Do AI Models Dream of Faster Code? An Empirical Study on LLM-Proposed Performance Improvements in Real-World Software
Pith reviewed 2026-05-18 06:36 UTC · model grok-4.3
The pith
LLMs can generate performance improvements for real Java production code but produce highly volatile results that lag human developers on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Although LLMs demonstrate a surprisingly high capability to solve these complex engineering problems, their solutions suffer from extreme volatility and still lag behind human developers on average. Consequently, we find that the current benchmarks based on algorithmic tasks yields an overly optimistic assessment of LLM capabilities. We trace this real-world performance gap to two primary limitations: first, LLMs struggle to autonomously pinpoint performance hotspots, and second, even with explicit guidance, they often fall short of synthesizing optimal algorithmic improvements.
What carries the argument
A collection of 65 performance-critical tasks mined from open-source Java projects, each validated with original developer-written JMH benchmarks, used to compare LLM-proposed optimizations directly against human baselines.
If this is right
- Algorithmic puzzle benchmarks overestimate how well LLMs handle performance work in production software.
- LLMs need additional runtime observation capabilities to locate slowdowns reliably.
- Even when hotspots are identified for them, LLMs still fall short of the most effective algorithmic changes humans make.
- Performance improvement systems should shift from static code generation toward agent-based approaches that can profile and react to runtime behavior.
Where Pith is reading between the lines
- Pairing LLMs with automated profiling tools could help close the gap in hotspot detection and reduce result volatility.
- Repeating the study on performance-critical code in other languages could show whether the volatility and gap are Java-specific or general across languages.
- A hybrid process in which humans flag hotspots and LLMs propose fixes might combine the strengths of both while avoiding full autonomy.
Load-bearing premise
The 65 mined tasks from performance-critical open-source Java projects, together with the developer-written JMH benchmarks, provide a representative and rigorous basis for comparing LLM and human performance improvements in real production code.
What would settle it
A follow-up experiment on the same or a larger set of real Java tasks in which LLMs given runtime profiles produce speedups that consistently match or exceed human baselines with low variance across runs would falsify the reported performance gap and volatility.
Figures





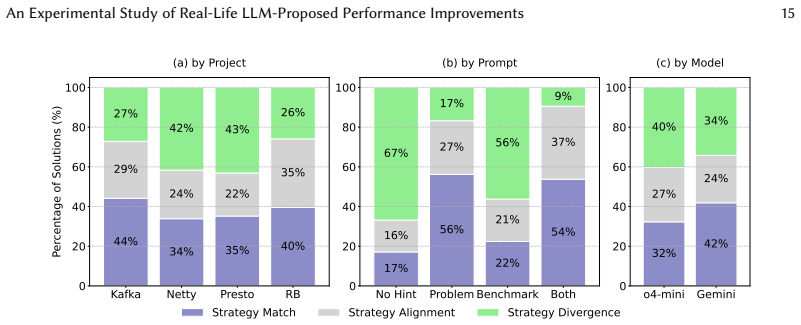

read the original abstract
Large Language Models (LLMs) can generate code, but can they generate fast code for complex, real-world software systems? In this study, we investigate this question using a dataset of 65 tasks mined from performance-critical open-source Java projects. Unlike prior studies, which focused on algorithmic puzzles, we conduct experiments on actual performance-sensitive production code and employ developer-written JMH benchmarks to rigorously validate performance gains against human baselines. Our results reveal a nuanced reality -- although LLMs demonstrate a surprisingly high capability to solve these complex engineering problems, their solutions suffer from extreme volatility and still lag behind human developers on average. Consequently, we find that the current benchmarks based on algorithmic tasks yields an overly optimistic assessment of LLM capabilities. We trace this real-world performance gap to two primary limitations: first, LLMs struggle to autonomously pinpoint performance hotspots, and second, even with explicit guidance, they often fall short of synthesizing optimal algorithmic improvements. Our results highlight the need to move beyond static code generation towards more complex agent-based systems that are able to profile and observe runtime behavior for performance improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study comparing LLM-proposed performance optimizations against human baselines across 65 tasks mined from performance-critical open-source Java projects. The authors employ developer-written JMH microbenchmarks to measure actual runtime gains, finding that LLMs show surprisingly high success rates on these complex engineering tasks yet produce highly volatile outputs that lag human developers on average. They conclude that this real-world gap implies current algorithmic-task benchmarks overestimate LLM capabilities, attributing the shortfall to difficulties in autonomous hotspot detection and synthesis of optimal algorithmic changes, and advocate for agent-based systems incorporating runtime profiling.
Significance. If the core empirical findings hold after addressing sampling and baseline issues, the work offers a timely corrective to the prevailing evaluation paradigm in LLM code generation research. By shifting from synthetic puzzles to production Java code with rigorous JMH validation, it provides concrete evidence that LLM performance claims may not generalize, underscoring the value of realistic benchmarks and motivating more sophisticated agentic approaches. The use of real projects and quantitative human comparisons is a clear methodological strength.
major comments (2)
- [§3.1] §3.1 (Task Mining): The criteria used to select the 65 performance-critical tasks are insufficiently specified. It remains unclear how 'performance-critical' was operationalized (e.g., via profiling data, commit messages, or issue reports), what project diversity was achieved (number of repositories, application domains, sizes), and whether tasks were filtered or favored by the pre-existence of JMH benchmarks. These details are load-bearing for the central claim that algorithmic benchmarks are overly optimistic, as a non-representative sample could produce the observed volatility and lag without implying a systematic overestimation.
- [§4.2] §4.2–4.3 (Human Baselines): The construction of the human performance baseline is ambiguous. The manuscript does not state whether the reported human improvements derive from the original developer commits in the repositories or from independent expert developers given identical prompts, constraints, and time limits as the LLMs. This distinction directly affects whether the average lag and volatility can be interpreted as evidence that algorithmic benchmarks are optimistic rather than an artifact of mismatched comparison conditions.
minor comments (2)
- [Abstract] Abstract, line 8: 'yields' should be 'yield' to agree with the plural subject 'benchmarks'.
- [Table 2] Table 2: The volatility metric (standard deviation of speedups) would benefit from an explicit definition or formula in the caption or methods, as readers must currently infer it from context.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. These have prompted us to clarify key methodological details. We respond to each major comment below and indicate where revisions will be made to the next version of the paper.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Task Mining): The criteria used to select the 65 performance-critical tasks are insufficiently specified. It remains unclear how 'performance-critical' was operationalized (e.g., via profiling data, commit messages, or issue reports), what project diversity was achieved (number of repositories, application domains, sizes), and whether tasks were filtered or favored by the pre-existence of JMH benchmarks. These details are load-bearing for the central claim that algorithmic benchmarks are overly optimistic, as a non-representative sample could produce the observed volatility and lag without implying a systematic overestimation.
Authors: We agree that §3.1 would benefit from greater specificity to support the generalizability of our findings. The tasks were mined by searching commit histories and linked issue reports in open-source Java repositories for mentions of performance optimizations or hotspots. In the revised manuscript we will explicitly state the operationalization (commit messages and issue reports), report the number of repositories and their domains (e.g., data processing, web infrastructure), provide summary statistics on project sizes, and confirm that pre-existing JMH benchmarks were a deliberate selection filter to enable rigorous runtime validation. We maintain that this sampling strategy targets authentic performance-engineering work rather than synthetic problems, thereby reinforcing rather than undermining the claim that algorithmic benchmarks overestimate LLM capabilities. revision: yes
-
Referee: [§4.2] §4.2–4.3 (Human Baselines): The construction of the human performance baseline is ambiguous. The manuscript does not state whether the reported human improvements derive from the original developer commits in the repositories or from independent expert developers given identical prompts, constraints, and time limits as the LLMs. This distinction directly affects whether the average lag and volatility can be interpreted as evidence that algorithmic benchmarks are optimistic rather than an artifact of mismatched comparison conditions.
Authors: The human baselines reported in §§4.2–4.3 are taken directly from the original developer commits that introduced the performance improvements in the studied repositories. These represent real, deployed human solutions rather than new experiments with independent experts under LLM-style constraints. We selected this comparison to evaluate LLM proposals against authentic production changes. In the revision we will add explicit wording in §§4.2–4.3 stating the source of the baselines and briefly discuss why this real-world reference is appropriate for assessing whether algorithmic benchmarks are overly optimistic. revision: yes
Circularity Check
Empirical study with no circular derivations or self-referential results
full rationale
This is a straightforward empirical reporting study that mines 65 tasks from open-source Java projects, applies LLMs to propose performance improvements, and compares results against developer-written JMH benchmarks and human baselines. No mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or self-citation chains are present in the abstract or described methodology. The central claim that algorithmic benchmarks are overly optimistic is an interpretive conclusion drawn from direct experimental comparisons on the collected dataset rather than any reduction to inputs by construction. The study is self-contained as an observational report; representativeness concerns affect external validity but do not create circularity in the reported findings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Developer-written JMH benchmarks provide an accurate and unbiased measure of performance differences
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We collect a dataset of 65 real performance-improving changes from four large and performance-sensitive Java projects... employ developer-written JMH benchmarks to rigorously validate performance gains against human baselines.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use a two-sided Wilcoxon signed-rank test... Vargha-Delaney A12 effect size
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
CppPerf: An Automated Pipeline and Dataset for Performance-Improving C++ Commits
CppPerf-Mine produces CppPerf-DB, a benchmark of 347 real-world performance-improving C++ patches (39% multi-file) from 42 repositories to evaluate repository-level repair tools.
Reference graph
Works this paper leans on
-
[1]
Sarah Abdulsalam, Ziliang Zong, Qijun Gu, and Meikang Qiu. 2015. Using the Greenup, Powerup, and Speedup metrics to evaluate software energy efficiency. In2015 Sixth International Green and Sustainable Computing Conference (IGSC). 1–8. doi:10.1109/IGCC.2015.7393699
-
[2]
Ali Abedi and Tim Brecht. 2017. Conducting Repeatable Experiments in Highly Variable Cloud Computing Environ- ments. InProceedings of the 8th ACM/SPEC on International Conference on Performance Engineering(L’Aquila, Italy) (ICPE ’17). Association for Computing Machinery, New York, NY, USA, 287–292. doi:10.1145/3030207.3030229
- [3]
-
[4]
Wajdi Aljedaani, Abdulrahman Habib, Ahmed Aljohani, Marcelo Eler, and Yunhe Feng. 2024. Does ChatGPT Generate Accessible Code? Investigating Accessibility Challenges in LLM-Generated Source Code. InProceedings of the 21st International Web for All Conference(Singapore, Singapore)(W4A ’24). Association for Computing Machinery, New York, NY, USA, 165–176. d...
-
[5]
Ando, Chi-Kwong Li, and Roy Mathias
T. Ando, Chi-Kwong Li, and Roy Mathias. 2004. Geometric means.Linear Algebra Appl.385 (2004), 305–334. doi:10. 1016/j.laa.2003.11.019 Special Issue in honor of Peter Lancaster
work page 2004
-
[6]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models. arXiv:2108.07732 [cs.PL] https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Sebastian Baltes and Paul Ralph. 2022. Sampling in software engineering research: a critical review and guidelines. Empirical Softw. Engg.27, 4 (July 2022), 31 pages. doi:10.1007/s10664-021-10072-8
-
[8]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2024. RepairAgent: An Autonomous, LLM-Based Agent for Program Repair. arXiv:2403.17134 [cs.SE] https://arxiv.org/abs/2403.17134
work page internal anchor Pith review arXiv 2024
-
[9]
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2022. CodeT: Code Generation with Generated Tests. arXiv:2207.10397 [cs.CL] https://arxiv.org/abs/2207.10397
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jianwei Yin. 2024. ChatUniTest: A Framework for LLM-Based Test Generation. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations 17https://github.com/icetlab/EvalLLMforJava , Vol. 1, No. 1, Article . Publication date: October 2025. 20 Lirong Yi, Gregory Gay, a...
-
[12]
Tristan Coignion, Clément Quinton, and Romain Rouvoy. 2024. A Performance Study of LLM-Generated Code on Leetcode. InProceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering (Salerno, Italy)(EASE ’24). Association for Computing Machinery, New York, NY, USA, 79–89. doi:10.1145/3661167. 3661221
-
[13]
Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I. Wang. 2024. CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution. arXiv:2401.03065 [cs.SE] https://arxiv.org/abs/2401. 03065
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Xue Han and Tingting Yu. 2016. An Empirical Study on Performance Bugs for Highly Configurable Software Systems. InProceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (Ciudad Real, Spain)(ESEM ’16). Association for Computing Machinery, New York, NY, USA, Article 23, 10 pages. doi:10.1145/2961111.2962602
-
[15]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. 2021. Measuring Coding Challenge Competence With APPS. arXiv:2105.09938 [cs.SE] https://arxiv.org/abs/2105.09938
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Dong Huang, Yuhao Qing, Weiyi Shang, Heming Cui, and Jie M. Zhang. 2024. EffiBench: Benchmarking the Efficiency of Automatically Generated Code. InAdvances in Neural Information Processing Systems, A. Glober- son, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 11506–11544. https://proceedings....
work page 2024
-
[17]
Baskhad Idrisov, Esther Eisenacher, and Tim Schlippe. 2025. Program Code Generation: Single LLMs vs. Multi-Agent Systems. In2025 7th International Conference on Natural Language Processing (ICNLP). 121–127. doi:10.1109/ICNLP65360. 2025.11108400
-
[18]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770 [cs.CL] https://arxiv.org/abs/ 2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Guoliang Jin, Linhai Song, Xiaoming Shi, Joel Scherpelz, and Shan Lu. 2012. Understanding and detecting real-world performance bugs.SIGPLAN Not.47, 6 (June 2012), 77–88. doi:10.1145/2345156.2254075
-
[20]
Ranim Khojah, Francisco Gomes Oliveira Neto, Mazen Mohamad, and Philipp Leitner. 2025. The Impact of Prompt Programming on Function-Level Code Generation.IEEE Transactions on Software Engineering (TSE)(2025)
work page 2025
-
[21]
Christoph Laaber, Stefan Würsten, Harald C. Gall, and Philipp Leitner. 2020. Dynamically reconfiguring software microbenchmarks: reducing execution time without sacrificing result quality. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (Virtual Event, USA)(ES...
-
[22]
Claire Le Goues, Michael Pradel, and Abhik Roychoudhury. 2019. Automated program repair.Commun. ACM62, 12 (Nov. 2019), 56–65. doi:10.1145/3318162
-
[23]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushm...
-
[24]
Bo Liu, Yanjie Jiang, Yuxia Zhang, Nan Niu, Guangjie Li, and Hui Liu. 2025. Exploring the potential of general purpose LLMs in automated software refactoring: an empirical study.Automated Software Engg.32, 1 (March 2025), 42 pages. doi:10.1007/s10515-025-00500-0
- [25]
-
[26]
Tianyang Liu, Canwen Xu, and Julian McAuley. 2023. RepoBench: Benchmarking Repository-Level Code Auto- Completion Systems. arXiv:2306.03091 [cs.CL] https://arxiv.org/abs/2306.03091
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an LLM to Help With Code Understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering (Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY, USA, Article 97, 13 pages. doi:10. 1145/3597503.3639187
-
[28]
Changan Niu, Ting Zhang, Chuanyi Li, Bin Luo, and Vincent Ng. 2024. On Evaluating the Efficiency of Source Code Generated by LLMs. InProceedings of the 2024 IEEE/ACM First International Conference on AI Foundation Models and , Vol. 1, No. 1, Article . Publication date: October 2025. An Experimental Study of Real-Life LLM-Proposed Performance Improvements ...
-
[29]
Ali Nouri, Beatriz Cabrero-Daniel, Fredrik Törner, Håkan Sivencrona, and Christian Berger. 2024. Engineering Safety Requirements for Autonomous Driving with Large Language Models. In2024 IEEE 32nd International Requirements Engineering Conference (RE). 218–228. doi:10.1109/RE59067.2024.00029
-
[30]
Lyu, Caiming Xiong, Silvio Savarese, and Doyen Sahoo
Yun Peng, Akhilesh Deepak Gotmare, Michael R. Lyu, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. 2025. PerfCodeGen: Improving Performance of LLM Generated Code with Execution Feedback. In2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge). 1–13. doi:10.1109/Forge66646.2025. 00008
-
[32]
Yun Peng, Jun Wan, Yichen Li, and Xiaoxue Ren. 2025. COFFE: A Code Efficiency Benchmark for Code Generation. Proc. ACM Softw. Eng.2, FSE, Article FSE012 (June 2025), 24 pages. doi:10.1145/3715727
-
[33]
Zichao Qi, Fan Long, Sara Achour, and Martin Rinard. 2015. An analysis of patch plausibility and correctness for generate-and-validate patch generation systems. InProceedings of the 2015 International Symposium on Software Testing and Analysis(Baltimore, MD, USA)(ISSTA 2015). Association for Computing Machinery, New York, NY, USA, 24–36. doi:10.1145/27717...
- [34]
-
[35]
Hazem Samoaa and Philipp Leitner. 2021. An Exploratory Study of the Impact of Parameterization on JMH Measurement Results in Open-Source Projects. InProceedings of the ACM/SPEC International Conference on Performance Engineering (Virtual Event, France)(ICPE ’21). Association for Computing Machinery, New York, NY, USA, 213–224. doi:10.1145/ 3427921.3450243
- [36]
-
[37]
Atsushi Shirafuji, Yusuke Oda, Jun Suzuki, Makoto Morishita, and Yutaka Watanobe. 2023. Refactoring Programs Using Large Language Models with Few-Shot Examples. In2023 30th Asia-Pacific Software Engineering Conference (APSEC). 151–160. doi:10.1109/APSEC60848.2023.00025
-
[38]
S.E. Sim, S. Easterbrook, and R.C. Holt. 2003. Using benchmarking to advance research: a challenge to software engineering. In25th International Conference on Software Engineering, 2003. Proceedings.74–83. doi:10.1109/ICSE.2003. 1201189
-
[39]
John Smith. 1991. Performance engineering of software systems.Journal of the Operational Research Society42, 10 (1991), 903–904
work page 1991
-
[40]
Luca Traini, Vittorio Cortellessa, Daniele Di Pompeo, and Michele Tucci. 2023. Towards effective assessment of steady state performance in Java software: Are we there yet?Empirical Software Engineering28, 1 (2023), 13. doi:10.1007/s10664- 022-10247-x
-
[41]
András Vargha and Harold D. Delaney. 2000. A Critique and Improvement of the CL Common Language Effect Size Statistics of McGraw and Wong.Journal of Educational and Behavioral Statistics25, 2 (2000), 101–132. doi:10.3102/ 10769986025002101 arXiv:https://doi.org/10.3102/10769986025002101
-
[42]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems, I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30. Curran Associates, Inc. https://proc...
work page 2017
-
[43]
Xiang Wan, Wenqian Wang, Jiming Liu, and Tiejun Tong. 2014. Estimating the sample mean and standard deviation from the sample size, median, range and/or interquartile range.BMC medical research methodology14, 1 (2014), 135. doi:10.1186/1471-2288-14-135
-
[44]
Tobias Weyand, Andre Araujo, Bingyi Cao, and Jack Sim. 2020. Google Landmarks Dataset v2 - A Large-Scale Benchmark for Instance-Level Recognition and Retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2020
- [45]
-
[46]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated Program Repair in the Era of Large Pre- trained Language Models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). 1482–1494. doi:10.1109/ICSE48619.2023.00129
-
[47]
Nan Xu and Xuezhe Ma. 2025. LLM The Genius Paradox: A Linguistic and Math Expert’s Struggle with Simple Word-based Counting Problems. arXiv:2410.14166 [cs.CL] https://arxiv.org/abs/2410.14166 , Vol. 1, No. 1, Article . Publication date: October 2025. 22 Lirong Yi, Gregory Gay, and Philipp Leitner
-
[48]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
-
[49]
InAdvances in Neural Information Processing Systems, A
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 50528–50652. https://proceedings.neurips.cc/paper_files/paper/2024/file/ 5a7c947568c1b1328ccc5230172e1e7...
work page 2024
-
[50]
Hao Yu, Bo Shen, Dezhi Ran, Jiaxin Zhang, Qi Zhang, Yuchi Ma, Guangtai Liang, Ying Li, Qianxiang Wang, and Tao Xie. 2024. CoderEval: A Benchmark of Pragmatic Code Generation with Generative Pre-trained Models. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal)(ICSE ’24). Association for Computing Machiner...
- [51]
- [52]
-
[53]
Li Zhong and Zilong Wang. 2024. Can LLM Replace Stack Overflow? A Study on Robustness and Reliability of Large Language Model Code Generation.Proceedings of the AAAI Conference on Artificial Intelligence38, 19 (Mar. 2024), 21841–21849. doi:10.1609/aaai.v38i19.30185 Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009 , Vol. 1, No. 1, Art...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.