Recognition: 2 theorem links
· Lean TheoremCausalEmbed: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding
Pith reviewed 2026-05-16 10:11 UTC · model grok-4.3
The pith
Auto-regressive generation in latent space creates compact multi-vector embeddings that cut visual document token counts by 30-155 times while preserving retrieval accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
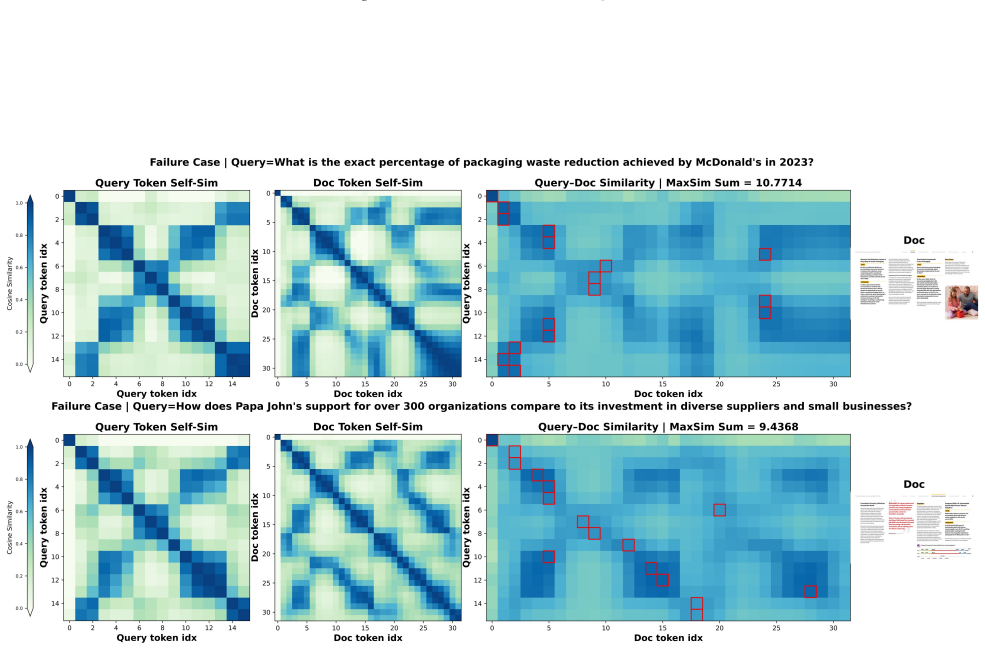
CausalEmbed uses an auto-regressive approach to generate multi-vector embeddings directly in latent space, combined with iterative margin loss during contrastive training, enabling efficient visual document retrieval with dramatically fewer tokens. This yields a 30-155x reduction in token count while maintaining highly competitive performance across various backbones and benchmarks, with theoretical analysis confirming gains in training efficiency and test-time scalability.
What carries the argument
CausalEmbed, the auto-regressive multi-vector generation process in latent space that uses iterative margin loss in contrastive training to produce compact, structured embeddings.
Load-bearing premise
Auto-regressive generation in latent space combined with iterative margin loss during contrastive training produces embeddings that remain information-rich enough for retrieval despite the drastic token reduction.
What would settle it
Retrieval accuracy on standard visual document benchmarks drops substantially below existing multi-vector baselines when the method is restricted to only dozens of tokens per page.
Figures









read the original abstract
Although Multimodal Large Language Models (MLLMs) have shown remarkable potential in Visual Document Retrieval (VDR) through generating high-quality multi-vector embeddings, the substantial storage overhead caused by representing a page with thousands of visual tokens limits their practicality in real-world applications. To address this challenge, we propose an auto-regressive generation approach, CausalEmbed, for constructing multi-vector embeddings. By incorporating iterative margin loss during contrastive training, CausalEmbed encourages the embedding models to learn compact and well-structured representations. Our method enables efficient VDR tasks using only dozens of visual tokens, achieving a 30-155x reduction in token count while maintaining highly competitive performance across various backbones and benchmarks. Theoretical analysis and empirical results demonstrate the unique advantages of auto-regressive embedding generation in terms of training efficiency and scalability at test time. As a result, CausalEmbed introduces a flexible test-time scaling strategy for multi-vector VDR representations and sheds light on the generative paradigm within multimodal document retrieval. Our code is available at https://github.com/Z1zs/Causal-Embed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CausalEmbed, an auto-regressive generation method in latent space to produce compact multi-vector embeddings for visual document retrieval (VDR). It incorporates iterative margin loss in contrastive training to encourage structured representations, claiming a 30-155x reduction in visual token count (from thousands to dozens) while achieving competitive performance across backbones and benchmarks. The work includes theoretical analysis of training efficiency and test-time scalability, plus a flexible scaling strategy, with code released.
Significance. If the performance claims hold under rigorous verification, the approach would meaningfully advance practical VDR by addressing storage and compute bottlenecks in MLLM-based multi-vector embeddings. The generative paradigm and test-time scaling are novel angles that could influence retrieval system design; code availability strengthens reproducibility.
major comments (2)
- [Abstract and Experiments] The central claim of 30-155x token reduction while preserving retrieval performance (abstract) rests on the untested premise that auto-regressive latent generation plus iterative margin loss retains fine-grained layout information (e.g., table alignments, figure-text relations). No information-theoretic bound or ablation isolating layout fidelity is described, which is load-bearing for the competitiveness assertion.
- [Theoretical Analysis] Theoretical analysis of training efficiency and scalability is referenced but lacks explicit derivation or comparison to non-autoregressive baselines; this weakens the claim that the method introduces unique advantages (abstract).
minor comments (2)
- [Abstract] Clarify the exact definition of 'visual tokens' and how the 30-155x reduction is computed (e.g., per-page average, specific backbone).
- [Experiments] Add error bars, data split details, and backbone-specific ablation tables to support the 'highly competitive performance' statement.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We agree that strengthening the empirical and theoretical support for our claims will improve the manuscript. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Abstract and Experiments] The central claim of 30-155x token reduction while preserving retrieval performance (abstract) rests on the untested premise that auto-regressive latent generation plus iterative margin loss retains fine-grained layout information (e.g., table alignments, figure-text relations). No information-theoretic bound or ablation isolating layout fidelity is described, which is load-bearing for the competitiveness assertion.
Authors: We agree that an explicit ablation isolating layout fidelity would provide stronger evidence. While our reported competitive results on standard VDR benchmarks (which include documents with complex tables, figures, and cross-modal relations) offer indirect support, these do not fully isolate the contribution. In the revised manuscript we will add a targeted ablation on layout-sensitive document subsets together with a short information-theoretic discussion of the multi-vector capacity under the auto-regressive generation scheme. revision: yes
-
Referee: [Theoretical Analysis] Theoretical analysis of training efficiency and scalability is referenced but lacks explicit derivation or comparison to non-autoregressive baselines; this weakens the claim that the method introduces unique advantages (abstract).
Authors: We acknowledge the need for greater rigor. The current theoretical discussion is high-level; we will expand the section and appendix with explicit derivations of the training-efficiency and test-time scaling advantages. We will also add a direct comparison (both analytically and empirically) against non-autoregressive multi-vector baselines to clarify the unique benefits of the auto-regressive latent generation approach. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes CausalEmbed as an empirical method combining auto-regressive latent generation with iterative margin loss for compact multi-vector embeddings. Performance claims (30-155x token reduction, competitive VDR results) rest on benchmark experiments and stated theoretical analysis rather than any reduction of outputs to fitted inputs or self-citations by construction. No equations or steps in the abstract or description equate predictions to training data by definition, and the central premise is externally falsifiable via retrieval metrics on held-out benchmarks. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
zk = τ(Ψ([C, z1, …, zk−1])) … Ld = −[S(q,d+1:Nd)−S(q,d+1)] + … Lq penalizes cosine similarity
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
contrastive objective Lm … progressive refinement and diversity regularization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Visual Late Chunking: An Empirical Study of Contextual Chunking for Efficient Visual Document Retrieval
ColChunk adaptively chunks visual document patches into contextual multi-vectors via clustering, cutting storage by over 90% while raising average nDCG@5 by 9 points.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
URLhttps://arxiv.org/abs/2404.14219. Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://huggingface.co/ApsaraSta ckMaaS/EvoQwen2.5-VL-Retriever-3B-v1. Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S., Lu, D., Lu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Beyer*, L., Steiner*, A., Pinto*, A
URL https: //arxiv.org/abs/2501.02235. Beyer*, L., Steiner*, A., Pinto*, A. S., Kolesnikov*, A., Wang*, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., Unterthiner, T., Key- sers, D., Koppula, S., Liu, F., Grycner, A., Gritsenko, A., Houlsby, N., Kumar, M., Rong, K., Eisenschlos, J., Kabra, R., Bauer, M., Boˇsnjak, M., Chen, ...
-
[4]
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., 9 CAUSALEMBED: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
work page 1901
-
[5]
Cha, S., Kim, D., Kim, M., Han, Y ., Jeon, B.-K., and Lee, S. Reinpool: Reinforcement learning pooling multi- vector embeddings for retrieval system.arXiv preprint arXiv:2601.07125,
-
[6]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., and Ruan, C. Janus-pro: Unified multimodal understand- ing and generation with data and model scaling.arXiv preprint arXiv:2501.17811,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Think then embed: Generative context improves multimodal embedding.arXiv preprint arXiv:2510.05014,
Cui, X., Cheng, J., Chen, H.-y., Shukla, S. N., Awasthi, A., Pan, X., Ahuja, C., Mishra, S. K., Yang, Y ., Xiao, J., et al. Think then embed: Generative context improves mul- timodal embedding.arXiv preprint arXiv:2510.05014, 2025a. Cui, X., Cheng, J., Chen, H.-y., Shukla, S. N., Awasthi, A., Pan, X., Ahuja, C., Mishra, S. K., Yang, Y ., Xiao, J., et al. ...
-
[8]
Gao, S., Zhao, S., Jiang, X., Duan, L., Chng, Y . X., Chen, Q.-G., Luo, W., Zhang, K., Bian, J.-W., and Gong, M. Scaling beyond context: A survey of multimodal retrieval- augmented generation for document understanding.arXiv preprint arXiv:2510.15253,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
K., Mohr, I., Ungureanu, A., Wang, B., Eslami, S., Martens, S., Werk, M., Wang, N., et al
G¨unther, M., Sturua, S., Akram, M. K., Mohr, I., Ungureanu, A., Wang, B., Eslami, S., Martens, S., Werk, M., Wang, N., et al. jina-embeddings-v4: Universal embeddings for multimodal multilingual retrieval. InProceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025), pp. 531–550,
work page 2025
-
[11]
Training Large Language Models to Reason in a Continuous Latent Space
Hao, S., Sukhbaatar, S., Su, D., Li, X., Hu, Z., Weston, J., and Tian, Y . Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Rzenembed: Towards comprehensive multimodal retrieval.arXiv preprint arXiv:2510.27350,
Jian, W., Zhang, Y ., Liang, D., Xie, C., He, Y ., Leng, D., and Yin, Y . Rzenembed: Towards comprehensive multimodal retrieval.arXiv preprint arXiv:2510.27350,
-
[13]
Jiang, Z., Meng, R., Yang, X., Yavuz, S., Zhou, Y ., and Chen, W. Vlm2vec: Training vision-language models for massive multimodal embedding tasks.arXiv preprint arXiv:2410.05160,
-
[14]
URL https://arxiv.org/abs/2512.03514. Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V ., Howard-Snyder, W., Chen, K., Kakade, S., Jain, P., et al. Matryoshka representation learning.Advances in Neural Information Processing Systems, 35:30233–30249, 2022a. Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan,...
-
[15]
Li, D., Luo, Y ., Bi, K., Guo, J., Yuan, W., Yang, B., Wang, Y ., Yang, F., Gao, T., and Zhou, G. Compression then 10 CAUSALEMBED: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding matching: An efficient pre-training paradigm for mul- timodal embedding.arXiv preprint arXiv:2511.08480,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Li, M., Zhang, Y ., Long, D., Keqin, C., Song, S., Bai, S., Yang, Z., Xie, P., Yang, A., Liu, D., Zhou, J., and Lin, J. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.arXiv preprint arXiv:2601.04720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Causal2Vec: Improving Decoder-only LLMs as Embedding Models through a Contextual Token
Lin, A., Li, Z., Funakoshi, K., and Okumura, M. Causal2vec: Improving decoder-only llms as versatile embedding mod- els.arXiv preprint arXiv:2507.23386,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Liu, C., Yang, J., Gao, R., Zhu, Y ., Zhu, F., Zhao, R., and Wang, L. Reasoning guided embeddings: Leveraging mllm reasoning for improved multimodal retrieval.arXiv preprint arXiv:2511.16150, 2025a. Liu, K., Li, J., Sun, Y ., Wu, S., jianzhang gao, Zhang, D., Zhang, W., Jin, S., Yu, S., Zhan, G., Ji, J., Zhou, F., Zheng, L., Y AN, S., Fei, H., and Chua, T...
-
[19]
Unifying multimodal retrieval via document screenshot embedding
Ma, X., Lin, S.-C., Li, M., Chen, W., and Lin, J. Unifying multimodal retrieval via document screenshot embedding. arXiv preprint arXiv:2406.11251,
-
[20]
Ma, Y ., Li, J., Zang, Y ., Wu, X., Dong, X., Zhang, P., Cao, Y ., Duan, H., Wang, J., Cao, Y ., et al. Towards storage-efficient visual document retrieval: An empirical study on reducing patch-level embeddings.arXiv preprint arXiv:2506.04997, 2025a. Ma, Y ., Li, J., Zang, Y ., Wu, X., Dong, X., Zhang, P., Cao, Y ., Duan, H., Wang, J., Cao, Y ., et al. To...
-
[21]
Meng, R., Jiang, Z., Liu, Y ., Su, M., Yang, X., Fu, Y ., Qin, C., Chen, Z., Xu, R., Xiong, C., et al. Vlm2vec-v2: Advancing multimodal embedding for videos, images, and visual documents.arXiv preprint arXiv:2507.04590,
-
[22]
R., Biswas, A., and O’Malley, D
Most, A., Winjum, J., Bhattarai, M., Jones, S., Ranasinghe, N. R., Biswas, A., and O’Malley, D. Lost in ocr trans- lation? vision-based approaches to robust document re- trieval. InProceedings of the 2025 ACM Symposium on Document Engineering, pp. 1–10,
work page 2025
-
[23]
Learning Transferable Visual Models From Natural Language Supervision
URLhttps://arxiv.org/abs/2103.00020. Santhanam, K., Khattab, O., Saad-Falcon, J., Potts, C., and Zaharia, M. Colbertv2: Effective and efficient retrieval via lightweight late interaction. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies, pp. 3715–3734,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
An overview of the tesseract ocr engine
Smith, R. An overview of the tesseract ocr engine. In Ninth international conference on document analysis and recognition (ICDAR 2007), volume 2, pp. 629–633. IEEE,
work page 2007
-
[25]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y ., Chen, S., Zhang, S., Peng, B., Luo, P., and Yuan, Z. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Sori- cut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ram ´e, A., 11 CAUSALEMBED: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding Rivi`ere, M., et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Tsai, Y .-C., Chen, K.-Y ., Li, Y .-C., Chen, Y .-H., Tsai, C.- Y ., and Lin, S.-D. Let llms speak embedding languages: Generative text embeddings via iterative contrastive re- finement.arXiv preprint arXiv:2509.24291,
-
[29]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
URL https://arxiv.org/abs/2409.12191. Ward Jr, J. H. Hierarchical grouping to optimize an objective function.Journal of the American statistical association, 58(301):236–244,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Xiao, Z., Ma, Q., Gu, M., Chen, C.-c. J., Chen, X., Ordonez, V ., and Mohan, V . Metaembed: Scaling multimodal retrieval at test-time with flexible late interaction.arXiv preprint arXiv:2509.18095,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Llama nemoretriever colembed: Top-performing text-image retrieval model
Xu, M., Moreira, G., Ak, R., Osmulski, R., Babakhin, Y ., Yu, Z., Schifferer, B., and Oldridge, E. Llama nemoretriever colembed: Top-performing text-image retrieval model. arXiv preprint arXiv:2507.05513,
-
[32]
Yan, Y ., Xu, G., Zou, X., Liu, S., Kwok, J., and Hu, X. Docpruner: A storage-efficient framework for multi- vector visual document retrieval via adaptive patch-level embedding pruning.arXiv preprint arXiv:2509.23883,
-
[33]
Yu, H., Zhao, Z., Yan, S., Korycki, L., Wang, J., He, B., Liu, J., Zhang, L., Fan, X., and Yu, H. Cafe: Unifying repre- sentation and generation with contrastive-autoregressive finetuning.arXiv preprint arXiv:2503.19900,
-
[34]
Ocr hinders rag: Evaluating the cascading impact of ocr on retrieval- augmented generation
Zhang, J., Zhang, Q., Wang, B., Ouyang, L., Wen, Z., Li, Y ., Chow, K.-H., He, C., and Zhang, W. Ocr hinders rag: Evaluating the cascading impact of ocr on retrieval- augmented generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 17443– 17453, 2025a. Zhang, K., Li, J., Li, Z., Zhang, J., Li, F., Liu, Y ., Yan, R., Jia...
-
[35]
GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
Zhang, X., Zhang, Y ., Xie, W., Li, M., Dai, Z., Long, D., Xie, P., Zhang, M., Li, W., and Zhang, M. Gme: Improving universal multimodal retrieval by multimodal llms.arXiv preprint arXiv:2412.16855,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Zheng, X., Weng, Z., Lyu, Y ., Jiang, L., Xue, H., Ren, B., Paudel, D., Sebe, N., Van Gool, L., and Hu, X. Retrieval augmented generation and understanding in vision: A sur- vey and new outlook.arXiv preprint arXiv:2503.18016,
-
[37]
VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval
Zhou, J., Liu, Z., Xiao, S., Zhao, B., and Xiong, Y . Vista: Visualized text embedding for universal multi-modal re- trieval.arXiv preprint arXiv:2406.04292,
-
[38]
Starbucks-v2: Improved training for 2d matryoshka embeddings.arXiv preprint arXiv:2410.13230,
Zhuang, S., Wang, S., Zheng, F., Koopman, B., and Zuccon, G. Starbucks-v2: Improved training for 2d matryoshka embeddings.arXiv preprint arXiv:2410.13230,
-
[39]
C. More Related Work C.1. Autoregressive Generation Autoregressive generation is the cornerstone paradigm for modern, high-performing LLMs (Achiam et al., 2023; Team et al., 2023; Guo et al., 2025). While this paradigm dominates natural language generation, several works have begun to explore its adoption in computer vision (Sun et al., 2024; Tian et al.,...
work page 2023
-
[40]
introduces a coarse-to-finenext-scale (resolution)prediction strategy, enabling efficient learning of visual distributions and strong generalization capabilities in autoregressive transformers. Moreover, recent research has increasingly focused on building unified models that combine both understanding and generation (Wu et al., 2025; Chen et al., 2025; L...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.