Synthetic Sources?: Auditing Generative Search Engine Citations for Evidence of AI-Generated Sources
Pith reviewed 2026-05-25 03:07 UTC · model grok-4.3
The pith
Generative search engines cite AI-generated sources in about 16 percent of cases across politics, health, and environment queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
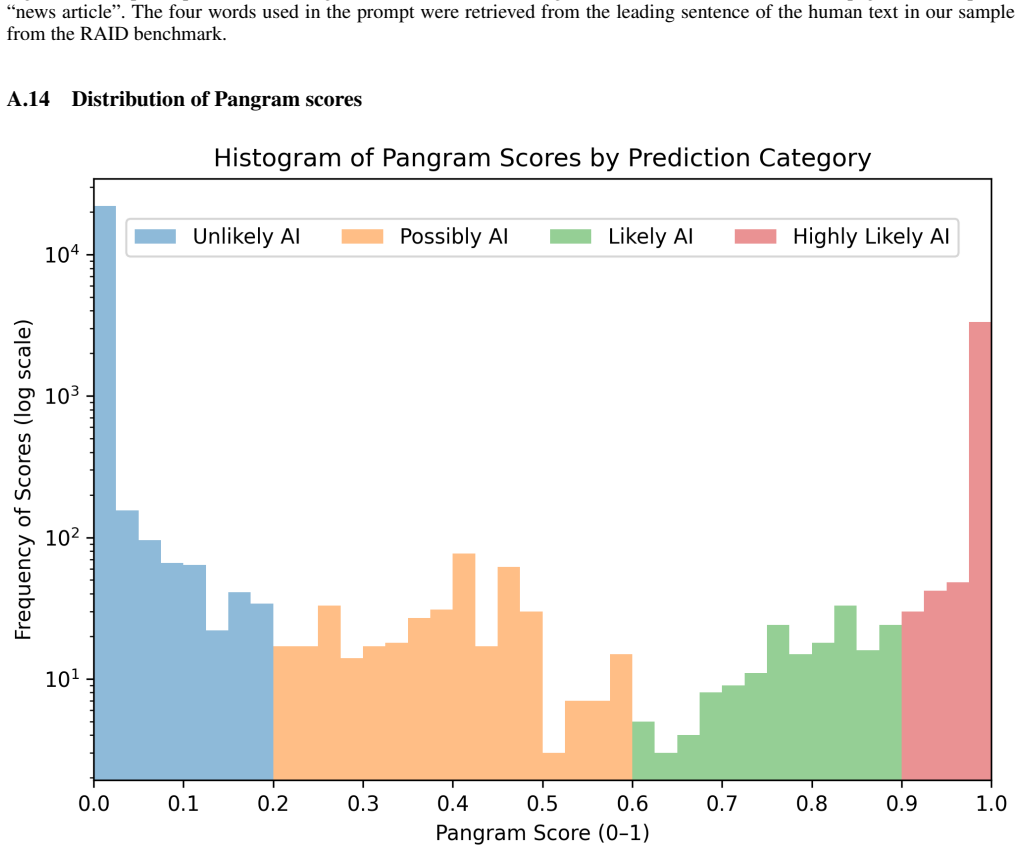
An audit of ChatGPT, Copilot, Gemini, and Perplexity on 712 queries spanning politics, health, and the environment found evidence that AI-generated sources appear among the citations in responses from all four engines, accounting for approximately 16 percent of cited sources overall. Certain web domains recur frequently across engines and topics as origins of these sources, while the engines otherwise draw from a long tail of minimally cited domains.
What carries the argument
Citation audit that classifies web sources returned in engine responses as AI-generated or not, applied to real-world queries in three high-stakes domains.
If this is right
- Users may receive information drawn from synthetic sources and treat it as equivalent to material from authoritative sources.
- Generative search engines surface a narrow set of repeatedly cited domains alongside a large number of minimally cited ones.
- Public awareness of these citation patterns can support better-informed use of the engines.
- The findings point toward the need for improved source filtering and governance measures in these systems.
Where Pith is reading between the lines
- If the 16 percent figure holds under stricter detection, it would indicate that AI content is already integrated into the citation layer of these tools at a scale that affects everyday queries.
- The concentration on a few recurring domains raises the possibility that certain sites function as high-volume producers of synthetic material that engines continue to surface.
- A follow-up audit could test whether the rate changes when queries are rephrased or when engines receive explicit instructions to avoid AI sources.
- The pattern suggests a feedback loop in which engines cite AI content that then becomes training or reference material for future generations of the same systems.
Load-bearing premise
The process used to label a cited source as AI-generated produces accurate and consistent results.
What would settle it
Independent re-examination of the same set of cited sources with a different detection method or human review that yields a percentage of AI-generated sources differing by more than five points from the reported 16 percent.
Figures




read the original abstract
The growing accessibility of Large Language Models via conversational interfaces capable of responding to users' questions by drawing on, synthesizing, and citing information from the web (i.e., Generative Search Engines) has simplified the information-seeking process for users. However, with the proliferation of AI-generated content on the web, it is unclear whether these engines can reliably omit citing synthetic sources (i.e., AI-generated sources). Should these engines be unable to do so, this puts users at risk of harm by treating information from AI-generated sources synthesized in responses of generative search engines as equivalent to information from authoritative or official sources. In a step towards identifying whether AI-generated sources are being cited by these engines, this work presents an audit of four generative search engines (ChatGPT, Copilot, Gemini, Perplexity) using a total of 712 real-world human-generated queries spanning domains of public importance: politics, health, and the environment. Our findings show evidence of AI-generated sources being cited across all four generative search engines (~16% of cited sources) and identifies key source web domains these sources belong to that are frequently cited across these engines and topics. In addition, we observed that generative search engines include a somewhat narrow set of repeatedly cited domains while predominantly surfacing a large number of minimally cited domains in responses to users' queries. These findings contribute to the growing body of work on assessing the risks of generative search engines with the objective of increasing public awareness of their limitations and encouraging appropriate measures to improve information quality and governance of these systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits four generative search engines (ChatGPT, Copilot, Gemini, Perplexity) with 712 real-world queries across politics, health, and environment. It reports evidence that ~16% of cited sources are AI-generated, identifies frequently cited source domains, and observes that engines rely on a narrow set of repeatedly cited domains alongside many minimally cited ones.
Significance. If the source classification is shown to be reliable, the audit would provide a concrete empirical measurement of a key risk in generative search systems, directly informing discussions on information quality, citation trustworthiness, and governance. The use of real user queries across high-stakes domains adds practical relevance to the cs.IR literature on search engine behavior.
major comments (1)
- [Methods (source classification procedure)] The central 16% figure and all domain-level patterns rest on the classification of sources as AI-generated, yet the manuscript provides no description of the detector (or criteria), threshold, validation set, error rates, or inter-annotator agreement. Without these, the measurement cannot be distinguished from detector bias or noise, directly undermining the headline claim.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We agree that methodological transparency is essential for the central claim and will revise the manuscript to provide the requested details on source classification.
read point-by-point responses
-
Referee: [Methods (source classification procedure)] The central 16% figure and all domain-level patterns rest on the classification of sources as AI-generated, yet the manuscript provides no description of the detector (or criteria), threshold, validation set, error rates, or inter-annotator agreement. Without these, the measurement cannot be distinguished from detector bias or noise, directly undermining the headline claim.
Authors: We acknowledge that the current manuscript does not include a description of the source classification procedure. In the revised version we will add a dedicated subsection detailing the detector (or criteria) used to identify AI-generated sources, any thresholds applied, the validation set and its construction, reported error rates, and inter-annotator agreement statistics. This addition will allow readers to evaluate the reliability of the ~16% figure and the domain-level patterns. revision: yes
Circularity Check
No circularity; purely empirical audit with direct source classification
full rationale
The paper conducts an empirical audit by issuing 712 queries to four generative search engines, collecting cited sources, and classifying a subset as AI-generated (~16%). No equations, derivations, parameters, or fitted models appear in the abstract or described methodology. The central claim rests on direct observation and labeling rather than any reduction to inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing steps. Classification accuracy is a separate methodological concern (unvalidated detector details) but does not constitute circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anticipating Impacts: Using Large-Scale Scenario Writing to Explore Diverse Implications of Generative
-
[2]
Kieslich, Kimon and Helberger, Natali and Diakopoulos, Nicholas , journal =. 2024 , title =. doi:10.1145/3630106.3659026 , pages =
-
[3]
Nishal, Sachita and Diakopoulos, Nicholas , journal =. 2024 , title =. doi:10.48550/arxiv.2402.18835 , eprint =
-
[4]
Zhang, Peixian and Ye, Qiming and Peng, Zifan and Garimella, Kiran and Tyson, Gareth , journal =. 2025 , title =. doi:10.48550/arxiv.2512.09483 , eprint =
-
[5]
Russell, Jenna and Karpinska, Marzena and Akinode, Destiny and Thai, Katherine and Emi, Bradley and Spero, Max and Iyyer, Mohit , journal =. 2025 , title =
work page 2025
-
[6]
arXiv preprint arXiv:2410.22349 , year=
Search engines in an ai era: The false promise of factual and verifiable source-cited responses , author=. arXiv preprint arXiv:2410.22349 , year=
-
[7]
Proceedings of the Association for Information Science and Technology , volume=
Generative ai search engines as arbiters of public knowledge: An audit of bias and authority , author=. Proceedings of the Association for Information Science and Technology , volume=. 2024 , publisher=
work page 2024
-
[8]
arXiv preprint arXiv:2507.05301 , year=
News source citing patterns in ai search systems , author=. arXiv preprint arXiv:2507.05301 , year=
-
[9]
The News with ChatGPT: An Audit and Survey Experiment on the Effects of GPT-Enabled News Search on User Attitudes , author=
-
[10]
They're All Bad at Citing News , author =
AI Search Has a Citation Problem: We Compared Eight AI Search Engines. They're All Bad at Citing News , author =. 2025 , howpublished =
work page 2025
-
[11]
arXiv preprint arXiv:2304.09848 , year=
Evaluating verifiability in generative search engines , author=. arXiv preprint arXiv:2304.09848 , year=
-
[12]
arXiv preprint arXiv:2508.00838 , year=
The Attribution Crisis in LLM Search Results , author=. arXiv preprint arXiv:2508.00838 , year=
-
[13]
Athena Chapekis and Anna Lieb , title =. 2025 , month = jul, day =
work page 2025
- [14]
-
[15]
Auditing algorithms: Understanding algorithmic systems from the outside in , author=. Foundations and Trends. 2021 , publisher=
work page 2021
-
[16]
Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
Generative echo chamber? effect of llm-powered search systems on diverse information seeking , author=. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems , pages=
work page 2024
-
[17]
arXiv preprint arXiv:2404.07981 , year=
Manipulating large language models to increase product visibility , author=. arXiv preprint arXiv:2404.07981 , year=
-
[18]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Media source matters more than content: Unveiling political bias in llm-generated citations , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[19]
Proceedings of the 2nd International Workshop on Diffusion of Harmful Content on Online Web , pages=
Global Claims: A Multilingual Dataset of Fact-Checked Claims with Veracity, Topic, and Salience Annotations , author=. Proceedings of the 2nd International Workshop on Diffusion of Harmful Content on Online Web , pages=
-
[20]
News Integrity in AI Assistants: An International PSM Study , author =. 2025 , month = oct, url =
work page 2025
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Cram: Credibility-aware attention modification in llms for combating misinformation in rag , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
- [22]
- [23]
-
[24]
arXiv preprint arXiv:2510.27489 , year=
Auditing LLM Editorial Bias in News Media Exposure , author=. arXiv preprint arXiv:2510.27489 , year=
-
[25]
Proceedings of the Association for Information Science and Technology , volume=
Bing chat: The future of search engines? , author=. Proceedings of the Association for Information Science and Technology , volume=. 2023 , publisher=
work page 2023
-
[26]
Telematics and Informatics , volume=
The silence of the LLMs: Cross-lingual analysis of guardrail-related political bias and false information prevalence in ChatGPT, Google Bard (Gemini), and Bing Chat , author=. Telematics and Informatics , volume=. 2025 , publisher=
work page 2025
-
[27]
Examining query sentiment bias effects on search results in large language models , author=. The Symposium on Future Directions in Information Access (FDIA) co-located with the 2023 European Summer School on Information Retrieval (ESSIR) , year=
work page 2023
-
[28]
AI chatbot accountability in the age of algorithmic gatekeeping: Comparing generative search engine political information retrieval across five languages , author=. new media & society , pages=. 2025 , publisher=
work page 2025
-
[29]
arXiv preprint arXiv:2502.04951 , year=
Unsafe LLM-Based Search: Quantitative Analysis and Mitigation of Safety Risks in AI Web Search , author=. arXiv preprint arXiv:2502.04951 , year=
-
[30]
Telecommunications Policy , pages=
Sourcing behavior and the role of news media in AI-powered search engines in the digital media ecosystem: Comparing political news retrieval across five languages , author=. Telecommunications Policy , pages=. 2025 , publisher=
work page 2025
-
[31]
Roy, Jean-Hugues , journal =. I used. 2025 , url =
work page 2025
-
[32]
ACM computing surveys , volume=
Survey of hallucination in natural language generation , author=. ACM computing surveys , volume=. 2023 , publisher=
work page 2023
-
[33]
The chat-chamber effect: Trusting the AI hallucination , author=. Big Data & Society , volume=. 2025 , publisher=
work page 2025
-
[34]
arXiv preprint arXiv:2402.11707 , year=
Search engines post-ChatGPT: How generative artificial intelligence could make search less reliable , author=. arXiv preprint arXiv:2402.11707 , year=
-
[35]
arXiv preprint arXiv:2404.07461 , year=
An Audit on the Perspectives and Challenges of Hallucinations in NLP , author=. arXiv preprint arXiv:2404.07461 , year=
-
[36]
Your Google News feed is likely filled with AI-generated articles , year =. Engadget , url =
-
[37]
Matthias Bastian , title =. The Decoder , url =. 2023 , month = dec, day =
work page 2023
-
[38]
arXiv preprint arXiv:2402.04607 , year=
Google Scholar is manipulatable , author=. arXiv preprint arXiv:2402.04607 , year=
-
[39]
Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
On the dangers of stochastic parrots: Can language models be too big? , author=. Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
work page 2021
-
[40]
AI use in American newspapers is widespread, uneven, and rarely disclosed
AI use in American newspapers is widespread, uneven, and rarely disclosed , author=. arXiv preprint arXiv:2510.18774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
arXiv preprint arXiv:2509.19163 , year=
Measuring AI" Slop" in Text , author=. arXiv preprint arXiv:2509.19163 , year=
-
[42]
arXiv preprint arXiv:2402.14873 , year=
Technical report on the pangram ai-generated text classifier , author=. arXiv preprint arXiv:2402.14873 , year=
-
[43]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
work page 2025
- [44]
-
[45]
arXiv preprint arXiv:2401.06730 , year=
Relying on the unreliable: The impact of language models' reluctance to express uncertainty , author=. arXiv preprint arXiv:2401.06730 , year=
-
[46]
Nudges to mitigate confirmation bias during web search on debated topics: Support vs. manipulation , author=. ACM Transactions on the Web , volume=. 2024 , publisher=
work page 2024
-
[47]
Search and politics: The uses and impacts of search in Britain, France, Germany, Italy, Poland, Spain, and the United States , author=. 2017 , publisher=
work page 2017
-
[48]
Proceedings of the 2018 conference on human information interaction & retrieval , pages=
Searching as learning: Exploring search behavior and learning outcomes in learning-related tasks , author=. Proceedings of the 2018 conference on human information interaction & retrieval , pages=
work page 2018
-
[49]
Contrasting search as a learning activity with instructor-designed learning , author=. Proceedings of the 27th ACM international conference on information and knowledge management , pages=
-
[50]
Communications of the ACM , volume=
Exploratory search: from finding to understanding , author=. Communications of the ACM , volume=. 2006 , publisher=
work page 2006
-
[51]
Annual review of public health , volume=
Public health and online misinformation: challenges and recommendations , author=. Annual review of public health , volume=. 2020 , publisher=
work page 2020
-
[52]
Google search histories of patients presenting to an emergency department: an observational study , author=. BMJ open , volume=. 2019 , publisher=
work page 2019
-
[53]
Journal of marketing research , volume=
What makes online content viral? , author=. Journal of marketing research , volume=. 2012 , publisher=
work page 2012
-
[54]
Proceedings of the 2022 Conference on Human Information Interaction and Retrieval , pages=
Featured snippets and their influence on users’ credibility judgements , author=. Proceedings of the 2022 Conference on Human Information Interaction and Retrieval , pages=
work page 2022
-
[55]
Human--Computer Interaction , volume=
SNIF-ACT: A cognitive model of user navigation on the World Wide Web , author=. Human--Computer Interaction , volume=. 2007 , publisher=
work page 2007
-
[56]
Journal of broadcasting & electronic media , volume=
Uses and grats 2.0: New gratifications for new media , author=. Journal of broadcasting & electronic media , volume=. 2013 , publisher=
work page 2013
-
[57]
Proceedings of the 22nd international conference on World Wide Web , pages=
Measuring personalization of web search , author=. Proceedings of the 22nd international conference on World Wide Web , pages=
-
[58]
International Journal of Knowledge Society Research (IJKSR) , volume=
In search we trust: exploring how search engines are shaping society , author=. International Journal of Knowledge Society Research (IJKSR) , volume=. 2014 , publisher=
work page 2014
-
[59]
Proceedings of the 2019 CHI Conference on human factors in computing systems , pages=
Search as news curator: The role of Google in shaping attention to news information , author=. Proceedings of the 2019 CHI Conference on human factors in computing systems , pages=
work page 2019
-
[60]
Online searches to evaluate misinformation can increase its perceived veracity , author=. Nature , volume=. 2024 , publisher=
work page 2024
-
[61]
arXiv preprint arXiv:2501.13802 , year=
Enhancing LLMs for Governance with Human Oversight: Evaluating and Aligning LLMs on Expert Classification of Climate Misinformation for Detecting False or Misleading Claims about Climate Change , author=. arXiv preprint arXiv:2501.13802 , year=
-
[62]
Harvard Kennedy School Misinformation Review , year=
LLMs grooming or data voids? LLM-powered chatbot references to Kremlin disinformation reflect information gaps, not manipulation , author=. Harvard Kennedy School Misinformation Review , year=
-
[63]
Data Voids and Echo Chambers: The Transformative Journey of Search and Its Consequences , author=. NASIG Proceedings , volume=
-
[64]
Zihlmann, Oliver and Euchner, Celina , title =. Tages-Anzeiger , year =
-
[65]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
Informing AI Risk Assessment with News Media: Analyzing National and Political Variation in the Coverage of AI Risks , author=. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume=
-
[66]
arXiv preprint arXiv:2306.05949 , year=
Evaluating the social impact of generative ai systems in systems and society , author=. arXiv preprint arXiv:2306.05949 , year=
-
[67]
Impact of misinformation from generative AI on user information processing: How people understand misinformation from generative AI , author=. New Media & Society , volume=. 2025 , publisher=
work page 2025
-
[68]
Invisible search and online search engines: The ubiquity of search in everyday life , author=. 2019 , publisher=
work page 2019
-
[69]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
BERTopic: Neural topic modeling with a class-based TF-IDF procedure , author=. arXiv preprint arXiv:2203.05794 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
2025 , month = feb, howpublished =
Arena Explorer: A Topic Modeling Pipeline for LLM Evals & Analytics , author =. 2025 , month = feb, howpublished =
work page 2025
-
[71]
The Information Society , volume=
Searching for politics: Using real-world web search behavior and surveys to see political information searching in context , author=. The Information Society , volume=. 2023 , publisher=
work page 2023
-
[72]
Online health information seeking behavior: a systematic review , author=. Healthcare , volume=. 2021 , organization=
work page 2021
-
[73]
arXiv preprint arXiv:2504.11373 , year=
Cancer-Myth: Evaluating AI Chatbot on Patient Questions with False Presuppositions , author=. arXiv preprint arXiv:2504.11373 , year=
-
[74]
arXiv preprint arXiv:2403.14709 , year=
ClimateQ&A: Bridging the gap between climate scientists and the general public , author=. arXiv preprint arXiv:2403.14709 , year=
-
[75]
ChatGPT as a news recommender system: Measuring source types and diversity across different interfaces , author=. 2025 , publisher=
work page 2025
-
[76]
Playwright: Fast and reliable end-to-end testing for modern web apps , year =
-
[77]
Newspaper3k: Article scraping & curation — Documentation , author =. 2018 , note =
work page 2018
- [78]
-
[79]
Colorado College Publication , series =
Gini, Corrado , title =. Colorado College Publication , series =
-
[80]
arXiv preprint arXiv:2506.05334 , year=
Search Arena: Analyzing Search-Augmented LLMs , author=. arXiv preprint arXiv:2506.05334 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.