Recognition: no theorem link
Toward Reliable Sim-to-Real Predictability for MoE-based Robust Quadrupedal Locomotion
Pith reviewed 2026-05-16 08:56 UTC · model grok-4.3
The pith
A gated Mixture-of-Experts policy paired with sim-to-sim metrics lets quadruped controllers transfer reliably to real hardware on unseen rough terrain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
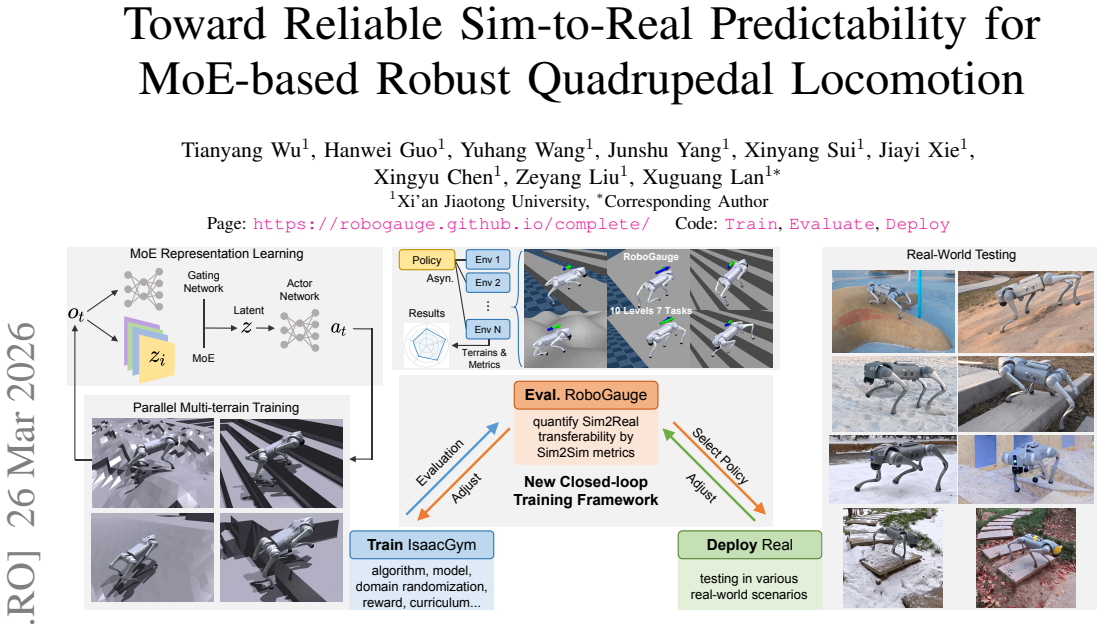
The central claim is that an MoE locomotion policy, whose gated experts decompose latent terrain features and velocity commands, achieves stronger robustness and generalization when selected by RoboGauge's multi-dimensional proprioception metrics obtained from controlled sim-to-sim trials across terrains, difficulty levels, and randomizations. This combination allows reliable deployment on a Unitree Go2 without extensive physical validation, as shown by successful traversal of snow, sand, stairs, slopes, and 30 cm obstacles plus sustained speeds of 4 m/s with an emergent narrow-width gait.
What carries the argument
Mixture-of-Experts policy whose gated specialist experts decompose latent terrain and command modeling, together with RoboGauge's proprioception-based sim-to-sim metrics for predictive policy selection.
If this is right
- The MoE policy delivers superior robustness and generalization from proprioception alone on multi-terrain tasks.
- RoboGauge metrics enable policy selection that avoids most physical trial-and-error.
- The selected policies handle previously unseen surfaces including snow, sand, stairs, slopes, and 30 cm obstacles.
- High-speed runs reach 4 m/s while producing a stable narrow-width gait that emerges without explicit reward shaping.
- The framework reduces the cost and risk of moving reinforcement-learned controllers from simulation to hardware.
Where Pith is reading between the lines
- The same expert-decomposition idea could be tested on bipeds or wheeled platforms to check whether the sim-to-real predictability generalizes beyond quadrupeds.
- If RoboGauge scores prove consistent across robot platforms, future work could replace part of today's heavy domain randomization with targeted metric-guided training.
- The appearance of a narrow gait at high speed suggests that stability at velocity may arise from the policy architecture itself rather than from hand-crafted reward terms.
- RoboGauge-style predictive suites might be adapted to manipulation or navigation tasks where physical resets are equally expensive.
Load-bearing premise
RoboGauge's multi-dimensional proprioception-based sim-to-sim metrics accurately forecast which policies will transfer and remain robust on physical hardware without needing physical validation.
What would settle it
A side-by-side physical test on the Unitree Go2 in which a policy ranked highest by RoboGauge metrics fails to complete the reported terrain suite while a lower-ranked policy succeeds would falsify the predictive claim.
Figures
















read the original abstract
Reinforcement learning has shown strong promise for quadrupedal agile locomotion, even with proprioception-only sensing. In practice, however, sim-to-real gap and reward overfitting in complex terrains can produce policies that fail to transfer, while physical validation remains risky and inefficient. To address these challenges, we introduce a unified framework encompassing a Mixture-of-Experts (MoE) locomotion policy for robust multi-terrain representation with RoboGauge, a predictive assessment suite that quantifies sim-to-real transferability. The MoE policy employs a gated set of specialist experts to decompose latent terrain and command modeling, achieving superior deployment robustness and generalization via proprioception alone. RoboGauge further provides multi-dimensional proprioception-based metrics via sim-to-sim tests over terrains, difficulty levels, and domain randomizations, enabling reliable MoE policy selection without extensive physical trials. Experiments on a Unitree Go2 demonstrate robust locomotion on unseen challenging terrains, including snow, sand, stairs, slopes, and 30 cm obstacles. In dedicated high-speed tests, the robot reaches 4 m/s and exhibits an emergent narrow-width gait associated with improved stability at high velocity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Mixture-of-Experts (MoE) locomotion policy for quadrupedal robots that uses gated specialist experts to model terrain and commands, paired with RoboGauge, a suite of multi-dimensional proprioception-based sim-to-sim metrics intended to predict sim-to-real transferability and enable policy selection without extensive physical trials. Real-world experiments on a Unitree Go2 are reported to demonstrate robust locomotion on unseen terrains (snow, sand, stairs, slopes, 30 cm obstacles) at speeds up to 4 m/s with an emergent narrow-width gait.
Significance. If the predictive validity of RoboGauge holds, the framework would meaningfully advance efficient sim-to-real workflows in robotics by reducing reliance on risky hardware validation for RL policies. The reported hardware results on diverse challenging terrains provide concrete evidence of the MoE policy's practical robustness and generalization from proprioception alone.
major comments (2)
- [RoboGauge description and Experiments] The central claim that RoboGauge's sim-to-sim metrics reliably forecast sim-to-real transferability (and thus enable selection of successful MoE policies) is not supported by any quantitative correlation analysis between the multi-dimensional metrics and real-world outcomes such as success rate or achieved velocity. The manuscript reports successful Unitree Go2 deployment but provides no Pearson r, regression, or statistical validation linking RoboGauge scores to physical performance.
- [Experiments on Unitree Go2] No controlled ablation or baseline comparison is presented to isolate the contribution of RoboGauge-based selection from the MoE architecture itself; without this, it remains unclear whether the reported robustness stems from the predictive framework or from the policy design and training.
minor comments (2)
- [Abstract and Methods] The abstract and methods sections omit full training details, exact definitions of the multi-dimensional RoboGauge metrics, aggregation procedure for policy selection, and error analysis, all of which are required for reproducibility.
- [Method] Notation for the MoE gating mechanism and the precise proprioceptive inputs used in RoboGauge should be clarified with explicit equations or pseudocode to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have incorporated revisions to provide stronger quantitative support for our claims.
read point-by-point responses
-
Referee: [RoboGauge description and Experiments] The central claim that RoboGauge's sim-to-sim metrics reliably forecast sim-to-real transferability (and thus enable selection of successful MoE policies) is not supported by any quantitative correlation analysis between the multi-dimensional metrics and real-world outcomes such as success rate or achieved velocity. The manuscript reports successful Unitree Go2 deployment but provides no Pearson r, regression, or statistical validation linking RoboGauge scores to physical performance.
Authors: We agree that a quantitative correlation analysis would provide stronger evidence for RoboGauge's predictive validity. In the revised manuscript we will add a dedicated analysis section that computes Pearson correlation coefficients (and associated p-values) between each RoboGauge dimension and the observed real-world success rates and peak velocities across the evaluated policies. This will directly link the sim-to-sim metrics to hardware outcomes. revision: yes
-
Referee: [Experiments on Unitree Go2] No controlled ablation or baseline comparison is presented to isolate the contribution of RoboGauge-based selection from the MoE architecture itself; without this, it remains unclear whether the reported robustness stems from the predictive framework or from the policy design and training.
Authors: We acknowledge that the current experiments do not isolate RoboGauge's contribution via controlled ablation. In the revision we will add an ablation study comparing RoboGauge-selected MoE policies against (i) MoE policies chosen solely by aggregate sim-to-sim reward and (ii) randomly selected MoE policies, reporting transfer success rates and velocity on the same hardware terrains. This will clarify the incremental benefit of the predictive selection framework. revision: yes
Circularity Check
No significant circularity; claims rest on independent sim-to-sim metrics and physical experiments
full rationale
The paper trains an MoE policy and defines RoboGauge metrics from separate sim-to-sim tests across terrains, difficulties, and domain randomizations. Policy selection uses these metrics, but real-world results on the Unitree Go2 (4 m/s, snow/sand/stairs/obstacles) are reported as direct empirical outcomes rather than derived from the metrics by construction. No equation reduces a prediction to a fitted parameter, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled in. The framework is self-contained against external physical benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Oussama Khatib. Real-time obstacle avoidance for ma- nipulators and mobile robots.The international journal of robotics research, 5(1):90–98, 1986
work page 1986
-
[2]
Sertac Karaman and Emilio Frazzoli. Sampling-based al- gorithms for optimal motion planning.The international journal of robotics research, 30(7):846–894, 2011
work page 2011
-
[3]
Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
Jemin Hwangbo, Joonho Lee, Alexey Dosovitskiy, Dario Bellicoso, Vassilios Tsounis, Vladlen Koltun, and Marco Hutter. Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
work page 2019
-
[4]
Russell Buchanan, Lorenz Wellhausen, Marko Bjelonic, Tirthankar Bandyopadhyay, Navinda Kottege, and Marco Hutter. Perceptive whole-body planning for multilegged robots in confined spaces.Journal of Field Robotics, 38 (1):68–84, 2021
work page 2021
-
[5]
Learning to walk in the real world with minimal human effort
Sehoon Ha, Peng Xu, Zhenyu Tan, Sergey Levine, and Jie Tan. Learning to walk in the real world with minimal human effort. InConference on Robot Learning, pages 1110–1120. PMLR, 2021
work page 2021
-
[6]
Legged robots that keep on learning: Fine-tuning locomotion policies in the real world
Laura Smith, J Chase Kew, Xue Bin Peng, Sehoon Ha, Jie Tan, and Sergey Levine. Legged robots that keep on learning: Fine-tuning locomotion policies in the real world. In2022 international conference on robotics and automation (ICRA), pages 1593–1599. IEEE, 2022
work page 2022
-
[7]
Robust autonomous navigation of a small-scale quadruped robot in real-world environments
Thomas Dudzik, Matthew Chignoli, Gerardo Bledt, Bryan Lim, Adam Miller, Donghyun Kim, and Sangbae Kim. Robust autonomous navigation of a small-scale quadruped robot in real-world environments. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3664–3671. IEEE, 2020
work page 2020
-
[8]
Collision-free mpc for legged robots in static and dynamic scenes
Magnus Gaertner, Marko Bjelonic, Farbod Farshidian, and Marco Hutter. Collision-free mpc for legged robots in static and dynamic scenes. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 8266–8272. IEEE, 2021
work page 2021
-
[9]
A collision-free mpc for whole-body dynamic locomotion and manipulation
Jia-Ruei Chiu, Jean-Pierre Sleiman, Mayank Mittal, Far- bod Farshidian, and Marco Hutter. A collision-free mpc for whole-body dynamic locomotion and manipulation. In2022 international conference on robotics and au- tomation (ICRA), pages 4686–4693. IEEE, 2022
work page 2022
-
[10]
David Hoeller, Lorenz Wellhausen, Farbod Farshidian, and Marco Hutter. Learning a state representation and navigation in cluttered and dynamic environments.IEEE Robotics and Automation Letters, 6(3):5081–5088, 2021
work page 2021
-
[11]
Vision aided dynamic exploration of unstructured terrain with a small-scale quadruped robot
Donghyun Kim, Daniel Carballo, Jared Di Carlo, Ben- jamin Katz, Gerardo Bledt, Bryan Lim, and Sangbae Kim. Vision aided dynamic exploration of unstructured terrain with a small-scale quadruped robot. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 2464–2470. IEEE, 2020
work page 2020
-
[12]
Qiayuan Liao, Zhongyu Li, Akshay Thirugnanam, Jun Zeng, and Koushil Sreenath. Walking in narrow spaces: Safety-critical locomotion control for quadrupedal robots with duality-based optimization. In2023 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), pages 2723–2730. IEEE, 2023
work page 2023
-
[13]
Matias Mattamala, Nived Chebrolu, and Maurice Fallon. An efficient locally reactive controller for safe navigation in visual teach and repeat missions.IEEE Robotics and Automation Letters, 7(2):2353–2360, 2022
work page 2022
-
[14]
Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers
Ruihan Yang, Minghao Zhang, Nicklas Hansen, Huazhe Xu, and Xiaolong Wang. Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers. InDeep RL Workshop NeurIPS 2021
work page 2021
-
[15]
Resilient legged local navigation: Learning to traverse with com- promised perception end-to-end
Chong Zhang, Jin Jin, Jonas Frey, Nikita Rudin, Mat ´ıas Mattamala, Cesar Cadena, and Marco Hutter. Resilient legged local navigation: Learning to traverse with com- promised perception end-to-end. In2024 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 34–41. IEEE, 2024
work page 2024
-
[16]
Learning quadrupedal locomotion over challenging terrain.Science robotics, 5 (47):eabc5986, 2020
Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning quadrupedal locomotion over challenging terrain.Science robotics, 5 (47):eabc5986, 2020
work page 2020
-
[17]
Rma: Rapid motor adaptation for legged robots
Ashish Kumar, Zipeng Fu, Deepak Pathak, and Jitendra Malik. Rma: Rapid motor adaptation for legged robots. Robotics: Science and Systems XVII, 2021
work page 2021
-
[18]
Leveraging symmetry in rl-based legged locomotion control
Zhi Su, Xiaoyu Huang, Daniel Ordo ˜nez-Apraez, Yunfei Li, Zhongyu Li, Qiayuan Liao, Giulio Turrisi, Massim- iliano Pontil, Claudio Semini, Yi Wu, et al. Leveraging symmetry in rl-based legged locomotion control. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6899–6906. IEEE, 2024
work page 2024
-
[19]
Gwanghyeon Ji, Juhyeok Mun, Hyeongjun Kim, and Jemin Hwangbo. Concurrent training of a control policy and a state estimator for dynamic and robust legged locomotion.IEEE Robotics and Automation Letters, 7 (2):4630–4637, 2022
work page 2022
-
[20]
Jinze Wu, Guiyang Xin, Chenkun Qi, and Yufei Xue. Learning robust and agile legged locomotion using ad- versarial motion priors.IEEE Robotics and Automation Letters, 8(8):4975–4982, 2023
work page 2023
-
[21]
Daydreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
work page 2023
-
[22]
Learning to walk in minutes using massively parallel deep reinforcement learning
Nikita Rudin, David Hoeller, Philipp Reist, and Marco Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InConference on robot learning, pages 91–100. PMLR, 2022
work page 2022
-
[23]
Takahiro Miki, Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning robust perceptive locomotion for quadrupedal robots in the wild.Science robotics, 7(62):eabk2822, 2022
work page 2022
-
[24]
I Made Aswin Nahrendra, Byeongho Yu, and Hyun Myung. Dreamwaq: Learning robust quadrupedal lo- comotion with implicit terrain imagination via deep reinforcement learning. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5078–5084. IEEE, 2023
work page 2023
-
[25]
Hybrid internal model: Learning agile legged locomotion with simulated robot response
Junfeng Long, Zirui Wang, Quanyi Li, Liu Cao, Jiawei Gao, and Jiangmiao Pang. Hybrid internal model: Learning agile legged locomotion with simulated robot response. InICLR, 2024
work page 2024
-
[26]
Rapid locomotion via reinforcement learning
Gabriel B Margolis, Ge Yang, Kartik Paigwar, Tao Chen, and Pulkit Agrawal. Rapid locomotion via reinforcement learning. InRobotics: Science and Systems, 2022
work page 2022
-
[27]
Minimizing energy consumption leads to the emergence of gaits in legged robots
Zipeng Fu, Ashish Kumar, Jitendra Malik, and Deepak Pathak. Minimizing energy consumption leads to the emergence of gaits in legged robots. InConference on Robot Learning, pages 928–937. PMLR, 2022
work page 2022
-
[28]
Walk these ways: Tuning robot control for generalization with mul- tiplicity of behavior
Gabriel B Margolis and Pulkit Agrawal. Walk these ways: Tuning robot control for generalization with mul- tiplicity of behavior. InConference on Robot Learning, pages 22–31. PMLR, 2023
work page 2023
-
[29]
Multi-expert learning of adaptive legged locomotion.Science Robotics, 5(49):eabb2174, 2020
Chuanyu Yang, Kai Yuan, Qiuguo Zhu, Wanming Yu, and Zhibin Li. Multi-expert learning of adaptive legged locomotion.Science Robotics, 5(49):eabb2174, 2020
work page 2020
-
[30]
Sylvain Koos, Jean-Baptiste Mouret, and St ´ephane Don- cieux. The transferability approach: Crossing the reality gap in evolutionary robotics.IEEE Transactions on Evolutionary Computation, 17(1):122–145, 2012
work page 2012
-
[31]
Domain ran- domization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain ran- domization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ in- ternational conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017
work page 2017
-
[32]
Sim-to-real transfer of robotic control with dynamics randomization
Xue Bin Peng, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. In2018 IEEE international conference on robotics and automa- tion (ICRA), pages 3803–3810. IEEE, 2018
work page 2018
-
[33]
OpenAI: Marcin Andrychowicz, Bowen Baker, Maciek Chociej, Rafal Jozefowicz, Bob McGrew, Jakub Pa- chocki, Arthur Petron, Matthias Plappert, Glenn Powell, Alex Ray, et al. Learning dexterous in-hand manipula- tion.The International Journal of Robotics Research, 39 (1):3–20, 2020
work page 2020
-
[34]
Closing the sim-to-real loop: Adapting simulation randomization with real world experience
Yevgen Chebotar, Ankur Handa, Viktor Makoviychuk, Miles Macklin, Jan Issac, Nathan Ratliff, and Dieter Fox. Closing the sim-to-real loop: Adapting simulation randomization with real world experience. In2019 International Conference on Robotics and Automation (ICRA), pages 8973–8979. IEEE, 2019
work page 2019
-
[35]
Yunho Kim, Hyunsik Oh, Jeonghyun Lee, Jinhyeok Choi, Gwanghyeon Ji, Moonkyu Jung, Donghoon Youm, and Jemin Hwangbo. Not only rewards but also constraints: Applications on legged robot locomotion.IEEE Trans- actions on Robotics, 40:2984–3003, 2024
work page 2024
-
[36]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Learning agile locomotion on risky terrains
Chong Zhang, Nikita Rudin, David Hoeller, and Marco Hutter. Learning agile locomotion on risky terrains. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11864–11871. IEEE, 2024
work page 2024
-
[38]
Long short- term memory.Neural Computation, 9(8):1735–1780,
Sepp Hochreiter and J ¨urgen Schmidhuber. Long short- term memory.Neural Computation, 9(8):1735–1780,
-
[39]
doi: 10.1162/neco.1997.9.8.1735
-
[40]
Hacl: History-aware curriculum learning for fast locomotion.arXiv preprint arXiv:2505.18429, 2025
Prakhar Mishra, Amir Hossain Raj, Xuesu Xiao, and Di- nesh Manocha. Hacl: History-aware curriculum learning for fast locomotion.arXiv preprint arXiv:2505.18429, 2025
-
[41]
Gaitor: Learning a unified representation across gaits for real-world quadruped locomotion
Alexander Luis Mitchell, Wolfgang Merkt, Aristotelis Papatheodorou, Ioannis Havoutis, and Ingmar Posner. Gaitor: Learning a unified representation across gaits for real-world quadruped locomotion. In8th Annual Conference on Robot Learning, 2024
work page 2024
-
[42]
Allgaits: Learning all quadruped gaits and transitions
Guillaume Bellegarda, Milad Shafiee, and Auke Ijspeert. Allgaits: Learning all quadruped gaits and transitions. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15929–15935. IEEE, 2025
work page 2025
-
[43]
Milad Shafiee, Guillaume Bellegarda, and Auke Ijspeert. Viability leads to the emergence of gait transitions in learning agile quadrupedal locomotion on challenging terrains.Nature Communications, 15(1):3073, 2024
work page 2024
-
[44]
Non-conflicting energy minimization in rein- forcement learning based robot control
Skand Peri, Akhil Perincherry, Bikram Pandit, and Ste- fan Lee. Non-conflicting energy minimization in rein- forcement learning based robot control. In9th Annual Conference on Robot Learning, 2025
work page 2025
-
[45]
Moe-loco: Mixture of experts for multitask locomotion
Runhan Huang, Shaoting Zhu, and Yilun Du. Moe-loco: Mixture of experts for multitask locomotion. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 14218–14225, 10 2025. doi: 10.1109/IROS60139.2025.11246585
-
[46]
Evaluating real-world robot manipulation policies in simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al. Evaluating real-world robot manipulation policies in simulation. InRSS 2024 Workshop: Data Generation for Robotics
work page 2024
-
[47]
Scalable policy evaluation with video world models
Wei-Cheng Tseng, Jinwei Gu, Qinsheng Zhang, Hanzi Mao, Ming-Yu Liu, Florian Shkurti, and Lin Yen-Chen. Scalable policy evaluation with video world models. arXiv preprint arXiv:2511.11520, 2025
-
[48]
Robogsim: A real2sim2real robotic gaussian splatting simulator.arXiv preprint arXiv:2411.11839, 2024
Xinhai Li, Jialin Li, Ziheng Zhang, Rui Zhang, Fan Jia, Tiancai Wang, Haoqiang Fan, Kuo-Kun Tseng, and Ruip- ing Wang. Robogsim: A real2sim2real robotic gaussian splatting simulator.arXiv preprint arXiv:2411.11839, 2024
-
[49]
Shaoting Zhu, Linzhan Mou, Derun Li, Baijun Ye, Runhan Huang, and Hang Zhao. Vr-robo: A real-to- sim-to-real framework for visual robot navigation and locomotion.IEEE Robotics and Automation Letters, 2025
work page 2025
-
[50]
Hongxi Wang, Haoxiang Luo, Wei Zhang, and Hua Chen. Cts: Concurrent teacher-student reinforcement learning for legged locomotion.IEEE Robotics and Automation Letters, 2024
work page 2024
-
[51]
Ying Zhang, Tao Xiang, Timothy M Hospedales, and Huchuan Lu. Deep mutual learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4320–4328, 2018
work page 2018
-
[52]
Adaptive mixtures of local experts
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991
work page 1991
-
[53]
Hierarchical mixtures of experts and the em algorithm.Neural computation, 6(2):181–214, 1994
Michael I Jordan and Robert A Jacobs. Hierarchical mixtures of experts and the em algorithm.Neural computation, 6(2):181–214, 1994
work page 1994
-
[54]
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learn- ing Research, 23(120):1–39, 2022
work page 2022
-
[55]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[56]
Isaac gym: High performance gpu based physics simulation for robot learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu based physics simulation for robot learning. InNeurIPS Datasets and Benchmarks, 2021
work page 2021
-
[57]
Mu- joco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mu- joco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033, 2012. doi: 10.1109/IROS.2012.6386109
-
[58]
Miomir Vukobratovi ´c and Branislav Borovac. Zero- moment point—thirty five years of its life.International journal of humanoid robotics, 1(01):157–173, 2004
work page 2004
-
[59]
St ´ephane Caron, Quang-Cuong Pham, and Yoshihiko Nakamura. Stability of surface contacts for humanoid robots: Closed-form formulae of the contact wrench cone for rectangular support areas. In2015 IEEE International Conference on Robotics and Automation (ICRA), pages 5107–5112. IEEE, 2015
work page 2015
-
[60]
Xue Bin Peng, Michael Chang, Grace Zhang, Pieter Abbeel, and Sergey Levine. Mcp: Learning composable hierarchical control with multiplicative compositional policies.Advances in neural information processing systems, 32, 2019
work page 2019
-
[61]
Karl Pearson. Liii. on lines and planes of closest fit to systems of points in space.The London, Edinburgh, and Dublin philosophical magazine and journal of science, 2 (11):559–572, 1901. APPENDIXA ROBOGAUGESUPPLEMENTARYMATERIAL A. Stability Metric To provide a more comprehensive evaluation of locomotion stability, we introduce two formal physical criteri...
work page 1901
-
[62]
Zero Moment Point (ZMP) Margin:The Zero Moment Point (ZMP) is a fundamental concept in legged locomotion, defined as the point on the ground where the net moment of inertial and gravitational forces has no horizontal components. To formalize this metric within our framework, we establish the following definitions: •Support Polygon:The convex hull formed b...
-
[63]
LetN c be the number of active foot contacts with the ground
Coulomb Friction Margin:To account for potential slippage and Contact Wrench Cone (CWC) constraints, we introduce a translational friction margin. LetN c be the number of active foot contacts with the ground. For each contacti, f tangent i represents the tangential force,f normal i represents the normal force, andµis the surface friction coefficient. The ...
-
[64]
velocity trackingexp(−σ|ω cmd z −ω z|2) 0.5 Lin
1.0/2.0 Ang. velocity trackingexp(−σ|ω cmd z −ω z|2) 0.5 Lin. velocity (z)v 2 z −2.0 Ang. velocity (xy)||ω xy||2 2 −0.05 Joint acceleration¨q 2 −2.5×10 −7 Joint power|τ||˙q| T −2×10 −5 Joint torque||τ|| 2 2 −1×10 −4 Base height(h des −h) 2 −1.0 Action rate||a t −a t−1||2 2 −0.01 Action smoothness||a t −2a t−1 +a t−2||2 2 −0.01 Collisionn collision −1.0 Jo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.