Recognition: unknown
MotionBricks: Scalable Real-Time Motions with Modular Latent Generative Model and Smart Primitives
Pith reviewed 2026-05-08 02:37 UTC · model grok-4.3
The pith
A single modular latent model plus smart primitives can generate high-quality real-time motions from datasets of over 350,000 clips at production scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
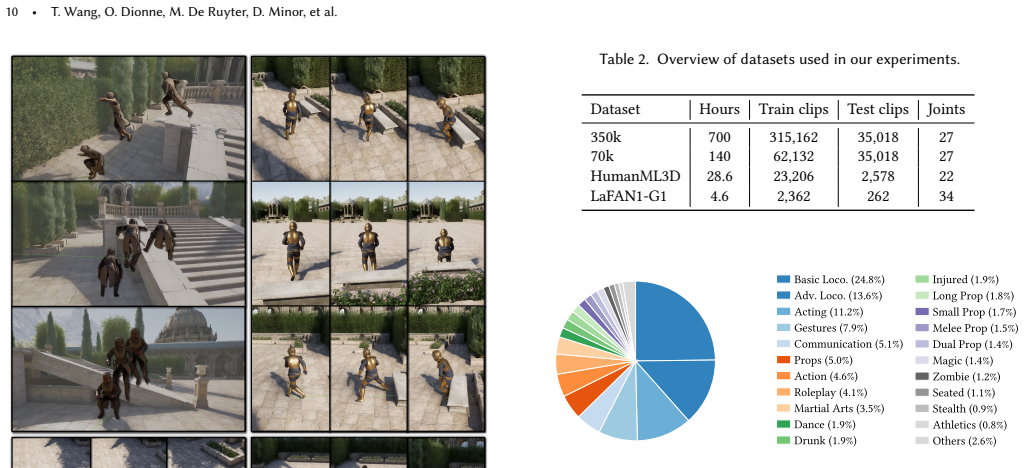
MotionBricks is a framework built around a large-scale modular latent generative backbone that models more than 350,000 motion clips with a single model, paired with smart primitives that give a unified interface for multi-modal inputs such as velocity commands, style selection, and precise keyframes. The system produces state-of-the-art motion quality on both public and proprietary datasets while running at 15,000 frames per second with 2 ms latency, and it supports a complete production animation pipeline plus direct deployment on the Unitree G1 humanoid robot.
What carries the argument
The modular latent generative backbone, which partitions motion modeling into reusable latent modules that together scale to hundreds of thousands of clips under real-time constraints, and the smart primitives, which act as composable building blocks for navigation and object interaction.
If this is right
- Motion quality remains state-of-the-art across open-source and proprietary datasets of varying sizes.
- Real-time generation reaches 15,000 FPS with only 2 ms latency on standard hardware.
- A single trained model covers navigation, object-scene interaction, and multiple styles without retraining.
- Animation sequences can be authored by combining primitives in a plug-and-play way that requires no expert keyframing.
- The same model transfers directly to real-time control of a humanoid robot.
Where Pith is reading between the lines
- Production pipelines could shift from maintaining large libraries of pre-baked clips to maintaining one generative model plus a small set of primitives.
- The primitive interface might let non-animators design robot behaviors in simulation and deploy them without additional fine-tuning steps.
- If the modular backbone generalizes across embodiment, the same training run could supply motion for both human characters and different robot morphologies.
- Game engines could expose the primitives as native nodes, allowing designers to script complex AI movement without writing motion graphs.
Load-bearing premise
A single modular latent model can represent the full range of behaviors in a 350,000-clip dataset without quality loss when forced to run at millisecond latency.
What would settle it
A direct comparison that measures motion quality and visual artifacts on the full 350k-clip dataset when the model is constrained to 2 ms inference time versus when it is allowed longer compute.
Figures





















read the original abstract
Despite transformative advances in generative motion synthesis, real-time interactive motion control remains dominated by traditional techniques. In this work, we identify two key challenges in bridging research and production: 1) Real-time scalability: Industry applications demand real-time generation of a vast repertoire of motion skills, while generative methods exhibit significant degradation in quality and scalability under real-time computation constraints, and 2) Integration: Industry applications demand fine-grained multi-modal control involving velocity commands, style selection, and precise keyframes, a need largely unmet by existing text- or tag-driven models. To overcome these limitations, we introduce MotionBricks: a large-scale, real-time generative framework with a two-fold solution. First, we propose a large-scale modular latent generative backbone tailored for robust real-time motion generation, effectively modeling a dataset of over 350,000 motion clips with a single model. Second, we introduce smart primitives that provide a unified, robust, and intuitive interface for authoring both navigation and object interaction. Applications can be designed in a plug-and-play manner like assembling bricks without expert animation knowledge. Quantitatively, we show that MotionBricks produces state-of-the-art motion quality on open-source and proprietary datasets of various scales, while also achieving a real-time throughput of 15,000 FPS with 2ms latency. We demonstrate the flexibility and robustness of MotionBricks in a complete production-level animation demo, covering navigation and object-scene interaction across various styles with a unified model. To showcase our framework's application beyond animation, we deploy MotionBricks on the Unitree G1 humanoid robot to demonstrate its flexibility and generalization for real-time robotic control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MotionBricks, a framework consisting of a modular latent generative backbone trained on a dataset of over 350,000 motion clips for scalable real-time motion synthesis, paired with 'smart primitives' that enable plug-and-play multi-modal control for navigation and object-scene interactions. It reports state-of-the-art motion quality on both open-source and proprietary datasets, real-time throughput of 15,000 FPS with 2 ms latency, a production-level animation demo across styles, and deployment on the Unitree G1 humanoid robot for robotic control.
Significance. If the quantitative results hold, the work is significant for bridging generative motion research with production needs in animation and robotics by demonstrating a single unified model that maintains quality at scale under strict real-time constraints while providing an intuitive control interface. The combination of large-scale training, modular architecture, and empirical validation on diverse datasets plus hardware deployment strengthens its potential impact.
major comments (2)
- [§4.3, Table 3] §4.3, Table 3: The SOTA quality claims on proprietary datasets rely on metrics that are not fully detailed in comparison to baselines under identical real-time inference budgets; without explicit per-baseline FPS/latency numbers in the same table, it is difficult to confirm that the quality advantage is achieved without trading off the reported 15k FPS target.
- [§3.2] §3.2: The smart primitives are presented as providing a unified interface, but the formal mapping from primitive parameters to latent conditioning (e.g., how velocity commands and keyframes are encoded without expert tuning) is described at a high level; a concrete example or pseudocode showing the encoding for a multi-modal command would strengthen the claim that they require no expert animation knowledge.
minor comments (2)
- [Figure 4] Figure 4 caption: The production demo timeline should explicitly label which segments use navigation primitives versus object-interaction primitives to make the plug-and-play claim visually verifiable.
- [§5.1] §5.1: The robot deployment results mention generalization but do not report the exact motion clip count or diversity metrics for the training subset used in sim-to-real transfer; adding this would clarify the scope of the claimed robustness.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive review and the recommendation for minor revision. The comments identify opportunities to strengthen the clarity of our experimental comparisons and the description of smart primitives. We address each point below and will incorporate the suggested revisions into the manuscript.
read point-by-point responses
-
Referee: [§4.3, Table 3] The SOTA quality claims on proprietary datasets rely on metrics that are not fully detailed in comparison to baselines under identical real-time inference budgets; without explicit per-baseline FPS/latency numbers in the same table, it is difficult to confirm that the quality advantage is achieved without trading off the reported 15k FPS target.
Authors: We appreciate this observation. The manuscript reports MotionBricks' throughput of 15,000 FPS with 2 ms latency and notes that all comparisons were conducted under real-time constraints, but we agree that explicit per-baseline FPS and latency values in Table 3 would make the comparison more transparent. In the revised manuscript, we will update Table 3 to include measured FPS and latency for each baseline on identical hardware, confirming that the reported quality improvements are achieved without compromising the real-time target. revision: yes
-
Referee: [§3.2] The smart primitives are presented as providing a unified interface, but the formal mapping from primitive parameters to latent conditioning (e.g., how velocity commands and keyframes are encoded without expert tuning) is described at a high level; a concrete example or pseudocode showing the encoding for a multi-modal command would strengthen the claim that they require no expert animation knowledge.
Authors: We thank the referee for this suggestion. While Section 3.2 describes the high-level design of smart primitives as a plug-and-play interface, we agree that a concrete example would better illustrate the encoding process. In the revised manuscript, we will add pseudocode (either in Section 3.2 or an appendix) showing how a sample multi-modal command—combining velocity, style, and keyframe parameters—is mapped to latent conditioning vectors without requiring expert animation knowledge. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on empirical training and evaluation of a modular latent generative model on >350k motion clips plus smart primitives for control. Reported SOTA quality metrics, 15k FPS / 2 ms latency figures, and robot-deployment results are obtained from direct experiments on specified open-source and proprietary datasets; these quantities are not forced by construction from the model definition or prior self-citations. No equations or steps reduce the output to the input by redefinition, renaming, or load-bearing self-reference.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Smart primitives
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InACM SIGGRAPH 2024 Conference Papers
Flexible motion in-betweening with diffusion models. InACM SIGGRAPH 2024 Conference Papers. 1–9. Boston Dynamics. 2025. Use Choreographer with Spot. https://support.bostondynamics. com/s/article/Use-Choreographer-with-Spot-72036. Unreal Engine. 2025. Graphing in Animation Blueprints. https://dev.epicgames. com/documentation/en-us/unreal-engine/graphing-in...
2024
-
[2]
A neural temporal model for human motion prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12116–12125. Ruiyu Gou, Michiel van de Panne, and Daniel Holden. 2025. Control Operators for Interactive Character Animation.ACM Transactions on Graphics (TOG)44, 6 (2025), 1–20. Chuan Guo, Yuxuan Mu, Muhammad Gohar Jav...
-
[3]
PyRoki: A modular toolkit for robot kinematic optimization
PyRoki: A Modular Toolkit for Robot Kinematic Optimization.arXiv preprint arXiv:2505.03728(2025). Jihoon Kim, Taehyun Byun, Seungyoun Shin, Jungdam Won, and Sungjoon Choi. 2022. Conditional motion in-betweening.Pattern Recognition132 (2022), 108894. Serkan Kiranyaz, Onur Avci, Osama Abdeljaber, Turker Ince, Moncef Gabbouj, and Daniel J Inman. 2021. 1D con...
-
[4]
InACM SIGGRAPH Asia 2010 Papers(Seoul, South Korea)(SIGGRAPH ASIA ’10)
Motion Fields for Interactive Character Locomotion. InACM SIGGRAPH Asia 2010 Papers(Seoul, South Korea)(SIGGRAPH ASIA ’10). Association for Computing Machinery, New York, NY, USA, Article 138, 8 pages. doi:10.1145/1866158.1866160 Jiefeng Li, Jinkun Cao, Haotian Zhang, Davis Rempe, Jan Kautz, Umar Iqbal, and Ye Yuan. 2025. GENMO: A GENeralist Model for Hum...
-
[5]
CHOICE: Coordinated human-object interaction in cluttered environments for pick-and-place actions.arXiv preprint arXiv:2412.06702(2024). ACM Trans. Graph., Vol. 45, No. 4, Article . Publication date: July 2026. MotionBricks: Scalable Real-Time Motions with Modular Latent Generative Model and Smart Primitives•17 Zhuoyan Luo, Fengyuan Shi, Yixiao Ge, Yujiu ...
-
[6]
arXiv preprint arXiv:2303.01418 (2023) 3
High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695. Alla Safonova and Jessica K Hodgins. 2007. Construction and optimal search of inter- polated motion graphs. InACM SIGGRAPH 2007 papers. 106–es. Yonatan Shafir, Guy Tevet, Roy Kapon, and Amit H Berm...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.