Recognition: no theorem link
Action-guided generation of 3D functionality segmentation data
Pith reviewed 2026-05-17 04:46 UTC · model grok-4.3
The pith
SynthFun3D creates synthetic 3D functionality segmentation data from action descriptions to supplement scarce real annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SynthFun3D takes an action description in natural language, retrieves objects carrying part-level annotations, arranges them into a 3D scene under explicit spatial and semantic constraints, renders multiple views, and automatically identifies the target functional element to produce exact ground-truth masks. A VLM-based 3D functionality segmentation model trained on the combination of these generated examples and real-world data achieves higher accuracy than real data alone, with measured improvements of +2.2 mAP, +6.3 mAR, and +5.7 mIoU.
What carries the argument
The SynthFun3D pipeline that retrieves part-annotated assets, assembles them into action-compliant scenes, renders multi-view images, and derives precise functional-element masks automatically.
If this is right
- Augmenting real training sets with the generated data produces measurable gains in mAP, mAR, and mIoU on real test scenes.
- The method removes the need for manual mask annotation on the synthetic portion of the training data.
- Large numbers of training examples can be produced for arbitrary action descriptions without additional human effort.
- Models gain improved ability to locate interactive elements described in free-form language inside 3D environments.
Where Pith is reading between the lines
- The same retrieval-and-constraint approach could be adapted to generate training data for other 3D vision-language tasks such as affordance prediction or step-by-step action planning.
- Scaling the asset repository or loosening the arrangement constraints might further increase diversity and reduce any remaining domain gap.
- Combining this generation process with self-supervised refinement on real images could push performance higher while keeping annotation costs low.
Load-bearing premise
The automatically assembled scenes and their derived masks must be realistic enough that models trained on the mixture learn real-world patterns rather than artifacts of the generation process.
What would settle it
Training the same VLM-based model on real data augmented with SynthFun3D examples and observing zero gain or a drop in mAP, mAR, or mIoU on held-out real test scenes.
Figures


















read the original abstract
3D functionality segmentation aims to identify the interactive element in a 3D scene required to perform an action described in free-form language (e.g., the handle to ``Open the second drawer of the cabinet near the bed''). Progress has been constrained by the scarcity of annotated real-world data, as collecting and labeling fine-grained 3D masks is prohibitively expensive. To address this limitation, we introduce SynthFun3D, the first method for generating 3D functionality segmentation data directly from action descriptions. Given an action description, SynthFun3D constructs a plausible 3D scene by retrieving objects with part-level annotations from a large-scale asset repository and arranging them under spatial and semantic constraints. SynthFun3D renders multi-view images and automatically identifies the target functional element, producing precise ground-truth masks without manual annotation. We demonstrate the effectiveness of the generated data by training a VLM-based 3D functionality segmentation model. Augmenting real-world data with our synthetic data consistently improves performance, with gains of +2.2 mAP, +6.3 mAR, and +5.7 mIoU over real-only training. This shows that action-guided synthetic data generation provides a scalable and effective complement to manual annotation for 3D functionality understanding. Project page: tev-fbk.github.io/synthfun3d.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SynthFun3D, a pipeline for generating synthetic 3D functionality segmentation data directly from free-form action descriptions. Given an action, it retrieves part-annotated objects from a large asset repository, arranges them into plausible scenes under spatial and semantic constraints, renders multi-view images, and automatically identifies the target functional element to produce precise ground-truth masks without manual labeling. A VLM-based segmentation model trained on real data augmented with the synthetic data achieves consistent gains of +2.2 mAP, +6.3 mAR, and +5.7 mIoU over real-only training on held-out real data.
Significance. If the generated masks prove reliable and free of systematic biases, the work provides a scalable complement to expensive manual annotation for 3D functionality understanding, a domain limited by data scarcity. The action-guided scene construction and automatic mask production represent a practical advance, and the augmentation results offer empirical support for the utility of such synthetic data in training language-conditioned 3D models.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments: the reported gains (+2.2 mAP, +6.3 mAR, +5.7 mIoU) are presented without error analysis, controls for generation artifacts, or quantitative validation of the automatically produced masks against human annotations. This leaves open whether improvements arise from genuine functional understanding or from confounding factors in the synthetic data.
- [Method] Method (scene construction and mask generation): the automatic identification of the target functional element from free-form actions (e.g., via retrieval or rule-based heuristics) is load-bearing for the claim of precise ground-truth masks. The manuscript should detail this step and analyze failure modes on ambiguous cases such as 'open the second drawer', as incorrect masks could cause models to learn generation-specific patterns rather than generalizable functionality.
minor comments (2)
- [Abstract] The project page is referenced but the manuscript would benefit from explicit discussion of limitations arising from the asset repository coverage and retrieval heuristics.
- [Throughout] Terminology for 'functional element' versus 'interactive element' should be used consistently throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the major comments below and have made revisions to the manuscript to incorporate additional details and analyses where possible.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments: the reported gains (+2.2 mAP, +6.3 mAR, +5.7 mIoU) are presented without error analysis, controls for generation artifacts, or quantitative validation of the automatically produced masks against human annotations. This leaves open whether improvements arise from genuine functional understanding or from confounding factors in the synthetic data.
Authors: We agree that the experimental results would benefit from additional analysis. In the revised version, we include error bars by reporting the mean and standard deviation of the metrics over multiple training runs. We have also added a discussion of potential generation artifacts and their possible impact on the results. However, a full quantitative validation of the synthetic masks against independent human annotations is not included, as it would require significant additional resources; we acknowledge this as a limitation in the revised manuscript. revision: partial
-
Referee: [Method] Method (scene construction and mask generation): the automatic identification of the target functional element from free-form actions (e.g., via retrieval or rule-based heuristics) is load-bearing for the claim of precise ground-truth masks. The manuscript should detail this step and analyze failure modes on ambiguous cases such as 'open the second drawer', as incorrect masks could cause models to learn generation-specific patterns rather than generalizable functionality.
Authors: We have revised the Method section to provide a more detailed explanation of the automatic identification of the target functional element. This step leverages the part-level annotations from the asset repository combined with parsing of the action description to select the relevant object part. Additionally, we have included an analysis of failure modes for ambiguous action descriptions, such as 'open the second drawer', with examples illustrating how the system resolves or flags such cases. This helps demonstrate that the generated masks support learning generalizable functionality rather than dataset-specific patterns. revision: yes
Circularity Check
No circularity: empirical gains measured on independent real test data
full rationale
The paper's core result is an empirical performance improvement (+2.2 mAP, +6.3 mAR, +5.7 mIoU) when augmenting real training data with SynthFun3D-generated synthetic scenes and masks. This is evaluated on held-out real-world test data, providing an external benchmark independent of the generation process. The method retrieves part-annotated assets, applies spatial/semantic constraints, renders views, and produces masks via automatic identification of the functional element from the action description. No equations, fitted parameters, or self-referential definitions reduce the reported gains to inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes from prior author work are invoked to force the outcome. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Part-annotated 3D assets can be retrieved and arranged under spatial and semantic constraints to form plausible scenes for arbitrary action descriptions.
Reference graph
Works this paper leans on
-
[1]
https://www.blender.org/ , 2024
Blender. https://www.blender.org/ , 2024. Ac- cessed: 2024-06-01. 5
work page 2024
-
[2]
World Simulation with Video Foundation Models for Physical AI
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Eliza- beth Cha, Yu-Wei Chao, et al. World Simulation with Video Foundation Models for Physical AI.arXiv preprint arXiv:2511.00062, 2025. 5, 8, 1, 4, 7, 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Alisson Azzolini, Junjie Bai, Hannah Brandon, Jiaxin Cao, Prithvijit Chattopadhyay, Huayu Chen, Jinju Chu, Yin Cui, Jenna Diamond, Yifan Ding, et al. Cosmos-Reason1: From Physical Common Sense to Embodied Reasoning.arXiv preprint arXiv:2503.15558, 2025. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5- VL Technical Report.a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Objectnav Revisited: On Evaluation of Embodied Agents Navigating to Objects
Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Olek- sandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, and Erik Wijmans. Objectnav Revisited: On Evaluation of Embodied Agents Navigating to Objects. arXiv preprint arXiv:2006.13171, 2020. 2
-
[6]
Llama-nemotron: Efficient reasoning models
Akhiad Bercovich, Itay Levy, Izik Golan, Mohammad Dab- bah, Ran El-Yaniv, Omri Puny, Ido Galil, Zach Moshe, Tomer Ronen, Najeeb Nabwani, et al. Llama-Nemotron: Efficient Reasoning Models.arXiv preprint arXiv:2505.00949, 2025. 5, 7
-
[7]
SceneFactor: Factored Latent 3D Diffusion for Controllable 3D Scene Generation
Aleksey Bokhovkin, Quan Meng, Shubham Tulsiani, and Angela Dai. SceneFactor: Factored Latent 3D Diffusion for Controllable 3D Scene Generation. InInternational Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[8]
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, et al. Perception Encoder: The Best Visual Embeddings Are Not at the Output of the Network.International Conference on Neural Information Processing Systems (NeurIPS), 2025. 4, 5
work page 2025
-
[9]
Functionality Understanding and Segmentation in 3D Scenes
Jaime Corsetti, Francesco Giuliari, Alice Fasoli, Davide Boscaini, and Fabio Poiesi. Functionality Understanding and Segmentation in 3D Scenes. InInternational Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2, 3, 8, 4
work page 2025
-
[10]
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. ProcTHOR: Large-Scale Embodied AI Using Procedural Generation.In- ternational Conference on Neural Information Processing Systems (NeurIPS), 2022. 1
work page 2022
-
[11]
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-Xl: A Universe of 10m+ 3D Objects.International Conference on Neural Information Processing Systems (NeurIPS), 2023. 2, 3, 5, 4
work page 2023
-
[12]
Scene- Fun3D: Fine-Grained Functionality and Affordance Under- standing in 3D Scenes
Alexandros Delitzas, Ayca Takmaz, Federico Tombari, Robert Sumner, Marc Pollefeys, and Francis Engelmann. Scene- Fun3D: Fine-Grained Functionality and Affordance Under- standing in 3D Scenes. InInternational Conference on Com- puter Vision and Pattern Recognition (CVPR), 2024. 1, 2, 4, 7, 8
work page 2024
-
[13]
3D-Future: 3D Furniture Shape with Texture.International Journal on Com- puter Vision (IJCV), 2021
Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3D-Future: 3D Furniture Shape with Texture.International Journal on Com- puter Vision (IJCV), 2021. 2
work page 2021
-
[14]
Holistic Un- derstanding of 3D Scenes as Universal Scene Description
Anna-Maria Halacheva, Yang Miao, Jan-Nico Zaech, Xi Wang, Luc Van Gool, and Danda Pani Paudel. Holistic Un- derstanding of 3D Scenes as Universal Scene Description. In International Conference on Computer Vision (ICCV), 2025. 1
work page 2025
-
[15]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-Rank Adaptation of Large Language Models.Interna- tional Conference on Learning Representations (ICLR), 2022. 8
work page 2022
-
[16]
Video Perception Models for 3D Scene Synthesis
Rui Huang, Guangyao Zhai, Zuria Bauer, Marc Pollefeys, Federico Tombari, Leonidas Guibas, Gao Huang, and Francis Engelmann. Video Perception Models for 3D Scene Synthesis. International Conference on Neural Information Processing Systems (NeurIPS), 2025. 1, 2
work page 2025
-
[17]
LERF: Language Embedded Radiance Fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. LERF: Language Embedded Radiance Fields. InInternational Conference on Computer Vision (ICCV), 2023. 2
work page 2023
-
[18]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment Any- thing. InInternational Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 4, 8
work page 2023
-
[19]
Oliver Lemke, Zuria Bauer, René Zurbrügg, Marc Pollefeys, Francis Engelmann, and Hermann Blum. Spot-Compose: A Framework for Open-vocabulary Object Retrieval and Drawer Manipulation in Point Clouds. 2024. 2
work page 2024
-
[20]
Pratyush Maini, Vineeth Dorna, Parth Doshi, Aldo Carranza, Fan Pan, Jack Urbanek, Paul Burstein, Alex Fang, Alvin Deng, Amro Abbas, et al. BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-Scale Pretraining.arXiv preprint arXiv:2508.10975, 2025. 4
-
[21]
Phuc D. A. Nguyen, Tuan Duc Ngo, Evangelos Kalogerakis, Chuang Gan, Anh Tran, Cuong Pham, and Khoi Nguyen. Open3DIS: Open-V ocabulary 3D Instance Segmentation with 2D Mask Guidance. InInternational Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
work page 2024
-
[22]
Habitat 3.0: A Co-Habitat for Humans, Avatars, and Robots
Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung-Yen Yang, Ruslan Partsey, Ruta Desai, Alexan- der Clegg, Michal Hlavac, So Yeon Min, et al. Habitat 3.0: A Co-Habitat for Humans, Avatars, and Robots. InInterna- tional Conference on Learning Representations (ICLR), 2024. 1
work page 2024
-
[23]
Learning Transferable Visual Models from Natural Language Super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning Transferable Visual Models from Natural Language Super- vision. InInternational Conference on Machine Learning (ICML), 2021. 3, 5, 6
work page 2021
-
[24]
Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. InEMNLP- IJCNLP, 2019. 3, 6
work page 2019
-
[25]
Dennis Rotondi, Fabio Scaparro, Hermann Blum, and Kai O Arras. FunGraph: Functionality Aware 3D Scene Graphs for Language-Prompted Scene Interaction.IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS),
-
[26]
Llm-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Lan- guage Models
Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, and Yu Su. Llm-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Lan- guage Models. InInternational Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 1
work page 2023
-
[27]
Layoutvlm: Differentiable Optimization of 3D Layout via Vision-Language Models
Fan-Yun Sun, Weiyu Liu, Siyi Gu, Dylan Lim, Goutam Bhat, Federico Tombari, Manling Li, Nick Haber, and Jiajun Wu. Layoutvlm: Differentiable Optimization of 3D Layout via Vision-Language Models. InInternational Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2
work page 2025
-
[28]
SLAG: Scalable Language-Augmented Gaussian Splatting
Laszlo Szilagyi, Francis Engelmann, and Jeannette Bohg. SLAG: Scalable Language-Augmented Gaussian Splatting. IEEE Robotics and Automation Letters (RA-L), 2025. 2
work page 2025
-
[29]
Habitat 2.0: Training Home Assistants to Rearrange Their Habitat
Andrew Szot, Alex Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Chaplot, Oleksandr Maksymets, Aaron Gokaslan, Vladimir V ondrus, Sameer Dharur, Franziska Meier, Woj- ciech Galuba, Angel Chang, Zsolt Kira, Vladlen Koltun, Ji- tendra Malik, Manolis Savva, and Dhruv Batra. Habitat 2.0: Training Home As...
work page 2021
-
[30]
Ayca Takmaz, Elisabetta Fedele, Robert Sumner, Marc Polle- feys, Federico Tombari, and Francis Engelmann. Open- Mask3D: Open-V ocabulary 3D Instance Segmentation.In- ternational Conference on Neural Information Processing Systems (NeurIPS), 2024. 2
work page 2024
-
[31]
Sumner, Francis Engelmann, Johanna Wald, and Federico Tombari
Ayca Takmaz, Alexandros Delitzas, Robert W. Sumner, Francis Engelmann, Johanna Wald, and Federico Tombari. Search3D: Hierarchical Open-V ocabulary 3D Segmentation. IEEE Robotics and Automation Letters (RA-L), 2025. 2
work page 2025
-
[32]
Diffuscene: Denoising Dif- fusion Models for Generative Indoor Scene Synthesis
Jiapeng Tang, Yinyu Nie, Lev Markhasin, Angela Dai, Justus Thies, and Matthias Nießner. Diffuscene: Denoising Dif- fusion Models for Generative Indoor Scene Synthesis. In International Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
work page 2024
-
[33]
P2P-Bridge: Diffusion Bridges for 3D Point Cloud Denoising
Mathias V ogel, Keisuke Tateno, Marc Pollefeys, Federico Tombari, Marie-Julie Rakotosaona, and Francis Engelmann. P2P-Bridge: Diffusion Bridges for 3D Point Cloud Denoising. InEuropean Conference on Computer Vision (ECCV), 2024. 2
work page 2024
-
[34]
AffordBot: 3D Fine-Grained Embodied Rea- soning via Multimodal Large Language Models
Xinyi Wang, Xun Yang, Yanlong Xu, Yuchen Wu, Zhen Li, and Na Zhao. AffordBot: 3D Fine-Grained Embodied Rea- soning via Multimodal Large Language Models. InInterna- tional Conference on Neural Information Processing Systems (NeurIPS), 2025. 2
work page 2025
-
[35]
AffordBot: 3D Fine-Grained Embodied Rea- soning via Multimodal Large Language Models
Xinyi Wang, Xun Yang, Yanlong Xu, Yuchen Wu, Zhen Li, and Na Zhao. AffordBot: 3D Fine-Grained Embodied Rea- soning via Multimodal Large Language Models. InInterna- tional Conference on Neural Information Processing Systems (NeurIPS), 2025. 1
work page 2025
-
[36]
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X. Chang, Leonidas J. Guibas, and Hao Su. SAPIEN: A SimulAted Part-Based Interactive ENviron- ment. InInternational Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 2, 3, 5, 4, 6, 7
work page 2020
-
[37]
Xiuyu Yang, Yunze Man, Junkun Chen, and Yu-Xiong Wang. SceneCraft: Layout-Guided 3D Scene Generation.Interna- tional Conference on Neural Information Processing Systems (NeurIPS), 2024. 2
work page 2024
-
[38]
Physcene: Physically Interactable 3D Scene Synthesis for Embodied Ai
Yandan Yang, Baoxiong Jia, Peiyuan Zhi, and Siyuan Huang. Physcene: Physically Interactable 3D Scene Synthesis for Embodied Ai. InInternational Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 1, 2, 5
work page 2024
-
[39]
Holodeck: Language Guided Generation of 3D Embodied Ai Environments
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Al- varo Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, et al. Holodeck: Language Guided Generation of 3D Embodied Ai Environments. InInterna- tional Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2024. 1, 2, 3, 4, 5, 6
work page 2024
-
[40]
Open-V ocabulary Functional 3D Scene Graphs for Real-World Indoor Spaces
Chenyangguang Zhang, Alexandros Delitzas, Fangjinhua Wang, Ruida Zhang, Xiangyang Ji, Marc Pollefeys, and Francis Engelmann. Open-V ocabulary Functional 3D Scene Graphs for Real-World Indoor Spaces. InInternational Con- ference on Computer Vision and Pattern Recognition (CVPR),
-
[41]
Adding Conditional Control to Text-to-Image Diffusion Models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding Conditional Control to Text-to-Image Diffusion Models. In International Conference on Computer Vision (ICCV), 2023. 5
work page 2023
-
[42]
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think Beyond Images.arXiv preprint arXiv:2508.11630, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models
Gengze Zhou, Yicong Hong, and Qi Wu. NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models. InAssociation for the Advancement of Artificial Intelligence (AAAI), 2024. 1
work page 2024
-
[44]
ESC: Ex- ploration with Soft Commonsense Constraints for Zero-Shot Object Navigation
Kaiwen Zhou, Kaizhi Zheng, Connor Pryor, Yilin Shen, Hongxia Jin, Lise Getoor, and Xin Eric Wang. ESC: Ex- ploration with Soft Commonsense Constraints for Zero-Shot Object Navigation. InInternational Conference on Machine Learning (ICML), 2023. 1
work page 2023
-
[45]
Unifying 3D Vision-Language Understanding via Prompt- able Queries
Ziyu Zhu, Zhuofan Zhang, Xiaojian Ma, Xuesong Niu, Yixin Chen, Baoxiong Jia, Zhidong Deng, Siyuan Huang, and Qing Li. Unifying 3D Vision-Language Understanding via Prompt- able Queries. InEuropean Conference on Computer Vision (ECCV), 2024. 2 Language-guided 3D Scene Synthesis for Fine-grained Functionality Understanding Supplementary Material In this doc...
work page 2024
-
[46]
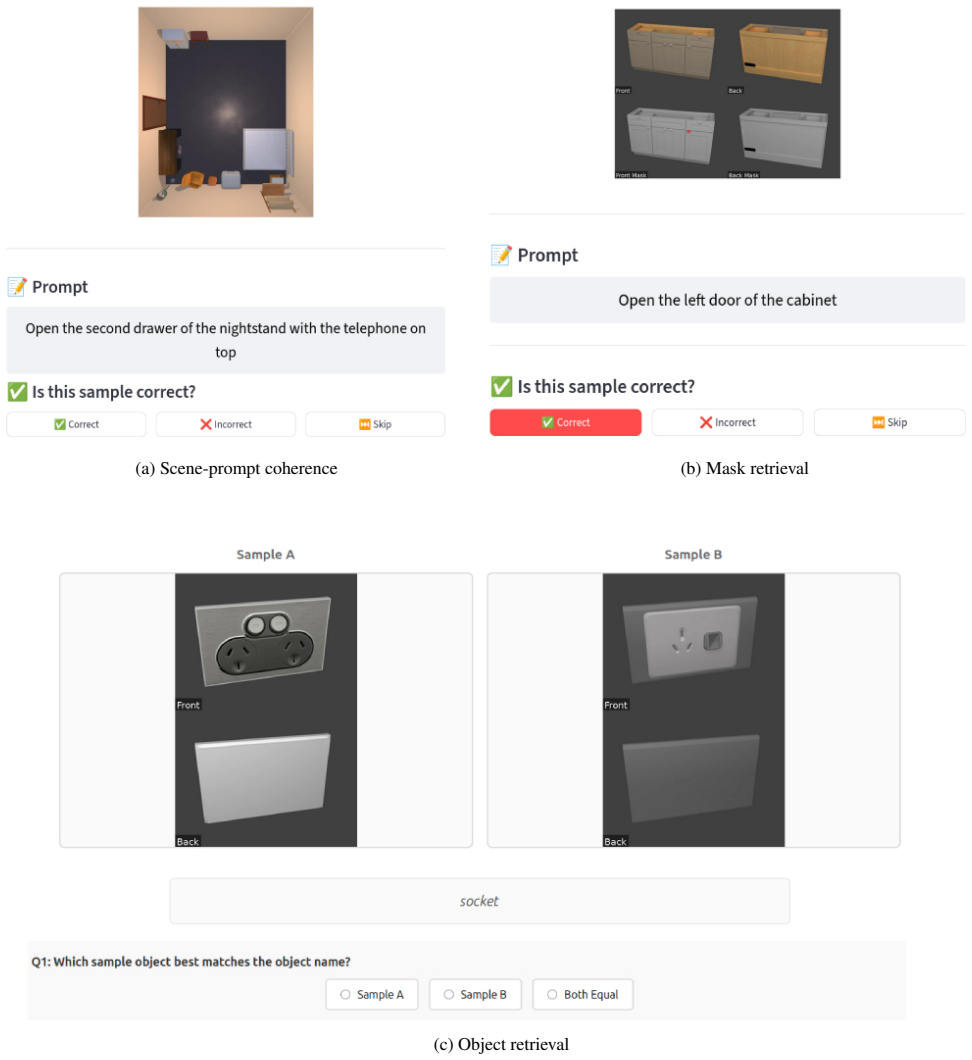
User study details In the main paper, we presented the results of three user studies. In the following Section, we provide details about the interface and the number of participants. Scene-prompt coherence.We randomly sample 85 task de- scriptions D from the training split of SceneFun3D [12]. For each prompt, we generate one scene with SynthFun3D and one ...
-
[47]
Training on downstream task In the following Sections, we detail the process used to obtain the ground-truth points, which are used to train a VLM on the downstream task. 2.1. Generating pointing data from SceneFun3D To train the pointing-capable VLM used in our studies on the Scene- Fun3D dataset, we use high-resolution RGB-D videos ( 1920× 1440), associ...
work page 1920
-
[48]
Additional quantitative results In this Section, we report additional quantitative results relative to experiments presented in the main paper. In Sec. 3.1, we report an ablation study on Holodeck, and, in Sec. 3.2, we compare the error rate in the points produced by Qwen when trained on different data sources. 3.1. Ablation study on scene generation Holo...
-
[49]
Qualitative results In this Section, we show additional qualitative results obtained with SynthFun3D. In Sec. 4.1, we show additional examples of scene generation. For each scene, we highlight the spatial relation- ships mentioned in the prompt and also report an example frame generated with this scene, along with the frame generated by Cos- mos. In Sec. ...
-
[50]
Prompts As our retrieval strategy makes extensive use of the metadata pro- vided by PartNet-Mobility [36], in Sec. 5.1 we discuss the meta- data structure and how it was used in SynthFun3D. We report the prompts used to guide the retrieval step of SynthFun3D in Sec. 5.2. Finally, in Sec. 5.3 we report the prompts used in the Cosmos pipeline to generate th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.