Draw-In-Mind: Rebalancing Designer-Painter Roles in Unified Multimodal Models Benefits Image Editing
Pith reviewed 2026-05-18 19:59 UTC · model grok-4.3
The pith
Rebalancing design and painting roles between understanding and generation modules improves precise image editing in unified multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
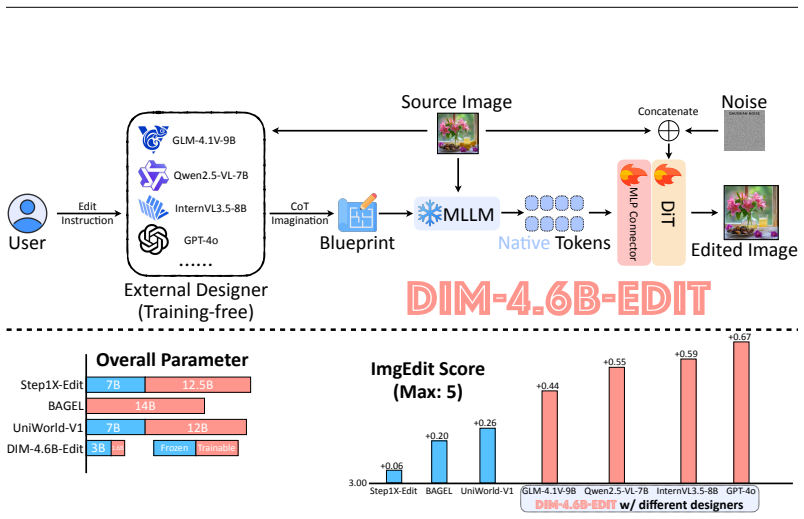
The authors show that current unified multimodal models assign too much work to the generation module, forcing it to act as both designer and painter. By instead supplying the understanding module with explicit design blueprints in the form of 233K chain-of-thought imaginations, and training a combined 4.6B model on the resulting Draw-In-Mind dataset, they obtain SOTA or competitive editing performance on standard benchmarks while using far fewer parameters than competing systems.
What carries the argument
The Draw-In-Mind dataset, whose DIM-Edit subset supplies chain-of-thought imaginations as explicit design blueprints that shift layout inference and region identification to the understanding module.
If this is right
- Unified models can reach strong editing results at modest scale once design responsibility is moved to the understanding module.
- Long-context image-text pairs improve the model's ability to follow complex editing instructions.
- Freezing the understanding module and training only the generation module via a lightweight connector preserves reasoning capacity while adapting output rendering.
- The same rebalancing approach may reduce the performance gap between unified models and specialized editing pipelines.
Where Pith is reading between the lines
- If the design blueprints prove reliable, the method could be applied to other tasks that require both understanding and precise generation, such as video editing or 3D scene modification.
- Scaling the blueprint generation process beyond GPT-4o might further improve results without increasing model size.
Load-bearing premise
The 233K chain-of-thought imaginations generated by GPT-4o serve as accurate, unbiased explicit design blueprints for image edits.
What would settle it
A controlled ablation that removes the explicit design blueprints from training data and shows no drop in editing accuracy on ImgEdit or GEdit-Bench would falsify the claim.
Figures










read the original abstract
In recent years, integrating multimodal understanding and generation into a single unified model has emerged as a promising paradigm. While this approach achieves strong results in text-to-image (T2I) generation, it still struggles with precise image editing. We attribute this limitation to an imbalanced division of responsibilities. The understanding module primarily functions as a translator that encodes user instructions into semantic conditions, while the generation module must simultaneously act as designer and painter, inferring the original layout, identifying the target editing region, and rendering the new content. This imbalance is counterintuitive because the understanding module is typically trained with several times more data on complex reasoning tasks than the generation module. To address this issue, we introduce Draw-In-Mind (DIM), a dataset comprising two complementary subsets: (i) DIM-T2I, containing 14M long-context image-text pairs to enhance complex instruction comprehension; and (ii) DIM-Edit, consisting of 233K chain-of-thought imaginations generated by GPT-4o, serving as explicit design blueprints for image edits. We connect a frozen Qwen2.5-VL-3B with a trainable SANA1.5-1.6B via a lightweight two-layer MLP, and train it on the proposed DIM dataset, resulting in DIM-4.6B-T2I/Edit. Despite its modest parameter scale, DIM-4.6B-Edit achieves SOTA or competitive performance on the ImgEdit and GEdit-Bench benchmarks, outperforming much larger models such as UniWorld-V1 and Step1X-Edit. These findings demonstrate that explicitly assigning the design responsibility to the understanding module provides significant benefits for image editing. Our dataset and models are available at https://github.com/showlab/DIM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that unified multimodal models struggle with precise image editing due to imbalanced roles where the generation module must act as both designer and painter. To address this, they introduce the Draw-In-Mind (DIM) dataset: DIM-T2I with 14M long-context image-text pairs and DIM-Edit with 233K GPT-4o-generated chain-of-thought imaginations as explicit design blueprints. They connect a frozen Qwen2.5-VL-3B understanding module to a trainable SANA1.5-1.6B generation module via a lightweight two-layer MLP, train on DIM to produce DIM-4.6B-T2I/Edit, and report SOTA or competitive results on ImgEdit and GEdit-Bench, outperforming larger models like UniWorld-V1 and Step1X-Edit. This is presented as evidence that explicitly assigning design responsibility to the understanding module benefits image editing.
Significance. If the central claim holds after proper isolation of factors, the work demonstrates that role rebalancing via high-quality external design data can enable strong image editing performance with a modest 4.6B parameter model. The open release of the DIM dataset and models is a concrete strength that could facilitate follow-up research on separating reasoning and rendering in unified architectures.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The manuscript attributes performance gains on ImgEdit and GEdit-Bench to the rebalancing of designer-painter roles via DIM-Edit's chain-of-thought blueprints, yet reports no ablation studies (e.g., training the same architecture on DIM-T2I alone or without the CoT component) to isolate this factor from dataset scale, model choice, or the connector architecture. This omission makes it difficult to confirm that the reported improvements are causally linked to the proposed role assignment rather than other variables.
- [Abstract] Abstract: The claim that the 233K GPT-4o-generated CoT imaginations serve as effective explicit design blueprints for edits is central to the argument, but the paper provides no details on data quality validation, human evaluation, or error analysis of these generations. Without such checks, the assumption that these serve as accurate, unbiased blueprints remains untested and load-bearing for the significance of the role-rebalancing contribution.
minor comments (2)
- [Method] The description of the two-layer MLP connector and training procedure could include more specifics on hyperparameters, loss functions, and how the frozen understanding module interacts with the trainable generation module during editing inference.
- [Experiments] Qualitative examples in figures would benefit from explicit annotations highlighting where the design blueprints influence the editing outcomes versus baseline behavior.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and commit to revisions that strengthen the isolation of our contributions.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The manuscript attributes performance gains on ImgEdit and GEdit-Bench to the rebalancing of designer-painter roles via DIM-Edit's chain-of-thought blueprints, yet reports no ablation studies (e.g., training the same architecture on DIM-T2I alone or without the CoT component) to isolate this factor from dataset scale, model choice, or the connector architecture. This omission makes it difficult to confirm that the reported improvements are causally linked to the proposed role assignment rather than other variables.
Authors: We agree that controlled ablations are necessary to more rigorously attribute gains to the role-rebalancing mechanism. Although our main results show DIM-4.6B-Edit outperforming larger unified models, we will add the suggested ablations in the revised manuscript: (1) training the identical architecture on DIM-T2I only, and (2) a variant of DIM-Edit without the CoT component. These will help isolate the contribution of the explicit design blueprints from dataset scale and architecture choices. revision: yes
-
Referee: [Abstract] Abstract: The claim that the 233K GPT-4o-generated CoT imaginations serve as effective explicit design blueprints for edits is central to the argument, but the paper provides no details on data quality validation, human evaluation, or error analysis of these generations. Without such checks, the assumption that these serve as accurate, unbiased blueprints remains untested and load-bearing for the significance of the role-rebalancing contribution.
Authors: We acknowledge that explicit validation of the GPT-4o CoT data would strengthen the central claim. The generation pipeline is detailed in Section 3.2, but we will expand the revision with a new subsection on data quality: human evaluation on a random sample of 500 CoT imaginations (reporting agreement rates on design accuracy and relevance) together with a categorized error analysis of failure modes. This will provide direct evidence that the blueprints are reliable. revision: yes
Circularity Check
No significant circularity; derivation relies on external data and benchmarks
full rationale
The paper attributes editing limitations to role imbalance, introduces the DIM dataset (including 233K GPT-4o-generated CoT imaginations as explicit blueprints), connects a frozen Qwen2.5-VL-3B understanding module to a trainable SANA generation module via MLP, trains on DIM, and reports SOTA/competitive results on independent external benchmarks (ImgEdit, GEdit-Bench). No equations, fitted parameters, or self-citations reduce the performance claim or role-rebalancing conclusion to the inputs by construction. The central result is an empirical outcome measured against outside benchmarks rather than a tautological renaming or self-defined prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GPT-4o can generate high-quality, unbiased chain-of-thought design blueprints for image edits
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We attribute this limitation to an imbalanced division of responsibilities. The understanding module primarily functions as a translator... while the generation module must simultaneously act as designer and painter
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DIM-Edit, consisting of 233K chain-of-thought imaginations generated by GPT-4o, serving as explicit design blueprints
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025a. Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Junying Chen, Zhenyang Cai, Pengcheng Chen, Shunian Chen, Ke Ji, Xidong Wang, Yunjin Yang, and Benyou Wang. Sharegpt-4o-image: Aligning multimodal models with gpt-4o-level image generation.arXiv preprint arXiv:2506.18095, 2025b. Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimod...
-
[4]
Emerging Properties in Unified Multimodal Pretraining
Accessed: 2025-08-05. Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Dimba: Transformer-mamba diffusion models.arXiv preprint arXiv:2406.01159,
Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, Youqiang Zhang, and Junshi Huang. Dimba: Transformer-mamba diffusion models.arXiv preprint arXiv:2406.01159,
-
[6]
Yuying Ge, Sijie Zhao, Chen Li, Yixiao Ge, and Ying Shan. Seed-data-edit technical report: A hybrid dataset for instructional image editing.arXiv preprint arXiv:2405.04007,
-
[7]
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Lixue Gong, Xiaoxia Hou, Fanshi Li, Liang Li, Xiaochen Lian, Fei Liu, Liyang Liu, Wei Liu, Wei Lu, Yichun Shi, et al. Seedream 2.0: A native chinese-english bilingual image generation foundation model.arXiv preprint arXiv:2503.07703,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Hq-edit: A high-quality dataset for instruction-based image editing.arXiv preprint arXiv:2404.09990,
Mude Hui, Siwei Yang, Bingchen Zhao, Yichun Shi, Heng Wang, Peng Wang, Yuyin Zhou, and Cihang Xie. Hq-edit: A high-quality dataset for instruction-based image editing.arXiv preprint arXiv:2404.09990,
-
[10]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Linmiao Xu, and Suhail Doshi. Playground v2. 5: Three insights towards enhancing aesthetic quality in text-to-image generation.arXiv preprint arXiv:2402.17245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Bin Lin, Zongjian Li, Xinhua Cheng, Yuwei Niu, Yang Ye, Xianyi He, Shenghai Yuan, Wangbo Yu, Shaodong Wang, Yunyang Ge, et al. Uniworld: High-resolution semantic encoders for unified visual understanding and generation.arXiv preprint arXiv:2506.03147,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Transfer between Modalities with MetaQueries
Accessed: YYYY-MM- DD. Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, et al. Transfer between modalities with metaqueries.arXiv preprint arXiv:2504.06256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Janus: Decoupling visual encoding for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 12966–12977, 2025a. Size Wu, Zhonghua Wu, Zerui Gong, Qingyi Tao,...
-
[19]
URLhttps://arxiv.org/abs/ 2506.03569. Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Chengyue Wu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, et al. Sana 1.5: Efficient scaling of training-time and inference- time compute in linear diffusion transformer.arXiv preprint arXiv:2501.18427, 2025a. Jinheng Xie, Weijia Mao, Zechen Bai, David J...
-
[20]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show-o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564, 2025b. Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. InProceedings of t...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Specifically, Step1X-Edit is provided with short raw prompts, while DIM-4.6B-Edit is evaluated with longer CoT prompts. Even under this more demanding setting, our model achieves a 4.5× speedup while preserving high editing quality, highlighting the effectiveness of the proposed DIM dataset and the Draw-In-Mind paradigm. 14 Remove the sheep in the foregro...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.