ShadowNPU: System and Algorithm Co-design for NPU-Centric On-Device LLM Inference
Pith reviewed 2026-05-18 21:59 UTC · model grok-4.3
The pith
shadowAttn keeps attention on the NPU for on-device LLMs by using pilot compute to sparsely process only important tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ShadowAttn is a system-algorithm co-designed sparse attention module with minimal reliance on CPU/GPU by only sparsely calculating the attention on a tiny portion of tokens. The key idea is to hide the overhead of estimating the important tokens with a NPU-based pilot compute. Further, shadowAttn proposes NPU compute graph bucketing, head-wise NPU-CPU/GPU pipeline and per-head fine-grained sparsity ratio to achieve high accuracy and efficiency. shadowAttn delivers the best performance with highly limited CPU/GPU resource; it requires much less CPU/GPU resource to deliver on-par performance of SoTA frameworks.
What carries the argument
shadowAttn, a sparse attention module that hides token-importance estimation overhead via NPU pilot compute and applies graph bucketing, head-wise pipelining, and per-head sparsity to limit CPU/GPU use.
If this is right
- shadowAttn delivers the best performance with highly limited CPU/GPU resource.
- It requires much less CPU/GPU resource to deliver on-par performance of SoTA frameworks.
- NPU compute graph bucketing and head-wise pipeline support both accuracy and efficiency.
- Per-head fine-grained sparsity ratio allows tailored trade-offs across attention heads.
Where Pith is reading between the lines
- The pilot-compute approach for token selection could apply to other quantization-sensitive operators beyond attention.
- Devices with very constrained CPU or GPU cores might now support larger models without major accuracy trade-offs.
- System schedulers for on-device inference could become simpler by keeping nearly all work on the NPU.
Load-bearing premise
Sparsely calculating attention on only a tiny portion of tokens selected via NPU pilot compute preserves model accuracy without significant degradation.
What would settle it
A direct accuracy or perplexity comparison on a standard LLM benchmark showing substantial quality loss when replacing full attention with shadowAttn at the same sparsity level.
Figures







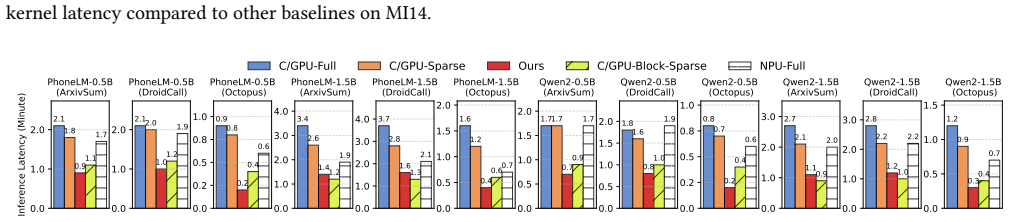

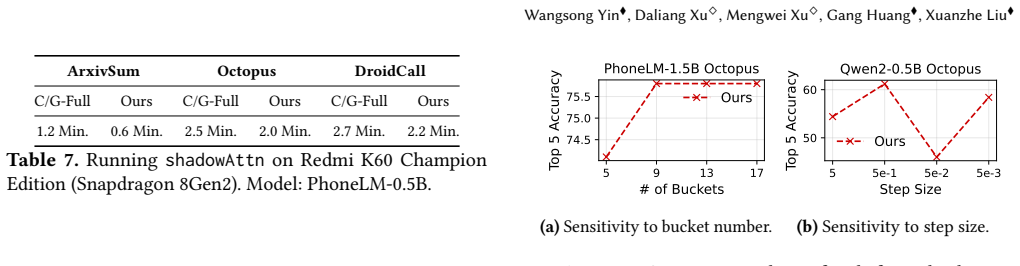
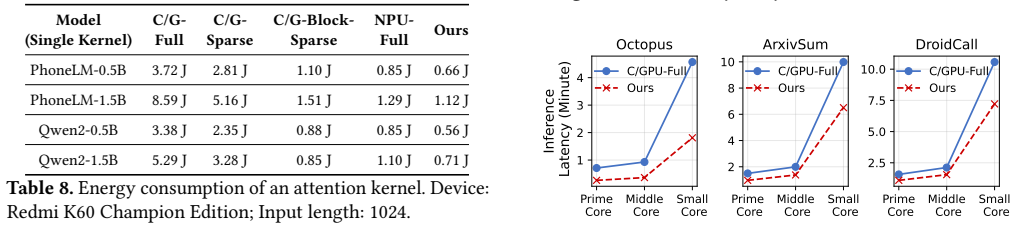

read the original abstract
On-device running Large Language Models (LLMs) is nowadays a critical enabler towards preserving user privacy. We observe that the attention operator falls back from the special-purpose NPU to the general-purpose CPU/GPU because of quantization sensitivity in state-of-the-art frameworks. This fallback results in a degraded user experience and increased complexity in system scheduling. To this end, this paper presents shadowAttn, a system-algorithm codesigned sparse attention module with minimal reliance on CPU/GPU by only sparsely calculating the attention on a tiny portion of tokens. The key idea is to hide the overhead of estimating the important tokens with a NPU-based pilot compute. Further, shadowAttn proposes insightful techniques such as NPU compute graph bucketing, head-wise NPU-CPU/GPU pipeline and per-head fine-grained sparsity ratio to achieve high accuracy and efficiency. shadowAttn delivers the best performance with highly limited CPU/GPU resource; it requires much less CPU/GPU resource to deliver on-par performance of SoTA frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ShadowNPU, a system-algorithm co-design for NPU-centric on-device LLM inference. It introduces shadowAttn, a sparse attention module that hides token-importance estimation overhead inside an NPU-based pilot compute, then performs attention only on a tiny selected token subset. Additional techniques include NPU compute-graph bucketing, head-wise NPU-CPU/GPU pipelining, and per-head fine-grained sparsity ratios. The central claim is that shadowAttn achieves on-par accuracy with state-of-the-art frameworks while requiring substantially less CPU/GPU resource.
Significance. If the accuracy-preservation claim holds under realistic workloads, the work would be a practical advance for on-device LLMs: it directly attacks the quantization-induced fallback of attention to CPU/GPU, which currently degrades latency and complicates scheduling. The co-design emphasis and explicit handling of NPU graph constraints are strengths that could influence future hardware-software interfaces for quantized inference.
major comments (2)
- [Abstract, §4] Abstract and §4 (evaluation): the central claim that shadowAttn 'delivers the best performance with highly limited CPU/GPU resource' and 'on-par performance of SoTA frameworks' is stated without any quantitative numbers, error bars, or ablation tables in the abstract and is only weakly supported in the evaluation description. Without measured accuracy deltas, latency breakdowns, or resource-usage figures, the load-bearing performance assertion cannot be assessed.
- [§3.2] §3.2 (shadowAttn pilot): the assumption that NPU-pilot-selected sparse attention preserves accuracy is load-bearing yet unsupported by concrete evidence. The manuscript does not report the pilot's approximation error relative to full attention, nor does it show token-selection stability across context lengths or model scales; if the pilot misses high-attention tokens, the 'on-par' result collapses even if CPU/GPU usage drops.
minor comments (2)
- [Figure 3] Figure 3 (pipeline diagram): the head-wise NPU-CPU/GPU pipeline is difficult to follow because the figure lacks explicit timing annotations or resource-occupancy bars; adding these would clarify the claimed overlap benefit.
- [§3.3] §3.3: the per-head fine-grained sparsity ratio is introduced without a precise formula or pseudocode; a short algorithmic listing would remove ambiguity about how the ratio is computed and applied at runtime.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the quantitative support for our claims and providing additional evidence for accuracy preservation. We address each major comment below and have made revisions to the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (evaluation): the central claim that shadowAttn 'delivers the best performance with highly limited CPU/GPU resource' and 'on-par performance of SoTA frameworks' is stated without any quantitative numbers, error bars, or ablation tables in the abstract and is only weakly supported in the evaluation description. Without measured accuracy deltas, latency breakdowns, or resource-usage figures, the load-bearing performance assertion cannot be assessed.
Authors: We agree that the abstract would benefit from explicit quantitative results to make the performance claims more concrete and assessable. In the revised manuscript we have updated the abstract to include specific metrics such as CPU/GPU resource reduction percentages and accuracy deltas relative to SoTA frameworks. For §4, the original evaluation already contains direct comparisons, but we have expanded it with additional tables reporting accuracy deltas, per-component latency breakdowns, resource-usage figures, and error bars derived from repeated runs to more robustly substantiate the central claims. revision: yes
-
Referee: [§3.2] §3.2 (shadowAttn pilot): the assumption that NPU-pilot-selected sparse attention preserves accuracy is load-bearing yet unsupported by concrete evidence. The manuscript does not report the pilot's approximation error relative to full attention, nor does it show token-selection stability across context lengths or model scales; if the pilot misses high-attention tokens, the 'on-par' result collapses even if CPU/GPU usage drops.
Authors: We acknowledge the value of explicit quantification for the pilot's fidelity. In the revised §3.2 we have added a new analysis subsection that reports the pilot's approximation error (measured as the L1 difference in attention scores versus full attention) and includes experiments demonstrating token-selection stability across multiple context lengths and model scales. These additions show that the selected token subsets reliably capture high-attention tokens, thereby supporting the observed accuracy preservation while still reducing CPU/GPU fallback. revision: yes
Circularity Check
No significant circularity in engineering co-design
full rationale
The paper presents shadowAttn as a practical system-algorithm co-design for NPU-centric sparse attention, relying on techniques such as NPU pilot compute for token selection, graph bucketing, head-wise pipelining, and per-head sparsity ratios. These are described as engineering choices validated through implementation and benchmarking rather than derived quantities. No equations, predictions, or first-principles results reduce by construction to fitted inputs or self-referential definitions. Claims of on-par accuracy and reduced CPU/GPU usage are framed as empirical outcomes, not tautological re-statements of the design itself. Self-citations, if present, are not load-bearing for any central mathematical result. The derivation chain is self-contained as an applied systems contribution.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
shadowAttn offloads the estimation to NPU... only a small portion of tokens are computed on CPU/GPU with high precision float operations... per-head fine-grained sparsity ratio
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NPU compute graph bucketing... scale factor buckets... step size 5e-1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Efficient Mixture-of-Experts LLM Inference with Apple Silicon NPUs
NPUMoE accelerates MoE LLM inference on Apple Silicon NPUs via offline-calibrated static expert tiers, grouped execution, and load-aware graph residency, delivering 1.32x-5.55x lower latency and 1.81x-7.37x better ene...
-
EdgeFlow: Fast Cold Starts for LLMs on Mobile Devices
EdgeFlow reduces mobile LLM cold-start latency up to 4.07x versus llama.cpp, MNN, and llm.npu by NPU-aware adaptive quantization, SIMD-friendly packing, and synergistic granular CPU-NPU pipelining at comparable accuracy.
Reference graph
Works this paper leans on
- [1]
-
[2]
2025. Hexagon NPU SDK. https://www.qualcomm.com/developer/ software/hexagon-npu-sdk
work page 2025
-
[3]
2025. LLVM. https://llvm.org/
work page 2025
-
[4]
2025. Nvidia Jetson Orin. https://www.nvidia.com/en-us/autonomous- machines/embedded-systems/jetson-orin/
work page 2025
-
[5]
2025. Open CL. https://en.wikipedia.org/wiki/OpenCL
work page 2025
-
[6]
2025. QNN SDK. https://docs.qualcomm.com/bundle/publicresource/ topics/80-63442-50/introduction.html
work page 2025
-
[7]
Qualcomm Neural Processing Engine
2025. Qualcomm Neural Processing Engine. https://docs.qualcomm. com/bundle/publicresource/topics/80-70015-15BY/snpe.html
work page 2025
-
[8]
2025. rewind. https://www.rewind.ai/
work page 2025
-
[9]
Snapdragon 8 gen 3 mobile platform product brief
2025. Snapdragon 8 gen 3 mobile platform product brief. https://docs.qualcomm.com/bundle/publicresource/87-71408-1_ REV_C_Snapdragon_8_gen_3_Mobile_Platform_Product_Brief.pdf
work page 2025
-
[10]
TMS320F2812 platform product brief
2025. TMS320F2812 platform product brief. https://www.ti.com/ product/TMS320F2812
work page 2025
-
[11]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin and etc. Jyoti Aneja. 2024. Phi-3 Technical Re- port: A Highly Capable Language Model Locally on Your Phone. arXiv:2404.14219 [cs.CL] https://arxiv.org/abs/2404.14219
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Ozan Baris, Yizhuo Chen, Gaofeng Dong, Liying Han, Tomoyoshi Kimura, Pengrui Quan, Ruijie Wang, Tianchen Wang, Tarek Ab- delzaher, Mario Bergés, Paul Pu Liang, and Mani Srivastava. 2025. Foundation Models for CPS-IoT: Opportunities and Challenges. arXiv:2501.16368 [cs.LG] https://arxiv.org/abs/2501.16368
-
[14]
Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, and Pavlo Molchanov
-
[15]
Small Language Models are the Future of Agentic AI
Small Language Models are the Future of Agentic AI. arXiv:2506.02153 [cs.AI] https://arxiv.org/abs/2506.02153
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. 2025. A Survey on Mixture of Experts in Large Language Models. IEEE Transactions on Knowledge and Data Engineering (2025), 1–20. doi: 10.1109/tkde.2025.3554028
- [17]
- [18]
-
[19]
Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. 2018. A Discourse- Aware Attention Model for Abstractive Summarization of Long Doc- uments. In Proceedings of the 2018 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Hu- man Language Technologies, Volume 2...
-
[20]
Ziyan Fu, Ju Ren, Deyu Zhang, Yuezhi Zhou, and Yaoxue Zhang. 2022. Kalmia: A Heterogeneous QoS-aware Scheduling Framework for DNN Tasks on Edge Servers. In IEEE INFOCOM 2022 - IEEE Conference on Computer Communications. 780–789. doi: 10.1109/INFOCOM48880. 2022.9796661
-
[21]
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. 2024. Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs. arXiv:2310.01801 [cs.CL] https://arxiv. org/abs/2310.01801
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
ggml. 2025. llama.cpp. https://github.com/ggml-org/llama.cpp
work page 2025
-
[23]
Joo Seong Jeong, Jingyu Lee, Donghyun Kim, Changmin Jeon, Changjin Jeong, Youngki Lee, and Byung-Gon Chun. 2022. Band: co- ordinated multi-DNN inference on heterogeneous mobile processors. In Proceedings of the 20th Annual International Conference on Mobile Systems, Applications and Services (Portland, Oregon) (MobiSys ’22). Association for Computing Mach...
-
[24]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.068...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xu- fang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024. MInference 1.0: Ac- celerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention. arXiv:2407.02490 [cs.CL] https://arxiv.org/abs/2407.02490
- [26]
-
[27]
Ko, Sangeun Oh, and Insik Shin
Sunjae Lee, Junyoung Choi, Jungjae Lee, Munim Hasan Wasi, Hojun Choi, Steven Y. Ko, Sangeun Oh, and Insik Shin. 2024. Explore, Select, Derive, and Recall: Augmenting LLM with Human-like Memory for Mobile Task Automation. arXiv:2312.03003 [cs.HC] https://arxiv.org/ abs/2312.03003
- [28]
-
[29]
Xiang Li, Zhenyan Lu, Dongqi Cai, Xiao Ma, and Mengwei Xu
-
[30]
Large Language Models on Mobile Devices: Measurements, Analysis, and Insights. In Proceedings of the Workshop on Edge and Mobile Foundation Models (Minato-ku, Tokyo, Japan) (EdgeFM ’24). Association for Computing Machinery, New York, NY, USA, 1–6. doi:10.1145/3662006.3662059
-
[31]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. arXiv:2306.00978 [cs.CL] https: //arxiv.org/abs/2306.00978
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Kaiwei Liu, Bufang Yang, Lilin Xu, Yunqi Guo, Guoliang Xing, Xian Shuai, Xiaozhe Ren, Xin Jiang, and Zhenyu Yan. 2025. TaskSense: A Translation-like Approach for Tasking Heterogeneous Sensor Systems with LLMs. Association for Computing Machinery, New York, NY, 12 Dynamic Sparse Attention on Mobile SoCs USA, 213–225. https://doi.org/10.1145/3715014.3722070
- [33]
- [34]
-
[35]
MoBA: Mixture of Block Attention for Long-Context LLMs
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, Zhiqi Huang, Huan Yuan, Suting Xu, Xinran Xu, Guokun Lai, Yanru Chen, Huabin Zheng, Junjie Yan, Jianlin Su, Yuxin Wu, Neo Y. Zhang, Zhilin Yang, Xinyu Zhou, Mingxing Zhang, and Jiezhong Qiu. 2025. MoBA: Mixture of Block Attention for Long...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei
-
[37]
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits. arXiv:2402.17764 [cs.CL] https://arxiv.org/abs/2402.17764
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher
-
[39]
Pointer Sentinel Mixture Models
Pointer Sentinel Mixture Models. arXiv:1609.07843 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Melkamu Mersha, Khang Lam, Joseph Wood, Ali K. AlShami, and Jugal Kalita. 2024. Explainable artificial intelligence: A survey of needs, techniques, applications, and future direction. Neurocomputing 599 (Sept. 2024), 128111. doi: 10.1016/j.neucom.2024.128111
- [41]
- [42]
-
[43]
Xiaomin Ouyang, Xian Shuai, Yang Li, Li Pan, Xifan Zhang, Hem- ing Fu, Sitong Cheng, Xinyan Wang, Shihua Cao, Jiang Xin, Hazel Mok, Zhenyu Yan, Doris Sau Fung Yu, Timothy Kwok, and Guo- liang Xing. 2024. ADMarker: A Multi-Modal Federated Learning System for Monitoring Digital Biomarkers of Alzheimer’s Disease. arXiv:2310.15301 [cs.LG] https://arxiv.org/ab...
-
[44]
Jun-Seok Park, Changsoo Park, Suknam Kwon, Taeho Jeon, Yesung Kang, Heonsoo Lee, Dongwoo Lee, James Kim, Hyeong-Seok Kim, YoungJong Lee, Sangkyu Park, MinSeong Kim, SangHyuck Ha, Jihoon Bang, Jinpyo Park, SukHwan Lim, and Inyup Kang. 2023. A Multi- Mode 8k-MAC HW-Utilization-Aware Neural Processing Unit With a Unified Multi-Precision Datapath in 4-nm Flag...
- [45]
-
[46]
phonelm. 2025. PhoneLM-0.5B. https://huggingface.co/unsloth/ PhoneLM-0.5B
work page 2025
-
[47]
phonelm. 2025. PhoneLM-1.5B. https://huggingface.co/unsloth/ PhoneLM-1.5B
work page 2025
-
[48]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
qwen. 2025. Qwen2-0.5B. https://huggingface.co/unsloth/Qwen2-0.5B
work page 2025
-
[50]
qwen. 2025. Qwen2-1.5B. https://huggingface.co/unsloth/Qwen2-1.5B
work page 2025
-
[51]
redmi. 2025. Redmi K60 Champion Edition Smartphone . https://www. gsmarena.com/xiaomi_redmi_k60_pro-12046.php
work page 2025
-
[52]
Tanmoy Sen, Haiying Shen, and Anand Padmanabha Iyer. 2025. Flex: Fast, Accurate DNN Inference on Low-Cost Edges Using Heteroge- neous Accelerator Execution. In Proceedings of the Twentieth Euro- pean Conference on Computer Systems (Rotterdam, Netherlands) (Eu- roSys ’25). Association for Computing Machinery, New York, NY, USA, 507–523. doi: 10.1145/368903...
-
[53]
Andrii Skliar, Ties van Rozendaal, Romain Lepert, Todor Boinovski, Mart van Baalen, Markus Nagel, Paul Whatmough, and Babak Eht- eshami Bejnordi. 2025. Mixture of Cache-Conditional Experts for Efficient Mobile Device Inference. arXiv:2412.00099 [cs.LG] https: //arxiv.org/abs/2412.00099
-
[54]
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2023. RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864 [cs.CL] https://arxiv.org/abs/ 2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Shreyas Subramanian, Vikram Elango, and Mecit Gungor. 2025. Small Language Models (SLMs) Can Still Pack a Punch: A survey. arXiv:2501.05465 [cs.CL] https://arxiv.org/abs/2501.05465
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Xin Tan, Yimin Jiang, Yitao Yang, and Hong Xu. 2025. Towards End-to- End Optimization of LLM-based Applications with Ayo. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (Rotterdam, Netherlands) (ASPLOS ’25). Association for Computing Machinery, New York, NY, USA, 13...
-
[57]
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. 2024. Quest: Query-Aware Sparsity for Efficient Long- Context LLM Inference. arXiv:2406.10774 [cs.CL] https://arxiv.org/ abs/2406.10774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
TFLite team. 2025. mediapipe. https://ai.google.dev/edge/mediapipe/ solutions/guide
work page 2025
-
[59]
Mobillama: Towards accurate and lightweight fully transparent gpt
Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, and Fahad Shahbaz Khan. 2024. MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT. arXiv:2402.16840 [cs.CL] https: //arxiv.org/abs/2402.16840
-
[60]
Hanrui Wang, Zhekai Zhang, and Song Han. 2021. SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning. HPCA (2021)
work page 2021
-
[61]
Jianyu Wei, Ting Cao, Shijie Cao, Shiqi Jiang, Shaowei Fu, Mao Yang, Yanyong Zhang, and Yunxin Liu. 2023. NN-Stretch: Automatic Neural Network Branching for Parallel Inference on Heterogeneous Multi- Processors. In Proceedings of the 21st Annual International Conference on Mobile Systems, Applications and Services (Helsinki, Finland) (Mo- biSys ’23). Asso...
- [62]
-
[63]
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. 2024. DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads. arXiv:2410.10819 [cs.CL] https://arxiv.org/abs/2410.10819
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
xiaomi. 2025. MI14 Smartphone. https://www.mi.com/global/product/ xiaomi-14/specs/
work page 2025
- [65]
-
[66]
Daliang Xu, Wangsong Yin, Hao Zhang, Xin Jin, Ying Zhang, Shiyun Wei, Mengwei Xu, and Xuanzhe Liu. 2025. EdgeLLM: Fast On-Device LLM Inference With Speculative Decoding. IEEE Transactions on Mobile Computing 24, 4 (2025), 3256–3273. doi: 10.1109/TMC.2024. 3513457 13 Wangsong Yin♦, Daliang Xu^, Mengwei Xu^, Gang Huang♦, Xuanzhe Liu♦
-
[67]
Daliang Xu, Hao Zhang, Liming Yang, Ruiqi Liu, Gang Huang, Meng- wei Xu, and Xuanzhe Liu. 2025. Fast On-device LLM Inference with NPUs. In Proceedings of the 30th ACM International Confer- ence on Architectural Support for Programming Languages and Op- erating Systems, Volume 1 (Rotterdam, Netherlands) (ASPLOS ’25). Association for Computing Machinery, Ne...
-
[68]
Mengwei Xu, Dongqi Cai, Wangsong Yin, Shangguang Wang, Xin Jin, and Xuanzhe Liu. 2025. Resource-efficient Algorithms and Systems of Foundation Models: A Survey. ACM Comput. Surv. 57, 5, Article 110 (Jan. 2025), 39 pages. doi: 10.1145/3706418
-
[69]
Mengwei Xu, Wangsong Yin, Dongqi Cai, Rongjie Yi, Daliang Xu, Qipeng Wang, Bingyang Wu, Yihao Zhao, Chen Yang, Shihe Wang, Qiyang Zhang, Zhenyan Lu, Li Zhang, Shangguang Wang, Yuanchun Li, Yunxin Liu, Xin Jin, and Xuanzhe Liu. 2024. A Sur- vey of Resource-efficient LLM and Multimodal Foundation Models. arXiv:2401.08092 [cs.LG] https://arxiv.org/abs/2401.08092
- [70]
- [71]
-
[72]
Bufang Yang, Lilin Xu, Liekang Zeng, Kaiwei Liu, Siyang Jiang, Wenrui Lu, Hongkai Chen, Xiaofan Jiang, Guoliang Xing, and Zhenyu Yan
-
[73]
arXiv:2505.14668 [cs.AI] https: //arxiv.org/abs/2505.14668
ContextAgent: Context-Aware Proactive LLM Agents with Open-World Sensory Perceptions. arXiv:2505.14668 [cs.AI] https: //arxiv.org/abs/2505.14668
- [74]
-
[75]
Juheon Yi and Youngki Lee. 2020. Heimdall: mobile GPU coordination platform for augmented reality applications. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking (London, United Kingdom) (MobiCom ’20). Association for Computing Machinery, New York, NY, USA, Article 35, 14 pages. doi: 10.1145/ 3372224.3419192
-
[76]
Wangsong Yin, Daliang Xu, Gang Huang, Ying Zhang, Shiyun Wei, Mengwei Xu, and Xuanzhe Liu. 2024. PieBridge: Fast and Parameter- Efficient On-Device Training via Proxy Networks. In Proceedings of the 22nd ACM Conference on Embedded Networked Sensor Systems (Hangzhou, China) (SenSys ’24). Association for Computing Machinery, New York, NY, USA, 126–140. doi:...
- [77]
- [78]
-
[79]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y. X. Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. 2025. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. arXiv:2502.11089 [cs.CL] https://arxiv.org/abs/2502.11089
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. 2025. Spargeattn: Accurate sparse attention accelerating any model inference. InInternational Conference on Machine Learning (ICML)
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.