MobiBench: Multi-Branch, Modular Benchmark for Mobile GUI Agents
Pith reviewed 2026-05-16 22:56 UTC · model grok-4.3
The pith
MobiBench provides a modular offline benchmark for mobile GUI agents that matches human evaluators at 94.72 percent agreement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MobiBench is the first modular and multi-path aware offline benchmarking framework for mobile GUI agents. It achieves 94.72 percent agreement with human evaluators on par with carefully engineered online benchmarks while retaining the scalability and reproducibility of static offline benchmarks, and it supports module-level analysis of agent performance.
What carries the argument
Multi-branch annotations paired with modular decomposition of agent pipelines that separate perception, reasoning, and action modules for independent scoring.
If this is right
- Different agent techniques can be compared fairly without penalizing valid alternative paths.
- Performance bottlenecks can be isolated to specific modules such as perception or planning.
- Optimal module configurations can be identified across different model sizes.
- Actionable guidelines emerge for building more capable and cost-efficient mobile GUI agents.
Where Pith is reading between the lines
- The same multi-path and modular structure could transfer to benchmarking GUI agents on web or desktop platforms.
- Richer multi-path data might serve as improved training signals for agent models.
- Widespread adoption would lower the cost and time of reliable agent evaluation, speeding iteration cycles.
Load-bearing premise
The multi-path annotations capture all valid alternative actions that human evaluators would accept without systematic omissions.
What would settle it
A direct comparison study that collects fresh human ratings on a held-out set of agent trajectories and measures whether MobiBench scores still reach at least 90 percent agreement.
Figures





read the original abstract
Mobile GUI Agents, AI agents capable of interacting with mobile applications on behalf of users, have the potential to transform human computer interaction. However, current evaluation practices for GUI agents face two fundamental limitations. First, they either rely on single path offline benchmarks or online live benchmarks. Offline benchmarks using static, single path annotated datasets unfairly penalize valid alternative actions, while online benchmarks suffer from poor scalability and reproducibility due to the dynamic and unpredictable nature of live evaluation. Second, existing benchmarks treat agents as monolithic black boxes, overlooking the contributions of individual components, which often leads to unfair comparisons or obscures key performance bottlenecks. To address these limitations, we present MobiBench, the first modular and multi path aware offline benchmarking framework for mobile GUI agents that enables high fidelity, scalable, and reproducible evaluation entirely in offline settings. Our experiments demonstrate that MobiBench achieves 94.72 percent agreement with human evaluators, on par with carefully engineered online benchmarks, while preserving the scalability and reproducibility of static offline benchmarks. Furthermore, our comprehensive module level analysis uncovers several key insights, including a systematic evaluation of diverse techniques used in mobile GUI agents, optimal module configurations across model scales, the inherent limitations of current LFMs, and actionable guidelines for designing more capable and cost efficient mobile agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MobiBench, a modular multi-branch offline benchmark for mobile GUI agents. It claims to resolve the unfair penalization of valid alternative actions in single-path offline benchmarks and the poor scalability/reproducibility of online live benchmarks by providing multi-path annotations and component-wise evaluation, reporting 94.72% agreement with human evaluators while enabling module-level analysis of techniques, model scales, and design guidelines.
Significance. If the multi-path annotations prove comprehensive and the agreement metric robust, MobiBench would represent a meaningful advance by delivering scalable, reproducible offline evaluation that matches the fidelity of online benchmarks, while also supplying actionable module-level insights that could guide more efficient GUI agent design.
major comments (2)
- [§3 and §4.2] §3 (Benchmark Construction) and §4.2 (Human Agreement Evaluation): the 94.72% agreement claim is load-bearing for the central contribution, yet the manuscript provides insufficient detail on the procedure used to enumerate and validate the completeness of alternative paths (e.g., no quantitative coverage metric, no inter-annotator agreement on path exhaustiveness, and no explicit check for omitted error-recovery or navigation-order variants). This leaves open the possibility that agreement rates partly reflect annotation coverage rather than true behavioral equivalence.
- [§5.3] §5.3 (Module-Level Analysis): the reported breakdowns by module and model scale are presented without an ablation that isolates the effect of multi-path versus single-path scoring on per-module performance; without this, it is unclear whether the modular insights are driven by the multi-branch feature or would hold under conventional single-path evaluation.
minor comments (3)
- [§2] The related-work section (§2) omits several 2024 GUI-agent papers that also explore offline evaluation; adding them would strengthen positioning.
- [Figure 2] Figure 2 (benchmark pipeline) would benefit from explicit call-outs for the multi-branch merging step and the exact matching criteria used in path comparison.
- [§3.1] A few minor notation inconsistencies appear in the module-interface definitions (e.g., inconsistent use of M_i versus Module_i); a quick pass for uniformity would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of transparency and interpretability that we address below. We have prepared revisions to strengthen the manuscript on both points.
read point-by-point responses
-
Referee: [§3 and §4.2] §3 (Benchmark Construction) and §4.2 (Human Agreement Evaluation): the 94.72% agreement claim is load-bearing for the central contribution, yet the manuscript provides insufficient detail on the procedure used to enumerate and validate the completeness of alternative paths (e.g., no quantitative coverage metric, no inter-annotator agreement on path exhaustiveness, and no explicit check for omitted error-recovery or navigation-order variants). This leaves open the possibility that agreement rates partly reflect annotation coverage rather than true behavioral equivalence.
Authors: We agree that greater detail on path enumeration and validation is warranted to substantiate the agreement metric. In the revised manuscript we will expand §3 to describe our multi-annotator protocol, report quantitative coverage statistics (average paths per task and saturation curves), provide inter-annotator agreement figures specifically for path exhaustiveness, and document the systematic inclusion of error-recovery and navigation-order variants. These additions will clarify that the observed agreement reflects comprehensive annotation rather than incomplete coverage. revision: yes
-
Referee: [§5.3] §5.3 (Module-Level Analysis): the reported breakdowns by module and model scale are presented without an ablation that isolates the effect of multi-path versus single-path scoring on per-module performance; without this, it is unclear whether the modular insights are driven by the multi-branch feature or would hold under conventional single-path evaluation.
Authors: We concur that an ablation isolating multi-path versus single-path scoring is necessary to interpret the module-level findings. In the revised §5.3 we will add a direct comparison that recomputes all module and scale breakdowns under single-path scoring and contrasts the results with the multi-path evaluation. This will show whether the reported insights depend on the multi-branch annotations. revision: yes
Circularity Check
No circularity; empirical agreement measured against independent human judgments
full rationale
The paper presents MobiBench as an empirical benchmarking framework and reports a 94.72% agreement rate with human evaluators. This rate is obtained by direct comparison to external human annotations rather than any fitted parameters, self-citations, or internal derivations. No equations, predictions, or first-principles claims appear in the provided text that reduce to inputs by construction. The multi-path annotation process is described as an engineering choice whose coverage is validated externally via human agreement, keeping the central result independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human evaluators provide reliable ground truth for valid agent actions
invented entities (1)
-
MobiBench modular multi-path benchmark
no independent evidence
Forward citations
Cited by 4 Pith papers
-
Beyond Binary: Reframing GUI Critique as Continuous Semantic Alignment
BBCritic uses contrastive learning to align GUI actions in a continuous affordance space, outperforming larger binary critic models on a new four-level hierarchical benchmark while enabling zero-shot transfer.
-
Beyond Binary: Reframing GUI Critique as Continuous Semantic Alignment
BBCritic reframes GUI critique as continuous semantic alignment via contrastive learning in an affordance space, outperforming larger binary SOTA models on a new four-level hierarchical benchmark without extra annotations.
-
RiskWebWorld: A Realistic Interactive Benchmark for GUI Agents in E-commerce Risk Management
RiskWebWorld is the first realistic interactive benchmark for GUI agents in e-commerce risk management, revealing a large gap between generalist and specialized models plus RL gains.
-
AgentLens: Adaptive Visual Modalities for Human-Agent Interaction in Mobile GUI Agents
AgentLens adaptively deploys Full UI, Partial UI, and GenUI modalities with virtual display overlays for mobile GUI agents, yielding 85.7% user preference and best-in-study usability in a 21-participant evaluation.
Reference graph
Works this paper leans on
-
[1]
Saaket Agashe, Kyle Wong, Vincent Tu, Jiachen Yang, Ang Li, and Xin Eric Wang. 2025. Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents. arXiv:2504.00906 [cs.AI] https: //arxiv.org/abs/2504.00906
work page internal anchor Pith review arXiv 2025
-
[2]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [3]
- [4]
- [5]
- [6]
- [7]
-
[8]
Android Developers. [n. d.].AccessibilityService | API ref- erence. https://developer.android.com/reference/android/ accessibilityservice/AccessibilityService Accessed 2025-09-02
work page 2025
-
[9]
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. 2023. Chain-of- verification reduces hallucination in large language models.arXiv preprint arXiv:2309.11495(2023)
work page internal anchor Pith review arXiv 2023
-
[10]
Divyansh Garg, Shaun VanWeelden, Diego Caples, Andis Draguns, Nikil Ravi, Pranav Putta, Naman Garg, Tomas Abraham, Michael Lara, Federico Lopez, James Liu, Atharva Gundawar, Prannay Hebbar, Youngchul Joo, Jindong Gu, Charles London, Christian Schroeder de Witt, and Sumeet Motwani. 2025. REAL: Benchmarking Au- tonomous Agents on Deterministic Simulations o...
- [11]
- [12]
- [13]
-
[14]
Jungjae Lee, Dongjae Lee, Chihun Choi, Youngmin Im, Jaeyoung Wi, Kihong Heo, Sangeun Oh, Sunjae Lee, and Insik Shin. 2025. VeriSafe Agent: Safeguarding Mobile GUI Agent via Logic-based Action Verifi- cation. InProceedings of the 31st Annual International Conference on Mobile Computing and Networking(Kerry Hotel, Hong Kong, Hong Y. Im, B. Jo, et al., Young...
-
[15]
Sunjae Lee, Junyoung Choi, Jungjae Lee, Munim Hasan Wasi, Ho- jun Choi, Steve Ko, Sangeun Oh, and Insik Shin. 2024. MobileGPT: Augmenting LLM with Human-like App Memory for Mobile Task Automation. InProceedings of the 30th Annual International Conference on Mobile Computing and Networking(Washington D.C., DC, USA) (ACM MobiCom ’24). Association for Comput...
- [16]
- [17]
-
[18]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. 2023. Self-refine: Iterative refinement with self- feedback.Advances in Neural Information Processing Systems36 (2023), 46534–46594
work page 2023
- [19]
-
[20]
2025.GPT-5.1: A smarter, more conversational ChatGPT
openai. 2025.GPT-5.1: A smarter, more conversational ChatGPT. openai. Retrieved 11 12, 2025 from https://openai.com/index/gpt-5-1/
work page 2025
-
[21]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
work page 2023
-
[22]
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xiaojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen, Zhaojian Li, Haihua Ya...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Qualcomm. 2023.EasyOCR. Qualcomm. Retrieved Nov 11, 2025 from https://aihub.qualcomm.com/models/easyocr
work page 2023
-
[24]
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya Tya- magundlu, Timothy Lillicrap, and Oriana Riva. 2024. AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents. arXiv:2405.14573 [cs.AI] https://...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. 2023. Android in the wild: a large-scale dataset for android device control. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Article 2609, 21 pages
work page 2023
- [26]
-
[27]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal rein- forcement learning.Advances in Neural Information Processing Systems 36 (2023), 8634–8652
work page 2023
-
[28]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [29]
-
[30]
Jianqiang Wan, Sibo Song, Wenwen Yu, Yuliang Liu, Wenqing Cheng, Fei Huang, Xiang Bai, Cong Yao, and Zhibo Yang. 2024. Omniparser: A unified framework for text spotting key information extraction and table recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15641–15653
work page 2024
-
[31]
Bryan Wang, Gang Li, and Yang Li. 2023. Enabling Conversational In- teraction with Mobile UI using Large Language Models. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (Hamburg, Germany)(CHI ’23). Association for Computing Machin- ery, New York, NY, USA, Article 432, 17 pages. doi:10.1145/3544548. 3580895
-
[32]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voy- ager: An Open-Ended Embodied Agent with Large Language Models. arXiv:2305.16291 [cs.AI] https://arxiv.org/abs/2305.16291
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. 2024. Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi- agent collaboration.Advances in Neural Information Processing Systems 37 (2024), 2686–2710
work page 2024
- [34]
- [35]
-
[36]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain- of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903 [cs.CL] https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [37]
- [38]
-
[39]
Jason Wu, Xiaoyi Zhang, Jeff Nichols, and Jeffrey P Bigham. 2021. Screen parsing: Towards reverse engineering of ui models from screen- shots. InThe 34th Annual ACM Symposium on User Interface Software and Technology. 470–483
work page 2021
- [40]
-
[41]
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. 2024. Os-atlas: A foundation action model for generalist gui agents.arXiv preprint arXiv:2410.23218(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Xiaoxin Chen, Aojun Zhou, and Hongsheng Li
Han Xiao, Guozhi Wang, Yuxiang Chai, Zimu Lu, Weifeng Lin, Hao He, Lue Fan, Liuyang Bian, Rui Hu, Liang Liu, Shuai Ren, Yafei Wen, preprint. Xiaoxin Chen, Aojun Zhou, and Hongsheng Li. 2025. UI-Genie: A Self- Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents. arXiv:2505.21496 [cs.CL] https://arxiv.org/abs/2505.21496
- [43]
- [44]
- [45]
-
[46]
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. 2024. Aguvis: Unified pure vision agents for autonomous gui interaction.arXiv preprint arXiv:2412.04454(2024)
work page internal anchor Pith review arXiv 2024
-
[47]
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. 2023. Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V. arXiv:2310.11441 [cs.CV] https://arxiv. org/abs/2310.11441
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR)
work page 2023
-
[49]
Jiabo Ye, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Zhaoqing Zhu, Ziwei Zheng, Feiyu Gao, Junjie Cao, Zhengxi Lu, Jitong Liao, Qi Zheng, Fei Huang, Jingren Zhou, and Ming Yan. 2025. Mobile-Agent- v3: Fundamental Agents for GUI Automation. arXiv:2508.15144 [cs.AI] https://arxiv.org/abs/2508.15144
work page internal anchor Pith review arXiv 2025
-
[50]
Wenwen Yu, Zhibo Yang, Jianqiang Wan, Sibo Song, Jun Tang, Wenqing Cheng, Yuliang Liu, and Xiang Bai. 2025. OmniParser V2: Structured-Points-of-Thought for Unified Visual Text Pars- ing and Its Generality to Multimodal Large Language Models. arXiv:2502.16161 [cs.CV] https://arxiv.org/abs/2502.16161
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. 2025. Appagent: Multimodal agents as smartphone users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–20
work page 2025
-
[52]
Danyang Zhang, Zhennan Shen, Rui Xie, Situo Zhang, Tianbao Xie, Zihan Zhao, Siyuan Chen, Lu Chen, Hongshen Xu, Ruisheng Cao, and Kai Yu. 2024. Mobile-Env: Building Qualified Evaluation Benchmarks for LLM-GUI Interaction. arXiv:2305.08144 [cs.AI] https://arxiv.org/ abs/2305.08144
- [54]
-
[55]
Li Zhang, Shihe Wang, Xianqing Jia, Zhihan Zheng, Yunhe Yan, Longxi Gao, Yuanchun Li, and Mengwei Xu. 2024. Llamatouch: A faithful and scalable testbed for mobile ui task automation. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–13
work page 2024
-
[56]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. 2022. Least-to-most prompting enables complex reasoning in large language models.arXiv preprint arXiv:2205.10625(2022). Y. Im, B. Jo, et al., Youngmin Im, Byeongung Jo, Jaeyoung Wi, Tae Hoon Min, Seungwoo Baek, Joo H...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[61]
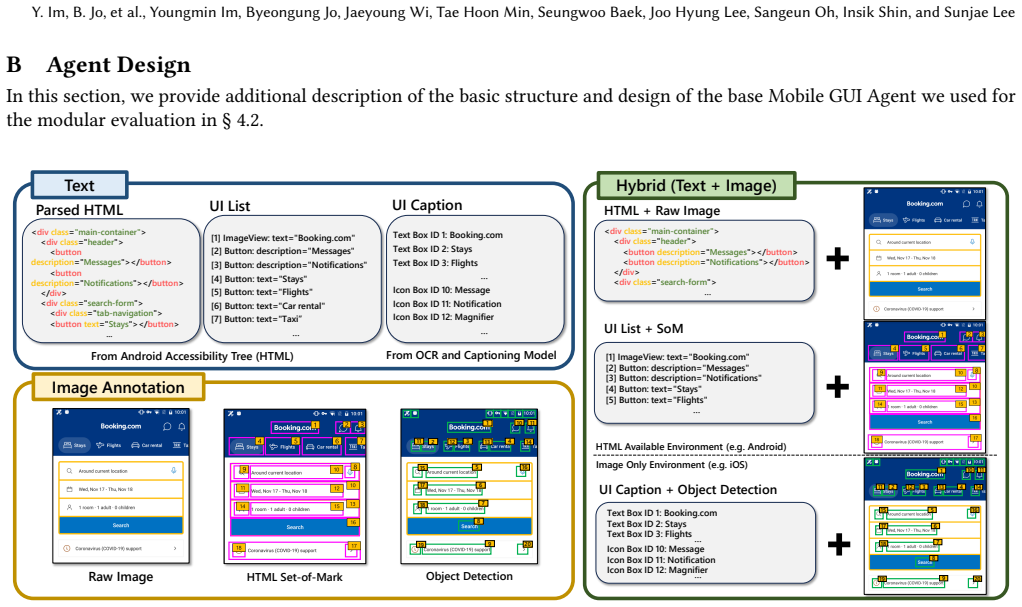
Button: text="Flights" … <div class="main-container"> <div class="header"> <button description="Messages"></button> <button description="Notifications"></button> </div> <div class="search-form"> … Text Image Annotation Hybrid (Text + Image) UI List Parsed HTML
- [62]
- [63]
- [64]
-
[65]
Button: text="Stays"
-
[66]
Button: text="Flights"
- [67]
-
[68]
Button: text="Taxi” … <div class="main-container"> <div class="header"> <button description="Messages"></button> <button description="Notifications"></button> </div> <div class="search-form"> <div class="tab-navigation"> <button text="Stays"></button> ... UI Caption Text Box ID 1: Booking.com Text Box ID 2: Stays Text Box ID 3: Flights … Icon Box ID 10: M...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.