Beyond the Leaderboard: Rethinking Medical Benchmarks for Large Language Models
Pith reviewed 2026-05-19 00:35 UTC · model grok-4.3
The pith
Existing medical LLM benchmarks show deep disconnects from clinical practice, data contamination risks, and neglected safety tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce MedCheck, the first lifecycle-oriented assessment framework specifically designed for medical benchmarks. Our framework deconstructs a benchmark's development into five continuous stages, from design to governance, and provides a comprehensive checklist of 46 medically-tailored criteria. Using MedCheck, we conducted an in-depth empirical evaluation of 53 medical LLM benchmarks. Our analysis uncovers widespread, systemic issues, including a profound disconnect from clinical practice, a crisis of data integrity due to unmitigated contamination risks, and a systematic neglect of safety-critical evaluation dimensions like model robustness and uncertainty awareness.
What carries the argument
MedCheck, the five-stage lifecycle framework equipped with 46 medically tailored criteria that audits benchmarks from initial design through ongoing governance.
If this is right
- Benchmarks can be audited stage by stage for alignment with actual clinical workflows.
- Future benchmark creators can add explicit steps to reduce data contamination.
- Safety evaluations must routinely include tests for model robustness and uncertainty awareness.
- Standardized checklists can replace ad-hoc approaches in medical AI assessment.
- Healthcare AI development can shift toward more transparent and reliable performance measures.
Where Pith is reading between the lines
- Widespread adoption could reorder current leaderboard standings once the new criteria are applied.
- The same lifecycle approach might transfer to benchmark design in other high-stakes fields such as law or autonomous systems.
- Researchers could run follow-up studies to check whether MedCheck scores predict better patient outcomes in controlled trials.
- Periodic updates to the criteria would likely be needed as medical AI capabilities and risks evolve.
Load-bearing premise
The 46 criteria are assumed to capture all essential dimensions of clinical fidelity, data management, and safety without major gaps or skewed priorities.
What would settle it
Finding that benchmarks scoring low on MedCheck still produce safe, accurate results in real clinical deployments, or that high-scoring ones fail in practice, would test the framework's core claims.
Figures























read the original abstract
Large language models (LLMs) show significant potential in healthcare, prompting numerous benchmarks to evaluate their capabilities. However, concerns persist regarding the reliability of these benchmarks, which often lack clinical fidelity, robust data management, and safety-oriented evaluation metrics. To address these shortcomings, we introduce MedCheck, the first lifecycle-oriented assessment framework specifically designed for medical benchmarks. Our framework deconstructs a benchmark's development into five continuous stages, from design to governance, and provides a comprehensive checklist of 46 medically-tailored criteria. Using MedCheck, we conducted an in-depth empirical evaluation of 53 medical LLM benchmarks. Our analysis uncovers widespread, systemic issues, including a profound disconnect from clinical practice, a crisis of data integrity due to unmitigated contamination risks, and a systematic neglect of safety-critical evaluation dimensions like model robustness and uncertainty awareness. Based on these findings, MedCheck serves as both a diagnostic tool for existing benchmarks and an actionable guideline to foster a more standardized, reliable, and transparent approach to evaluating AI in healthcare.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce MedCheck, the first lifecycle-oriented assessment framework for medical benchmarks with 46 criteria across five stages from design to governance. Applying it to 53 medical LLM benchmarks reveals widespread systemic issues including disconnect from clinical practice, data integrity problems due to contamination, and neglect of safety dimensions like robustness and uncertainty awareness. It positions MedCheck as both diagnostic and guideline for better evaluation.
Significance. If the framework's criteria are shown to be valid and reliable, this could have substantial impact by shifting the field toward more clinically relevant and safe benchmark practices. The broad audit provides a valuable snapshot of current shortcomings in medical LLM evaluation.
major comments (3)
- [MedCheck framework description] The construction of the 46 criteria lacks any described methodology for derivation, such as synthesis from existing literature, input from medical experts, or validation through pilot studies and inter-rater reliability measures. This is load-bearing for the central claim, as the identification of 'systemic issues' in the 53 benchmarks depends on these criteria accurately reflecting clinical fidelity, data management, and safety without author-specific biases or omissions.
- [Empirical evaluation of 53 benchmarks] While the abstract states that the analysis uncovers 'widespread, systemic issues,' there are no quantitative results, tables summarizing failure rates per criterion or stage, or statistical evidence provided in the high-level description. This makes it difficult to assess the strength of the 'profound disconnect' and 'crisis of data integrity' claims.
- [Audit process] Details on how the evaluation was performed, including the number of raters, their expertise, blinding procedures, or resolution of disagreements, are not mentioned. This raises concerns about the reproducibility and objectivity of the findings regarding safety-critical dimensions.
minor comments (1)
- [Abstract] Consider adding a brief note on how the five stages were selected to enhance clarity for readers unfamiliar with lifecycle models in benchmark development.
Simulated Author's Rebuttal
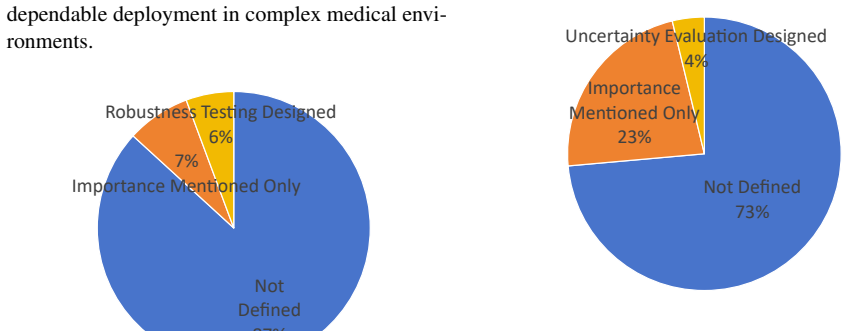
We sincerely thank the referee for their constructive and detailed feedback on our manuscript. The comments identify key areas where additional transparency and rigor will strengthen the presentation of MedCheck and our audit findings. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [MedCheck framework description] The construction of the 46 criteria lacks any described methodology for derivation, such as synthesis from existing literature, input from medical experts, or validation through pilot studies and inter-rater reliability measures. This is load-bearing for the central claim, as the identification of 'systemic issues' in the 53 benchmarks depends on these criteria accurately reflecting clinical fidelity, data management, and safety without author-specific biases or omissions.
Authors: We agree that an explicit account of criterion derivation is necessary to support the framework's validity. The 46 criteria were synthesized from a systematic review of clinical practice guidelines, AI evaluation literature, and regulatory documents on medical AI safety, with input from co-authors who have clinical and technical expertise. To address the referee's concern, we will add a dedicated subsection in the Methods describing this synthesis process, citing the primary sources, and noting the internal review steps used to refine the criteria. This addition will clarify the grounding of the framework and reduce any perception of author-specific bias. revision: yes
-
Referee: [Empirical evaluation of 53 benchmarks] While the abstract states that the analysis uncovers 'widespread, systemic issues,' there are no quantitative results, tables summarizing failure rates per criterion or stage, or statistical evidence provided in the high-level description. This makes it difficult to assess the strength of the 'profound disconnect' and 'crisis of data integrity' claims.
Authors: We accept that the main text currently emphasizes qualitative synthesis over aggregate statistics. The full manuscript contains per-benchmark annotations in the supplementary materials, but we will add a new summary table to the Results section that reports the percentage of benchmarks failing each of the five stages and selected high-impact criteria (e.g., contamination controls and robustness testing). This table will include simple counts and proportions to quantify the systemic issues and allow readers to evaluate the strength of our conclusions directly. revision: yes
-
Referee: [Audit process] Details on how the evaluation was performed, including the number of raters, their expertise, blinding procedures, or resolution of disagreements, are not mentioned. This raises concerns about the reproducibility and objectivity of the findings regarding safety-critical dimensions.
Authors: We acknowledge the importance of documenting the audit procedure for reproducibility. The evaluation was performed by the four authors, each with relevant expertise in medical AI, benchmark design, or clinical informatics; disagreements on criterion application were resolved through iterative discussion until consensus was reached. Because the source material consisted of publicly available benchmark papers and documentation, formal blinding was not required. We will expand the Methods section to include these details, along with a brief description of the consensus process, to improve transparency and allow future replication efforts. revision: yes
Circularity Check
No significant circularity: MedCheck is an independent framework applied to external benchmarks
full rationale
The paper introduces MedCheck as a new lifecycle-oriented framework that deconstructs benchmark development into five stages and supplies a checklist of 46 criteria; this construction is presented as an original contribution rather than derived from the 53 benchmarks under evaluation. The subsequent empirical audit applies the framework to external benchmarks, uncovering issues such as disconnect from clinical practice and data contamination risks. No equations, fitted parameters, self-citations, or ansatzes are invoked to force the criteria or results back onto the input benchmarks by construction. The derivation chain remains self-contained because the framework functions as an independent diagnostic lens rather than a self-referential mapping of its own evaluation targets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmark development can be meaningfully decomposed into five continuous stages from design to governance.
invented entities (1)
-
MedCheck framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce MedCheck, the first lifecycle-oriented assessment framework... deconstructs a benchmark's development into five continuous stages... comprehensive checklist of 46 medically-tailored criteria.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Phase II: Dataset Construction and Management... proactive mitigation of data contamination risks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Self-Prompting Small Language Models for Privacy-Sensitive Clinical Information Extraction
Small open-weight language models can self-optimize prompts for clinical named entity recognition in dental notes, reaching micro F1 of 0.864 after DPO on Qwen2.5-14B.
-
Measuring What Matters: Benchmarking Generative, Multimodal, and Agentic AI in Healthcare
Healthcare AI benchmarks show high scores on medical exams but sharply lower performance on real clinical tasks such as documentation and decision support, indicating a need for better frameworks to measure reliabilit...
Reference graph
Works this paper leans on
-
[1]
Medec: A benchmark for medical error de- tection and correction in clinical notes. Preprint, arXiv:2501.03465. Ahmed Alaa, Thomas Hartvigsen, Niloufar Golchini, Shiladitya Dutta, Frances Dean, Inioluwa Deborah Raji, and Travis Zack. 2025. Medical large language model benchmarks should prioritize construct valid- ity. Preprint, arXiv:2503.10694. Rahul K. A...
-
[2]
How should we build a benchmark? revisiting 274 code-related benchmarks for llms,
Machine learning data practices through a data curation lens: An evaluation framework. In Pro- ceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 1055–1067. Jialun Cao, Yuk-Kit Chan, Zixuan Ling, Wenxuan Wang, Shuqing Li, Mingwei Liu, Ruixi Qiao, Yuting Han, Chaozheng Wang, Boxi Yu, Pinjia He, Shuai Wang, Zibin Zheng,...
-
[3]
arXiv preprint arXiv:2502.14425 , year=
A survey on evaluation of large language mod- els. In Proceedings of the 22nd Chinese National Conference on Computational Linguistics (Volume 2: Short Papers), pages 88–109. Pengcheng Chen, Jin Ye, Guoan Wang, Yanjun Li, Zhongying Deng, Wei Li, Tianbin Li, Haodong Duan, Ziyan Huang, Yanzhou Su, Benyou Wang, Shaoting Zhang, Bin Fu, Jianfei Cai, Bohan Zhua...
-
[4]
ER-Reason: A Benchmark Dataset for LLM Clinical Reasoning in the Emergency Room
Er-reason: A benchmark dataset for llm-based clinical reasoning in the emergency room. Preprint, arXiv:2505.22919. Francesco Molfese, Simone Balloccu, Gianni Fenu, and Ludovico Marras. 2025. Right answer, wrong score: Uncovering the inconsistencies of llm evaluation in multiple-choice question answering. arXiv preprint arXiv:2503.05113. Ziad Obermeyer, Br...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
CliMedBench: A large-scale Chinese bench- mark for evaluating medical large language models in clinical scenarios. In Proceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing, pages 8428–8438, Miami, Florida, USA. Association for Computational Linguistics. Ankit Pal, Logesh Kumar Umapathi, and Malaikan- nan Sankarasubbu. 20...
-
[6]
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
Betterbench: Assessing ai benchmarks, un- covering issues, and establishing best practices. In Advances in Neural Information Processing Systems, volume 37, pages 21763–21813. Curran Associates, Inc. Winston W Royce. 1970. Managing the development of large software systems. Proceedings of IEEE WESCON, 26(8):1–9. Samuel Schmidgall, Rojin Ziaei, Carl Harris...
work page internal anchor Pith review arXiv 1970
-
[7]
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
A medical data-effective learning benchmark for highly efficient pre-training of foundation models. In Proceedings of the 32nd ACM International Con- ference on Multimedia, MM ’24, page 3499–3508, New York, NY , USA. Association for Computing Machinery. Qahtan M Yas, Abdulbasit ALazzawi, and Bahbibi Rah- matullah. 2023. A comprehensive review of software ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
In this Equation, Ndisease represents the num- ber of diseases in the ICD-11 standard, specifically the first 23 diseases, serving as the benchmark for the types of diseases considered. Ndepartment de- notes the number of medical departments, typi- cally referring to the medical specialties included in the model’s evaluation. The variableN benchmark disea...
-
[9]
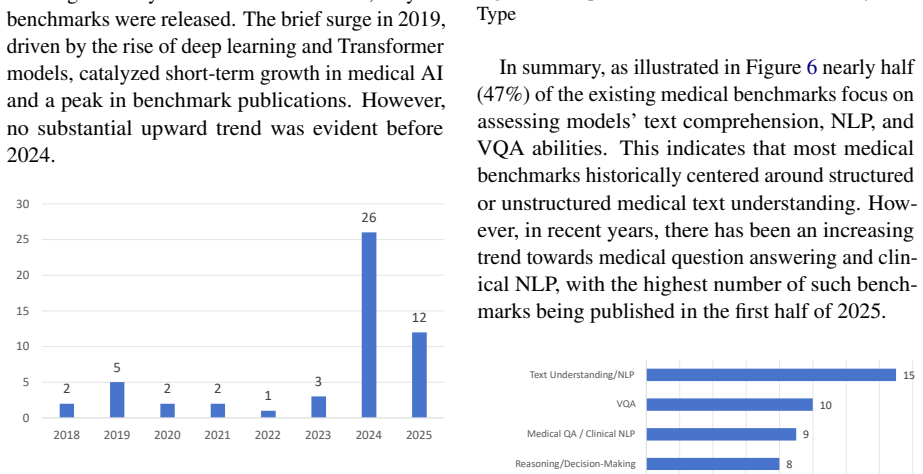
did not mention the issue at all. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 AfriMed-QA GMAI-MMBench MedRisk Asclepius MVME MMMU(Health &… VQA-Med HealthBench BRIDGE OmniMedVQA webMedQA MedCalc-Bench MedChain MedJourney CMB CLIMB MedMCQA ReasonMed COGNET-MD CheXpert CHBench SLAKE MediQ MedExQA MLEC-QA LLMEval-Med PathMMU Disease Type Coverage 0 0.1 0.2 0.3 0.4 0.5 0.6...
-
[10]
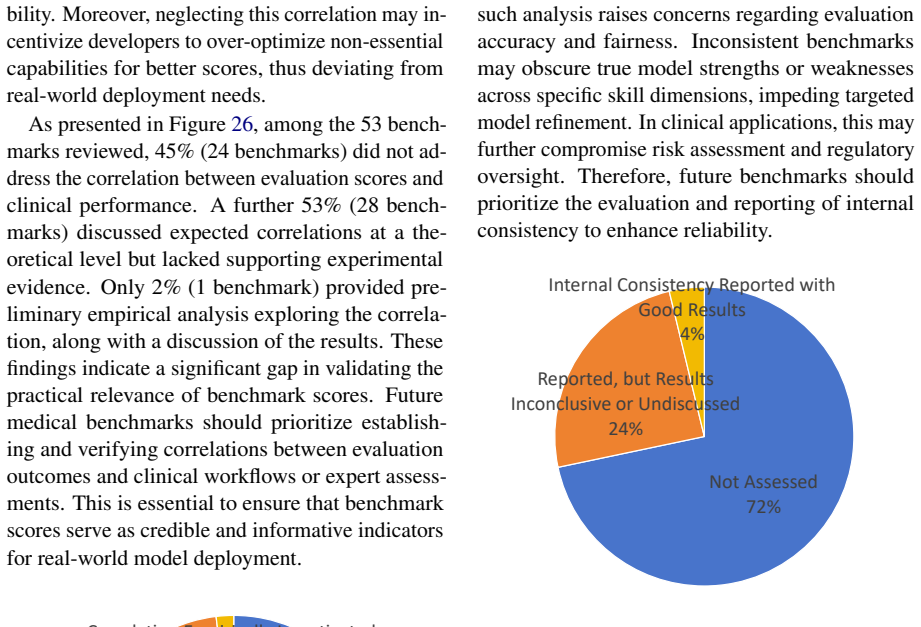
The remaining 72% (38 out of 53) did not conduct in- ternal consistency assessments
also reported such metrics, but without clear discussion or yielded inconclusive findings. The remaining 72% (38 out of 53) did not conduct in- ternal consistency assessments. The absence of such analysis raises concerns regarding evaluation accuracy and fairness. Inconsistent benchmarks may obscure true model strengths or weaknesses across specific skill...
-
[11]
These findings highlight a lack of rigorous statistical stan- dards in current benchmark design
provided mean and standard deviation across multiple runs, they did not employ formal statis- tical tests to compare model performance. These findings highlight a lack of rigorous statistical stan- dards in current benchmark design. Incorporating structured multi-run strategies and statistical signif- 23 icance testing is critical to enhance the reliabili...
-
[12]
Clarity of Evaluation Objectives 6 6.5 7 7.5 8 8.5 9 9.5 10 10.5 HealthBench MEDIC EHRNoteQA BRIDGE ClinicBench MedAgentBench AgentClinicMedOdysseyMedCalc-Bench MVME MedR-Bench TRIALPANORAMA MedRisk MedAgentsBench CHBench Figure 34: Top 15 Benchmarks by Score in Phase IV 9 10 11 12 13 14 15 16 17 18 MedS-Bench MEDICBRIDGE MedAgentBench HealthBench MedSafe...
-
[13]
Clarity of Application Scenario • Explanation: Benchmark developers should clearly describes the specific med- 25 ical application scenarios it corresponds to and explains the potential value. • Justification: Linking the benchmark to real-world application scenarios en- sures that the results are meaningful. It facilitates the validation of model’s effec...
-
[14]
Uniqueness and Novelty • Explanation: By comparing with rele- vant benchmarks, benchmark developers should explain their contributions and the uniqueness of the benchmark, such as filling a gap and proposing new evalu- ation methodology. • Justification: Demonstrating the unique- ness demonstrates the necessity and jus- tification of the new benchmark. It...
-
[15]
• Scoring: – 0: Does not define the target LLM capability
Target Capability of Evaluation • Explanation: Benchmark developers should clearly define the capability of LLMs intended to evaluate (e.g., text gen- eration, multimodal understanding) • Justification: Clearly defining the tar- geted capability helps clarify the scope of the benchmark, which can prevent mis- using the benchmark. • Scoring: – 0: Does not ...
-
[16]
Medical Domain Coverage • Explanation: Benchmark developers should clearly define the scope of the medical specialties of the benchmark, such as clinical departments, disease types, or task types. • Justification: By clearly defining the medical scope, it helps users better un- derstand the breath and depth of the cov- erage of the benchmark. It also help...
-
[17]
• Justification: An effective benchmark should serve the needs of users
Demonstration of User Needs • Explanation: The benchmark should re- flect the core concerns and assessment needs of its target users, such as address- ing specific clinical challenges or over- coming technical obstacles. • Justification: An effective benchmark should serve the needs of users. Evi- dence of user needs justifies the devel- opment of the ben...
-
[18]
Domain Experts Involvement • Explanation: Domain expert (e.g., physicians or clinical researchers) should be involved in the development of the benchmark. • Justification: Due to the professionalism and rigor required in the medical field, the development of a benchmark must involve deep engagement from domain experts. Their expertise are fundamen- tal to...
-
[19]
Authoritative Knowledge Sources • Explanation: Benchmark developers must clearly specify which authorita- tive medical knowledge sources (e.g., clinical guidelines, textbooks, medical databases) the benchmark content is based on. • Justification: Benchmark content should adhere to recognized, evidence- based medical knowledge sources. By using authoritati...
-
[20]
Medical Standards Alignment • Explanation: Benchmarks should follow internationally or industry- recognized medical standards (e.g., ICD, SNOMED CT, LOINC) when medical terminology is involved. • Justification: Adherence to medical standards ensures the clinical relevance and consistency, facilitating integration and comparison in reflect real-world medic...
-
[21]
• Justification: Evaluation metrics di- rectly shape the interpretation of results
Validity of Core Metric • Explanation: The core performance metric should be clearly defined and closely related to the clinical task or med- ical capability being assessed. • Justification: Evaluation metrics di- rectly shape the interpretation of results. Choosing suitable metric and explaining its relevance ensures a shared understand- ing and comprehe...
-
[22]
• Justification: In high-stakes medical do- main, going beyond correctness is vi- tal
Multi-dimensional Evaluation 27 • Explanation: Apart from the correct- ness, benchmark developers should in- clude evaluation of other important di- mensions (e.g., safety, fluency). • Justification: In high-stakes medical do- main, going beyond correctness is vi- tal. Multi-dimensional evaluation of- fers a more comprehensive assessment of whether a mode...
-
[23]
Safety and Fairness Considerations • Explanation: Benchmark should in- clude evaluation for potential risks (e.g., unsafe recommendation, toxicity) and bias (e.g., gender, ethnicity) in model outputs. • Justification: Evaluating risks and fair- ness facilitates bias-free, safe and equi- table applications of LLMs in the med- ical domain, promoting respons...
-
[24]
Data source transparency and traceability • Explanation: Benchmark developers should clearly state the data source of the benchmark, along with relevant trace- ability information (e.g., data collection time frame, platforms). • Justification: Clear and traceable data sources are critical to ensure trans- parency and ethical data usage, which is especiall...
-
[25]
Data Source Reliability • Explanation: Benchmark developers should clearly describe the selection cri- teria and explain the reliability of the data source. • Justification: Collecting data from unre- liable sources may lead to invalid results for medical applications. By explaining the reliability of the data source, credibil- ity of the benchmark can be...
-
[26]
Data Authenticity • Explanation: Benchmark developers should clearly specify whether the data comes from the real world scenarios, syn- thetically generated, or a mixture of both. For synthetically generated data, the con- struction process and verification for its authenticity (e.g., expert review) should also be described. • Justification: Real-world da...
-
[27]
Dataset Representativeness • Explanation: The representativeness of key features (e.g., patient age, disease) of the dataset should be explained and statistically analyzed. • Justification: A benchmark that lacks representativeness may lead to bias in evaluation, reducing the clinical rele- vance, generalizability and fairness of the results. • Scoring: –...
-
[28]
Dataset Diversity • Explanation: The benchmark should have a diverse coverage, and provide quantitative evidence of its diversity of disease or medical departments covered. • Justification: Ensuring the dataset cov- ers a variety helps comprehensively eval- uate the model’s generalization ability, reducing bias in the evaluation results. • Scoring: – 0: D...
-
[29]
• Justification: It ensures that the final dataset is well-structured, enhancing re- liability
Data Cleaning and Standardization • Explanation: The processes and steps of data preprocessing, including data cleaning and standardization, should be clearly described. • Justification: It ensures that the final dataset is well-structured, enhancing re- liability. Also, it allows a better under- standing of the construction process of the benchmark, ensu...
-
[30]
Privacy Protection • Explanation: If sensitive data is used, it should be de-identified. Methods of de-identification should be described and compliance with relevant regulations (e.g., HIPAA) should be clearly stated. • Justification: Real-world clinical data may contain patient information. It is es- sential to ensure that the data and privacy protectio...
-
[31]
• Justification: A clear and consistent for- mat is essential for standardized evalua- tion
Data Format Clarity and Consistency 29 • Explanation: The data in the dataset, including questions, cases, or task de- scriptions, should be written clearly and presented in a consistent format. • Justification: A clear and consistent for- mat is essential for standardized evalua- tion. Inconsistent format may affect mod- els’ interpretation, compromising...
-
[32]
• Justification: A dataset construction pro- cess without review mechanism is prone to errors
Data Review and Audit • Explanation: The dataset construction process should include a review proce- dure with involvement of medical ex- perts. • Justification: A dataset construction pro- cess without review mechanism is prone to errors. Careful review that involves medical experts can ensures clinical rel- evance, professionalism and reliable of the da...
-
[33]
Quality of Reference Answer • Explanation: The benchmark should provide clear and accurate reference an- swers or scoring guidelines, and explain the construction and verification process (e.g., expert consensus). • Justification: Clear reference answers or scoring guidelines ensures transpar- ent and accurate evaluation. By explain- ing how are reference...
-
[34]
Data Contamination Prevention • Explanation: Benchmark developers should take actions to identify, address and prevent potential data contamination issues of the data. • Justification: Data contamination may lead to inflated performance, which only reflect memorization instead of medical capability from the models. Preventing and controlling potential con...
-
[35]
User-friendliness of evaluation tools • Explanation: Evaluation scripts or tools that is easy to obtain and use should be provided. • Justification: It ensures that users can use the benchmark conveniently, promot- ing benchmark adoption and ensuring fair, transparent, and consistent evalua- tion. • Scoring: – 0: No evaluation scripts or tools is provided...
-
[36]
Technical Reproducibility • Explanation: Tools and technical doc- umentation (e.g., environment configu- ration, dependency versions) should be provided. • Justification: The availability of evalua- tion tools and clear technical documenta- tion ensures reproducibility of reported results, thereby enhancing the credibility of the benchmark. • Scoring: – 0...
-
[37]
Provision of performance baselines • Explanation: Benchmark developers should provide multiple meaningful per- formance baselines, such as random, baseline models and human perfor- mance. • Justification: Providing different per- formance baselines allows comparison against the model’s performance, en- abling a deeper understanding and better interpretabi...
-
[38]
Reasoning Process Evaluation • Explanation: Apart from the final an- swer, the benchmark includes evalua- tions for the model’s reasoning process or explanation abilities. • Justification: In medical domain, un- derstanding the model’s decision-making process is just as important as the final answer. Evaluating the reasoning process helps ensure that the ...
-
[39]
Robustness testing en- sures model’s output is consistent and reliable under different conditions
Robustness Evaluation • Explanation: Benchmark should in- clude testing for the model’s stability and robustness (e.g., input perturbations, ad- versarial samples) • Justification: In practical applications, models may encounter different varia- tions of inputs. Robustness testing en- sures model’s output is consistent and reliable under different conditi...
-
[40]
Generalization Capability Evaluation • Explanation: The benchmark design should help evaluate the generalization capability of models to unseen data or scenarios (e.g., careful train/test split, out-of-distribution testing). 31 • Justification: Due to the high variability in medical scenarios, assessing a model’s generalization capability is essential for...
-
[41]
Uncertainty Evaluation • Explanation: Benchmark should in- clude evaluation for the model’s ability to recognize and express its own uncer- tainty (e.g., responding “I don’t know”) • Justification: Incorrect overconfident an- swers can be dangerous in high-stakes medical applications. A model’s ability to accurately identify and express uncer- tainty is c...
-
[42]
• Justification: It ensures that different types of models can be tested under the same interface
Evaluation Flexibility • Explanation: Evaluation code should have modular interface and support dif- ferent models, including closed-source models that require API access and local open-source models. • Justification: It ensures that different types of models can be tested under the same interface. • Scoring: – 0: Supports only one type of model and is di...
-
[43]
Knowledge and Skill Coverage • Explanation: Evidence (e.g., expert evaluation) is provided to demonstrate that the benchmark content sufficiently covers the medical knowledge and skills it claims to assess. • Justification: Sufficient coverage of the core medical competencies the bench- mark aims to measure is the prerequisite for establishing content val...
-
[44]
Scenario Authenticity • Explanation: The evaluation tasks of the benchmark should effectively simulate and mirror real-world medical scenario. • Justification: Ensuring that the evalu- ation task closely mirrors the targeted clinical practice in real-world scenarios enhance the relevance of the benchmark. It helps assess whether the model can be transferr...
-
[45]
Model Discrimination Ability • Explanation: Benchmark developers should provide experiment data and anal- ysis, indicating that the benchmark can effectively distinguish the capability be- tween different models. • Justification: An effective benchmark should be capable of differentiating and distinguishing models of varying capabil- ities. It provides me...
-
[46]
Correlation with Clinical Performance • Explanation: Benchmark developers should provide evidence that prelimi- narily explores the correlation between benchmark performance and the model’s performance in actual clinical applica- tions. • Justification: Validating whether bench- mark results have meaningful indica- tion on the model’s performance in real-...
-
[47]
• Scoring: – 0: Does not mention or conduct any internal consistency measurement
Internal Consistency • Explanation: For different sections or items of the benchmark evaluating the same capability, benchmark developers should demonstrate good internal consis- tency (e.g., Cronbach’sα) • Justification: It ensures that different sections or items reliably assess the same capability, enabling meaningful compar- isons and interpretation o...
-
[48]
Statistical Significance Reporting • Explanation: When comparing the per- formance of different models, statistical significance (e.g., confidence intervals, and p-values) should be report. • Justification: Statistical significance testing allows for a more informed inter- pretation of results by differentiating the performance differences between mod- el...
-
[49]
Documentation Completeness • Explanation: Benchmark developers should provide a clear and comprehen- sive documentation of the benchmark, systematically describing the relevant de- tails, including the design, objectives, scope, construction process, task defini- tions and evaluation procedures. • Justification: A complete and clear doc- umentation help u...
-
[50]
Clarity of Evaluation Guidelines • Explanation: Benchmark developers should provide evaluation guidelines, with definitions of evaluation metrics, de- tailed scoring criteria, and easy-to-follow usage instructions for users to replicate the evaluation process. • Justification: Clear evaluation guide- lines help users better understand how model performanc...
-
[51]
• Justification: Disclosing limitations and risks demonstrates scientific rigor and responsibility
Discussion of Limitations and Risks • Explanation: The benchmark develop- ers should openly discuss the limitations and potential social risks of the bench- mark. • Justification: Disclosing limitations and risks demonstrates scientific rigor and responsibility. This transparency helps prevent users from misunderstanding and misusing the benchmark, especi...
-
[52]
Peer Review • Explanation: The benchmark and its corresponding paper was accepted at peer-reviewed venue. • Justification: Going through peer review process means that the design, validity and results of a benchmark has been rig- orous evaluated. It enhances credibility and ensures quality. • Scoring: – 0: The benchmark has not been ac- cepted at a peer-r...
-
[53]
on platforms like GitHub or Hugging Face) along with the applica- ble license
Accessibility of Evaluation Code and Data • Explanation: Access to the evaluation code and data, which can be shared within legal and ethical boundaries, is provided (e.g. on platforms like GitHub or Hugging Face) along with the applica- ble license. • Justification: Accessible code and data are prerequisites for reproducibility. Moreover, it allows the c...
-
[54]
• Justification: Proper usage and citation guidelines help maintain academic in- tegrity
Usage and Citation Guidelines • Explanation: Clear guidelines are pro- vided to standardize benchmark usage, result reporting, and correct citation for- mats in academic papers or technical re- ports. • Justification: Proper usage and citation guidelines help maintain academic in- tegrity. It also promote standardized re- porting of results, facilitating ...
-
[55]
Update and Version Management • Explanation: A feedback channel should be maintained for users to report problems, provide feedback and sugges- tions. • Justification: Maintaining an effective feedback channel allows users to provide feedback when issues with the bench- mark are discovered. This is crucial for continuously improving benchmark qual- ity an...
-
[56]
Feedback Channel for Users • Explanation: A feedback channel should be maintained for users to report problems, provide feedback and sugges- tions. • Justification: Maintaining an effective feedback channel allows users to provide feedback when issues with the bench- mark are discovered. This is crucial for continuously improving benchmark qual- ity and f...
-
[57]
Long-term Maintenance Responsibility • Explanation: The individuals, teams, or institutions responsible for its long-term maintenance and development should be clearly stated. • Justification: Clarifying who holds long- term responsibility reassures the commu- nity that it will be actively supported and improved, ensuring usability and credi- bility. • Sc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.