RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Pith reviewed 2026-05-19 01:12 UTC · model grok-4.3
The pith
A hybrid reinforcement learning approach lets LLMs exceed their original reasoning boundaries by blending internal exploitation with external data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
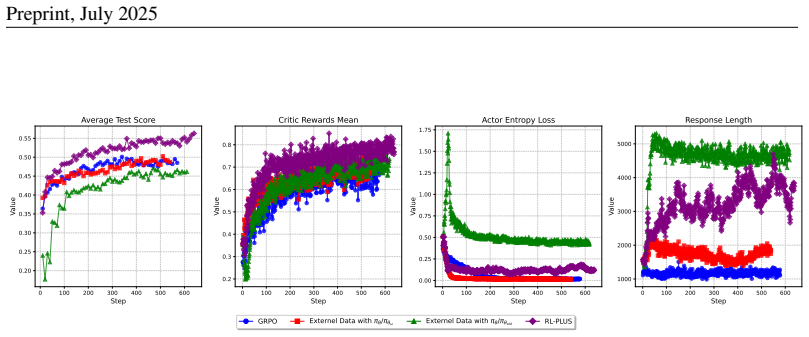
RL-PLUS is a novel hybrid-policy optimization approach for LLMs that synergizes internal exploitation with external data to achieve stronger reasoning capabilities and surpass the boundaries of base models. It integrates Multiple Importance Sampling to address distributional mismatch from external data, and Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. Theoretical analysis and experiments show state-of-the-art results on six math reasoning benchmarks, superior results on six out-of-distribution tasks, and consistent gains across model families with relative improvements up to 69.2 percent, while Pass@k curves indicate the collapse is
What carries the argument
Hybrid-policy optimization that combines Multiple Importance Sampling to correct for external data shifts with an Exploration-Based Advantage Function that favors unexplored high-value paths.
If this is right
- State-of-the-art performance on six math reasoning benchmarks relative to prior RLVR methods.
- Superior results on six out-of-distribution reasoning tasks.
- Consistent gains across different model families with average relative improvements reaching 69.2 percent.
- Resolution of capability boundary collapse as shown by sustained improvement in Pass@k curves.
Where Pith is reading between the lines
- The same hybrid sampling and advantage design could be tested on code-generation or scientific reasoning tasks to check whether it prevents similar narrowing in other domains.
- Combining the method with larger-scale external datasets might reveal how much additional data is needed before gains plateau.
- The work implies that future LLM post-training pipelines may routinely mix on-policy stability with controlled off-policy signals to keep policy diversity high.
Load-bearing premise
The assumption that Multiple Importance Sampling and the Exploration-Based Advantage Function can be combined without introducing new distributional biases or reward sparsity issues that would undermine the claimed resolution of capability boundary collapse.
What would settle it
A direct comparison of Pass@k curves at increasing k values; if RL-PLUS curves plateau or flatten at the same level as standard RLVR baselines, the claim that the hybrid method prevents boundary collapse would be falsified.
Figures






read the original abstract
Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its essentially on-policy strategy coupled with LLM's immense action space and sparse reward. Critically, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel hybrid-policy optimization approach for LLMs that synergizes internal exploitation with external data to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components, i.e., Multiple Importance Sampling to address distributional mismatch from external data, and Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. Compared with existing RLVR methods, RL-PLUS achieves 1) state-of-the-art performance on six math reasoning benchmarks; 2) superior performance on six out-of-distribution reasoning tasks; 3) consistent and significant gains across diverse model families, with average relative improvements up to 69.2\%. Moreover, the analysis of Pass@k curves indicates that RL-PLUS effectively resolves the capability boundary collapse problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RL-PLUS, a hybrid-policy optimization method for Reinforcement Learning with Verifiable Reward (RLVR) applied to LLMs. It targets the capability boundary collapse arising from on-policy sampling and sparse rewards by combining Multiple Importance Sampling (to correct for distributional mismatch when incorporating external data) with an Exploration-Based Advantage Function (to prioritize high-value unexplored reasoning trajectories). The authors supply theoretical analysis plus extensive experiments claiming state-of-the-art results on six math reasoning benchmarks, superior performance on six out-of-distribution reasoning tasks, consistent gains across model families (average relative improvement up to 69.2 %), and resolution of collapse as evidenced by Pass@k curve analysis.
Significance. If the central empirical claims and the absence of new distributional biases hold, the work would constitute a meaningful advance in RLVR post-training by demonstrating a practical route to expand LLM reasoning scope beyond base-model boundaries. The hybrid-policy framing, the explicit handling of external data via importance sampling, and the Pass@k diagnostic for collapse are potentially reusable contributions. Reproducible code and the breadth of benchmarks (in-distribution and OOD) would further strengthen the result if supplied.
major comments (2)
- §3.2–3.3 (Multiple Importance Sampling + Exploration-Based Advantage Function): The central claim that the two components can be combined without introducing new distributional biases or reward-sparsity artifacts is load-bearing for the collapse-resolution argument, yet the manuscript provides only high-level motivation rather than a concrete bias bound or ablation isolating the interaction term. A direct comparison of effective sample size or variance of the combined estimator versus each component alone would be required to substantiate that the hybrid policy does not simply trade one form of collapse for another.
- Table 2 / Figure 4 (Pass@k curves): The reported flattening or upward shift of Pass@k relative to baselines is presented as evidence that capability boundaries are resolved. However, the curves are shown only for the proposed method and a single baseline; without the full set of competing RLVR methods on the identical Pass@k metric and identical sampling budget, it remains unclear whether the improvement is attributable to the hybrid policy or to increased total compute/exploration.
minor comments (2)
- Notation: The definition of the Exploration-Based Advantage Function (Eq. (7) or equivalent) uses an exploration bonus term whose scaling hyper-parameter is not listed among the reported hyper-parameters; its sensitivity should be documented.
- Missing reference: The discussion of capability boundary collapse would benefit from citing the prior RLVR works that first quantified the phenomenon (e.g., the original papers introducing the on-policy + sparse-reward failure mode).
Simulated Author's Rebuttal
We thank the referee for their insightful comments and constructive feedback on our manuscript. We address each major comment point by point below and outline the revisions we will make to strengthen the presentation.
read point-by-point responses
-
Referee: §3.2–3.3 (Multiple Importance Sampling + Exploration-Based Advantage Function): The central claim that the two components can be combined without introducing new distributional biases or reward-sparsity artifacts is load-bearing for the collapse-resolution argument, yet the manuscript provides only high-level motivation rather than a concrete bias bound or ablation isolating the interaction term. A direct comparison of effective sample size or variance of the combined estimator versus each component alone would be required to substantiate that the hybrid policy does not simply trade one form of collapse for another.
Authors: We thank the referee for highlighting this important aspect. While Sections 3.2 and 3.3 derive the hybrid estimator and provide theoretical motivation for its unbiasedness under the stated assumptions, we agree that an explicit bias bound and targeted ablation would offer stronger support. In the revised manuscript we will add (i) a formal bias bound for the combined Multiple Importance Sampling estimator, (ii) an ablation that isolates the interaction between the two components, and (iii) empirical comparisons of effective sample size and estimator variance for the full hybrid policy versus each component used in isolation. These additions will directly address whether the hybrid formulation trades one form of collapse for another. revision: yes
-
Referee: Table 2 / Figure 4 (Pass@k curves): The reported flattening or upward shift of Pass@k relative to baselines is presented as evidence that capability boundaries are resolved. However, the curves are shown only for the proposed method and a single baseline; without the full set of competing RLVR methods on the identical Pass@k metric and identical sampling budget, it remains unclear whether the improvement is attributable to the hybrid policy or to increased total compute/exploration.
Authors: We appreciate this observation. The current Figure 4 contrasts our method with a representative on-policy baseline to illustrate the diagnostic value of the Pass@k metric. To strengthen the attribution argument, we will expand the figure in the revised manuscript to include Pass@k curves for additional competing RLVR methods, all evaluated under identical sampling budgets and training-step counts. We will also make explicit in the text that total compute and exploration budget were matched across all compared methods, thereby clarifying that the observed gains stem from the hybrid-policy design rather than differences in resource allocation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces RL-PLUS as a hybrid-policy method combining Multiple Importance Sampling and an Exploration-Based Advantage Function, supported by a claimed theoretical analysis and extensive experiments on math reasoning benchmarks. No derivation step reduces a claimed prediction or resolution of capability boundary collapse to a fitted parameter or self-referential definition by construction. The central claims rest on the synergy of the two new components addressing on-policy and sparse-reward issues, with performance gains presented as empirical outcomes rather than tautological outputs of the input data or prior self-citations. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RL-PLUS integrates two core components, i.e., Multiple Importance Sampling to address distributional mismatch from external data, and Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The analysis of Pass@k curves indicates that RL-PLUS effectively resolves the capability boundary collapse problem.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
Evaluating the Formal Reasoning Capabilities of Large Language Models through Chomsky Hierarchy
LLMs display clear performance stratification on formal language tasks aligned with Chomsky hierarchy complexity levels, limited by severe efficiency barriers rather than absolute capability.
-
Beyond Uniform Credit Assignment: Selective Eligibility Traces for RLVR
S-trace adds sparse eligibility traces to RLVR that mask low-entropy tokens, outperforming GRPO by 0.49-3.16% pass@16 on Qwen3 models while improving sample and token efficiency.
-
Rethinking Agentic Reinforcement Learning In Large Language Models
The paper reviews conceptual foundations, methodological innovations, effective designs, critical challenges, and future directions for LLM-based Agentic Reinforcement Learning.
-
Rethinking Agentic Reinforcement Learning In Large Language Models
This review synthesizes conceptual foundations, methods, challenges, and future directions for agentic reinforcement learning in large language models.
-
Rethinking Agentic Reinforcement Learning In Large Language Models
The paper surveys the conceptual foundations, methodological innovations, challenges, and future directions of agentic reinforcement learning frameworks that embed cognitive capabilities like meta-reasoning and self-r...
Reference graph
Works this paper leans on
-
[1]
How much backtracking is enough? exploring the interplay of sft and rl in enhancing llm reasoning
Hongyi James Cai, Junlin Wang, Xiaoyin Chen, and Bhuwan Dhingra. How much backtracking is enough? exploring the interplay of sft and rl in enhancing llm reasoning.arXiv preprint arXiv:2505.24273,
-
[2]
Jack Chen, Fazhong Liu, Naruto Liu, Yuhan Luo, Erqu Qin, Harry Zheng, Tian Dong, Haojin Zhu, Yan Meng, and Xiao Wang. Step-wise adaptive integration of supervised fine-tuning and rein- forcement learning for task-specific llms.arXiv preprint arXiv:2505.13026,
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.CoRR, abs/2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025a. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Teaching large language models to reason with reinforcement learning,
10 Preprint, July 2025 Alexander Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Nalmpantis, Jane Dwivedi- Yu, et al. Teaching large language models to reason with reinforcement learning.arXiv preprint arXiv:2403.04642,
-
[9]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
URLhttps://huggingface.co/ datasets/open-r1/OpenR1-Math-220k. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
KimiTeam. Kimi k1.5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Yihao Liu, Shuocheng Li, Lang Cao, Yuhang Xie, Mengyu Zhou, Haoyu Dong, Xiaojun Ma, Shi Han, and Dongmei Zhang. Superrl: Reinforcement learning with supervision to boost language model reasoning.arXiv preprint arXiv:2506.01096, 2025a. Zichen Liu, Changyu Chen, Wenjun Li, Tianyu Pang, Chao Du, and Min Lin. There may not be aha moment in r1-zero-like traini...
-
[13]
11 Preprint, July 2025 Martin L Puterman.Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons,
work page 2025
-
[14]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, et al. Reinforcement learning for reasoning in large language models with one training example.arXiv preprint arXiv:2504.20571,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
UFT: Unifying Fine-Tuning of SFT and RLHF/DPO/UNA through a Generalized Implicit Reward Function
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi- task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024a. Zhichao Wang, Bin Bi, Zixu Zhu, Xiangbo Mao, Jun Wang, and Sh...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Learning to Reason under Off-Policy Guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance.arXiv preprint arXiv:2504.14945,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jian- hong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?CoRR, abs/2504.13837, 2025a. Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, et al. Vapo: Ef...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
12 Preprint, July 2025 A Theoretical Analysis of Multiple Importance Sampling We provide a rigorous theoretical analysis of the Multiple Importance Sampling (MIS) estimator for policy optimization. First, we dissect the bias and variance issues inherent to standard Importance Sampling (IS) when using data from a single behavior policy. Subsequently, we pr...
work page 2025
-
[24]
Therefore, the variance is: Varπω(rω) = (χ2(πθ, πω) + 1)−1 2 =χ 2(πθ, πω). Both theχ 2-divergence and the more commonly known KL-divergence (DKL(πθ∥πω)) are measures of dissimilarity between distributions (both are instances of f-divergences). A large value in one typically implies a large value in the other. Therefore, as the policies diverge, there are ...
work page 2025
-
[25]
Under this assumption, the maximum-entropy (uniform) distribution isU(τ) = 1for allτ∈ T. 17 Preprint, July 2025 RemarkA.14 (Robustness and Connection to Regularization).Theorem A.12 provides a rigorous justification for what is, in essence, a form of regularization. The resulting estimatorˆπ∗ ω is a mixture model that hedges against the deficiencies ofπ θ...
work page 2025
-
[26]
as the base model in our experiments. For our training, we use a subset of OpenR1-Math-220k (Hugging Face, 2025), which contains 45,000 prompts with correct reasoning trajectories annotated by Deepseek-R1, and change the rope theta of Qwen2.5-Math-7B from 10000 to 40000 and extend the window size to 16384, following previous work (Yan et al., 2025). In im...
work page 2025
-
[27]
For each problem, we use 8 rollout trajectories, with a maximum response length of 8192 tokens. For our approach, one of the model-generated rollouts is replaced with a correct reasoning trajectory from the training dataset. It is important to note that we ensure all other RL algorithms maintain the same parameter settings as RL-PLUS to guarantee a fair c...
work page 2021
-
[28]
and AMC 2023 (Li et al., 2024). Additionally, although our training focuses on math, we extend our evaluation to out-of-domain (OOD) tasks to assess the robustness and gener- alization capabilities of our approach. The OOD datasets include ARC-c (Clark et al., 2018)(Open- Domain Reasoning), GPQA-diamond (Rein et al.,
work page 2023
-
[29]
(Science Graduate Knowledge), MMLU- Pro (Wang et al., 2024a) (Reasoning-focused Questions from Academic Exams and Textbooks), as well as three code generation datasets: HumanEval (Chen et al., 2021), LeetCode (Guo et al., 2024), and LiveCodeBench (Jain et al., 2024). During evaluation, we set the sampling temperature to 0.6 and report the average pass@1 s...
work page 2021
-
[30]
per- forms RL and SFT alternately during training. The second category consists of four straightforward baselines: 1)SFT, supervised fine-tuning using external reasoning trajectory data. 2)GRPO(Shao et al., 2024), training with GRPO algorithm on question-answer pairs. 3)SFT+GRPO, a common RL cold-start approach that performs SFT before RL training. 4)GRPO...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.