Recognition: unknown
Toward Scalable Terminal Task Synthesis via Skill Graphs
Pith reviewed 2026-05-07 16:08 UTC · model grok-4.3
The pith
SkillSynth builds a scenario-mediated skill graph and samples workflow paths to synthesize terminal tasks with controlled diversity in minimal execution trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
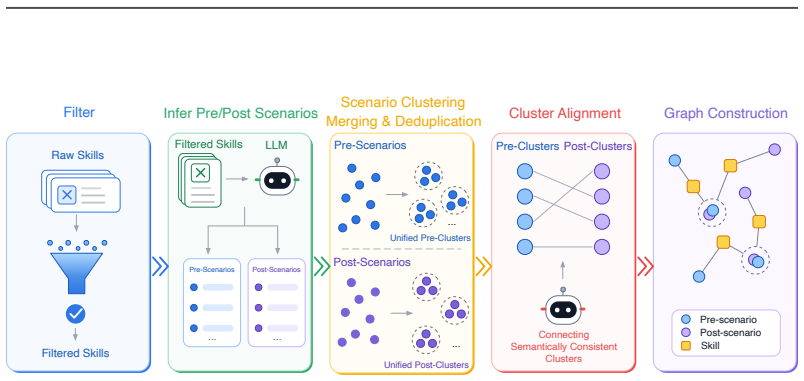
SkillSynth is an automated framework for terminal task synthesis built on a scenario-mediated skill graph. The framework first constructs a large-scale skill graph where scenarios serve as intermediate transition nodes that connect diverse command-line skills. It then samples paths from this graph as abstractions of real-world workflows and uses a multi-agent harness to instantiate them into executable task instances. By grounding task synthesis in graph-sampled workflow paths, SkillSynth explicitly controls the diversity of minimal execution trajectories required to solve the synthesized tasks. Experiments on Terminal-Bench demonstrate the effectiveness of SkillSynth, and the generated task
What carries the argument
The scenario-mediated skill graph, in which scenarios act as intermediate nodes connecting command-line skills, so that sampled paths serve as abstractions of workflows and directly determine the diversity of minimal execution trajectories in the resulting tasks.
If this is right
- Agents trained on the synthesized tasks encounter a wider range of minimal execution trajectories than under quantity-focused synthesis.
- Task generation becomes scalable while retaining explicit control over trajectory diversity.
- The same graph-sampling process can be reused to produce additional task sets without redesigning the synthesis pipeline.
- Tasks generated this way have already been used to improve the terminal performance of a deployed agent preview.
Where Pith is reading between the lines
- The graph structure could support curriculum-style training by ordering paths according to increasing length or number of distinct skills.
- Because paths are explicit abstractions, the method might make it easier to diagnose which kinds of workflows an agent still fails to handle.
- If the skill graph is updated with new scenarios, the same sampling machinery could generate tasks for evolving command-line environments without starting from scratch.
Load-bearing premise
Building a scenario-mediated skill graph and sampling paths from it produces tasks whose minimal execution trajectories are diverse and representative enough to improve agent performance over earlier synthesis methods, and the multi-agent harness can turn those abstract paths into executable instances without adding artifacts.
What would settle it
Train agents on SkillSynth tasks and on tasks from prior synthesis methods, then measure both success rates and the actual diversity of minimal trajectories on Terminal-Bench; if the SkillSynth agents show no measurable gain in either metric, or if many generated instances contain non-executable artifacts, the claim is falsified.
Figures





read the original abstract
Terminal agents have demonstrated strong potential for autonomous command-line execution, yet their training remains constrained by the scarcity of high-quality and diverse execution trajectories. Existing approaches mitigate this bottleneck by synthesizing large-scale terminal task instances for trajectory sampling. However, they primarily focus on scaling the number of tasks while providing limited control over the diversity of execution trajectories that agents actually experience during training. In this paper, we present SkillSynth, an automated framework for terminal task synthesis built on a scenario-mediated skill graph. SkillSynth first constructs a large-scale skill graph, where scenarios serve as intermediate transition nodes that connect diverse command-line skills. It then samples paths from this graph as abstractions of real-world workflows, and uses a multi-agent harness to instantiate them into executable task instances. By grounding task synthesis in graph-sampled workflow paths, SkillSynth explicitly controls the diversity of minimal execution trajectories required to solve the synthesized tasks. Experiments on Terminal-Bench demonstrate the effectiveness of SkillSynth. Moreover, task instances synthesized by SkillSynth have been adopted to train Hy3 Preview, contributing to its enhanced agentic capabilities in terminal-based settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillSynth, an automated framework for terminal task synthesis built on a scenario-mediated skill graph. It constructs a large-scale skill graph with scenarios as intermediate transition nodes connecting diverse command-line skills, samples paths from this graph as abstractions of real-world workflows, and uses a multi-agent harness to instantiate them into executable task instances. By grounding task synthesis in graph-sampled workflow paths, it claims to explicitly control the diversity of minimal execution trajectories. Experiments on Terminal-Bench are reported to demonstrate effectiveness, and the synthesized tasks have been adopted to train Hy3 Preview for enhanced agentic capabilities.
Significance. If the results hold, this framework offers a promising way to scale the generation of diverse training trajectories for terminal agents, potentially overcoming limitations of existing synthesis methods that focus mainly on quantity rather than controlled diversity. The adoption into Hy3 Preview training provides some evidence of practical value, but without detailed metrics, the significance remains difficult to quantify.
major comments (1)
- Abstract: The claim that 'Experiments on Terminal-Bench demonstrate the effectiveness of SkillSynth' is not supported by any metrics, baselines, ablation details, or quantitative results on trajectory diversity or agent performance gains. This is load-bearing for the central contribution, as it prevents evaluation of whether graph-based path sampling meaningfully improves upon prior task synthesis approaches.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point-by-point below and will incorporate revisions to improve clarity and support for our claims.
read point-by-point responses
-
Referee: Abstract: The claim that 'Experiments on Terminal-Bench demonstrate the effectiveness of SkillSynth' is not supported by any metrics, baselines, ablation details, or quantitative results on trajectory diversity or agent performance gains. This is load-bearing for the central contribution, as it prevents evaluation of whether graph-based path sampling meaningfully improves upon prior task synthesis approaches.
Authors: We agree that the abstract statement is too high-level and does not provide immediate quantitative grounding for the effectiveness claim. Our experiments section does report results on Terminal-Bench, including comparisons of trajectory diversity (via path coverage and minimal execution length metrics) against prior synthesis baselines, as well as downstream agent performance when training on the synthesized tasks. To address the concern directly, we will revise the abstract to include concise references to these key metrics and baseline comparisons, ensuring the claim is explicitly supported by the reported findings. revision: yes
Circularity Check
No significant circularity; framework is a direct construction
full rationale
The paper presents SkillSynth as an explicit pipeline: construct a scenario-mediated skill graph, sample workflow paths, and instantiate tasks via multi-agent harness. The central claim that this controls diversity of minimal execution trajectories follows directly from the graph-sampling design choice itself, without any fitted parameters, self-referential predictions, or reductions to prior self-citations. No equations, uniqueness theorems, or ansatzes are invoked that collapse back to the inputs. The derivation chain is self-contained as a proposed engineering framework rather than a mathematical result that must be verified against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scenarios can serve as meaningful intermediate nodes that connect diverse command-line skills into realistic workflow abstractions.
invented entities (2)
-
SkillSynth framework
no independent evidence
-
scenario-mediated skill graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fast unfolding of communities in large networks.Journal of Statistical Mechanics: Theory and Experiment, 2008(10):P10008, October
Vincent D Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. Fast unfolding of communities in large networks.Journal of Statistical Mechanics: Theory and Experiment, 2008(10):P10008, October
2008
-
[2]
Fast Unfolding of Communities in Large Networks
ISSN 1742-5468. doi: 10.1088/1742-5468/2008/10/p10008. URLhttp://dx.doi.org/10.1088/1742-5468/2008/10/P10008. Mouxiang Chen, Lei Zhang, Yunlong Feng, Xuwu Wang, Wenting Zhao, Ruisheng Cao, Jiaxi Yang, Jiawei Chen, Mingze Li, Zeyao Ma, Hao Ge, Zongmeng Zhang, Zeyu Cui, Dayiheng Liu, Jingren Zhou, Jianling Sun, Junyang Lin, and Binyuan Hui. Swe-universe: Sc...
-
[3]
Kanishk Gandhi, Shivam Garg, Noah D
URLhttps://arxiv.org/abs/2602.02361. Kanishk Gandhi, Shivam Garg, Noah D. Goodman, and Dimitris Papailiopoulos. Endless terminals: Scaling rl environments for terminal agents,
-
[4]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
URL https://arxiv.org/abs/2310.06770. Stephen C. Johnson. Hierarchical clustering schemes.Psychometrika, 32(3):241–254,
work page internal anchor Pith review arXiv
-
[5]
Hao Li, Chunjiang Mu, Jianhao Chen, Siyue Ren, Zhiyao Cui, Yiqun Zhang, Lei Bai, and Shuyue Hu
doi: 10.1007/BF02289588. Hao Li, Chunjiang Mu, Jianhao Chen, Siyue Ren, Zhiyao Cui, Yiqun Zhang, Lei Bai, and Shuyue Hu. Organizing, orchestrating, and benchmarking agent skills at ecosystem scale,
-
[6]
URL https://arxiv.org/abs/2603.02176. Yuan Liang, Ruobin Zhong, Haoming Xu, Chen Jiang, Yi Zhong, Runnan Fang, Jia-Chen Gu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Xin Xu, Tongtong Wu, Kun Wang, Yang Liu, Zhen Bi, Jungang Lou, Yuchen Eleanor Jiang, Hangcheng Zhu, Gang Yu, Haiwen Hong, Longtao Huang, Hui Xue, Chenxi Wang, Yijun Wang, Zifei Shan...
-
[7]
Skillnet: Create, evaluate, and connect ai skills.arXiv preprint arXiv:2603.04448,
URLhttps://arxiv.org/abs/2603.04448. Xi Victoria Lin, Chenglong Wang, Luke Zettlemoyer, and Michael D. Ernst. Nl2bash: A corpus and semantic parser for natural language interface to the linux operating system,
-
[8]
Nl2bash: A corpus and semantic parser for natural language interface to the linux operating system
URL https://arxiv.org/abs/1802.08979. Yusong Lin, Haiyang Wang, Shuzhe Wu, Lue Fan, Feiyang Pan, Sanyuan Zhao, and Dandan Tu. Cli-gym: Scalable cli task generation via agentic environment inversion,
-
[9]
URLhttps: //arxiv.org/abs/2602.10999. Dirk Merkel. Docker: Lightweight linux containers for consistent development and deployment. Linux Journal, 2014(239):2,
-
[10]
URL https://arxiv.org/abs/2601.11868. OpenAI. Introducing codex.https://openai.com/index/introducing-codex/, May
work page internal anchor Pith review arXiv
- [11]
-
[12]
Voyager: An Open-Ended Embodied Agent with Large Language Models
URLhttps://arxiv.org/abs/2305.16291. Lilin Wang, Lucas Ramalho, Alan Celestino, Phuc Anthony Pham, Yu Liu, Umang Kumar Sinha, Andres Portillo, Onassis Osunwa, and Gabriel Maduekwe. Swe-bench++: A framework for the scalable generation of software engineering benchmarks from open-source repositories, 2025a. URLhttps://arxiv.org/abs/2512.17419. Xingyao Wang,...
work page internal anchor Pith review arXiv
-
[13]
URLhttps://arxiv.org/abs/2602. 01244. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang ...
work page internal anchor Pith review arXiv
-
[14]
arXiv preprint arXiv:2306.14898 , year=
URLhttps://arxiv. org/abs/2306.14898. John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents, 2025b. URLhttps://arxiv.org/abs/2504.21798. Linghao Zhang, Shilin He, Chaoyun Zhang, Yu Kang, Bowen Li, Chengxing...
-
[15]
URLhttps://arxiv. org/abs/2505.23419. Kaijie Zhu, Yuzhou Nie, Yijiang Li, Yiming Huang, Jialian Wu, Jiang Liu, Ximeng Sun, Zhenfei Yin, Lun Wang, Zicheng Liu, Emad Barsoum, William Yang Wang, and Wenbo Guo. Termi- gen: High-fidelity environment and robust trajectory synthesis for terminal agents,
-
[16]
URL https://arxiv.org/abs/2602.07274. 12 A PROOF OFEQUIVALENCE We show that the skill-level objective in Equation 3 reduces to the standard next-action objective under three assumptions: (A1) the mappingζ7→ξis deterministic, (A2) each scenarioσ t is a sufficient statistic for the agent’s next decision, and (A3) each skillκ t = (ait , . . . , ajt)is execut...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.