HERO: Hierarchical Extrapolation and Refresh for Efficient World Models
Pith reviewed 2026-05-18 22:06 UTC · model grok-4.3
The pith
A hierarchical framework accelerates inference in diffusion-based world models by selectively refreshing shallow features and extrapolating deeper ones for 1.73 times speedup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
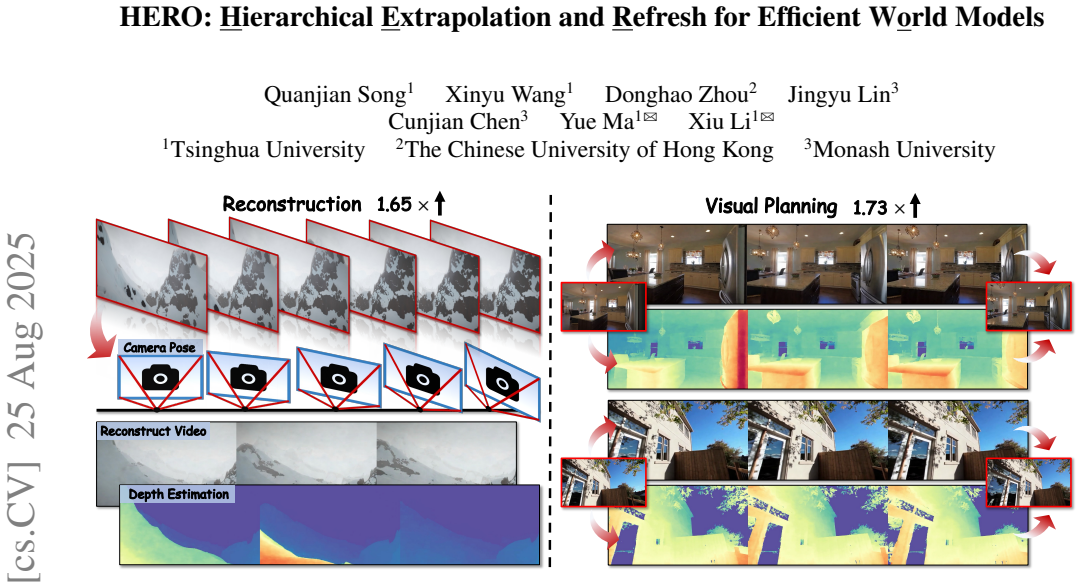
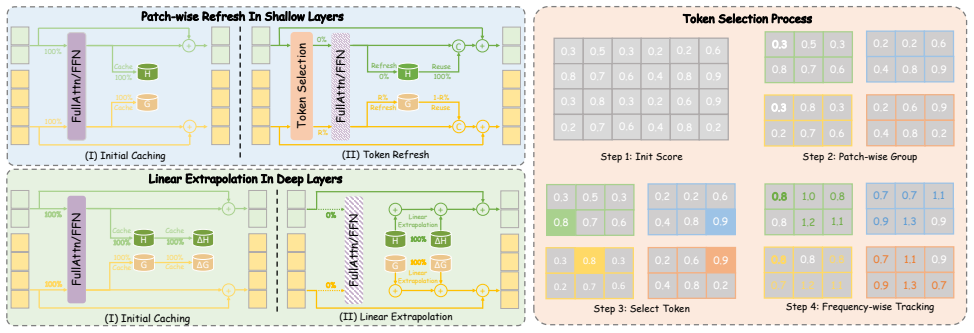
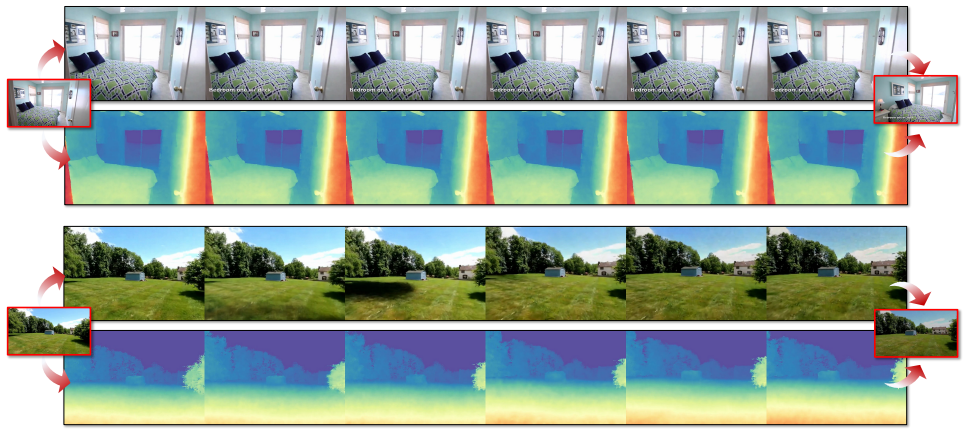
The paper claims that due to the feature coupling phenomenon in world models, where shallow layers exhibit high temporal variability and deeper layers yield stable feature representations, a hierarchical acceleration can be achieved. Shallow layers use a patch-wise refresh mechanism with patch-wise sampling and frequency-aware tracking to select tokens for recomputation, compatible with FlashAttention. Deeper layers use linear extrapolation to estimate intermediate features, bypassing attention and feed-forward network computations. Experiments demonstrate a 1.73× speedup with minimal quality degradation, significantly better than existing diffusion acceleration methods.
What carries the argument
The feature coupling phenomenon separating variable shallow layers from stable deeper layers, supported by patch-wise refresh mechanism and linear extrapolation scheme.
Load-bearing premise
The feature coupling phenomenon holds in the tested world models, with shallow layers showing high temporal variability and deeper layers providing stable representations suitable for extrapolation.
What would settle it
Applying the hierarchical refresh and extrapolation to a diffusion world model and checking if the measured speedup is near 1.73 times while quality degradation stays minimal; a large quality drop or lack of speedup would disprove the claim.
Figures







read the original abstract
Generation-driven world models create immersive virtual environments but suffer slow inference due to the iterative nature of diffusion models. While recent advances have improved diffusion model efficiency, directly applying these techniques to world models introduces limitations such as quality degradation. In this paper, we present HERO, a training-free hierarchical acceleration framework tailored for efficient world models. Owing to the multi-modal nature of world models, we identify a feature coupling phenomenon, wherein shallow layers exhibit high temporal variability, while deeper layers yield more stable feature representations. Motivated by this, HERO adopts hierarchical strategies to accelerate inference: (i) In shallow layers, a patch-wise refresh mechanism efficiently selects tokens for recomputation. With patch-wise sampling and frequency-aware tracking, it avoids extra metric computation and remain compatible with FlashAttention. (ii) In deeper layers, a linear extrapolation scheme directly estimates intermediate features. This completely bypasses the computations in attention modules and feed-forward networks. Our experiments show that HERO achieves a 1.73$\times$ speedup with minimal quality degradation, significantly outperforming existing diffusion acceleration methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HERO, a training-free hierarchical acceleration framework for diffusion-based world models. It identifies a 'feature coupling phenomenon' in which shallow layers exhibit high temporal variability while deeper layers produce more stable feature representations. Motivated by this observation, HERO applies a patch-wise refresh mechanism (with patch-wise sampling and frequency-aware tracking) in shallow layers and a linear extrapolation scheme in deeper layers that bypasses attention and FFN computations entirely. The central experimental claim is a 1.73× speedup with minimal quality degradation that outperforms existing diffusion acceleration methods.
Significance. If the feature-coupling observation holds and the extrapolation does not introduce undetected compounding errors, the training-free hierarchical design could enable practical speedups for world-model rollouts while remaining compatible with FlashAttention. The absence of fitted parameters and the explicit motivation from an observed layer-wise phenomenon are positive attributes that distinguish the work from purely empirical acceleration techniques.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the claim of '1.73× speedup with minimal quality degradation' is stated without any description of the quality metric, the baselines, the dataset or rollout length, or statistical significance; this directly undermines verification of the central performance claim.
- [§3.2] §3.2 (Linear Extrapolation): no explicit equation is given for the extrapolation operator, nor any bound on accumulated error across temporal steps; because the method bypasses all attention and FFN compute in deeper layers, the absence of such analysis is load-bearing for the quality-preservation claim.
- [§3.1 and §4] §3.1 and §4: the partitioning into 'high temporal variability' shallow layers and 'stable' deeper layers is justified solely by the asserted feature-coupling phenomenon, yet the manuscript provides neither per-layer variability statistics nor an ablation that isolates extrapolation error from the refresh mechanism.
minor comments (1)
- [Abstract] The abstract uses LaTeX notation (1.73$×$) that should be rendered consistently in the body text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments have helped us identify areas where the manuscript can be strengthened for clarity and rigor. We address each major comment point by point below, indicating the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of '1.73× speedup with minimal quality degradation' is stated without any description of the quality metric, the baselines, the dataset or rollout length, or statistical significance; this directly undermines verification of the central performance claim.
Authors: We agree that the abstract and experimental section require more explicit details to allow verification of the central claim. In the revised manuscript, we have expanded the abstract to specify the quality metrics (PSNR, SSIM, and FID), the compared baselines (recent diffusion acceleration methods), the evaluation dataset, the rollout lengths tested (up to 100 frames), and that results are reported as averages over multiple random seeds with standard deviations. Parallel expansions with tables and statistical details have been added to §4. revision: yes
-
Referee: [§3.2] §3.2 (Linear Extrapolation): no explicit equation is given for the extrapolation operator, nor any bound on accumulated error across temporal steps; because the method bypasses all attention and FFN compute in deeper layers, the absence of such analysis is load-bearing for the quality-preservation claim.
Authors: We thank the referee for highlighting this omission. The revised §3.2 now includes the explicit equation for the linear extrapolation operator: given stable features f_t and f_{t-1} in deeper layers, the estimate at step t+1 is f_{t+1} = 2 f_t - f_{t-1}. We have also added a short analysis of error accumulation, supported by empirical measurements showing that the per-step extrapolation error remains small and does not compound noticeably over the evaluated rollout horizons due to the observed feature stability. While a fully rigorous theoretical bound would require stronger assumptions on feature dynamics, the added empirical characterization directly addresses the quality-preservation concern. revision: yes
-
Referee: [§3.1 and §4] §3.1 and §4: the partitioning into 'high temporal variability' shallow layers and 'stable' deeper layers is justified solely by the asserted feature-coupling phenomenon, yet the manuscript provides neither per-layer variability statistics nor an ablation that isolates extrapolation error from the refresh mechanism.
Authors: The feature-coupling observation originated from our internal analysis of temporal feature differences across layers. To make this transparent, the revised §3.1 now includes per-layer variability statistics (mean temporal L2 differences and variance of feature deltas between consecutive frames) that quantitatively justify the shallow/deep partitioning. In addition, §4 has been augmented with an ablation study that reports results for (i) patch-wise refresh only, (ii) linear extrapolation only, and (iii) the full hierarchical HERO combination, thereby isolating the error contribution of each component. revision: yes
Circularity Check
No circularity: empirical observation motivates training-free method with independent experimental validation
full rationale
The paper identifies the feature coupling phenomenon via direct observation in world model layers and uses it to motivate a hierarchical strategy of patch-wise refresh in shallow layers plus linear extrapolation in deeper layers. The claimed 1.73× speedup is shown through experiments rather than any derivation that reduces to fitted parameters or self-citations. No equations, uniqueness theorems, or ansatzes are presented that collapse the result to its own inputs by construction. The approach remains self-contained against external benchmarks as a standard empirical acceleration technique.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feature coupling phenomenon: shallow layers exhibit high temporal variability while deeper layers yield more stable feature representations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
shallow layers exhibit high temporal variability, while deeper layers yield more stable feature representations... linear extrapolation scheme directly estimates intermediate features... bypasses the computations in attention modules and feed-forward networks
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HERO achieves a 1.73× speedup with minimal quality degradation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
OmniShow: Unifying Multimodal Conditions for Human-Object Interaction Video Generation
OmniShow unifies text, image, audio, and pose conditions into an end-to-end model for high-quality human-object interaction video generation and introduces the HOIVG-Bench benchmark, claiming state-of-the-art results.
-
Video Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms
Video generation models can function as world simulators if efficiency gaps in spatiotemporal modeling are bridged via organized paradigms, architectures, and algorithms.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foun- dation model platform for physical ai. arXiv preprint arXiv:2501.03575, 2025. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. In CVPR, 2025. 1, 3
work page 2025
-
[5]
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. In CVPR, 2025. 1
work page 2025
-
[6]
A naturalistic open source movie for opti- cal flow evaluation
Daniel J Butler, Jonas Wulff, Garrett B Stanley, and Michael J Black. A naturalistic open source movie for opti- cal flow evaluation. In ECCV, 2012. 6, 10
work page 2012
-
[7]
An empirical study of gpt-4o image generation capabilities
Sixiang Chen, Jinbin Bai, Zhuoran Zhao, Tian Ye, Qingyu Shi, Donghao Zhou, Wenhao Chai, Xin Lin, Jianzong Wu, Chao Tang, et al. An empirical study of gpt-4o image gen- eration capabilities. arXiv preprint arXiv:2504.05979, 2025. 1
-
[8]
Flashattention: Fast and memory-efficient exact at- tention with io-awareness
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christo- pher R´e. Flashattention: Fast and memory-efficient exact at- tention with io-awareness. Advances in neural information processing systems, 2022. 2, 5
work page 2022
-
[9]
Structural pruning for diffusion models
Gongfan Fang, Xinyin Ma, and Xinchao Wang. Structural pruning for diffusion models. In NeurIPS, 2023. 2
work page 2023
-
[10]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Moham- mad Norouzi. Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603, 2019. 3
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[11]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. In CVPR, 2024. 6
work page 2024
-
[13]
Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S Ryoo, and Tian Xie. Adaptive caching for faster video generation with diffu- sion transformers. arXiv preprint arXiv:2411.02397, 2024. 2, 4, 6, 10
-
[14]
Token fusion: Bridging the gap between token pruning and token merging
Minchul Kim, Shangqian Gao, Yen-Chang Hsu, Yilin Shen, and Hongxia Jin. Token fusion: Bridging the gap between token pruning and token merging. In WACV, 2024. 2
work page 2024
-
[15]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
From reusing to forecasting: Accelerating diffusion models with taylorseers
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accelerating diffusion models with taylorseers. In ICCV, 2025. 2, 4, 6, 7, 10
work page 2025
-
[17]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jian- feng Gao, et al. Sora: A review on background, technology, 8 limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. NeurIPS,
-
[19]
One-step diffusion distillation through score implicit matching
Weijian Luo, Zemin Huang, Zhengyang Geng, J Zico Kolter, and Guo-jun Qi. One-step diffusion distillation through score implicit matching. NeurIPS, 2024. 2
work page 2024
-
[20]
Transformer-based world models are happy with 100k interactions
Jan Robine, Marc H ¨oftmann, Tobias Uelwer, and Stefan Harmeling. Transformer-based world models are happy with 100k interactions. arXiv preprint arXiv:2303.07109, 2023. 3
-
[21]
GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fe- doseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. Gaia-2: A controllable multi-view generative world model for autonomous driving. arXiv preprint arXiv:2503.20523,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Post-training quantization on diffusion models
Yuzhang Shang, Zhihang Yuan, Bin Xie, Bingzhe Wu, and Yan Yan. Post-training quantization on diffusion models. In CVPR, 2023. 2
work page 2023
-
[23]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. De- noising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[24]
Aether: Geometric-aware uni- fied world modeling
Aether Team, Haoyi Zhu, Yifan Wang, Jianjun Zhou, Wen- zheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Chunhua Shen, Jiangmiao Pang, et al. Aether: Geometric-aware uni- fied world modeling. In ICCV, 2025. 1, 2, 3, 5, 6, 10
work page 2025
-
[25]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Bap- tiste Rozi `ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. arXiv preprint arXiv:2501.12387, 2025. 6
-
[29]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. In CVPR, 2024. 6
work page 2024
-
[30]
Junyi Wu, Zhiteng Li, Zheng Hui, Yulun Zhang, Linghe Kong, and Xiaokang Yang. Quantcache: Adaptive importance-guided quantization with hierarchical latent and layer caching for video generation. arXiv preprint arXiv:2503.06545, 2025. 2
-
[31]
Daydreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. In CoRL, 2023. 1, 3
work page 2023
-
[32]
Perflow: Piecewise rectified flow as universal plug-and-play accelerator
Hanshu Yan, Xingchao Liu, Jiachun Pan, Jun Hao Liew, Qiang Liu, and Jiashi Feng. Perflow: Piecewise rectified flow as universal plug-and-play accelerator. NeurIPS, 2024. 2
work page 2024
-
[33]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. In ICLR, 2025. 3, 5, 6
work page 2025
-
[34]
One-step diffusion with distribution matching distillation
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In CVPR, 2024. 2
work page 2024
-
[35]
Evelyn Zhang, Jiayi Tang, Xuefei Ning, and Linfeng Zhang. Training-free and hardware-friendly acceleration for diffu- sion models via similarity-based token pruning. In AAAI,
-
[36]
Effortless efficiency: Low-cost pruning of diffusion models
Yang Zhang, Er Jin, Yanfei Dong, Ashkan Khakzar, Philip Torr, Johannes Stegmaier, and Kenji Kawaguchi. Effort- less efficiency: Low-cost pruning of diffusion models. arXiv preprint arXiv:2412.02852, 2024. 2
-
[37]
Chang Zou, Evelyn Zhang, Runlin Guo, Haohang Xu, Con- ghui He, Xuming Hu, and Linfeng Zhang. Accelerating dif- fusion transformers with dual feature caching.arXiv preprint arXiv:2412.18911, 2024. 2
-
[38]
Accelerating diffusion transformers with token- wise feature caching
Chang Zou, Xuyang Liu, Ting Liu, Siteng Huang, and Lin- feng Zhang. Accelerating diffusion transformers with token- wise feature caching. In ICLR, 2025. 2, 4, 6, 10 9 A. Additional Implementation Details We provide more detailed implementation settings to facil- itate reproducibility. As described in the main paper, we adopt Aether [24], a recent state-of...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.