Energy Scaling Laws for Diffusion Models: Quantifying Compute in Image Generation
Pith reviewed 2026-05-17 21:03 UTC · model grok-4.3
The pith
An adapted Kaplan scaling law predicts GPU energy use for diffusion models from FLOPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
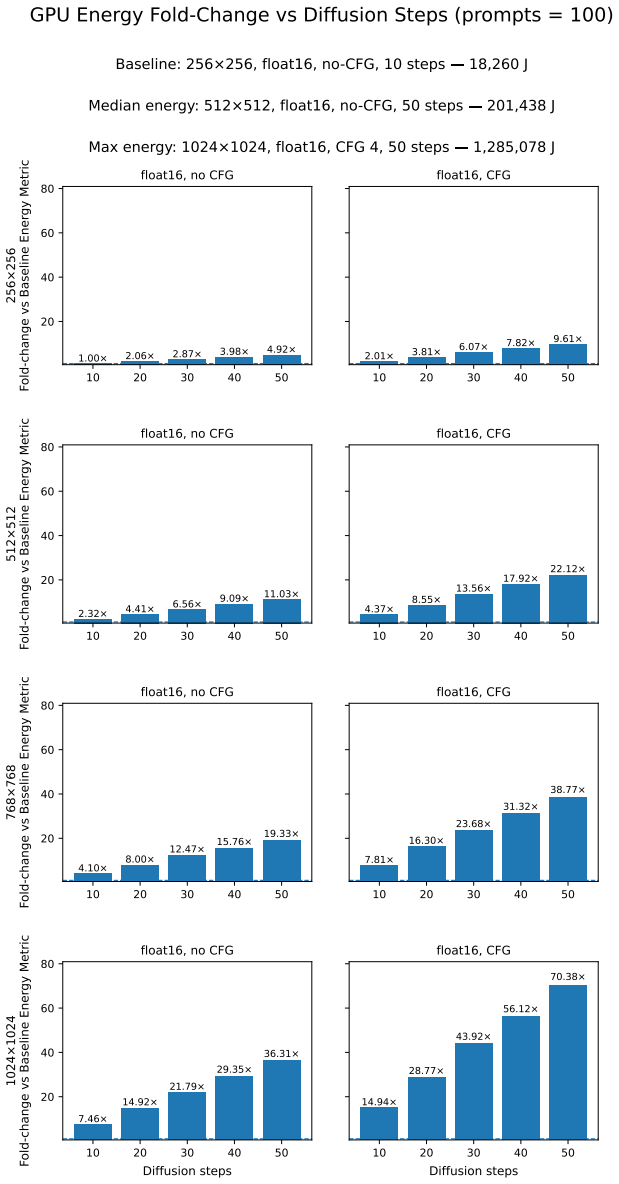
The central claim is that GPU energy consumption for diffusion model inference can be predicted from FLOPs using an adaptation of Kaplan scaling laws. The hypothesis that denoising operations dominate because they repeat across multiple steps is supported by measurements showing high predictive accuracy within architectures and strong rank correlations that allow reliable estimates for unseen model-hardware pairs.
What carries the argument
The adapted energy scaling law that relates total GPU energy to FLOPs after isolating the repeated denoising component as the main driver.
If this is right
- Energy needs for new resolutions, precisions, or step counts can be estimated without running the model.
- Rankings of energy efficiency remain consistent when moving models between different GPU types.
- The relation supplies a basis for calculating carbon footprints of image generation workloads.
- Diffusion inference behaves as a compute-bound process whose energy follows the same pattern across tested settings.
Where Pith is reading between the lines
- The law could be used to simulate energy costs when increasing resolution or step counts in next-generation models.
- Similar scaling approaches might apply to other iterative generation tasks such as video or audio synthesis.
- Designers could tune step count or precision to lower energy while keeping acceptable image quality.
- Quick energy estimates from the law would support regulatory reviews of large-scale AI environmental impact.
Load-bearing premise
Denoising operations dominate energy consumption due to their repeated execution across multiple inference steps.
What would settle it
Measure actual energy draw for a diffusion model on a previously untested GPU and configuration; a large mismatch with the value predicted from FLOPs would disprove the scaling law.
Figures











read the original abstract
The rapidly growing computational demands of diffusion models for image generation have raised significant concerns about energy consumption and environmental impact. While existing approaches to energy optimization focus on architectural improvements or hardware acceleration, there is a lack of principled methods to predict energy consumption across different model configurations and hardware setups. We propose an adaptation of Kaplan scaling laws to predict GPU energy consumption for diffusion models based on computational complexity (FLOPs). Our approach decomposes diffusion model inference into text encoding, iterative denoising, and decoding components, with the hypothesis that denoising operations dominate energy consumption due to their repeated execution across multiple inference steps. We conduct comprehensive experiments across four state-of-the-art diffusion models (Stable Diffusion 2, Stable Diffusion 3.5, Flux, and Qwen) on three GPU architectures (NVIDIA A100, A4000, A6000), spanning various inference configurations including resolution ($256^2$--$1024^2$), precision (fp16/fp32), step counts (10--50), and classifier-free guidance settings. Our energy scaling law achieves high predictive accuracy within individual architectures ($R^2 > 0.9$) and exhibits strong cross-architecture generalization, maintaining high rank correlations across models and enabling reliable energy estimation for unseen model--hardware combinations. These results validate the compute-bound nature of diffusion inference and establish energy consumption estimation as a necessary foundation for sustainable AI deployment planning and subsequent carbon footprint assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript adapts Kaplan-style scaling laws to predict GPU energy consumption for diffusion-based image generation from FLOPs. It decomposes inference into text encoding, iterative denoising, and decoding, with the hypothesis that denoising dominates due to repeated steps. Experiments cover four models (Stable Diffusion 2, Stable Diffusion 3.5, Flux, Qwen) and three GPUs (A100, A4000, A6000) across resolutions 256²–1024², fp16/fp32, 10–50 steps, and classifier-free guidance. Key claims are within-architecture R² > 0.9 and strong cross-architecture rank correlations enabling energy estimates for unseen model–hardware pairs.
Significance. If the central claims hold, the work supplies a practical tool for forecasting energy use and carbon impact in generative diffusion pipelines, supporting sustainable deployment planning. The breadth of the experimental design—four distinct models, three GPU architectures, and systematic variation of resolution, precision, steps, and guidance—is a clear strength that grounds the reported within- and cross-architecture results.
major comments (2)
- [Abstract and §3] Abstract and §3: The hypothesis that 'denoising operations dominate energy consumption due to their repeated execution across multiple inference steps' is load-bearing for both the within-architecture R² fits and the cross-architecture rank correlations, yet no component-wise energy measurements (e.g., isolating text-encoder, denoiser, and decoder power draw) are reported. Without such validation, especially for large-encoder models like Flux or low step counts, the effective compute-to-energy mapping may be model- and configuration-dependent rather than universal.
- [§5 (Results)] §5 (Results): The reported R² > 0.9 values are presented without error bars, explicit description of the fitting procedure (ordinary least squares? weighted?), or criteria for data-point inclusion/exclusion. These details are required to evaluate whether the high correlations are robust or sensitive to post-hoc choices, directly affecting confidence in the scaling-law claims.
minor comments (2)
- [Notation] The notation for the fitted energy scaling coefficients should be introduced with an explicit equation in the main text (rather than only in the appendix) to improve readability.
- [Figures] Figure captions for the energy-versus-FLOPs scatter plots should state the number of data points per series and whether any points were excluded.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments, which help clarify important aspects of our work. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] The hypothesis that 'denoising operations dominate energy consumption due to their repeated execution across multiple inference steps' is load-bearing for both the within-architecture R² fits and the cross-architecture rank correlations, yet no component-wise energy measurements (e.g., isolating text-encoder, denoiser, and decoder power draw) are reported. Without such validation, especially for large-encoder models like Flux or low step counts, the effective compute-to-energy mapping may be model- and configuration-dependent rather than universal.
Authors: We appreciate this observation. Our experiments vary the number of denoising steps (10–50) while keeping text encoding and decoding fixed for each configuration. The observed strong linear scaling of total energy with step count (reflected in R² > 0.9) provides indirect support for denoising dominance, as a constant contribution from the other components would not produce the proportional increase we measure. For Flux and similar models, the single-pass text encoding remains a fixed overhead that becomes relatively smaller at higher step counts, consistent with our cross-architecture rank correlations. We will revise §3 to explicitly articulate this reasoning, acknowledge the absence of isolated component measurements as a limitation (particularly at low step counts), and note that future work could include direct power profiling. This strengthens the manuscript without requiring new experiments. revision: partial
-
Referee: [§5 (Results)] The reported R² > 0.9 values are presented without error bars, explicit description of the fitting procedure (ordinary least squares? weighted?), or criteria for data-point inclusion/exclusion. These details are required to evaluate whether the high correlations are robust or sensitive to post-hoc choices, directly affecting confidence in the scaling-law claims.
Authors: We agree that these details are necessary for full transparency and reproducibility. The reported fits used ordinary least squares regression on log-log transformed data, following the standard Kaplan-style procedure, with all measured configurations included and no post-hoc exclusions. In the revised §5 we will (i) explicitly state the fitting method, (ii) report the number of data points per model–hardware pair, (iii) include error bars or standard errors on the regression coefficients and R² values, and (iv) add supplementary fit diagnostics such as residual plots or p-values. These additions will allow readers to assess robustness directly. revision: yes
Circularity Check
No significant circularity in energy scaling law derivation
full rationale
The paper adapts Kaplan scaling laws empirically by measuring energy and FLOPs across multiple diffusion models (SD2, SD3.5, Flux, Qwen), GPUs (A100/A4000/A6000), resolutions, precisions, step counts, and CFG settings, then fits a relation and reports R² > 0.9 within architectures plus rank correlations for cross-architecture generalization to unseen model-hardware pairs. This is standard data-driven fitting with explicit out-of-sample checks rather than a closed derivation that reduces to its own inputs by construction. The denoising-dominance hypothesis is stated as an assumption and used to motivate the FLOPs-based predictor, but the validation rests on direct total-energy measurements, not on any self-referential loop or self-citation chain. No load-bearing step equates a claimed prediction to a fitted parameter by definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- energy scaling coefficients
axioms (1)
- domain assumption Energy consumption of diffusion inference is dominated by the iterative denoising steps and scales as a power law with total FLOPs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an adaptation of Kaplan scaling laws to predict GPU energy consumption for diffusion models based on computational complexity (FLOPs). ... log(E) = log(A) + α log(FLOPs×2^I_cfg) + β_dtype I_dtype + ...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FLOPstotal = FLOPs_text + N_steps × FLOPs_denoise + FLOPs_decode
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sam Altman. The Gentle Singularity. https://blog.samaltman.com/ the-gentle-singularity. [Accessed 18-10-2025]
work page 2025
-
[2]
arXiv preprint arXiv:2007.03051 doi:10.48550/arXiv.2007.03051
Lasse F Wolff Anthony, Benjamin Kanding, and Raghavendra Selvan. Carbontracker: Track- ing and predicting the carbon footprint of training deep learning models.arXiv preprint arXiv:2007.03051, 2020
-
[3]
de Araújo, JPW, and MinervaBooks
Benoit Courty, Victor Schmidt, Sasha Luccioni, Goyal-Kamal, MarionCoutarel, Boris Feld, Jérémy Lecourt, LiamConnell, Amine Saboni, Inimaz, supatomic, Mathilde Léval, Luis Blanche, Alexis Cruveiller, ouminasara, Franklin Zhao, Aditya Joshi, Alexis Bogroff, Hugues de La- voreille, Niko Laskaris, Edoardo Abati, Douglas Blank, Ziyao Wang, Armin Catovic, Marc ...
work page 2024
-
[4]
Cooper Elsworth, Keguo Huang, David Patterson, Ian Schneider, Robert Sedivy, Savannah Goodman, Ben Townsend, Parthasarathy Ranganathan, Jeff Dean, Amin Vahdat, et al. Measuring the environmental impact of delivering AI at Google Scale.arXiv preprint arXiv:2508.15734, 2025
-
[5]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transform- ers for high-resolution image synthesis.arXiv preprint arXiv:2403.03206, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Scaling rectified flow transformers for high-resolution image synthesis, 2024
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024
work page 2024
-
[7]
Introducing gemini 2.5 flash image, our state-of-the-art image model
Alisa Fortin, Guillaume Vernade, Kat Kampf, and Ammaar Reshi. Introducing gemini 2.5 flash image, our state-of-the-art image model. Google Developers Blog, August 2025
work page 2025
-
[8]
Towards the systematic reporting of the energy and carbon footprints of machine learning
Peter Henderson, Jieru Hu, Joshua Romoff, Emma Brunskill, Dan Jurafsky, and Joelle Pineau. Towards the systematic reporting of the energy and carbon footprints of machine learning. Journal of Machine Learning Research, 21(248):1–43, 2020
work page 2020
-
[9]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
work page 2020
-
[10]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack W. Rae, and Laurent Sifre...
work page 2022
-
[12]
Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking
Zhe Jia, Marco Maggioni, Benjamin Staiger, and Daniele Paolo Scarpazza. Dissecting the NVIDIA volta GPU architecture via microbenchmarking.arXiv preprint arXiv:1804.06826, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[14]
Lawrence Zitnick, and Piotr Dollár
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015. 10
work page 2015
-
[15]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in Neural Information Processing Systems, 35:5775–5787, 2022
work page 2022
-
[16]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Re- search, pages 1–22, 2025
work page 2025
-
[17]
Alexandra Sasha Luccioni, Sylvain Viguier, and Anne-Laure Ligozat. Estimating the carbon footprint of bloom, a 176b parameter language model.arXiv preprint arXiv:2211.02001, 2022
-
[18]
Alexandra Sasha Luccioni, Sylvain Viguier, and Anne-Laure Ligozat. Power hungry processing: Watts driving the cost of AI deployment?F AccT ’23: Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pages 85–99, 2023
work page 2023
-
[19]
NVIDIA tensor core programmability, performance & precision
Stefano Markidis, Steven Wei Der Chien, Erwin Laure, Ivy Bo Peng, and Jeffrey S Vetter. NVIDIA tensor core programmability, performance & precision. In2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 522–531. IEEE, 2018
work page 2018
-
[20]
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14297–14306, 2023
work page 2023
-
[21]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al. Mixed precision training.arXiv preprint arXiv:1710.03740, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021
work page 2021
-
[23]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2023
work page 2023
-
[24]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational conference on machine learning, pages 8821–8831. Pmlr, 2021
work page 2021
-
[25]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022
work page 2022
-
[26]
U-net: Convolutional networks for biomedical image segmentation, 2015
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation, 2015
work page 2015
-
[27]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. PMLR, 2015
work page 2015
-
[29]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[30]
Yang et al. Song. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[31]
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in NLP.Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3645–3650, 2019. 11
work page 2019
-
[32]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023
work page 2023
-
[33]
gddim: Generalized denoising diffusion implicit models
Qinsheng Zhang, Molei Tao, and Yongxin Chen. gddim: Generalized denoising diffusion implicit models.arXiv preprint arXiv:2206.05564, 2022. 12 A Additional Validation Results A.1 Individual U-Net Architecture Validation Figure 4 provides detailed individual model validation for Stable Diffusion 2’s U-Net architecture across different GPU platforms. Despite...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.