroS&P 2021, Vienna, Austria, September 6-10, 2021, pages 212–231. IEEE, 2021
work page 2021
-
[34]
Hengyi Wang, Haizhou Shi, Shiwei Tan, Weiyi Qin, Wenyuan Wang, Tunyu Zhang, Akshay Nambi, Tanuja Ganu, and Hao Wang. Multimodal needle in a haystack: Benchmarking long-context capability of multimodal large language models. CoRR, abs/2406.11230, 2024
-
[35]
Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, and Jifeng Dai. Enhancing the reasoning ability of multimodal large language models via mixed preference optimization. arXiv preprint arXiv:2411.10442, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Energy-latency attacks to on-device neural networks via sponge poisoning
Zijian Wang, Shuo Huang, Yujin Huang, and Helei Cui. Energy-latency attacks to on-device neural networks via sponge poisoning. In Proceedings of the 2023 Secure and Trustworthy Deep Learning Systems Workshop, SecTL 2023, Melbourne, VIC, Australia, July 10-14, 2023 , pages 4:1–4:11. ACM, 2023
work page 2023
-
[37]
MMIE: massive multimodal interleaved comprehension benchmark for large vision-language models
Peng Xia, Siwei Han, Shi Qiu, Yiyang Zhou, Zhaoyang Wang, Wenhao Zheng, Zhaorun Chen, Chenhang Cui, Mingyu Ding, Linjie Li, Lijuan Wang, and Huaxiu Yao. MMIE: massive multimodal interleaved comprehension benchmark for large vision-language models. CoRR, abs/2410.10139, 2024
-
[38]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Multimodal commonsense knowledge distillation for visual question answering (student abstract)
Shuo Yang, Siwen Luo, and Soyeon Caren Han. Multimodal commonsense knowledge distillation for visual question answering (student abstract). In AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 29545–29547. AAAI Press, 2025
work page 2025
-
[40]
<Image> What is the content of this image?
Yuanhe Zhang, Zhenhong Zhou, Wei Zhang, Xinyue Wang, Xiaojun Jia, Yang Liu, and Sen Su. Crabs: Consuming resource via auto-generation for llm-dos attack under black-box settings, 2025. 12 Appendix • In Appendix A, we provide implementation details. • In Appendix B, we provide the pseudo code of our LingoLoop Attack. • In Appendix C, we provide results on ...
work page 2025
-
[41]
A bun with a bite taken out of it
-
[43]
A piece of bread with a bite taken out of it
-
[54]
A slice of bread with a bite taken out of it
-
[55]
the SD" at the bottom of the poster likely refers to
A slice of bread with a bite taken out of it. ... The image shows a train on a track, with the front of the train visible. The train appears to be a diesel locomotive, characterized by its yellow and black striped front. The background features a rural landscape with fields and trees, suggesting that the train is on a heritage or narrow-gauge railway line...
work page 2016
-
[56]
**Traffic Light with Acorn**: The traffic light has an acorn design on it, which might be part of the festival's branding or a local symbol.\n
-
[57]
**"Not Seattle" Sign**: This sign is a playful reference to the fact that Coachella is not located in Seattle, where the band Death Cab for Cutie is from.\n
-
[58]
**"Coachella 2015" Sign**: This indicates that the photo was taken during the Coachella 2015 event.\n
work page 2015
-
[59]
**Festival Tower**: The iconic tower at the entrance of Coachella is visible, decorated with psychedelic art typical of the festival's aesthetic.\n
-
[60]
**Sunset and Skyline**: The background shows a sunset with silhouettes of the festival towers, giving a sense of the time of day and location.\n
-
[61]
**"Not Seattle" Sign Again**: Another "Not Seattle" sign reinforces the playful theme.\n
-
[62]
**"Coachella 2015" Sign Again**: This repetition emphasizes the year of the event.\n
work page 2015
-
[63]
**"Not Seattle" Sign Again**: Another playful reminder that Coachella is not in Seattle.\n
- [67]
- [69]
- [70]
-
[71]
**"Not Seattle" Sign Again**: Another playful reminder.\n ... CleanClean AttackedAttacked Figure 14: Visualization examples: Qwen2.5-VL-7B outputs before vs. after LingoLoop Attack. 24 The image depicts a giraffe standing in an open savanna landscape. The background features a large, fluffy cloud in the sky, and the terrain is flat with sparse vegetation....
-
[72]
- Next to the suitcase is a wicker suitcase, adding to the vintage travel theme
**Luggage and Suitcases:** - There is a brown leather suitcase adorned with various travel stickers and badges. - Next to the suitcase is a wicker suitcase, adding to the vintage travel theme
-
[73]
**Stickers and Badges:** - The leather suitcase is decorated with numerous travel stickers, including: - A "California" sticker. - A "Route 66" sticker. - A "California Motel" sticker. - A "HOTEL FOUR SEASONS" sticker. - A "New Mexico" sticker. - A "Route 7" sticker. - A "California" badge with a crown. - A "HOTEL" sticker. - A "Route 7" sticker. - A "Cal...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.