ReCode: Reinforcing Code Generation with Reasoning-Process Rewards
Pith reviewed 2026-05-19 01:06 UTC · model grok-4.3
The pith
ReCode trains code models with reasoning-process rewards gated by execution results to match GPT-4-Turbo performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
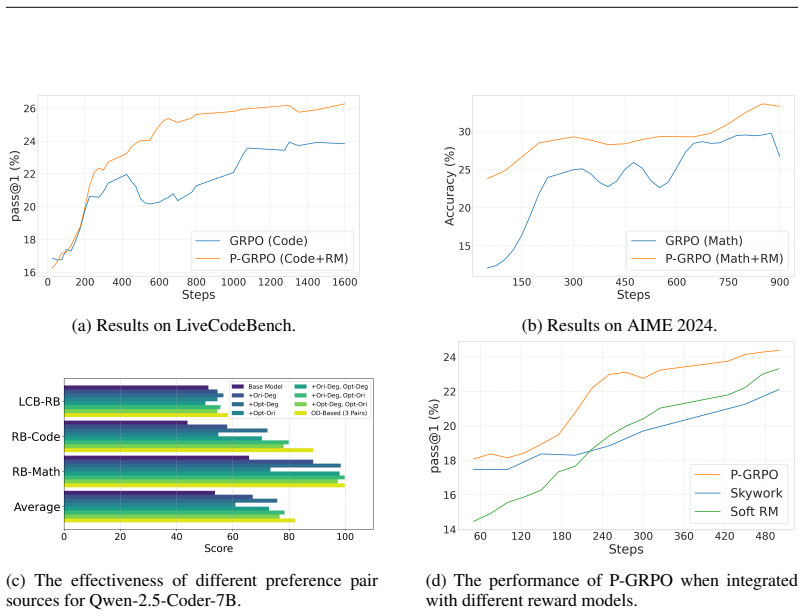
ReCode establishes that contrastive training on optimized versus degraded reasoning processes creates a useful reward model for code reasoning quality, and that gating this reward with strict execution correctness during GRPO training yields a 7B model that surpasses its base by 16.1% and performs at the level of GPT-4-Turbo on HumanEval(+), MBPP(+), LiveCodeBench, and BigCodeBench while also generalizing to mathematics.
What carries the argument
Contrastive Reasoning-Process Reward Learning (CRPL) combined with Consistency-Gated GRPO (CG-GRPO), where the latter uses execution correctness as a hard filter on the neural reward to balance process optimization with outcome reliability.
If this is right
- The trained 7B model achieves 16.1% higher performance than the base model on standard code generation benchmarks.
- ReCode reaches performance levels comparable to GPT-4-Turbo on HumanEval(+), MBPP(+), LiveCodeBench, and BigCodeBench.
- The framework generalizes from code generation to mathematical reasoning tasks.
- A new benchmark, LiveCodeBench-RewardBench, measures the ability of reward models to distinguish reasoning quality in code.
Where Pith is reading between the lines
- Similar synthesis of reasoning variants could supply preference data for other tasks where process quality matters but is hard to annotate.
- Execution-based gating might serve as a general safeguard when adding learned rewards to RL in domains with verifiable outcomes.
- This suggests that optimizing the reasoning trace separately from the final answer can improve model reliability in agent-like coding workflows.
- Extending the method to larger base models or different architectures could test whether the gains scale or saturate.
Load-bearing premise
That the automatically synthesized optimized and degraded reasoning variants create preference pairs that accurately reflect true differences in reasoning quality for producing correct code.
What would settle it
Training the reward model on the contrastive reasoning pairs and checking whether it consistently assigns higher scores to reasoning processes that result in passing test cases compared to those that fail, on problems outside the training set.
Figures






read the original abstract
In practice, rigorous reasoning is often a key driver of correct code, while Reinforcement Learning (RL) for code generation often neglects optimizing reasoning quality. Bringing process-level supervision into RL is appealing, but it faces two challenges. First, training reliable reward models to assess reasoning quality is bottlenecked by the scarcity of fine-grained preference data. Second, naively incorporating such neural rewards may suffer from reward hacking. This work proposes ReCode (Reasoning-Reinforced Code Generation), a novel RL training framework comprising: (1) Contrastive Reasoning-Process Reward Learning (CRPL), which trains a reward model with synthesized optimized and degraded reasoning variants to assess the quality of reasoning process; and (2) Consistency-Gated GRPO (CG-GRPO), which integrates the reasoning-process reward model into RL by gating neural reasoning-process rewards with strict execution outcomes, using execution correctness as a hard gate to mitigate reward hacking. Additionally, to assess the reward model's discriminative capability in assessing reasoning-process quality, we introduce LiveCodeBench-RewardBench (LCB-RB), a new benchmark comprising preference pairs of superior and inferior reasoning processes tailored for code generation. Experimental results across HumanEval(+), MBPP(+), LiveCodeBench, and BigCodeBench show that a 7B model trained with ReCode outperforms the base version by 16.1% and reaches performance comparable to GPT-4-Turbo. We further demonstrate the generalizability of ReCode by extending it to the math domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce ReCode, a RL framework for code generation consisting of CRPL for training a reasoning-process reward model using synthesized optimized and degraded variants, and CG-GRPO which gates the neural reward with execution correctness to avoid hacking. It also introduces the LCB-RB benchmark and reports that a 7B model with ReCode outperforms the base by 16.1% and is comparable to GPT-4-Turbo on multiple code benchmarks, with extension to math.
Significance. Should the synthesized variants prove to provide genuine process quality signals and the gating mechanism prove effective, the work would offer a promising direction for incorporating process-level rewards in RL for code generation, potentially improving model reliability. The new benchmark is a positive addition for evaluating such reward models.
major comments (3)
- [CRPL] The reliance on synthesized optimized and degraded reasoning variants for preference pairs in CRPL is load-bearing for the reward model. The manuscript does not provide evidence, such as human evaluation or artifact analysis, that these pairs isolate reasoning process quality rather than synthesis-induced features. This raises concerns about whether the reward model truly assesses reasoning quality as intended.
- [CG-GRPO] In CG-GRPO, gating the reasoning-process reward behind execution correctness limits its application to successful trajectories. This may prevent the reward from guiding the model to better reasoning processes when initial generations fail execution, which could undermine the goal of optimizing reasoning quality across all cases.
- [Results and ablations] The central performance claim of 16.1% improvement lacks supporting details on statistical significance, multiple runs, or ablations that separate the effects of the reward model from the gating mechanism. Without these, the evidence for the framework's effectiveness is incomplete.
minor comments (1)
- [Abstract] The abstract mentions extension to the math domain but provides no specific results or details, which could be clarified for completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [CRPL] The reliance on synthesized optimized and degraded reasoning variants for preference pairs in CRPL is load-bearing for the reward model. The manuscript does not provide evidence, such as human evaluation or artifact analysis, that these pairs isolate reasoning process quality rather than synthesis-induced features. This raises concerns about whether the reward model truly assesses reasoning quality as intended.
Authors: We appreciate this observation on the core assumption of CRPL. The synthesis procedure modifies individual reasoning steps (e.g., adding or removing logical justifications) while preserving code semantics to create contrastive pairs focused on process quality. Validation is provided via the LCB-RB benchmark, where the trained reward model demonstrates high accuracy in ranking superior versus inferior reasoning processes. That said, we agree that explicit human evaluation or qualitative artifact analysis would offer stronger corroboration that the pairs capture genuine reasoning differences rather than synthesis artifacts. We will incorporate a human study on a sampled subset of pairs in the revised version. revision: yes
-
Referee: [CG-GRPO] In CG-GRPO, gating the reasoning-process reward behind execution correctness limits its application to successful trajectories. This may prevent the reward from guiding the model to better reasoning processes when initial generations fail execution, which could undermine the goal of optimizing reasoning quality across all cases.
Authors: The gating mechanism is intentionally strict to prevent reward hacking, as ungrounded neural rewards can be exploited on incorrect trajectories. Execution correctness serves as a hard filter so that process-level rewards refine reasoning only among verifiably correct solutions. Unsuccessful trajectories continue to receive learning signals from the base GRPO objective based on execution outcomes. This design prioritizes reliable optimization over applying the neural reward universally. We will expand the discussion of this trade-off and its rationale in the revision while noting potential future relaxations of the gate. revision: partial
-
Referee: [Results and ablations] The central performance claim of 16.1% improvement lacks supporting details on statistical significance, multiple runs, or ablations that separate the effects of the reward model from the gating mechanism. Without these, the evidence for the framework's effectiveness is incomplete.
Authors: We acknowledge the need for greater statistical rigor. The manuscript already contains component ablations for CRPL and CG-GRPO, but we will augment the results section with details from multiple independent training runs, including means, standard deviations, and statistical significance tests for the reported gains. We will also present more granular ablations that isolate the contribution of the reasoning-process reward model from the consistency gate. revision: yes
Circularity Check
No significant circularity detected in ReCode framework
full rationale
The paper's core claims rest on an empirical pipeline: synthesizing optimized/degraded reasoning traces to create preference pairs for training a neural reward model (CRPL), then applying that model inside CG-GRPO where execution correctness acts as an independent hard gate. Performance gains are reported as experimental outcomes on HumanEval(+), MBPP(+), LiveCodeBench, and BigCodeBench rather than as mathematical derivations that reduce to the training inputs by construction. No equations equate the reward signal to its own synthesis procedure, no fitted parameters are relabeled as predictions, and no load-bearing uniqueness theorems or ansatzes are imported via self-citation. The external execution gate and new LCB-RB benchmark further separate the method from self-referential collapse. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Reward model parameters
axioms (2)
- domain assumption Synthesized optimized and degraded reasoning variants accurately capture differences in reasoning quality.
- domain assumption Execution correctness provides a reliable hard gate that prevents reward hacking without discarding useful reasoning signal.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the Optimized-Degraded based (OD-based) Method... generate optimized (y+) and degraded (y−) variants... three critical dimensions: Factual Accuracy, Logical Rigor, Logical Coherence... Bradley-Terry reward model
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Posterior-GRPO (P-GRPO)... thinking reward Rt is preserved... only when Ro = 1... Ri = Rf_i + Ro_i + Ro_i · Rt_i
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 7 Pith papers
-
LASER: A Data-Centric Method for Low-Cost and Efficient SQL Rewriting based on SQL-GRPO
LASER generates complex slow-query training data with MCTS and aligns small models via SQL-GRPO to deliver efficient, low-cost SQL rewriting that outperforms rules and large models.
-
Information-Consistent Language Model Recommendations through Group Relative Policy Optimization
GRPO fine-tuning with entropy-based stability rewards reduces output variability in LLMs for investment and job recommendations compared to baseline models.
-
CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment
CodeRL+ integrates variable-level execution trajectory inference into RLVR training to align textual code representations with execution semantics, delivering 4.6% relative pass@1 gains and generalization to code-reas...
-
Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
Rank-Surprisal Ratio (RSR) correlates strongly (average Spearman 0.86) with post-distillation reasoning gains across five student models and trajectories from eleven teachers, outperforming existing selection metrics.
-
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Survey that defines agentic RL for LLMs via POMDPs, introduces a taxonomy of planning/tool-use/memory/reasoning capabilities and domains, and compiles open environments from over 500 papers.
-
Code as Agent Harness
A survey that organizes existing work on LLM-based agents around code as the central harness, structured in three layers of interfaces, mechanisms, and multi-agent scaling, with applications across domains and listed ...
-
Reinforcement Learning with Negative Tests as Completeness Signal for Formal Specification Synthesis
SpecRL uses the fraction of negative tests rejected by candidate specifications as a reward signal in RL training to produce stronger and more verifiable formal specifications than prior methods.
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2021.emnlp-main.685
Notion Blog. 11 Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. InThe 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (IJCNLP-AACL ...
-
[2]
Deconstruct from First Principles: Begin by dissecting the problem statement. What is the core question? What are the explicit and implicit requirements? What are the inputs, outputs, and constraints? Break the problem down into smaller, more manageable sub-problems
-
[3]
Explicitly state what each test case teaches you
Analyze Examples and Edge Cases: Systematically use the provided examples and test cases to verify your understanding. Explicitly state what each test case teaches you
-
[4]
Brainstorm and Strategize: (1) Prioritize Optimal Approaches: Begin by brainstorming efficient strategies. First, explore algorithms and data structures that could lead to an optimal or near- optimal solution (e.g., hash maps, two-pointers, binary search, dynamic program- ming, greedy algorithms). Do not start by considering the brute-force approach. (2) ...
-
[5]
(1) Mental Walkthrough: ”Pre-run” your logic using a specific example
Develop a Step-by-Step Logical Plan: Based on your chosen strategy, create a clear, logical, and sequential plan. (1) Mental Walkthrough: ”Pre-run” your logic using a specific example. Narrate the state of your variables or data structures at each step of the plan. (2) Refine and Self-Correct: After the walkthrough, reflect on the plan. Are there any logi...
-
[6]
The goal is to illumi- nate the *how* and *why* of the solution, not just the what
Clarity and Structure: Ensure the entire reasoning process is articulated in a clear, structured manner that is easy for a human to follow. The goal is to illumi- nate the *how* and *why* of the solution, not just the what. # Output Format Your response must contain ONLY the reasoning process, formatted in Mark- down. Do not include any introductory or co...
-
[7]
Factually Incorrect Reasoning: Introduce a clear factual error into the logic. For example, misstate a core constraint from the problem, use an incorrect mathemat- ical formula, or misrepresent the time/space complexity of a known algorithm
-
[8]
This creates a distracting and inefficient reasoning path
Irrelevant or Misleading Path: Add steps that are factually correct on their own but are irrelevant to solving the actual problem. This creates a distracting and inefficient reasoning path
-
[9]
Incomplete Reasoning: The reasoning starts correctly but halts before reaching the final step, leaving the logic unfinished and the conclusion unsupported
-
[10]
Logical Gap / Jump: Remove a key intermediate step, making the jump from a premise to a conclusion seem abrupt and unsubstantiated, even if the final conclu- sion happens to be correct
-
[11]
Chaotic or Acausal Reasoning: Invert the cause-and-effect relationship, or cre- ate a sequence of steps that are logically disconnected and do not follow a coherent progression. # Execution Steps
-
[12]
Logical Gap, Factually Incorrect Reasoning
Identify Methods: Identify one or more ‘Degradation Methods’ from the inputs (e.g., a comma-separated list like “Logical Gap, Factually Incorrect Reasoning”)
-
[13]
Strategically plan how to weave all the selected degradation methods into the reasoning
Analyze & Plan: Carefully analyze the ‘Golden CoT’. Strategically plan how to weave all the selected degradation methods into the reasoning. The flaws should be as subtle as realistically possible, modelling a plausible human error
-
[14]
This section must contain ONLY the flawed reasoning itself
Generate Degraded CoT: Rewrite the CoT to create the flawed ‘[Degraded CoT]’. This section must contain ONLY the flawed reasoning itself
-
[15]
Generate Explanation: Create a concise ‘[Explanation of Degradation]’. In this section, you must clearly list each degradation method you used, and for each one, pinpoint exactly how, where, and why you altered the original reasoning. # Output Format Your response MUST be in Markdown format and strictly adhere to the two-part structure below. If multiple ...
-
[16]
If no errors are found, this method should not be applied
Factual Verification & Correction: Identifies and corrects a clear factual error within the reasoning. If no errors are found, this method should not be applied
-
[17]
Focusing Logic: Identifies and removes any redundant steps from the original reasoning. This ensures every step directly contributes to the final goal, making the entire reasoning path more focused
-
[18]
Comprehensive Reasoning: Extends a line of reasoning that may have halted prematurely or omitted final steps. This ensures the logical chain is fully closed and the conclusion is explicitly and robustly supported
-
[19]
This makes the transition from premise to conclu- sion smoother and more self-evident
Bridging Logical Gaps: Adds necessary intermediate steps between logical nodes that seemed disjointed. This makes the transition from premise to conclu- sion smoother and more self-evident
-
[20]
This ensures the entire thought process is well-structured and flows seamlessly from start to finish
Enhancing Logical Flow: Reorganizes reasoning steps to follow a clearer, more intuitive causal or hierarchical order. This ensures the entire thought process is well-structured and flows seamlessly from start to finish. # Execution Steps
-
[21]
Bridging Logical Gaps, Factual Verification
Identify Methods: Based on the ‘Optimization Methods’ above, analyze the input Golden CoT and identify one or more specific methods for application (e.g., a comma-separated list like “Bridging Logical Gaps, Factual Verification”)
-
[22]
Analyze & Plan: Carefully analyze the ‘Golden CoT’. Formulate a clear strat- egy for integrating all selected optimization methods into the new reasoning pro- cess. The goal of the optimization is to make the reasoning more rigorous, clear, and persuasive
-
[23]
This section must contain ONLY the improved reasoning itself
Generate Optimized CoT: Rewrite the CoT to create the ‘[Optimized CoT]’. This section must contain ONLY the improved reasoning itself
-
[24]
Generate Explanation: Create a concise ‘[Explanation of Optimization]’. In this section, you must clearly list each optimization method you used and, for each one, pinpoint exactly how, where, and why you improved the original reasoning. # Output Format Your response MUST be in Markdown format and strictly adhere to the two-part structure below. If multip...
-
[25]
Reasoning Soundness: Is the algorithm, logic, and step-by-step plan described in the ‘<think>‘ block a correct and robust way to solve the problem? Does this logic have flaws?
-
[26]
Implementation-Thought Consistency: Does the code in the ‘<answer>’ block faithfully implement the logic described in the ‘<think>’ block? Input Format: [Problem Description] {problem description} [Solution] {solution content} Your Task: Strictly adhere to the following two-line output format. Line 1: Output only ‘Yes’, ‘No’, or ‘None’ based on the follow...
-
[27]
Factual Errors: Does the reasoning introduce incorrect facts, misuse formulas, or misstate constraints from the problem?
-
[28]
Logical Gaps or Jumps: Are there missing steps? Does the conclusion jump from a premise without a clear, logical bridge?
-
[29]
Irrelevant or Misleading Paths: Does the reasoning include steps that, while perhaps factually correct, are irrelevant to solving the problem and create a dis- tracting or inefficient path?
-
[30]
Incomplete Reasoning: Does the reasoning start correctly but stop short of reaching a final, supported conclusion?
-
[31]
1.0: Perfectly sound reasoning
Chaotic or Acausal Structure: Is the reasoning jumbled? Does it invert cause- and-effect or present steps in an illogical, disconnected order? # Scoring Instructions Provide a single score from 0, 0.1, 0.2,..., 1.0 based on the reasoning quality. 1.0: Perfectly sound reasoning. Clear, correct, complete, and efficient. 0.7 - 0.9: Minor flaws. Contains smal...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.