AI use in American newspapers is widespread, uneven, and rarely disclosed
Pith reviewed 2026-05-18 04:52 UTC · model grok-4.3
The pith
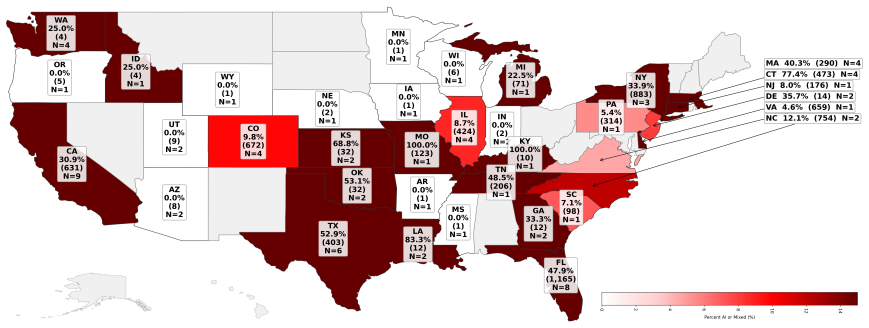
Roughly 9% of newly published American newspaper articles are partially or fully AI-generated.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
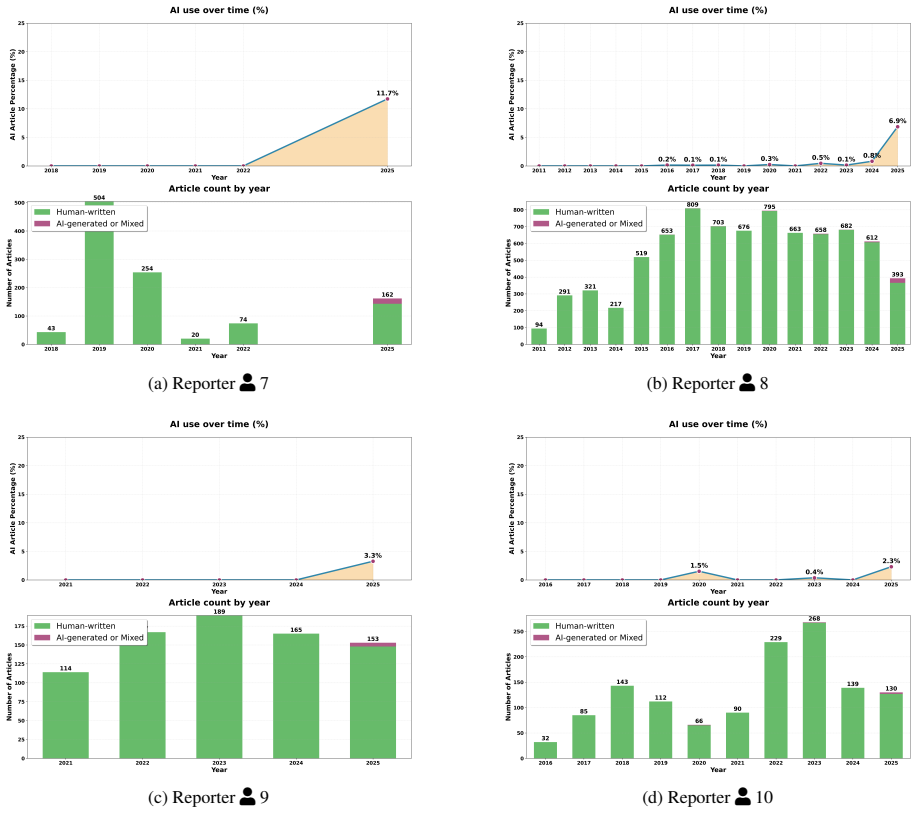
Using the Pangram AI detector on a dataset of 186K articles published by 1.5K American newspapers in summer 2025, we find that approximately 9% of newly-published articles are either partially or fully AI-generated. This use is uneven, appearing more in smaller outlets, weather and technology topics, and certain ownership groups. Opinion pieces from the Washington Post, New York Times, and Wall Street Journal are 6.4 times more likely to contain AI-generated content than news articles, and a manual audit reveals disclosures in only five of 100 AI-flagged articles.
What carries the argument
Large-scale application of the Pangram AI text detector across 186K newspaper articles, followed by breakdown by outlet size, topic, ownership, and a manual audit of disclosures in flagged items.
If this is right
- AI generation concentrates more in smaller local newspapers than in large national ones.
- Opinion sections at major papers contain AI content at far higher rates than straight news reporting.
- Disclosures of AI assistance appear in only a small minority of cases where it is used.
- Current editorial standards leave most AI-assisted articles without any reader notice.
Where Pith is reading between the lines
- If the detector holds up, local newsrooms may be integrating generative tools faster than larger organizations.
- AI use in opinion writing by public figures could shift how readers assess the origin of commentary.
- Widespread undetected AI content might gradually change audience expectations for what counts as original reporting.
Load-bearing premise
The Pangram detector accurately identifies AI-generated text in newspaper articles rather than flagging normal journalistic phrasing, topic-specific language, or outlet style as AI output.
What would settle it
Independent human experts manually labeling a random sample of articles flagged as AI-generated by Pangram, plus a matched set of unflagged articles from the same newspapers, to measure the detector's actual accuracy rate on this material.
Figures





















read the original abstract
AI is rapidly transforming journalism, but the extent of its use in published newspaper articles remains unclear. We address this gap by auditing a large-scale dataset of 186K articles from online editions of 1.5K American newspapers published in the summer of 2025. Using Pangram, a state-of-the-art AI detector, we discover that approximately 9% of newly-published articles are either partially or fully AI-generated. This AI use is unevenly distributed, appearing more frequently in smaller, local outlets, in specific topics such as weather and technology, and within certain ownership groups. We also analyze 45K opinion pieces from Washington Post, New York Times, and Wall Street Journal, finding that they are 6.4 times more likely to contain AI-generated content than news articles from the same publications, with many AI-flagged op-eds authored by prominent public figures. Despite this prevalence, we find that AI use is rarely disclosed: a manual audit of 100 AI-flagged articles found only five disclosures of AI use. Overall, our audit highlights the immediate need for greater transparency and updated editorial standards regarding the use of AI in journalism to maintain public trust.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript audits AI use in journalism via the Pangram detector applied to 186K articles from 1.5K U.S. newspapers (summer 2025), reporting that ~9% are partially or fully AI-generated. Rates are higher in smaller/local outlets, weather/technology topics, and certain ownership groups; opinion pieces from WaPo/NYT/WSJ are 6.4x more likely to be flagged than news articles from the same outlets; and a manual audit of 100 flagged articles finds only five disclosures.
Significance. If the detector classifications are reliable, the work supplies large-scale empirical data on AI adoption patterns in American newspapers and documents low disclosure rates, which bears directly on editorial standards and public trust in journalism. The scale of the corpus and the explicit focus on uneven distribution plus disclosure provide concrete, falsifiable observations that can ground further research in computational social science.
major comments (2)
- [Methods] Methods section: the headline 9% prevalence (and all downstream claims about uneven distribution by outlet size, topic, and ownership) rests on Pangram outputs without any reported calibration, false-positive baseline, or human-labeled validation set on newspaper prose. No pre-2023 human-written control corpus or error-rate measurement on this domain is described, leaving open the possibility that formulaic journalistic style (short declaratives, topic-specific phrasing) produces systematic false positives.
- [Results] Results (disclosure audit): the claim that AI use is 'rarely disclosed' is based on a post-selection manual review of only 100 AI-flagged articles. This sample is small, lacks reported sampling details, inter-annotator agreement, or confidence intervals, and therefore provides only weak support for the low-disclosure conclusion.
minor comments (2)
- [Abstract] Abstract and §3: specify the exact date range for 'summer of 2025' and the precise threshold or probability cutoff used to label an article as 'partially or fully AI-generated' from Pangram's output.
- [Results] Figure captions and §4: clarify whether the 6.4x multiplier for opinion pieces is a raw ratio or adjusted for article length or other covariates.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have prompted us to clarify and strengthen key aspects of the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Methods] Methods section: the headline 9% prevalence (and all downstream claims about uneven distribution by outlet size, topic, and ownership) rests on Pangram outputs without any reported calibration, false-positive baseline, or human-labeled validation set on newspaper prose. No pre-2023 human-written control corpus or error-rate measurement on this domain is described, leaving open the possibility that formulaic journalistic style (short declaratives, topic-specific phrasing) produces systematic false positives.
Authors: We appreciate the referee's point on domain-specific validation. Pangram was chosen based on its strong reported performance in recent benchmarks, but we acknowledge that no explicit calibration or false-positive analysis on newspaper prose was included. In the revised manuscript, we have added a dedicated limitations subsection in Methods that discusses the risk of false positives from formulaic journalistic writing and reports results from a small post-hoc human validation on a sample of pre-2023 articles. While a comprehensive pre-2023 control corpus was outside the scope of this large-scale audit, the relative differences across outlets, topics, and ownership groups remain informative even under moderate error rates. revision: partial
-
Referee: [Results] Results (disclosure audit): the claim that AI use is 'rarely disclosed' is based on a post-selection manual review of only 100 AI-flagged articles. This sample is small, lacks reported sampling details, inter-annotator agreement, or confidence intervals, and therefore provides only weak support for the low-disclosure conclusion.
Authors: We agree that the disclosure audit rests on a modest sample and that additional methodological details would improve transparency. The revised manuscript now specifies that the 100 articles were randomly sampled from the AI-flagged set, describes the annotation protocol in more detail, and reports a binomial confidence interval around the observed 5% disclosure rate. We have also added an explicit statement that the review was performed by a single annotator and note this as a limitation. While these changes do not increase the sample size, they provide a more precise and cautious presentation of the finding. revision: yes
Circularity Check
No circularity: direct empirical counts on external corpus
full rationale
This is a pure measurement study that applies an external detector (Pangram) to a fixed corpus of 186K articles and reports observed proportions and correlations. No equations, fitted parameters, or derived predictions are defined in terms of the target statistics; the 9% figure and uneven distributions are direct outputs of the detector applied to the input data. No self-citation chain, uniqueness theorem, or ansatz is invoked to justify the central claim. The derivation is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pangram detector output corresponds to actual AI generation in newspaper articles
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using Pangram, a state-of-the-art AI detector, we discover that approximately 9% of newly-published articles are either partially or fully AI-generated.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
Evaluating Commercial AI Chatbots as News Intermediaries
Commercial AI chatbots reach over 90% multiple-choice accuracy on recent news facts but lose 11-17% in free response and drop to 19-70% on subtle false-premise questions, with retrieval failures causing most errors an...
-
The Impact of AI-Generated Text on the Internet
By mid-2025 roughly 35% of new websites are AI-generated or AI-assisted, correlating with lower semantic diversity and higher positive sentiment but showing no significant drop in factual accuracy or stylistic diversity.
-
Frankentext: Stitching random text fragments into long-form narratives
Frankentexts force LLMs to compose coherent long-form stories by copying 90% of tokens verbatim from random human snippets, yielding better quality and originality than vanilla generation while evading detectors.
-
Synthetic Sources?: Auditing Generative Search Engine Citations for Evidence of AI-Generated Sources
Audit of ChatGPT, Copilot, Gemini and Perplexity finds ~16% of cited sources are AI-generated across 712 queries on politics, health and environment.
-
Generative artificial intelligence reduces social welfare through model collapse
A game-theoretic model shows that individually rational adoption of generative AI causes model collapse that reduces collective social welfare for important tasks, with habit formation creating spillovers from low-sta...
Reference graph
Works this paper leans on
-
[1]
The rise of AI-generated content in Wikipedia. InProceedings of the First Workshop on Advancing Natural Language Processing for Wikipedia, pages 67–79, Miami, Florida, USA. Association for Com- putational Linguistics. Peter Brown and Klaudia Ja´ zwi´nska. 2025. Journalism zero: How platforms and publishers are navigating ai. Report, Tow Center for Digital...
work page 2025
-
[2]
Language Models are Few-Shot Learners
Language Models are Few-Shot Learners. arXiv preprint. ArXiv:2005.14165 [cs]. Roberto Cavazos and Greg Sterling. 2024. The high cost of review fraud: An economic analysis of con- sumer harm. https://askfortransparency.com/ research/high-cost-of-review-fraud/ . Ac- cessed: 2025-10-17. Elizabeth Clark, Tal August, Sofia Serrano, Nikita Haduong, Suchin Gurur...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[3]
All that‘s ‘human’ is not gold: Evaluating human evaluation of generated text. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7282–7296, Online. Association for Computational Linguistics. Jim Conaghan. 2017. ...
work page 2017
-
[4]
Liam Dugan, Andrew Zhu, Firoj Alam, Preslav Nakov, Marianna Apidianaki, and Chris Callison-Burch
The long-lasting effects of newspaper op-eds on public opinion.Quarterly Journal of Political Science, 13(1):59–87. Liam Dugan, Andrew Zhu, Firoj Alam, Preslav Nakov, Marianna Apidianaki, and Chris Callison-Burch
-
[5]
arXiv preprint arXiv:2402.14873 , year=
GenAI content detection task 3: Cross-domain machine generated text detection challenge. InPro- ceedings of the 1stWorkshop on GenAI Content De- tection (GenAIDetect), pages 377–388, Abu Dhabi, UAE. International Conference on Computational Linguistics. Bradley Emi. 2025. All about false positives in ai detectors. https://www.pangram.com/blog/ all-about-f...
-
[6]
arXiv preprint arXiv:2504.09865 , year=
Bias and fairness in large language models: A survey.Computational Linguistics, 50(3):1097– 1179. Isabel O. Gallegos, Chen Shani, Weiyan Shi, Federico Bianchi, Izzy Gainsburg, Dan Jurafsky, and Robb Willer. 2025. Labeling messages as ai-generated does not reduce their persuasive effects.arXiv preprint arXiv:2504.09865. 14 Tarun Gupta and Danish Pruthi. 20...
-
[7]
Published online 2025-03-24; Taylor & Francis
Ai-generated news content: The impact of AI writer identity and perceived AI human-likeness.In- ternational Journal of Human-Computer Interaction, pages 1–13. Published online 2025-03-24; Taylor & Francis. Weixin Liang, Zachary Izzo, Yaohui Zhang, Haley Lepp, Hancheng Cao, Xuandong Zhao, Lingjiao Chen, Hao- tian Ye, Sheng Liu, Zhi Huang, Daniel A. McFarla...
work page 2025
-
[8]
The widespread adoption of large language model-assisted writing across society.Preprint, arXiv:2502.09747. Weixin Liang, Yaohui Zhang, Zhengxuan Wu, Haley Lepp, Wenlong Ji, Xuandong Zhao, Hancheng Cao, Sheng Liu, Siyu He, Zhi Huang, Diyi Yang, Christo- pher Potts, Christopher D Manning, and James Y . Zou. 2024b. Mapping the increasing use of LLMs in scie...
-
[9]
People who frequently use ChatGPT for writ- ing tasks are accurate and robust detectors of AI- generated text. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 5342–5373, Vienna, Austria. Association for Computational Lin- guistics. Fabio Salvi, Manoel Horta Ribeiro, Riccardo Gallot...
work page 2025
-
[10]
arXiv preprint arXiv:2505.09662 , year=
Large language models are more persua- sive than incentivized human persuaders.Preprint, arXiv:2505.09662. Minkyu Shin, Jin Kim, and Jiwoong Shin. 2025. The adoption and efficacy of large language models: Ev- idence from consumer complaints in the financial industry.Preprint, arXiv:2311.16466. Felix M. Simon. 2024. Artificial intelligence in the news: How...
-
[11]
Zellers, R., Holtzman, A., Rashkin, H., Bisk, Y ., Farhadi, A., Roesner, F., and Choi, Y
Taxonomy of risks posed by language models. InProceedings of the 2022 ACM Conference on Fair- ness, Accountability, and Transparency, FAccT ’22, page 214–229, New York, NY , USA. Association for Computing Machinery. Eileen Yam and Brian Kennedy. 2025. From political speeches to songs, how would americans react if they 16 found out AI was involved? Pew Res...
-
[12]
Carefully read the article content and identify the main focus
-
[13]
Choose the most appropriate primary topic from the taxonomy above
-
[14]
Base your decision on the primary subject matter and content focus
-
[15]
Consider the description of each category when making your choice
-
[16]
If the article truly doesn't fit well into any of the listed categories, choose "Other"
-
[17]
Be specific and accurate - don't force a category if it's not a good fit
-
[18]
Arkansas Department of Agriculture to host NASDA Annual Meeting
Respond ONLY with the classification in this exact format: <classification> Primary Topic: [exact primary topic name] </classification> Figure 9: Prompt for classifying topic of articles Topic Definition (IPTC summary) arts, culture, entertainment and media All forms of arts, entertainment, cultural heritage and media conflict, war and peace Acts of socia...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.