C-NAV: Towards Self-Evolving Continual Object Navigation in Open World
Pith reviewed 2026-05-18 04:29 UTC · model grok-4.3
The pith
A dual-path anti-forgetting system lets navigation agents learn new objects in changing environments while retaining old skills and using far less memory than full-history methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
C-Nav integrates a dual-path anti-forgetting mechanism—feature distillation that aligns multi-modal inputs into a consistent representation space for representation consistency and feature replay that retains temporal features within the action decoder for policy consistency—together with an adaptive sampling strategy that selects diverse and informative experiences to reduce redundancy and memory overhead, yielding superior performance on the continual object navigation benchmark.
What carries the argument
Dual-path anti-forgetting mechanism of feature distillation for representation consistency and feature replay for policy consistency, combined with adaptive sampling for experience selection.
If this is right
- Agents maintain high success rates on old object categories while gaining competence on new ones without retraining from scratch.
- Memory footprint stays low because only selected experiences are retained rather than full trajectories.
- The same framework delivers gains across different underlying model architectures.
- Navigation systems can handle open-world evolution with less risk of performance collapse over time.
Where Pith is reading between the lines
- Similar dual-consistency paths could transfer to other embodied continual tasks such as manipulation or exploration.
- Real-robot deployments with streaming sensor data would provide a direct test of the sampling strategy under non-stationary conditions.
- Scaling the number of categories to dozens or hundreds would clarify where the consistency mechanisms begin to degrade.
Load-bearing premise
The dual-path mechanism of feature distillation and feature replay plus adaptive sampling will continue to block catastrophic forgetting when object categories and environmental shifts grow much larger than the tested benchmark scenarios.
What would settle it
An experiment that doubles or triples the number of object categories or introduces more frequent scene changes and then measures a sharp drop in success rate on previously learned navigation tasks.
Figures








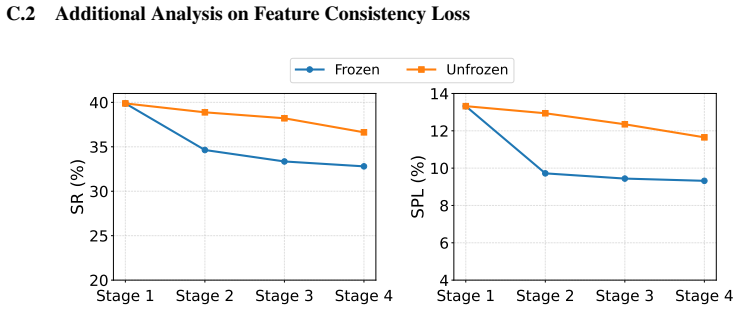


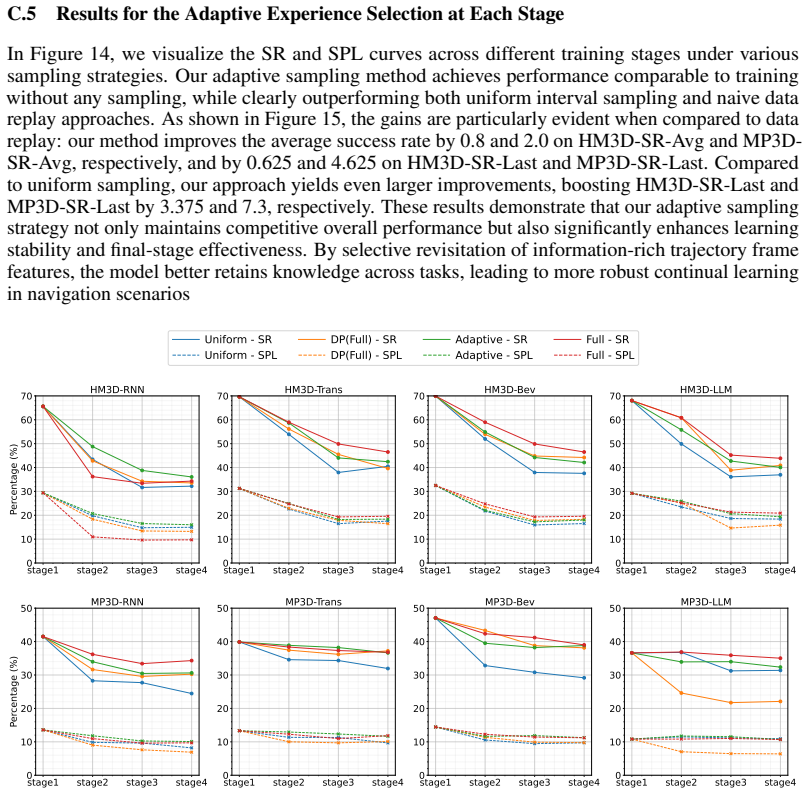
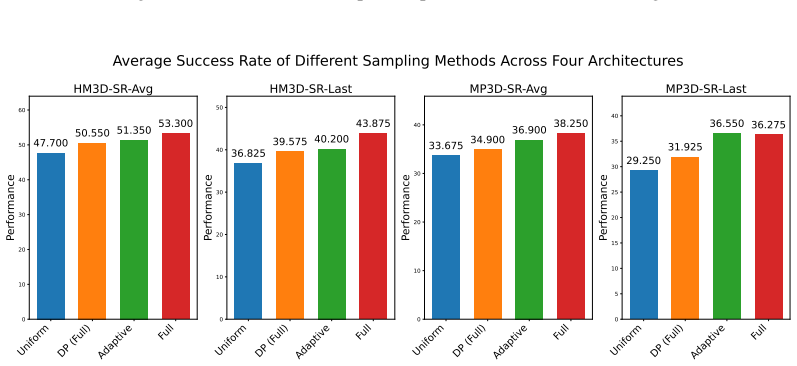
read the original abstract
Embodied agents are expected to perform object navigation in dynamic, open-world environments. However, existing approaches typically rely on static trajectories and a fixed set of object categories during training, overlooking the real-world requirement for continual adaptation to evolving scenarios. To facilitate related studies, we introduce the continual object navigation benchmark, which requires agents to acquire navigation skills for new object categories while avoiding catastrophic forgetting of previously learned knowledge. To tackle this challenge, we propose C-Nav, a continual visual navigation framework that integrates two key innovations: (1) A dual-path anti-forgetting mechanism, which comprises feature distillation that aligns multi-modal inputs into a consistent representation space to ensure representation consistency, and feature replay that retains temporal features within the action decoder to ensure policy consistency. (2) An adaptive sampling strategy that selects diverse and informative experiences, thereby reducing redundancy and minimizing memory overhead. Extensive experiments across multiple model architectures demonstrate that C-Nav consistently outperforms existing approaches, achieving superior performance even compared to baselines with full trajectory retention, while significantly lowering memory requirements. The code will be publicly available at https://bigtree765.github.io/C-Nav-project.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a continual object navigation benchmark requiring agents to learn navigation for new object categories in dynamic open-world settings without catastrophic forgetting. It proposes the C-Nav framework featuring a dual-path anti-forgetting mechanism (feature distillation for multi-modal representation consistency and feature replay for policy consistency in the action decoder) together with an adaptive sampling strategy that selects diverse experiences to reduce memory overhead. Experiments across model architectures claim consistent outperformance over prior methods, including baselines that retain full trajectories, while using substantially less memory.
Significance. If the central claims hold after addressing experimental controls, the work would be significant for continual learning in embodied robotics: it provides a new benchmark for open-world adaptation and demonstrates a memory-efficient approach that could scale navigation agents beyond static training regimes. The dual-path design and adaptive sampling directly target representation and policy consistency, which are load-bearing for long-term deployment in evolving environments.
major comments (2)
- [Abstract / Experimental Evaluation] Abstract and experimental evaluation: the claim of outperforming full-trajectory-retention baselines while using less memory is load-bearing for the central contribution. However, no ablation is reported that applies the identical adaptive sampling strategy to those full-retention baselines. Without this control, any observed performance edge cannot be unambiguously attributed to the dual-path anti-forgetting mechanism rather than improved data selection.
- [Method] Method section on adaptive sampling and dual-path components: the paper does not specify whether the adaptive sampling criteria (diversity and informativeness) or the distillation/replay weights were tuned on the same benchmark splits used for final evaluation. This raises a moderate risk of circularity that could inflate the reported gains relative to untuned baselines.
minor comments (2)
- [Figures and Tables] Figure captions and table headers should explicitly state the number of runs, random seeds, and statistical tests used to support the 'consistently outperforms' claim.
- [Benchmark Description] The continual object navigation benchmark definition would benefit from an explicit description of the train/test split protocol and the schedule of new object category introductions to facilitate future comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commit to revisions that strengthen the experimental controls and transparency of the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experimental Evaluation] Abstract and experimental evaluation: the claim of outperforming full-trajectory-retention baselines while using less memory is load-bearing for the central contribution. However, no ablation is reported that applies the identical adaptive sampling strategy to those full-retention baselines. Without this control, any observed performance edge cannot be unambiguously attributed to the dual-path anti-forgetting mechanism rather than improved data selection.
Authors: We agree this control is valuable for unambiguous attribution. The adaptive sampling strategy is a core part of C-Nav for memory reduction, but to isolate the dual-path anti-forgetting contribution, we will add a new ablation in the revised manuscript. This ablation will apply the identical adaptive sampling criteria to the full-trajectory-retention baselines and report the resulting performance and memory metrics. We expect this to confirm that the observed gains are not solely due to data selection. revision: yes
-
Referee: [Method] Method section on adaptive sampling and dual-path components: the paper does not specify whether the adaptive sampling criteria (diversity and informativeness) or the distillation/replay weights were tuned on the same benchmark splits used for final evaluation. This raises a moderate risk of circularity that could inflate the reported gains relative to untuned baselines.
Authors: We thank the referee for noting this potential issue. The adaptive sampling criteria and distillation/replay weights were tuned on a held-out validation split that is disjoint from the test splits used for final reporting. We will revise the Method section to explicitly describe the tuning protocol, including the validation split construction, the search ranges, and the selection criteria, thereby removing any ambiguity about circularity. revision: yes
Circularity Check
No circularity: empirical framework with independent experimental validation
full rationale
The paper proposes C-Nav as a practical continual navigation framework combining dual-path anti-forgetting (feature distillation and replay) with adaptive sampling, then validates it through experiments on a new benchmark. No mathematical derivation chain exists that reduces predictions or uniqueness claims to fitted parameters or self-citations by construction. The central performance claims rest on comparative results against baselines (including full-trajectory retention), which are externally falsifiable via the reported metrics and code release rather than being forced by internal definitions or prior author work. Adaptive sampling and distillation weights are implementation choices whose impact is measured, not smuggled in as predictions. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual-path anti-forgetting mechanism, which comprises feature distillation that aligns multi-modal inputs into a consistent representation space ... and feature replay that retains temporal features within the action decoder
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
adaptive experience selection module ... leverages the Local Outlier Factor (LOF) algorithm to automatically identify critical navigation moments
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
When Robots Do the Chores: A Benchmark and Agent for Long-Horizon Household Task Execution
LongAct benchmark reveals top VLMs reach only 59% goal completion and 16% full success on long-horizon household tasks, while HoloMind agent improves results via DAG planner, multimodal spatial memory, episodic memory...
Reference graph
Works this paper leans on
-
[1]
Object goal navigation using goal-oriented semantic exploration
Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Abhinav Gupta, et al. Object goal navigation using goal-oriented semantic exploration. InAdvances in Neural Information Processing Systems, volume 33 of NeurIPS, pages 4247–4258, 2020
work page 2020
-
[2]
Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Oleksandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, and Erik Wijmans. Objectnav revisited: On evaluation of embodied agents navigating to objects.arXiv preprint arXiv:2006.13171, 2020
-
[3]
V oronav: V oronoi-based zeroshot object navigation with large language model
Pengying Wu, Yao Mu, Bingxian Wu, Yi Hou, Ji Ma, Shanghang Zhang, and Chang Liu. V oronav: V oronoi-based zeroshot object navigation with large language model. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[4]
Vlfm: Vision- language frontier maps for zero-shot semantic navigation
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. Vlfm: Vision- language frontier maps for zero-shot semantic navigation. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 42–48. IEEE, 2024
work page 2024
-
[5]
Esc: Exploration with soft commonsense constraints for zero-shot object navigation
Kaiwen Zhou, Kaizhi Zheng, Connor Pryor, Yilin Shen, Hongxia Jin, Lise Getoor, and Xin Eric Wang. Esc: Exploration with soft commonsense constraints for zero-shot object navigation. InInternational Conference on Machine Learning, pages 42829–42842. PMLR, 2023
work page 2023
-
[6]
Karmesh Yadav, Arjun Majumdar, Ram Ramrakhya, et al. Ovrl-v2: A simple state-of-the-art baseline for imagenav and objectnav.arXiv preprint arXiv:2303.07798, 2023. Version 2
-
[7]
Pirlnav: Pretraining with imitation and rl finetuning for objectnav
Ram Ramrakhya, Dhruv Batra, Erik Wijmans, et al. Pirlnav: Pretraining with imitation and rl finetuning for objectnav. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17896–17906. IEEE/CVF, 2023
work page 2023
-
[8]
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation. arXiv preprint arXiv:2402.15852, 2024
work page internal anchor Pith review arXiv 2024
-
[9]
Object goal navigation with recursive implicit maps
Siyuan Chen, Thomas Chabal, Ivan Laptev, et al. Object goal navigation with recursive implicit maps. In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7089–7096. IEEE, 2023
work page 2023
-
[10]
Habitat-web: Learning embodied object-search strategies from human demonstrations at scale
Ram Ramrakhya, Erik Undersander, Dhruv Batra, et al. Habitat-web: Learning embodied object-search strategies from human demonstrations at scale. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5173–5183. IEEE/CVF, 2022
work page 2022
-
[11]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, volume 139, pages 8748–8763, feb 2021
work page 2021
-
[12]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, et al. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11975–11986. IEEE/CVF, 2023
work page 2023
- [13]
-
[14]
A comprehensive survey on continual learning in generative models
Haiyang Guo, Fanhu Zeng, Fei Zhu, Jiayi Wang, Xukai Wang, Jingang Zhou, Hongbo Zhao, Wenzhuo Liu, Shijie Ma, Xu-Yao Zhang, et al. A comprehensive survey on continual learning in generative models. arXiv preprint arXiv:2506.13045, 2025
-
[15]
Open-world machine learning: A review and new outlooks.arXiv e-prints, pages arXiv–2403, 2024
Fei Zhu, Shijie Ma, Zhen Cheng, Xu-Yao Zhang, Zhaoxiang Zhang, and Cheng-Lin Liu. Open-world machine learning: A review and new outlooks.arXiv e-prints, pages arXiv–2403, 2024
work page 2024
-
[16]
Bagdanov, and Joost Van De Weijer
Marc Masana, Xialei Liu, Bartłomiej Twardowski, Mikel Menta, Andrew D. Bagdanov, and Joost Van De Weijer. Class-incremental learning: Survey and performance evaluation on image classification. volume 45, pages 5513–5533. IEEE, 2022. 11
work page 2022
-
[17]
Dkt: Diverse knowledge transfer transformer for class incremental learning
Xiangyu Gao, Yang He, Shanshan Dong, Yujia Chen, Lei Wang, Wei Zhang, Hao Li, and Mingyuan Zhou. Dkt: Diverse knowledge transfer transformer for class incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24236–24245. IEEE/CVF, 2023
work page 2023
-
[18]
Kiana Ehsani, Tanmay Gupta, Ryan Hendrix, et al. Spoc: Imitating shortest paths in simulation enables effective navigation and manipulation in the real world.arXiv preprint arXiv:2312.02976, 2023
-
[19]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. iCaRL: incre- mental classifier and representation learning. InCVPR, 2017
work page 2017
-
[20]
Ramakrishnan, Dhruv Batra, Yonatan Bisk, and Roozbeh Mottaghi
Karmesh Yadav, Ram Ramrakhya, Santhosh K. Ramakrishnan, Dhruv Batra, Yonatan Bisk, and Roozbeh Mottaghi. Habitat-matterport 3d semantics dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4927–4936. IEEE/CVF, 2023
work page 2023
-
[21]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Angel Chang, Angela Dai, Thomas Funkhouser, and et al. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158, September 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9339–9347, 2019
work page 2019
-
[23]
Simple but effective: Clip embeddings for embodied ai
Apoorv Khandelwal, Luca Weihs, Roozbeh Mottaghi, and Aniruddha Kembhavi. Simple but effective: Clip embeddings for embodied ai. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14829–14838, 2022
work page 2022
-
[24]
Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al
Edward J. Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. LoRA: Low-rank adaptation of large language models. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[25]
Magmax: Leveraging model merging for seamless continual learning
Daniel Marczak, Bartłomiej Twardowski, Tomasz Trzci´nski, and Sebastian Cygert. Magmax: Leveraging model merging for seamless continual learning. InEuropean Conference on Computer Vision, pages 379–395. Springer, 2024
work page 2024
-
[26]
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, 2017
work page 2017
-
[27]
Lof: identifying density-based local outliers
Markus M Breunig, Hans-Peter Kriegel, Raymond T Ng, and Jörg Sander. Lof: identifying density-based local outliers. InProceedings of the 2000 ACM SIGMOD international conference on Management of data, pages 93–104, 2000
work page 2000
-
[28]
Openfm- nav: Towards open-set zero-shot object navigation via vision-language foundation models
Yuxuan Kuang, Hai Lin, and Meng Jiang. Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models.arXiv preprint arXiv:2402.10670, 2024
-
[29]
S. Y . Gadre, M. Wortsman, G. Ilharco, L. Schmidt, and S. Song. Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation. InProceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, volume 2023-June, pages 23171–23181, mar 2023
work page 2023
-
[30]
Unigoal: Towards universal zero-shot goal-oriented navigation.arXiv preprint arXiv:2503.10630, 2025
Hang Yin, Xiuwei Xu, Lingqing Zhao, Ziwei Wang, Jie Zhou, and Jiwen Lu. Unigoal: Towards universal zero-shot goal-oriented navigation.arXiv preprint arXiv:2503.10630, 2025
-
[31]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning.Advances in Neural Information Processing Systems, 36:1–19, 2023
work page 2023
-
[32]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
L3mvn: Leveraging large language models for visual target navigation
Bangguo Yu, Hamidreza Kasaei, and Ming Cao. L3mvn: Leveraging large language models for visual target navigation. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3554–3560. IEEE, 2023
work page 2023
-
[37]
An Embodied Generalist Agent in 3D World
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song- Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world.arXiv preprint arXiv:2311.12871, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Hierarchical consensus-based multi-agent reinforcement learning for multi-robot cooperation tasks
Pu Feng, Junkang Liang, Size Wang, Xin Yu, Xin Ji, Yiting Chen, Kui Zhang, Rongye Shi, and Wenjun Wu. Hierarchical consensus-based multi-agent reinforcement learning for multi-robot cooperation tasks. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 642–649. IEEE, 2024
work page 2024
-
[39]
Fast-slow test-time adaptation for online vision-and-language navigation
Junyu Gao, Xuan Yao, and Changsheng Xu. Fast-slow test-time adaptation for online vision-and-language navigation. 2024
work page 2024
-
[40]
Navmorph: A self-evolving world model for vision-and- language navigation in continuous environments
Junyu Gao Xuan Yao and Changsheng Xu. Navmorph: A self-evolving world model for vision-and- language navigation in continuous environments. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
work page 2025
-
[41]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017
work page 2017
-
[42]
Wenzhuo Liu, Xin-Jian Wu, Fei Zhu, Ming-Ming Yu, Chuang Wang, and Cheng-Lin Liu. Class incremental learning with self-supervised pre-training and prototype learning.Pattern Recognition, 157:110943, 2025
work page 2025
-
[43]
End-to-end incremental learning
Francisco M Castro, Manuel J Marín-Jiménez, Nicolás Guil, Cordelia Schmid, and Karteek Alahari. End-to-end incremental learning. InProceedings of the European conference on computer vision (ECCV), pages 233–248, 2018
work page 2018
-
[44]
Learning a unified classifier incrementally via rebalancing
Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and Dahua Lin. Learning a unified classifier incrementally via rebalancing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 831–839. IEEE/CVF, 2019
work page 2019
-
[45]
Prototype augmentation and self- supervision for incremental learning
Fei Zhu, Xu-Yao Zhang, Chuang Wang, Fei Yin, and Cheng-Lin Liu. Prototype augmentation and self- supervision for incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5871–5880, 2021
work page 2021
-
[46]
Der: Dynamically expandable representation for class incremental learning
Shipeng Yan, Jiangwei Xie, and Xuming He. Der: Dynamically expandable representation for class incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3014–3023. IEEE/CVF, 2021
work page 2021
-
[47]
Llava-c: Continual improved visual instruction tuning.arXiv preprint arXiv:2506.08666, 2025
Wenzhuo Liu, Fei Zhu, Haiyang Guo, Longhui Wei, and Cheng-Lin Liu. Llava-c: Continual improved visual instruction tuning.arXiv preprint arXiv:2506.08666, 2025
-
[48]
Hongbo Zhao, Fei Zhu, Rundong Wang, Gaofeng Meng, and Zhaoxiang Zhang. Mllm-cl: Continual learning for multimodal large language models.arXiv preprint arXiv:2506.05453, 2025
-
[49]
Haiyang Guo, Fanhu Zeng, Ziwei Xiang, Fei Zhu, Da-Han Wang, Xu-Yao Zhang, and Cheng-Lin Liu. Hide-llava: Hierarchical decoupling for continual instruction tuning of multimodal large language model. arXiv preprint arXiv:2503.12941, 2025
-
[50]
Fanhu Zeng, Fei Zhu, Haiyang Guo, Xu-Yao Zhang, and Cheng-Lin Liu. Modalprompt: Towards efficient multimodal continual instruction tuning with dual-modality guided prompt.arXiv preprint arXiv:2410.05849, 2024
-
[51]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
work page 2022
-
[52]
Pilora: Prototype guided incremental lora for federated class-incremental learning
Haiyang Guo, Fei Zhu, Wenzhuo Liu, Xu-Yao Zhang, and Cheng-Lin Liu. Pilora: Prototype guided incremental lora for federated class-incremental learning. InEuropean Conference on Computer Vision, pages 141–159. Springer, 2024
work page 2024
-
[53]
The Power of Scale for Parameter-Efficient Prompt Tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, April 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[54]
R. Ramrakhya, E. Undersander, D. Batra, and A. Das. Habitat-web: Learning embodied object-search strategies from human demonstrations at scale. InProceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2022
work page 2022
-
[55]
Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, and Dhruv Batra. Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames.arXiv preprint arXiv:1911.00357, 2019
-
[56]
Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
work page 1997
-
[57]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 13 A Dataset Details A.1 Category Splits for Continual ObjectNav HM3D Dataset.The object categories are split into four stages as follows: •Stage...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.