Low-rank Orthogonalization for Large-scale Matrix Optimization with Applications to Foundation Model Training
Pith reviewed 2026-05-18 15:43 UTC · model grok-4.3
The pith
Low-rank orthogonalization exploits the low-rank structure of gradients to create a Muon variant that outperforms the original on large foundation models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
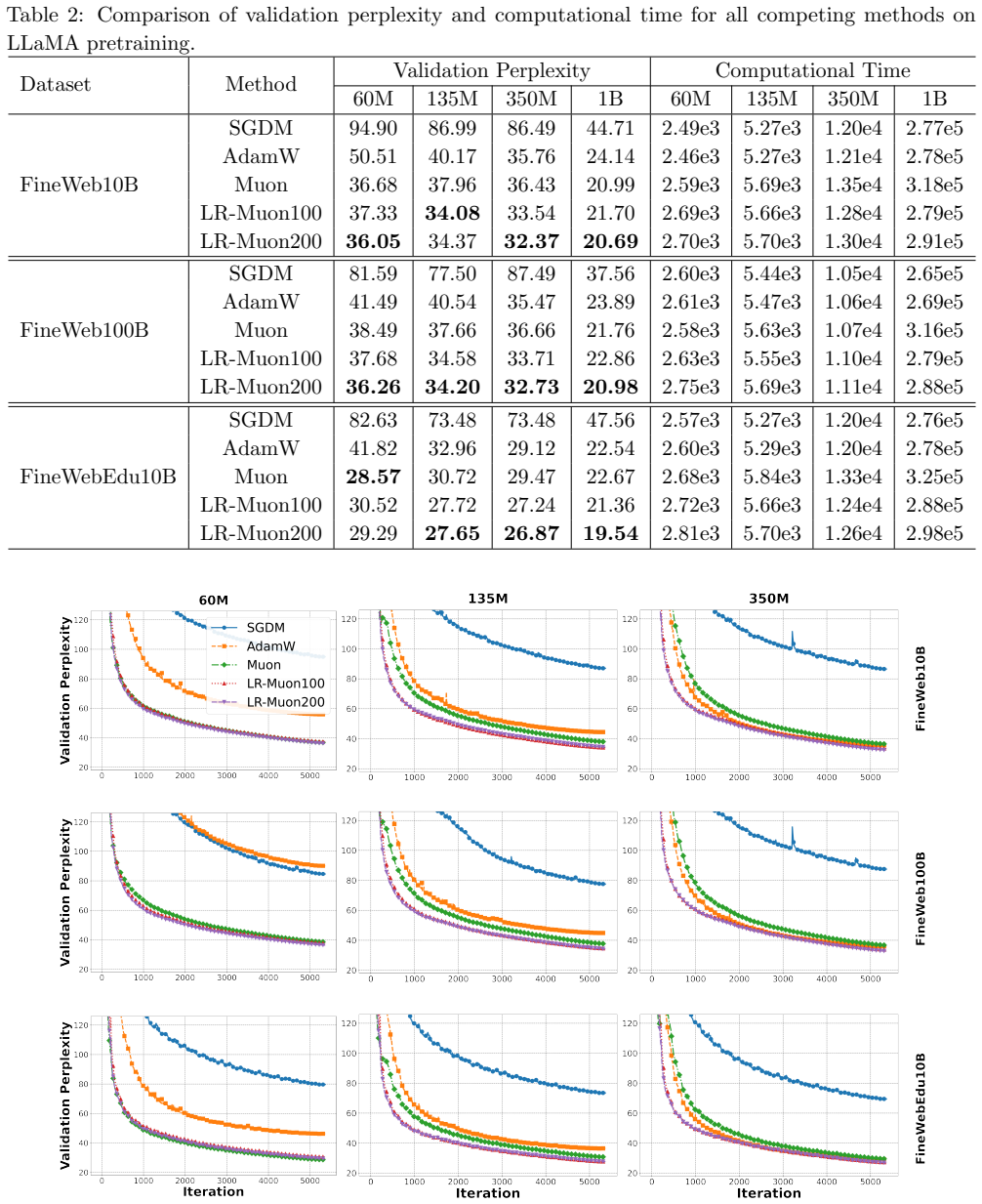
By replacing full orthogonalization with a low-rank version that uses the low-rank structure of gradients, low-rank MSGD achieves provable iteration complexity for approximate stationary points while low-rank Muon does the same for approximate stochastic stationary points under heavy-tailed noise. Numerical results show this yields superior performance over vanilla Muon in GPT-2 and LLaMA pretraining at large scales.
What carries the argument
low-rank orthogonalization, the process of orthogonalizing gradient matrices after projecting them to a low-rank subspace to exploit their observed low-rank structure during training
If this is right
- Low-rank Muon surpasses vanilla Muon on GPT-2 and LLaMA pretraining tasks with large model sizes.
- Low-rank MSGD reaches an approximate stationary solution with established iteration complexity.
- Low-rank Muon reaches an approximate stochastic stationary solution under heavy-tailed noise with established iteration complexity.
- The low-rank approach applies directly to other large-scale matrix optimization problems arising in neural network training.
Where Pith is reading between the lines
- If the low-rank gradient property persists at even larger scales, the method could cut memory and compute costs for orthogonalization steps in models beyond current LLaMA sizes.
- Similar low-rank projections might improve other matrix-aware optimizers that rely on orthogonalization or signed updates.
- The assumption could be validated by tracking the effective rank of gradients across different model architectures and datasets to identify when the speedup is reliable.
Load-bearing premise
Gradients during neural network training have enough low-rank structure that replacing full orthogonalization with a low-rank version preserves convergence and model quality.
What would settle it
A controlled experiment on a large LLaMA pretraining run where low-rank Muon converges to a strictly worse loss or requires substantially more steps than vanilla Muon would falsify the practical claim.
Figures







read the original abstract
Neural network (NN) training is inherently a large-scale matrix optimization problem, yet the matrix structure of NN parameters has long been overlooked. Recently, the optimizer Muon \citep{jordanmuon}, which explicitly exploits this structure, has gained significant attention for its strong performance in foundation model training. A key component contributing to Muon's success is matrix orthogonalization. In this paper, we propose \textit{low-rank orthogonalization}, which performs orthogonalization by leveraging the low-rank nature of gradients during NN training. Building on this, we introduce low-rank matrix-signed gradient descent (MSGD) and a low-rank variant of Muon. Numerical experiments demonstrate the superior performance of low-rank orthogonalization, with low-rank Muon achieving promising results in GPT-2 and LLaMA pretraining -- surpassing the carefully tuned vanilla Muon on tasks with large model sizes. Theoretically, we establish the iteration complexity of low-rank MSGD for finding an approximate stationary solution, and the iteration complexity of low-rank Muon for finding an approximate stochastic stationary solution under heavy-tailed noise. The code to reproduce our numerical experiments is available at https://github.com/dengzhanwang/Low-rank-Muon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes low-rank orthogonalization to exploit the low-rank structure of gradients in neural network training. It introduces low-rank matrix-signed gradient descent (MSGD) and a low-rank variant of the Muon optimizer, reports empirical results showing low-rank Muon outperforming carefully tuned vanilla Muon in GPT-2 and LLaMA pretraining on large models, and derives iteration complexity bounds for low-rank MSGD (approximate stationary points) and low-rank Muon (approximate stochastic stationary points under heavy-tailed noise). Code is provided for reproducibility.
Significance. If the low-rank gradient structure is verified and the performance gains hold under rigorous controls, the work could improve computational efficiency of orthogonalization steps in large-scale foundation model training without sacrificing convergence quality. The availability of reproduction code and the extension of Muon to low-rank settings are positive contributions to the matrix-optimization literature for deep learning.
major comments (2)
- [Numerical Experiments] The central empirical claim (low-rank Muon surpassing tuned vanilla Muon on large-model tasks) and the theoretical iteration bounds both rest on the premise that gradients possess exploitable low-rank structure. However, the manuscript reports neither the effective numerical rank nor the fraction of Frobenius norm captured by the top-k singular vectors at any training step in the GPT-2 or LLaMA experiments. Without these diagnostics, observed gains could arise from incidental implementation differences or hyper-parameter effects rather than the low-rank mechanism.
- [Theoretical Analysis] §4 (theoretical analysis): the iteration complexity statements for low-rank MSGD and low-rank Muon appear to follow from standard stochastic optimization arguments applied to a truncated orthogonalization operator. The derivation does not explicitly quantify how the rank truncation threshold affects the constants in the complexity bounds or the bias introduced relative to full orthogonalization.
minor comments (2)
- [Introduction] The abstract and introduction use the phrase 'low-rank nature of gradients' without a precise definition or reference to prior work quantifying this property in transformer training.
- [Numerical Experiments] Figure captions and experimental tables should explicitly state the rank truncation threshold used for each model size and whether it was tuned or fixed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the empirical validation of the low-rank structure and the transparency of the theoretical analysis. We address each major comment below and commit to revisions that directly incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Numerical Experiments] The central empirical claim (low-rank Muon surpassing tuned vanilla Muon on large-model tasks) and the theoretical iteration bounds both rest on the premise that gradients possess exploitable low-rank structure. However, the manuscript reports neither the effective numerical rank nor the fraction of Frobenius norm captured by the top-k singular vectors at any training step in the GPT-2 or LLaMA experiments. Without these diagnostics, observed gains could arise from incidental implementation differences or hyper-parameter effects rather than the low-rank mechanism.
Authors: We agree that providing these diagnostics is important to substantiate the low-rank premise. In the revised version, we will add new figures and tables in the experimental section that report, for multiple training steps in both the GPT-2 and LLaMA runs, the effective numerical rank (defined via singular values exceeding a small threshold relative to the largest) and the cumulative fraction of Frobenius norm captured by the top-k singular vectors. These additions will be computed from the existing experimental code and will directly address whether the observed gains align with the low-rank gradient structure. revision: yes
-
Referee: [Theoretical Analysis] §4 (theoretical analysis): the iteration complexity statements for low-rank MSGD and low-rank Muon appear to follow from standard stochastic optimization arguments applied to a truncated orthogonalization operator. The derivation does not explicitly quantify how the rank truncation threshold affects the constants in the complexity bounds or the bias introduced relative to full orthogonalization.
Authors: We appreciate this point on the need for greater explicitness. Although the current proofs apply standard stochastic optimization techniques to the low-rank truncated operator and control the truncation error via the assumed low-rank gradient structure, we will revise §4 to include an additional lemma or remark that explicitly bounds the dependence of the complexity constants on the rank threshold k. This will also quantify the bias relative to full orthogonalization in terms of the tail singular values, under the paper's low-rank gradient assumption, thereby clarifying the relationship between the low-rank and full-rank cases. revision: yes
Circularity Check
No significant circularity; derivations are self-contained
full rationale
The paper motivates low-rank orthogonalization from the empirical observation that gradients in NN training exhibit low-rank structure, then defines low-rank MSGD and low-rank Muon accordingly. Iteration complexity results for approximate stationary points are obtained by applying standard stochastic optimization arguments to these modified updates under heavy-tailed noise, without reducing to fitted parameters, self-definitional loops, or load-bearing self-citations. The central empirical claims rest on numerical experiments with GPT-2 and LLaMA rather than tautological renaming or imported uniqueness theorems. No step equates a prediction to its input by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- rank truncation threshold
axioms (2)
- domain assumption Gradients encountered during neural network training admit a useful low-rank approximation.
- standard math Standard stochastic gradient assumptions hold under heavy-tailed noise.
invented entities (1)
-
low-rank orthogonalization operator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we establish the iteration complexity of low-rank MSGD … under heavy-tailed noise
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
Rethinking Muon Beyond Pretraining: Spectral Failures and High-Pass Remedies for VLA and RLVR
Pion modifies Muon's Newton-Schulz iterations into a controllable high-pass filter that anchors dominant singular values at 1 while suppressing noisy tails, outperforming Muon and AdamW in VLA and RLVR regimes.
-
Muon with Nesterov Momentum: Heavy-Tailed Noise and (Randomized) Inexact Polar Decomposition
Muon with Nesterov momentum and inexact polar decomposition achieves optimal convergence rates of O(ε^(-(3α-2)/(α-1))) under heavy-tailed noise for ε-stationary points in non-convex settings.
-
Scale-Invariant Neural Network Optimization: Norm Geometry and Heavy-Tailed Noise
Establishes matching lower and upper oracle complexity bounds for scale-invariant methods with spectral norm under heavy-tailed noise, plus improved rates with higher-order smoothness, and practical tests on neural networks.
-
MiMuon: Mixed Muon Optimizer with Improved Generalization for Large Models
MiMuon is a hybrid optimizer that achieves a generalization error bound of O(1/N) independent of the small singular-value gap that limits the original Muon bound, while retaining the same O(1/T^{1/4}) convergence rate.
-
Position: Zeroth-Order Optimization in Deep Learning Is Underexplored, Not Underpowered
Zeroth-order optimization is underexplored rather than underpowered in deep learning, with limitations stemming from full-space designs that can be addressed via subspace, spectral, and systems-aware approaches.
Reference graph
Works this paper leans on
- [2]
-
[3]
E. AI, I. Shah, A. M. Polloreno, K. Stratos, P. Monk, A. Chaluvaraju, A. Hojel, A. Ma, A. Thomas, A. Tanwer, D. J. Shah, K. Nguyen, K. Smith, M. Callahan, M. Pust, M. Parmar, P. Rushton, P. Mazarakis, R. Kapila, S. Srivastava, S. Singla, T. Romanski, Y. Vanjani, and A. Vaswani. Practical efficiency of Muon for pretraining.arXiv preprint arXiv:2505.02222, 2025
- [4]
- [5]
-
[6]
Old Optimizer, New Norm: An Anthology
J. Bernstein and L. Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
F. Bian, J.-F. Cai, and R. Zhang. A preconditioned Riemannian gradient descent algorithm for low-rank matrix recovery.SIAM Journal on Matrix Analysis and Applications, 45(4):2075–2103, 2024
work page 2075
-
[8]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, E. Brynjolfsson, S. Buch, D. Card, R. Castellon, N. Chatterji, A. Chen, K. Creel, J. Q. Davis, D. Demszky, C. Donahue, M. Doumbouya, E. Durmus, S. Ermon, J. Etchemendy, K. Ethayarajh, L. Fei-Fei, C. Finn, T. Gale, L. Gillespie, K. Go...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
L. Bottou. Large-scale machine learning with stochastic gradient descent. InInternational Conference on Computational Statistics, pages 177–186. Springer, 2010
work page 2010
-
[10]
D. Carlson, V. Cevher, and L. Carin. Stochastic spectral descent for restricted Boltzmann machines. InInternational Conference on Artificial Intelligence and Statistics, pages 111–119, 2015
work page 2015
-
[11]
D. Carlson, Y.-P. Hsieh, E. Collins, L. Carin, and V. Cevher. Stochastic spectral descent for discrete graphical models.IEEE Journal of Selected Topics in Signal Processing, 10(2):296–311, 2015. 22
work page 2015
-
[12]
D. E. Carlson, E. Collins, Y.-P. Hsieh, L. Carin, and V. Cevher. Preconditioned spectral descent for deep learning. InAdvances in neural information processing systems, volume 28, 2015
work page 2015
- [13]
-
[14]
F. L. Cesista. Muon and a selective survey on steepest descent in Riemannian and non-Riemannian manifolds, 2025
work page 2025
- [15]
-
[16]
P. Drineas, R. Kannan, and M. W. Mahoney. Fast Monte Carlo algorithms for matrices I: Approxi- mating matrix multiplication.SIAM Journal on Computing, 36(1):132–157, 2006
work page 2006
-
[17]
P. Drineas, R. Kannan, and M. W. Mahoney. Fast Monte Carlo algorithms for matrices II: Computing a low-rank approximation to a matrix.SIAM Journal on Computing, 36(1):158–183, 2006
work page 2006
- [18]
-
[19]
S. S. S. Duvvuri, F. Devvrit, R. Anil, C. Hsieh, and I. S. Dhillon. Combining axes preconditioners through Kronecker approximation for deep learning. InInternational Conference on Learning Representations, 2024
work page 2024
-
[20]
A. Glentis, J. Li, A. Han, and M. Hong. A minimalist optimizer design for LLM pretraining.arXiv preprint arXiv:2506.16659, 2025
work page internal anchor Pith review arXiv 2025
- [21]
-
[22]
N. Halko, P.-G. Martinsson, and J. A. Tropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions.SIAM Review, 53(2):217–288, 2011
work page 2011
-
[23]
Y. Hao, Y. Cao, and L. Mou. Flora: Low-rank adapters are secretly gradient compressors. In International Conference on Machine Learning, 2024
work page 2024
- [24]
- [25]
-
[26]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.International Conference on Learning Representations, 1(2):3, 2022
work page 2022
- [27]
- [28]
-
[29]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations, 2015
work page 2015
- [30]
- [31]
- [32]
- [33]
- [34]
-
[35]
J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y. Du, Y. Qin, W. Xu, E. Lu, J. Yan, Y. Chen, H. Zheng, Y. Liu, S. Liu, B. Yin, W. He, H. Zhu, Y. Wang, J. Wang, M. Dong, Z. Zhang, Y. Kang, H. Zhang, X. Xu, Y. Zhang, Y. Wu, X. Zhou, and Z. Yang. Muon is scalable for LLM training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [36]
-
[37]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[38]
C. Ma, W. Gong, M. Scetbon, and E. Meeds. SWAN: Preprocessing SGD enables Adam-level performance on LLM training with significant memory reduction.arXiv e-prints, pages arXiv–2412, 2024
work page 2024
-
[39]
S. Malladi, T. Gao, E. Nichani, A. Damian, J. D. Lee, D. Chen, and S. Arora. Fine-tuning language models with just forward passes. InAdvances in Neural Information Processing Systems, volume 36, pages 53038–53075, 2023
work page 2023
-
[40]
Randomized methods for matrix computations
P.-G. Martinsson. Randomized methods for matrix computations.arXiv preprint arXiv:1607.01649, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[41]
Training Deep Learning Models with Norm-Constrained LMOs
T. Pethick, W. Xie, K. Antonakopoulos, Z. Zhu, A. Silveti-Falls, and V. Cevher. Training deep learning models with norm-constrained LMOs.arXiv preprint arXiv:2502.07529, 2025
work page internal anchor Pith review arXiv 2025
-
[42]
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever. Language models are unsupervised multitask learners. 2019
work page 2019
-
[43]
A. Riabinin, E. Shulgin, K. Gruntkowska, and P. Richt´ arik. Gluon: Making Muon & Scion great again! (bridging theory and practice of LMO-based optimizers for LLMs).arXiv preprint arXiv:2505.13416, 2025
-
[44]
V. Rokhlin, A. Szlam, and M. Tygert. A randomized algorithm for principal component analysis. SIAM Journal on Matrix Analysis and Applications, 31(3):1100–1124, 2010. 24
work page 2010
-
[45]
F. Rosenblatt. The perceptron: A probabilistic model for information storage and organization in the brain.Psychological Review, 65(6):386, 1958
work page 1958
- [46]
-
[47]
Lionsandmuons: Optimizationviastochasticfrank-wolfe.arXivpreprint arXiv:2506.04192, 2025
M.-E. Sfyraki and J.-K. Wang. Lions and Muons: Optimization via stochastic Frank-Wolfe.arXiv preprint arXiv:2506.04192, 2025
-
[48]
W. Shen, R. Huang, M. Huang, C. Shen, and J. Zhang. On the convergence analysis of Muon.arXiv preprint arXiv:2505.23737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [49]
-
[50]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi` ere, N. Goyal, E. Hambro, F. Azhar, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
arXiv preprint arXiv:2202.07052 , year=
M. Tuddenham, A. Pr¨ ugel-Bennett, and J. Hare. Orthogonalising gradients to speed up neural network optimisation.arXiv preprint arXiv:2202.07052, 2022
-
[52]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. InAdvances in neural information processing systems, volume 30, 2017
work page 2017
-
[53]
N. Vyas, D. Morwani, R. Zhao, I. Shapira, D. Brandfonbrener, L. Janson, and S. M. Kakade. SOAP: Improving and stabilizing Shampoo using Adam for language modeling. InInternational Conference on Learning Representations, 2025
work page 2025
- [54]
-
[55]
M. D. Zeiler. Adadelta: An adaptive learning rate method.arXiv preprint arXiv:1212.5701, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
- [56]
-
[57]
J. Zhao, Z. Zhang, B. Chen, Z. Wang, A. Anandkumar, and Y. Tian. GaLore: Memory-efficient LLM training by gradient low-rank projection. InInternational Conference on Machine Learning, volume 235, pages 61121–61143, 2024. A Low-rank orthogonalization procedures In this part, we introduce two new low-rank orthogonalization methods as alternatives to Algorit...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.