Efficient and Transferable Agentic Knowledge Graph RAG via Reinforcement Learning
Pith reviewed 2026-05-25 07:42 UTC · model grok-4.3
The pith
A single reinforcement learning agent for knowledge-graph retrieval-augmented generation reaches higher accuracy with fewer tokens than multi-module systems that rely on larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
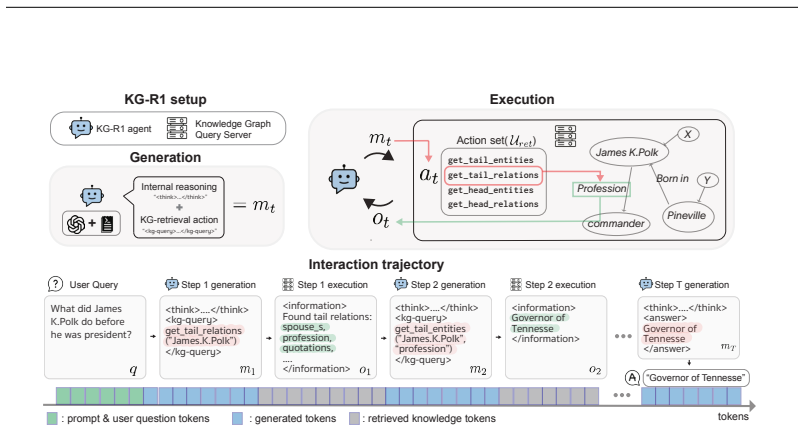
KG-R1 trains one agent through reinforcement learning to interact with a knowledge graph as its environment, selecting retrieval actions at each step and integrating the retrieved information into a single unified reasoning and generation process; on standard KGQA benchmarks this yields higher answer accuracy and lower token counts than prior multi-module workflows even when the base model is only 3B parameters, and the trained agent maintains performance on new graphs without retraining.
What carries the argument
The KG-R1 single agent that treats the knowledge graph as an RL environment and learns retrieval actions jointly with reasoning in one loop.
If this is right
- Inference cost drops because fewer tokens are generated and a smaller base model suffices.
- The same trained agent can be dropped onto new knowledge graphs without additional training or fine-tuning.
- The need for separate planning, reasoning, and response modules is removed by the single learned policy.
- Real-world KG-RAG deployments become more practical because the system generalizes across graph structures.
Where Pith is reading between the lines
- The same RL loop could be applied to other structured retrieval sources such as databases or document hierarchies.
- Training once on a diverse collection of graphs might produce agents that handle entirely new domains zero-shot.
- If the reward design proves robust, similar agentic RL training could replace multi-module pipelines in non-graph RAG settings.
Load-bearing premise
The reinforcement learning reward signal and the way retrieval actions are defined and scored are assumed to transfer across different knowledge-graph schemas without needing schema-specific redesign or retraining.
What would settle it
Train the agent on one family of knowledge graphs, then evaluate it on a second family whose relation vocabulary and connectivity patterns differ markedly; if accuracy falls sharply, the transfer claim does not hold.
Figures














read the original abstract
Knowledge-graph retrieval-augmented generation (KG-RAG) couples large language models (LLMs) with structured, verifiable knowledge graphs (KGs) to reduce hallucination and provide reasoning traces. However, current KG-RAG systems often rely on fixed pipelines of multiple LLM modules (e.g., planning, reasoning, and responding), which inflate inference costs and tie performance to specific graph schemas. To address this, we introduce KG-R1, an agentic framework that optimizes KG-RAG through reinforcement learning (RL). Unlike modular workflows, KG-R1 uses a single agent that interacts with KGs as its environment, learning to retrieve information at each step and incorporating it into its reasoning and generation in a unified process. Across Knowledge-Graph Question Answering (KGQA) benchmarks, KG-R1 demonstrates both efficiency and transferability-using Qwen 2.5-3B, KG-R1 improves answer accuracy with fewer generation tokens than prior multi-module workflow methods that use much larger foundation or fine-tuned models. Furthermore, KG-R1 exhibits strong plug-and-play capability: after training, maintaining accuracy on unseen KGs without retraining. These properties make KG-R1 a promising KG-RAG framework for real-world deployment. Our code is publicly available at github.com/junhongmit/KG-R1/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KG-R1, an agentic RL framework for KG-RAG in which a single LLM agent (Qwen 2.5-3B) treats the knowledge graph as an environment and learns to perform retrieval actions interleaved with reasoning and generation. It reports higher answer accuracy and lower token usage on KGQA benchmarks than prior multi-module pipelines that rely on larger foundation or fine-tuned models, together with plug-and-play transfer: the trained policy maintains accuracy on unseen KGs without retraining.
Significance. If the efficiency gains and schema-invariant transfer are substantiated, the work would be significant for practical KG-RAG deployment, as it reduces inference cost and eliminates per-graph retraining. The public code release supports reproducibility.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): the transfer claim requires that the action space, state representation, and reward encode no schema-specific structure. The manuscript supplies no explicit formulation of retrieval actions (e.g., whether they are defined over concrete relation vocabularies or abstract operations), leaving the generalization argument unsupported.
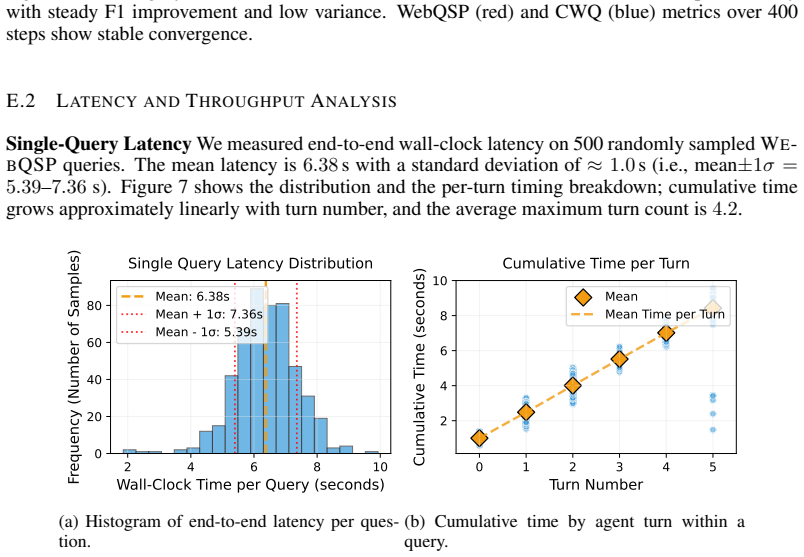
- [§4] §4 (Experiments): accuracy and token-count improvements are stated without error bars, statistical significance tests, training curves, or ablations on reward design and hyperparameters. These omissions are load-bearing for both the efficiency and transfer claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): the transfer claim requires that the action space, state representation, and reward encode no schema-specific structure. The manuscript supplies no explicit formulation of retrieval actions (e.g., whether they are defined over concrete relation vocabularies or abstract operations), leaving the generalization argument unsupported.
Authors: We agree that an explicit formulation is needed to support the transfer claim. The actions in KG-R1 are abstract operations (e.g., RetrieveNeighbors using relation embeddings rather than schema-specific tokens), states use schema-invariant embeddings, and rewards are task-performance based. We will add a formal definition of the action space, state representation, and reward in the revised §3. revision: yes
-
Referee: [§4] §4 (Experiments): accuracy and token-count improvements are stated without error bars, statistical significance tests, training curves, or ablations on reward design and hyperparameters. These omissions are load-bearing for both the efficiency and transfer claims.
Authors: We acknowledge that these elements are necessary to substantiate the claims. In the revised §4 we will add error bars from multiple runs, statistical significance tests, training curves, and ablations on reward design and hyperparameters. revision: yes
Circularity Check
Empirical RL training yields no circular derivation
full rationale
The paper reports results from training an RL agent (KG-R1) on KGQA benchmarks and evaluating accuracy, token efficiency, and transfer to unseen KGs. No equations, derivations, or fitted-parameter predictions are described that would reduce reported accuracies to training inputs by construction. The central claims rest on experimental outcomes rather than self-referential definitions or self-citation chains that collapse the result.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward function and hyperparameters
axioms (1)
- domain assumption The KG can be treated as a Markov decision process environment where retrieval actions produce observable state changes.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Program-guided temporal knowledge graph qa (prog-tqa). In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024. URL https://aclanthology.org/2024.lrec-main.1528.pdf
work page 2024
-
[3]
Knowledge-augmented language model prompting for zero-shot knowledge graph question answering, 2023
Jinheon Baek, Alham Fikri Aji, and Amir Saffari. Knowledge-augmented language model prompting for zero-shot knowledge graph question answering, 2023. URL https://arxiv.org/abs/2306.04136
-
[4]
Gett-qa: Graph embedding based t2t transformer for knowledge graph question answering
Debayan Banerjee, Pranav Ajit Nair, Ricardo Usbeck, and Chris Biemann. Gett-qa: Graph embedding based t2t transformer for knowledge graph question answering. In ESWC 2023 Workshops (SemDeep-6), 2023. URL https://2023.eswc-conferences.org/wp-content/uploads/2023/05/paper_Banerjee_2023_GETT-QA.pdf
work page 2023
-
[5]
Large-scale Simple Question Answering with Memory Networks
Antoine Bordes, Nicolas Usunier, Sumit Chopra, and Jason Weston. Large-scale Simple Question Answering with Memory Networks . arXiv preprint arXiv:1506.02075, 2015. URL https://arxiv.org/abs/1506.02075
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[6]
Elizabeth Boschee, Jennifer Lautenschlager, Sean O'Brien, Steve Shellman, James Starz, and Michael Ward. Icews coded event data, 2015. URL https://doi.org/10.7910/DVN/28075
-
[7]
Grounding dialogue systems via knowledge graph aware decoding with pre-trained transformers, 2021
Debanjan Chaudhuri, Md Rashad Al Hasan Rony, and Jens Lehmann. Grounding dialogue systems via knowledge graph aware decoding with pre-trained transformers, 2021. URL https://arxiv.org/abs/2103.16289
-
[8]
Multi-granularity Temporal Question Answering over Knowledge Graphs
Ziyang Chen, Jinzhi Liao, and Xiang Zhao. Multi-granularity Temporal Question Answering over Knowledge Graphs . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 11417--11431, Toronto, Canada, July 2023. Association for Computational Linguistics. doi:10.18653/v1/2023.acl-long.637. URL ...
-
[9]
Temporal knowledge question answering via abstract reasoning induction
Ziyang Chen, Dongfang Li, Xiang Zhao, Baotian Hu, and Min Zhang. Temporal knowledge question answering via abstract reasoning induction. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024. URL https://openreview.net/pdf?id=Yb64YLwWk_
work page 2024
-
[10]
Yuri Chervonyi, Trieu H. Trinh, Miroslav Olšák, Xiaomeng Yang, Hoang Nguyen, Marcelo Menegali, Junehyuk Jung, Vikas Verma, Quoc V. Le, and Thang Luong. Gold-medalist performance in solving olympiad geometry with alphageometry2, 2025. URL https://arxiv.org/abs/2502.03544
-
[11]
Jiaxi Cui, Munan Ning, Zongjian Li, Bohua Chen, Yang Yan, Hao Li, Bin Ling, Yonghong Tian, and Li Yuan. Chatlaw: A multi-agent collaborative legal assistant with knowledge graph enhanced mixture-of-experts large language model, 2024. URL https://arxiv.org/abs/2306.16092
-
[12]
Dynamic few-shot learning for knowledge graph question answering
Jacopo D'Abramo, Andrea Zugarini, and Paolo Torroni. Dynamic few-shot learning for knowledge graph question answering. arXiv preprint arXiv:2407.01409, 2024
-
[13]
Investigating large language models for text-to-sparql generation
Jacopo D'Abramo, Andrea Zugarini, and Paolo Torroni. Investigating large language models for text-to-sparql generation. In Weijia Shi, Greg Durrett, Hannaneh Hajishirzi, and Luke Zettlemoyer (eds.), Proceedings of the 4th International Workshop on Knowledge-Augmented Methods for Natural Language Processing, pp.\ 66--80, Albuquerque, New Mexico, USA, may 2...
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI . Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv:2501.12948, 2025. URL https://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
T-REx: A Large Scale Alignment of Natural Language with Knowledge Base Triples
Hady Elsahar, Pavlos Vougiouklis, Arslen Remaci, Christophe Gravier, Jonathon Hare, Fr \'e d \'e rique Laforest, and Elena Simperl. T-REx: A Large Scale Alignment of Natural Language with Knowledge Base Triples . In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, May 2018. European La...
work page 2018
-
[16]
Encode. Uvicorn. https://www.uvicorn.org/, 2018. ASGI server for Python. Accessed September 24, 2025
work page 2018
-
[17]
Shengxiang Gao, Jey Han Lau, and Jianzhong Qi. Beyond seen data: Improving kbqa generalization through schema-guided logical form generation (sg-kbqa), 2025. URL https://arxiv.org/abs/2502.12737
-
[18]
Beyond I.I.D.: Three Levels of Generalization for Question Answering on Knowledge Bases
Yu Gu, Sue Kase, Michelle Vanni, Brian Sadler, Percy Liang, Xifeng Yan, and Yu Su. Beyond I.I.D.: Three Levels of Generalization for Question Answering on Knowledge Bases . In Proceedings of the Web Conference 2021, pp.\ 3375--3385, Ljubljana, Slovenia, 2021. ACM / IW3C2. doi:10.1145/3442381.3449992. URL https://doi.org/10.1145/3442381.3449992
-
[19]
Atlas: Reasoning over language models with retrieval
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Stanislaw Jastrzebski, Sebastian Riedel, and Edouard Grave. Atlas: Reasoning over language models with retrieval. Journal of Machine Learning Research, 24, 2023. URL https://jmlr.org/papers/v24/22-1381.html
work page 2023
-
[20]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan \"Omer Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-R1 : Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516, 2025. doi:10.48550/arXiv.2503.09516. URL https://arxiv.org/abs/2503.09516
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.09516 2025
-
[21]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[22]
Query graph generation for answering multi-hop complex questions from knowledge bases
Yunshi Lan and Jing Jiang. Query graph generation for answering multi-hop complex questions from knowledge bases. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp.\ 969--974, Online, July 2020. Association for Computational Linguistics. doi...
- [23]
-
[24]
Sparkle: Enhancing sparql generation with direct kg integration in decoding, 2024
Jaebok Lee and Hyeonjeong Shin. Sparkle: Enhancing sparql generation with direct kg integration in decoding, 2024. URL https://arxiv.org/abs/2407.01626
-
[25]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective, 2025. URL https://arxiv.org/abs/2503.20783
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Reasoning on graphs: Faithful and interpretable large language model reasoning
Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. Reasoning on graphs: Faithful and interpretable large language model reasoning. In ICLR, 2024. URL https://arxiv.org/abs/2310.01061
-
[27]
OpenAI et al. OpenAI o1 System Card . arXiv:2412.16720, 2024. URL https://arxiv.org/abs/2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-T\"ur, Gokhan Tur, and Heng Ji. ToolRL : Reward is all tool learning needs. arXiv preprint arXiv:2504.13958, 2025. doi:10.48550/arXiv.2504.13958. URL https://arxiv.org/abs/2504.13958
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.13958 2025
-
[30]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. In ICLR (OpenReview), 2024. URL https://arxiv.org/abs/2307.16789
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Sebasti \'a n Ram \' rez. Fastapi. https://fastapi.tiangolo.com/, 2018. Accessed September 24, 2025
work page 2018
-
[33]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Ni, Heung-Yeung Shum, and Jian Guo
Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel M. Ni, Heung-Yeung Shum, and Jian Guo. Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph. In ICLR, 2024. URL https://arxiv.org/abs/2307.07697
-
[35]
The Web as a Knowledge-base for Answering Complex Questions
Alon Talmor and Jonathan Berant. The web as a knowledge-base for answering complex questions. In NAACL, 2018. URL https://arxiv.org/abs/1803.06643
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Yuhang Tian, Dandan Song, Zhijing Wu, Changzhi Zhou, Hao Wang, Jun Yang, Jing Xu, Ruanmin Cao, and HaoYu Wang. Augmenting reasoning capabilities of LLM s with graph structures in knowledge base question answering. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 11967-...
-
[37]
Ricardo Usbeck, Christina Unger, Andreas Both, Nandana Mihindukulasooriya, Gushem Tadesse, Dayana Spagnuelo, Filip Ilievski, Diego Moussallem, and Axel-Cyrille Ngonga Ngomo. QALD-10---The 10th Challenge on Question Answering over Linked Data: Shifting from DBpedia to Wikidata as a KG for KGQA . Semantic Web, 14 0 (1): 0 1--25, 2023. doi:10.3233/SW-222956....
-
[38]
Acting less is reasoning more! teaching model to act efficiently
Hongru Wang, Cheng Qian, Wanjun Zhong, Xiusi Chen, Jiahao Qiu, Shijue Huang, Bowen Jin, Mengdi Wang, Kam-Fai Wong, and Heng Ji. Acting less is reasoning more! teaching model to act efficiently. arXiv preprint arXiv:2504.14870, 2025 a . doi:10.48550/arXiv.2504.14870. URL https://arxiv.org/abs/2504.14870. Also referred to as ``OTC: Optimal Tool Calls via Re...
-
[39]
Knowledge graph retrieval-augmented generation for llm-based recommendation, 2025 b
Shijie Wang, Wenqi Fan, Yue Feng, Shanru Lin, Xinyu Ma, Shuaiqiang Wang, and Dawei Yin. Knowledge graph retrieval-augmented generation for llm-based recommendation, 2025 b . URL https://arxiv.org/abs/2501.02226
-
[40]
Reasoning of large language models over knowledge graphs with super-relations
Song Wang, Junhong Lin, Xiaojie Guo, Julian Shun, Jundong Li, and Yada Zhu. Reasoning of large language models over knowledge graphs with super-relations. arXiv:2503.22166, 2025 c . URL https://arxiv.org/abs/2503.22166
-
[41]
Knowledge-augmented language model for clinical question answering, 2023
Hao Xiong, Zifeng Wang, Zhijian-huang, Hao tian jia, Yefan-huang, Cheng zhong xu, Zheng-li, Zhi hong chen, Zhi yuan liu, and Zhong zhen su. Knowledge-augmented language model for clinical question answering, 2023
work page 2023
-
[42]
Kg-bert: Bert for knowledge graph completion, 2019
Liang Yao, Chengsheng Mao, and Yuan Luo. Kg-bert: Bert for knowledge graph completion, 2019. URL https://arxiv.org/abs/1909.03193
-
[43]
The value of semantic parse labeling for knowledge base question answering
Wen-tau Yih, Matthew Richardson, Chris Meek, Ming-Wei Chang, and Jina Suh. The value of semantic parse labeling for knowledge base question answering. In ACL, 2016. URL https://aclanthology.org/P16-2033.pdf
work page 2016
-
[44]
Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment
Siliang Zeng, Quan Wei, William Brown, Oana Frunza, Yuriy Nevmyvaka, and Mingyi Hong. Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment. arXiv preprint arXiv:2505.11821, 2025
-
[45]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023. URL https://arxiv.org/abs/2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Knowledge graph-guided retrieval augmented generation, 2025
Xiangrong Zhu, Yuexiang Xie, Yi Liu, Yaliang Li, and Wei Hu. Knowledge graph-guided retrieval augmented generation, 2025. URL https://arxiv.org/abs/2502.06864
-
[47]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[48]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[49]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.