Seeing What Matters: Visual Preference Policy Optimization for Visual Generation
Pith reviewed 2026-05-21 18:38 UTC · model grok-4.3
The pith
ViPO turns single scalar rewards into pixel-level advantage maps to guide visual generation toward perceptually important regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ViPO is a GRPO variant that employs a Perceptual Structuring Module to lift scalar feedback into structured, pixel-level advantages by constructing spatially and temporally aware advantage maps with pretrained vision backbones, redistributing optimization pressure toward perceptually important regions while preserving GRPO stability and yielding better in-domain alignment plus out-of-domain generalization on image and video benchmarks.
What carries the argument
The Perceptual Structuring Module, which uses pretrained vision backbones to build spatially and temporally aware advantage maps that redistribute optimization signals to perceptually important regions.
If this is right
- ViPO improves alignment with human-preference rewards on in-domain image and video benchmarks.
- The method enhances generalization on out-of-domain evaluations compared to standard GRPO.
- ViPO remains architecture-agnostic and fully compatible with existing GRPO training pipelines.
- The approach provides a more expressive learning signal for correcting localized artifacts in visual outputs.
Where Pith is reading between the lines
- The same map-based redistribution idea could be tested in other structured generation tasks such as audio waveforms or 3D scenes where local quality matters.
- Replacing the pretrained backbones with task-specific fine-tuned ones might further reduce any domain mismatch in the advantage maps.
- If the maps prove robust, training pipelines could incorporate them into reward models that operate directly on partial generations rather than final outputs.
Load-bearing premise
The Perceptual Structuring Module that uses pretrained vision backbones can reliably construct spatially and temporally aware advantage maps that correctly identify and prioritize perceptually important regions without introducing biases.
What would settle it
Running the same training setup but replacing the constructed advantage maps with uniform random values and observing no performance gain over vanilla GRPO would show the maps are not delivering the claimed benefit.
Figures








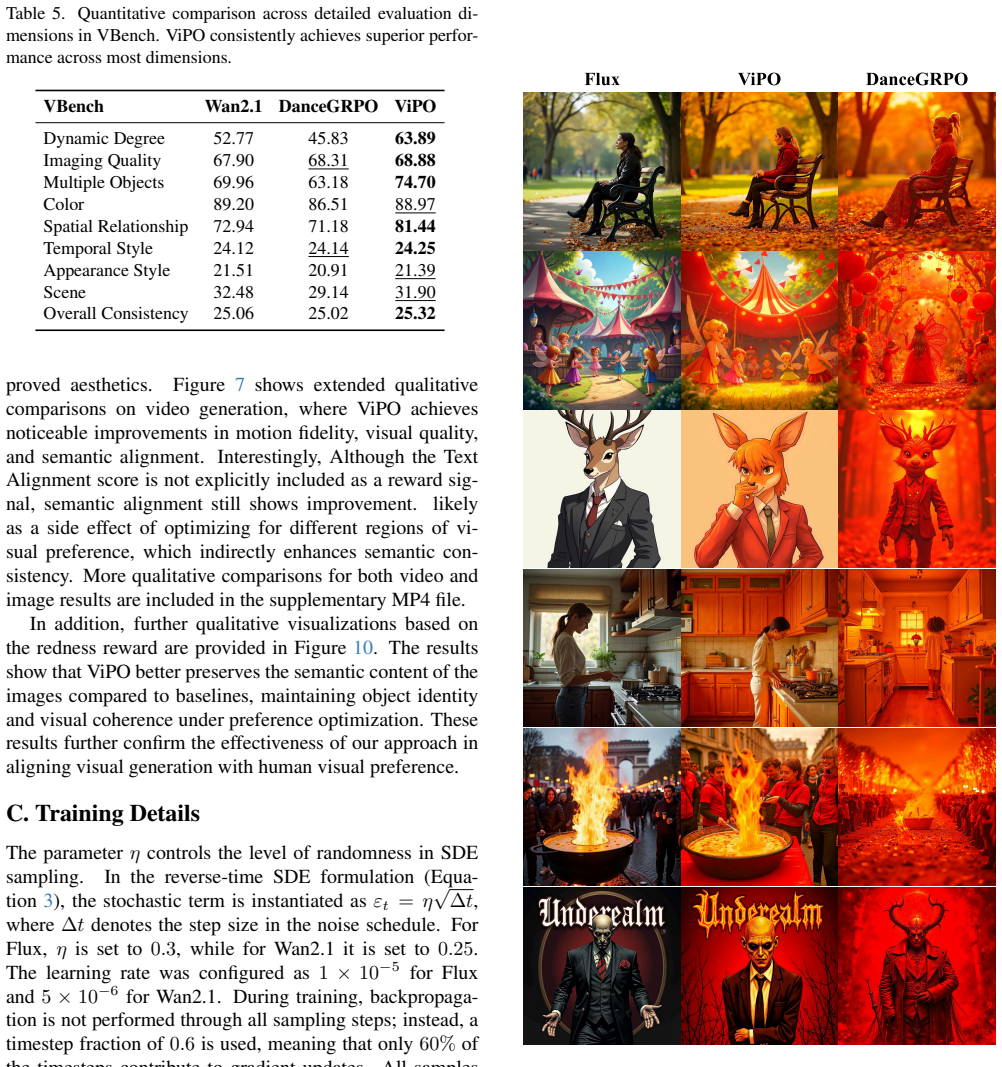
read the original abstract
Reinforcement learning (RL) has become a powerful tool for post-training visual generative models, with Group Relative Policy Optimization (GRPO) increasingly used to align generators with human preferences. However, existing GRPO pipelines rely on a single scalar reward per sample, treating each image or video as a holistic entity and ignoring the rich spatial and temporal structure of visual content. This coarse supervision hinders the correction of localized artifacts and the modeling of fine-grained perceptual cues. We introduce Visual Preference Policy Optimization (ViPO), a GRPO variant that lifts scalar feedback into structured, pixel-level advantages. ViPO employs a Perceptual Structuring Module that uses pretrained vision backbones to construct spatially and temporally aware advantage maps, redistributing optimization pressure toward perceptually important regions while preserving the stability of standard GRPO. Across both image and video benchmarks, ViPO consistently outperforms vanilla GRPO, improving in-domain alignment with human-preference rewards and enhancing generalization on out-of-domain evaluations. The method is architecture-agnostic, lightweight, and fully compatible with existing GRPO training pipelines, providing a more expressive and informative learning signal for visual generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Visual Preference Policy Optimization (ViPO), a variant of Group Relative Policy Optimization (GRPO) for post-training visual generative models. It introduces a Perceptual Structuring Module that employs pretrained vision backbones to lift scalar human-preference rewards into spatially and temporally aware pixel-level advantage maps. These maps are intended to redistribute optimization pressure toward perceptually important regions while maintaining GRPO stability. The authors claim that ViPO consistently outperforms vanilla GRPO across image and video benchmarks, yielding better in-domain alignment and improved out-of-domain generalization. The method is presented as architecture-agnostic and lightweight.
Significance. If the empirical claims hold after addressing the noted concerns, ViPO could offer a practical, plug-in improvement to GRPO-based alignment pipelines by incorporating perceptual structure without major architectural changes. This would be particularly relevant for reducing localized artifacts in image and video generation and for enhancing generalization, building directly on existing RLHF-style methods in the field.
major comments (2)
- [Method] Method section (Perceptual Structuring Module description): The central claim that the module produces reliable, human-preference-relevant advantage maps rests on the assumption that pretrained vision backbones (e.g., CLIP, DINO, or video equivalents) do not introduce systematic biases from their training distributions. No ablation studies are described that swap backbones, compare against non-semantic baselines (such as uniform or random maps), or hold the GRPO pipeline fixed while varying only the structuring component. Without such isolation, it remains possible that reported gains arise from implicit regularization effects rather than the claimed spatially/temporally aware redistribution of optimization pressure. This directly affects the validity of the outperformance and generalization results.
- [Experiments] Experiments section: The abstract states that ViPO 'consistently outperforms vanilla GRPO' on both in-domain and out-of-domain evaluations, yet the provided description supplies no quantitative metrics, error bars, statistical significance tests, or detailed ablation tables. To support the load-bearing claim of improved alignment and generalization, the manuscript must include specific results (e.g., reward scores, FID, or human preference win rates) with controls that isolate the Perceptual Structuring Module's contribution.
minor comments (1)
- [Abstract] The abstract would be strengthened by briefly noting the specific pretrained backbones used and the key quantitative improvements observed, to allow readers to immediately gauge the scale of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commit to revisions that directly strengthen the empirical support for ViPO.
read point-by-point responses
-
Referee: [Method] Method section (Perceptual Structuring Module description): The central claim that the module produces reliable, human-preference-relevant advantage maps rests on the assumption that pretrained vision backbones (e.g., CLIP, DINO, or video equivalents) do not introduce systematic biases from their training distributions. No ablation studies are described that swap backbones, compare against non-semantic baselines (such as uniform or random maps), or hold the GRPO pipeline fixed while varying only the structuring component. Without such isolation, it remains possible that reported gains arise from implicit regularization effects rather than the claimed spatially/temporally aware redistribution of optimization pressure. This directly affects the validity of the outperformance and generalization results.
Authors: We agree that isolating the contribution of the Perceptual Structuring Module is important for validating the core claim. The current manuscript does not include the requested ablations (backbone swaps or non-semantic baselines such as uniform/random maps with GRPO held fixed). In the revised version we will add these experiments, comparing multiple backbones (CLIP, DINO, and video equivalents) against uniform and random advantage maps while keeping the rest of the GRPO pipeline identical. This will provide direct evidence that performance differences arise from the spatially and temporally aware redistribution rather than incidental regularization. revision: yes
-
Referee: [Experiments] Experiments section: The abstract states that ViPO 'consistently outperforms vanilla GRPO' on both in-domain and out-of-domain evaluations, yet the provided description supplies no quantitative metrics, error bars, statistical significance tests, or detailed ablation tables. To support the load-bearing claim of improved alignment and generalization, the manuscript must include specific results (e.g., reward scores, FID, or human preference win rates) with controls that isolate the Perceptual Structuring Module's contribution.
Authors: The Experiments section of the full manuscript reports quantitative results, including human-preference win rates, FID scores, and out-of-domain generalization metrics that support the abstract claim. However, we acknowledge that error bars, statistical significance tests, and more granular ablation tables isolating the Perceptual Structuring Module are not sufficiently detailed. In the revision we will expand these sections to include error bars across runs, paired statistical tests, and explicit controls that vary only the structuring module while reporting reward scores, FID, and win rates. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces ViPO as an extension to standard GRPO by adding an independent Perceptual Structuring Module that leverages external pretrained vision backbones to generate pixel-level advantage maps. This structuring step is not defined in terms of the target rewards or outcomes, nor does it reduce any claimed prediction or advantage to a fitted parameter by construction. No self-citations are invoked as load-bearing for uniqueness or ansatz choices in the provided description, and performance gains are framed as empirical results on in-domain and out-of-domain benchmarks rather than mathematical identities. The derivation chain remains self-contained with external components supplying the perceptual signal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained vision backbones can be used to construct reliable spatially and temporally aware advantage maps
invented entities (1)
-
Perceptual Structuring Module
no independent evidence
Forward citations
Cited by 2 Pith papers
-
CreFlow: Corrective Reflow for Sparse-Reward Embodied Video Diffusion RL
CreFlow combines LTL compositional rewards with credit-aware NFT and corrective reflow losses in online RL to improve embodied video diffusion models, raising downstream task success by 23.8 percentage points on eight...
-
Learning to Credit the Right Steps: Objective-aware Process Optimization for Visual Generation
OTCA improves GRPO training for visual generation by estimating step importance in trajectories and adaptively weighting multiple reward objectives.
Reference graph
Works this paper leans on
-
[1]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforce- ment learning.arXiv preprint arXiv:2305.13301, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Neural mechanisms of selective visual attention.Annual review of neuroscience, 18 (1):193–222, 1995
Robert Desimone and John Duncan. Neural mechanisms of selective visual attention.Annual review of neuroscience, 18 (1):193–222, 1995. 4
work page 1995
-
[3]
Optimizing ddpm sampling with shortcut fine-tuning.arXiv preprint arXiv:2301.13362,
Ying Fan and Kangwook Lee. Optimizing ddpm sampling with shortcut fine-tuning.arXiv preprint arXiv:2301.13362,
-
[4]
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Moham- mad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffu- sion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023. 1, 2
work page 2023
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Taylor R Hayes and John M Henderson. Deep saliency mod- els learn low-, mid-, and high-level features to predict scene attention.Scientific reports, 11(1):18434, 2021. 2
work page 2021
-
[7]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 5, 1
work page 2016
-
[8]
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, et al. Videoscore: Building automatic metrics to simulate fine-grained human feedback for video genera- tion.arXiv preprint arXiv:2406.15252, 2024. 2
-
[9]
TempFlow-GRPO: When Timing Matters for GRPO in Flow Models
Xiaoxuan He, Siming Fu, Yuke Zhao, Wanli Li, Jian Yang, Dacheng Yin, Fengyun Rao, and Bo Zhang. Tempflow-grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[10]
Meaning-based guidance of attention in scenes as revealed by meaning maps
John M Henderson and Taylor R Hayes. Meaning-based guidance of attention in scenes as revealed by meaning maps. Nature Human Behaviour, 1:743–747, 2017. 2, 4
work page 2017
-
[11]
John M Henderson and Taylor R Hayes. Meaning guides attention in real-world scene images: Evidence from eye movements and meaning maps.Journal of vision, 18(6):10– 10, 2018. 2
work page 2018
-
[12]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1
work page 2020
-
[13]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 4
work page 2024
-
[14]
Computational modelling of visual attention.Nature reviews neuroscience, 2(3):194–203,
Laurent Itti and Christof Koch. Computational modelling of visual attention.Nature reviews neuroscience, 2(3):194–203,
-
[15]
Ming Jiang, Shengsheng Huang, Juanyong Duan, and Qi Zhao. Salicon: Saliency in context. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 1072–1080, 2015. 2
work page 2015
-
[16]
Perceptual losses for real-time style transfer and super-resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision, pages 694–711. Springer, 2016. 2
work page 2016
-
[17]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 5, 1
work page 2023
-
[18]
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Ma- tiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Ad- vances in neural information processing systems, 36:36652– 36663, 2023. 2, 4
work page 2023
-
[19]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 4
work page 2024
-
[20]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. Mixgrpo: Unlocking flow- based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Yuanzhi Liang, Yijie Fang, Rui Li, Ziqi Ni, Ruijie Su, and Chi Zhang. Integrating reinforcement learning with vi- sual generative models: Foundations and advances.arXiv preprint arXiv:2508.10316, 2025. 1
-
[22]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Wenyu Qin, Menghan Xia, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 5, 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[29]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Yulin Wang, Yang Yue, Yang Yue, Huanqian Wang, Haojun Jiang, Yizeng Han, Zanlin Ni, Yifan Pu, Minglei Shi, Rui Lu, et al. Emulating human-like adaptive vision for efficient and flexible machine visual perception.Nature Machine In- telligence, pages 1–19, 2025. 2
work page 2025
-
[31]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis, 2023. 4
work page 2023
-
[32]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagere- ward: Learning and evaluating human preferences for text- to-image generation.Advances in Neural Information Pro- cessing Systems, 36:15903–15935, 2023. 2, 4
work page 2023
-
[34]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shu- run Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation. arXiv preprint arXiv:2412.21059, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Show, attend and tell: Neural image caption gen- eration with visual attention
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption gen- eration with visual attention. InInternational conference on machine learning, pages 2048–2057. PMLR, 2015. 2
work page 2048
-
[36]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818, 2025. 1, 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Identity- preserving text-to-video generation by frequency decompo- sition
Shenghai Yuan, Jinfa Huang, Xianyi He, Yunyang Ge, Yu- jun Shi, Liuhan Chen, Jiebo Luo, and Li Yuan. Identity- preserving text-to-video generation by frequency decompo- sition. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12978–12988, 2025. 4
work page 2025
-
[38]
Chi Zhang, Yuanzhi Liang, Xi Qiu, Fangqiu Yi, and Xuelong Li. Vast 1.0: A unified framework for controllable and con- sistent video generation.arXiv preprint arXiv:2412.16677,
-
[39]
Flow- grpo: Training flow matching models via online reinforce- ment learning
Da Zhou, Yang Li, Qing Li, Yujia Yang, Jian Tang, Ye- long Shen, Xiang Li, Xinyang Wang, and Pan Zhou. Flow- grpo: Training flow matching models via online reinforce- ment learning. InProceedings of the International Confer- ence on Learning Representations (ICLR), 2024. 1, 2 Seeing What Matters: Visual Preference Policy Optimization for Visual Generation...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.