TimeRewarder: Learning Dense Reward from Passive Videos via Frame-wise Temporal Distance
Pith reviewed 2026-05-21 21:53 UTC · model grok-4.3
The pith
TimeRewarder learns dense rewards for RL by estimating temporal distances between frames in passive videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
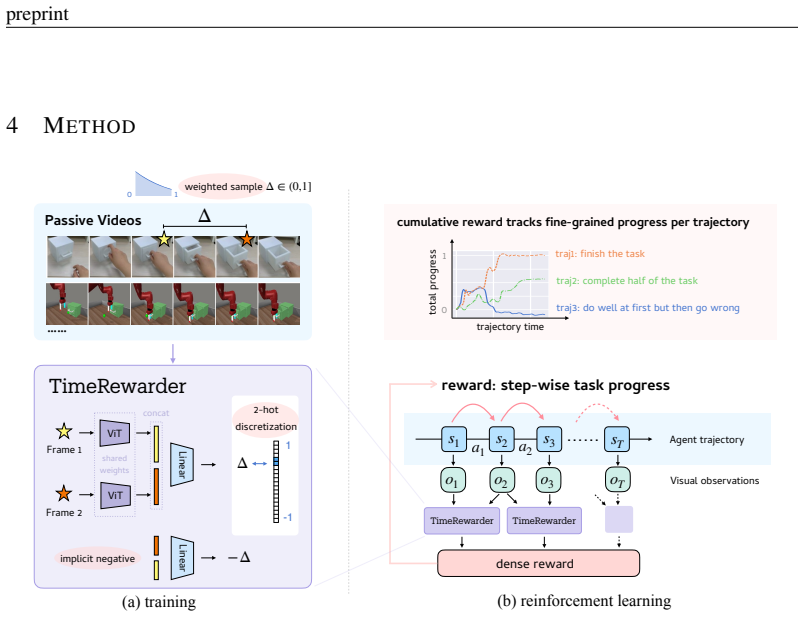
TimeRewarder derives progress estimation signals from passive videos, including robot demonstrations and human videos, by modeling temporal distances between frame pairs and supplies these signals as step-wise proxy rewards to guide reinforcement learning in sparse-reward robotics tasks.
What carries the argument
A frame-pair temporal distance predictor trained on passive videos that converts predicted distances into dense progress-based rewards for RL.
If this is right
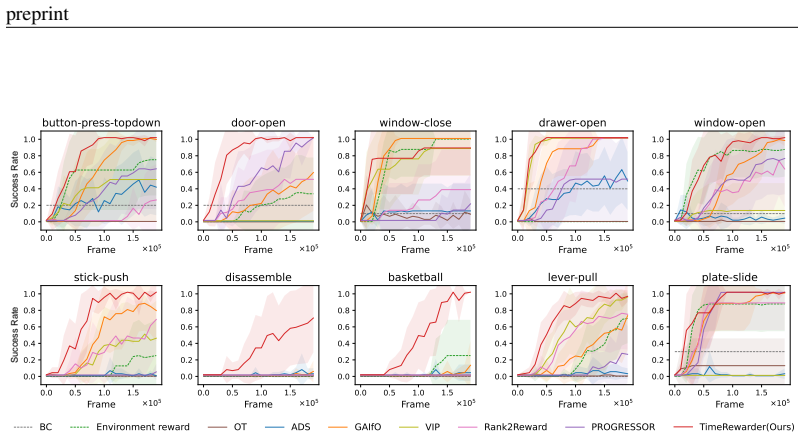
- RL agents reach near-perfect success in nine of ten Meta-World tasks using only 200,000 environment interactions each.
- The learned rewards improve both final performance and sample efficiency over previous reward-learning methods and manually designed dense rewards.
- The same approach can be pretrained on real-world human videos, enabling reward signals from diverse non-robot sources.
- No task-specific reward engineering is required once the temporal-distance model is trained.
Where Pith is reading between the lines
- The method may extend to other sequential decision domains where video or trajectory data is abundant but dense rewards are scarce.
- If temporal distance proves robust across viewpoints, similar models could support reward learning from internet-scale video without robot-specific data collection.
- Combining the temporal-distance signal with other unsupervised objectives from the same videos could produce even richer reward functions.
- The approach invites testing whether the learned rewards transfer zero-shot to new robot embodiments or tasks not seen during video pretraining.
Load-bearing premise
Temporal distances between frames in passive videos reliably indicate task progress that remains useful when transferred as rewards to a robot's own observations.
What would settle it
An RL policy trained with TimeRewarder rewards on a Meta-World task achieves success rates no higher than a sparse-reward baseline after 200,000 interactions.
Figures









read the original abstract
Designing dense rewards is crucial for reinforcement learning (RL), yet in robotics it often demands extensive manual effort and lacks scalability. One promising solution is to view task progress as a dense reward signal, as it quantifies the degree to which actions advance the system toward task completion over time. We present TimeRewarder, a simple yet effective reward learning method that derives progress estimation signals from passive videos, including robot demonstrations and human videos, by modeling temporal distances between frame pairs. We then demonstrate how TimeRewarder can supply step-wise proxy rewards to guide reinforcement learning. In our comprehensive experiments on ten challenging Meta-World tasks, we show that TimeRewarder dramatically improves RL for sparse-reward tasks, achieving nearly perfect success in 9/10 tasks with only 200,000 environment interactions per task. This approach outperformed previous methods and even the manually designed environment dense reward on both the final success rate and sample efficiency. Moreover, we show that TimeRewarder pretraining can exploit real-world human videos, highlighting its potential as a scalable approach to rich reward signals from diverse video sources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TimeRewarder, a method to derive dense rewards for RL by training a model on passive videos (robot demos or human videos) to predict temporal distances between frame pairs, then using the resulting progress signal as step-wise proxy rewards. It reports that this yields near-perfect success on 9/10 Meta-World tasks using only 200k environment steps per task, outperforming prior methods and even the hand-designed environment dense reward, while also showing applicability to real-world human videos.
Significance. If the central empirical claims prove robust, the work offers a scalable route to progress-based dense rewards from abundant video data, reducing manual reward engineering in robotics RL. The reported outperformance on multiple sparse-reward tasks and the extension to human videos would constitute a practical contribution to sample-efficient policy learning.
major comments (2)
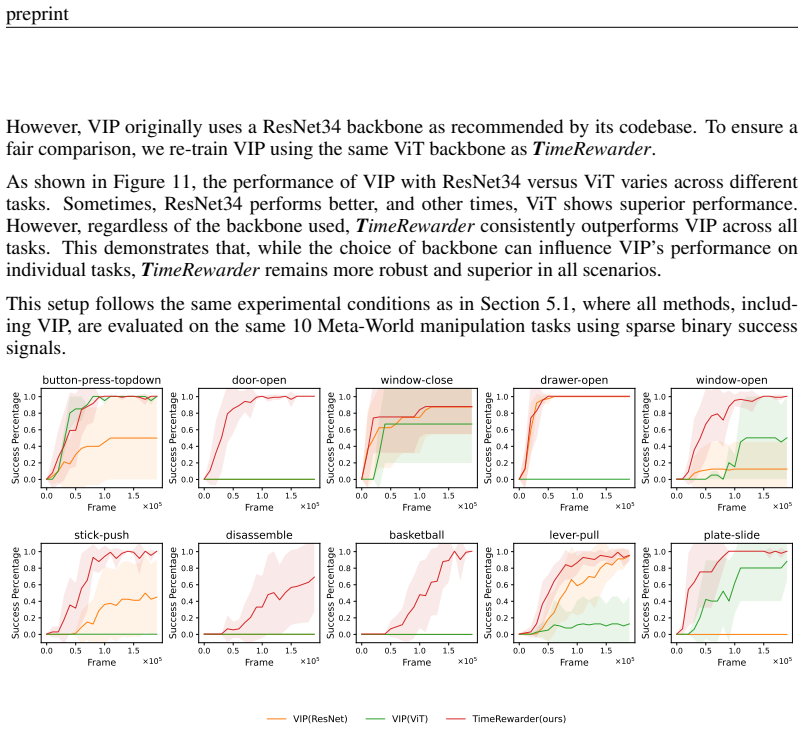
- [§4 Experiments] §4 Experiments: The headline results on ten Meta-World tasks report high success rates and sample efficiency but provide neither error bars, the number of random seeds, nor ablation tables on video source selection and hyperparameter sensitivity; without these it is impossible to assess whether the claimed gains over baselines and the environment dense reward are statistically reliable or brittle.
- [§3 Method] §3 Method: The derivation of the reward from the learned temporal-distance model does not include explicit handling or empirical tests for distribution shift (viewpoint, background, gripper appearance, or motion statistics) between the passive training videos and the states visited during RL exploration; this assumption is load-bearing for the claim that the scalar reward gradients point toward task completion.
minor comments (2)
- [§3] Notation for the temporal distance function and its conversion to a per-step reward could be stated more explicitly in the equations to improve reproducibility.
- [Figures] Figure captions and legends should clarify which video sources (robot demos vs. human videos) correspond to each curve.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental reporting and the treatment of distribution shift. We address each major comment below and indicate the revisions planned for the next manuscript version.
read point-by-point responses
-
Referee: [§4 Experiments] §4 Experiments: The headline results on ten Meta-World tasks report high success rates and sample efficiency but provide neither error bars, the number of random seeds, nor ablation tables on video source selection and hyperparameter sensitivity; without these it is impossible to assess whether the claimed gains over baselines and the environment dense reward are statistically reliable or brittle.
Authors: We agree that explicit reporting of error bars, the number of random seeds, and additional ablations would strengthen the assessment of statistical reliability. The experiments were run with 5 random seeds per task, with the headline numbers reflecting averages; we will add error bars to the main results table and figures in the revised manuscript. We will also include ablation tables on video source selection (robot demonstrations versus human videos) and hyperparameter sensitivity in the supplementary material to demonstrate that the reported gains are not brittle. revision: yes
-
Referee: [§3 Method] §3 Method: The derivation of the reward from the learned temporal-distance model does not include explicit handling or empirical tests for distribution shift (viewpoint, background, gripper appearance, or motion statistics) between the passive training videos and the states visited during RL exploration; this assumption is load-bearing for the claim that the scalar reward gradients point toward task completion.
Authors: The referee correctly notes that the method relies on the temporal-distance model transferring from passive videos to RL states without dedicated shift-handling mechanisms. While the successful transfer to real-world human videos provides some empirical support for robustness under natural shifts in viewpoint and appearance, we did not include explicit tests or mitigation strategies in the original submission. In the revision we will add a discussion paragraph in Section 3 on this assumption together with a small-scale experiment evaluating reward prediction accuracy under controlled distribution shifts (e.g., background and gripper changes). revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper trains a supervised temporal-distance model on frame pairs drawn from passive videos, using the known elapsed time between frames as the regression target. This model is then applied to produce scalar proxy rewards inside an independent RL loop on Meta-World tasks. The central claims are supported by external benchmark comparisons (success rates and sample efficiency against prior methods and hand-designed dense rewards) rather than any redefinition of fitted quantities as predictions or any load-bearing self-citation chain. No equation reduces the output reward to the training inputs by construction, and the approach remains falsifiable on held-out robot trajectories.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporal distance between frames correlates with task progress in a way that is transferable to RL reward signals.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present TimeRewarder, a simple yet effective reward learning method that derives progress estimation signals from passive videos... by modeling temporal distances between frame pairs... rTR(ot, ot+1) = Φ^{-1}[Fθ(ot, ot+1)] ∈ [-1,1]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tewodros Ayalew, Xiao Zhang, Kevin Yuanbo Wu, Tianchong Jiang, Michael Maire, and Matthew R Walter. Progressor: A perceptually guided reward estimator with self-supervised online refine- ment.arXiv preprint arXiv:2411.17764,
-
[2]
Annie S Chen, Suraj Nair, and Chelsea Finn. Learning generalizable robotic reward functions from” in-the-wild” human videos.arXiv preprint arXiv:2103.16817,
-
[3]
Primal wasserstein imita- tion learning.arXiv preprint arXiv:2006.04678,
Robert Dadashi, L´eonard Hussenot, Matthieu Geist, and Olivier Pietquin. Primal wasserstein imita- tion learning.arXiv preprint arXiv:2006.04678,
-
[4]
Minghuan Liu, Zhengbang Zhu, Yuzheng Zhuang, Weinan Zhang, Jianye Hao, Yong Yu, and Jun Wang. Plan your target and learn your skills: Transferable state-only imitation learning via de- coupled policy optimization.arXiv preprint arXiv:2203.02214,
-
[5]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training. arXiv preprint arXiv:2210.00030,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Ruiqian Nai, Jiacheng You, Liu Cao, Hanchen Cui, Shiyuan Zhang, Huazhe Xu, and Yang Gao. Fine-tuning hard-to-simulate objectives for quadruped locomotion: A case study on total power saving.arXiv preprint arXiv:2502.10956,
-
[7]
Combining self-supervised learning and imitation for vision-based rope manipulation
Ashvin Nair, Dian Chen, Pulkit Agrawal, Phillip Isola, Pieter Abbeel, Jitendra Malik, and Sergey Levine. Combining self-supervised learning and imitation for vision-based rope manipulation. In 2017 IEEE international conference on robotics and automation (ICRA), pp. 2146–2153. IEEE,
work page 2017
-
[8]
Deepak Pathak, Parsa Mahmoudieh, Guanghao Luo, Pulkit Agrawal, Dian Chen, Yide Shentu, Evan Shelhamer, Jitendra Malik, Alexei A Efros, and Trevor Darrell. Zero-shot visual imitation. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp. 2050–2053,
work page 2050
-
[9]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
11 preprint Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.arXiv preprint arXiv:1709.10087,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Sample-efficient on-policy imitation learning from observations.arXiv preprint arXiv:2306.09805,
Jo˜ao A Cˆandido Ramos, Lionel Blond´e, Naoya Takeishi, and Alexandros Kalousis. Sample-efficient on-policy imitation learning from observations.arXiv preprint arXiv:2306.09805,
-
[11]
Nicholas Roy, Ingmar Posner, Tim Barfoot, Philippe Beaudoin, Yoshua Bengio, Jeannette Bohg, Oliver Brock, Isabelle Depatie, Dieter Fox, Dan Koditschek, et al. From machine learn- ing to robotics: Challenges and opportunities for embodied intelligence.arXiv preprint arXiv:2110.15245,
-
[12]
Time-contrastive networks: Self-supervised learning from video
Pierre Sermanet, Corey Lynch, Yevgen Chebotar, Jasmine Hsu, Eric Jang, Stefan Schaal, Sergey Levine, and Google Brain. Time-contrastive networks: Self-supervised learning from video. In 2018 IEEE international conference on robotics and automation (ICRA), pp. 1134–1141. IEEE,
work page 2018
-
[13]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal under- standing across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Behavioral Cloning from Observation
Faraz Torabi, Garrett Warnell, and Peter Stone. Behavioral cloning from observation.arXiv preprint arXiv:1805.01954, 2018a. Faraz Torabi, Garrett Warnell, and Peter Stone. Generative adversarial imitation from observation. arXiv preprint arXiv:1807.06158, 2018b. C´edric Villani et al.Optimal transport: old and new, volume
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Shengjie Wang, Shaohuai Liu, Weirui Ye, Jiacheng You, and Yang Gao. Efficientzero v2: Mastering discrete and continuous control with limited data.arXiv preprint arXiv:2403.00564,
- [16]
-
[17]
2.Door open:to open a cabinet door with a handle
12 preprint A APPENDIX A.1 TASKS FOREVALUATION In this paper, we experiment with the following 10 tasks from the Meta-World suite (Yu et al., 2020): 1.Button press topdown:to press a button from the top. 2.Door open:to open a cabinet door with a handle. 3.Window close:to close a sliding window with a handle. 4.Drawer open:to open a cabinet drawer with a h...
work page 2020
-
[18]
Each task includes 20 videos captured from a fixed viewpoint
13 preprint (a) drawer-open (b) button-press-topdown (c) door-open Figure 9: Complete set of human videos recorded in thesingle-viewcondition for each of the three tasks. Each task includes 20 videos captured from a fixed viewpoint. (a) drawer-open (b) button-press-topdown (c) door-open Figure 10: Complete set of human videos recorded in themulti-viewcond...
work page 2022
-
[19]
16 preprint Table 1: Reward model hyperparameters. Config Value Backbone ViT-B/16 Feature dimension1024(512×2) Output bins20(two-hot discretization) Training pairs per epoch10,000 Epochs100 Warm-up epochs5 Batch size16 Accumulation steps1 Optimizer Adam Learning rate2×10 −5 We equip all the methods with the same underlying RL algorithm, DrQ-v2 (Yarats et ...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.