ANCORA: Learning to Question via Manifold-Anchored Self-Play for Verifiable Reasoning
Pith reviewed 2026-05-08 03:03 UTC · model grok-4.3
The pith
ANCORA lets a single policy generate its own verifiable problems and solve them, bootstrapping high performance in formal verification without any human solutions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
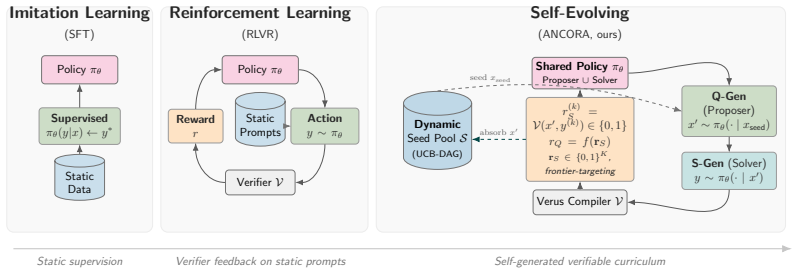
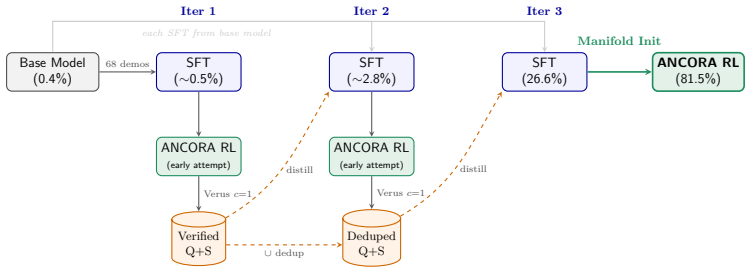
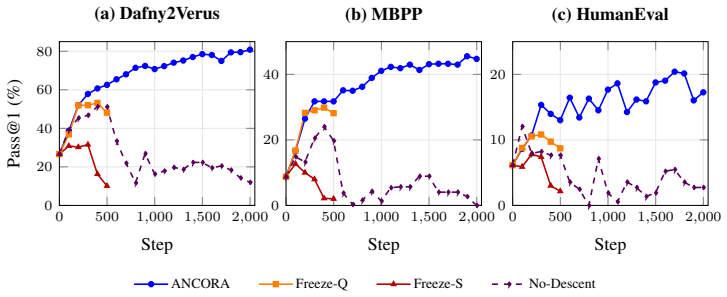
ANCORA alternates a Proposer that synthesizes novel specifications with a Solver that produces verified solutions; a two-level group-relative update couples their advantages, iterative self-distilled SFT projects the model onto its valid-output manifold, and a UCB-guided Curriculum DAG expands the policy-induced problem set under self-composition, enabling the entire loop to bootstrap from zero human solutions and reach 81.5 percent pass@1 on Verus tasks.
What carries the argument
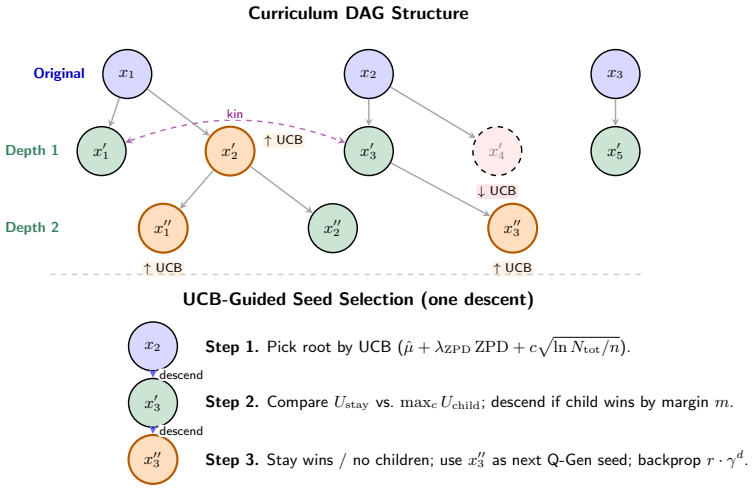
The three stabilizers (two-level group-relative update, iterative self-distilled SFT, and UCB-guided Curriculum DAG) that couple proposer and solver advantages and keep the generated problem set expanding without collapse.
If this is right
- The policy can synthesize an expanding set of verifiable problems whose difficulty is controlled by the UCB-guided DAG.
- Performance gains transfer to held-out benchmarks such as MBPP and HumanEval when training begins from Dafny2Verus seeds.
- The same loop can be applied to any domain that supplies an automatic verifier, removing the need for human-annotated solution traces.
- Test-time training with the anchored self-play loop improves 0-shot accuracy beyond 1-shot baselines that rely on external examples.
Where Pith is reading between the lines
- The Curriculum DAG structure may allow continuous, automatic curriculum expansion beyond the initial problem distribution.
- The manifold-projection step could be adapted to other modalities where an automatic verifier exists, such as theorem proving or constraint satisfaction.
- If the stabilizers generalize, self-play curricula might reduce dependence on large human-curated datasets for training verifiable reasoners.
Load-bearing premise
The three stabilizers are enough to stop the proposer from collapsing when verifier feedback is sparse and only the model’s own outputs are available.
What would settle it
Run the identical training loop on the same Verus tasks but disable one stabilizer (for example, remove the two-level group-relative update) and measure whether pass@1 falls back to the 26.6 percent SFT baseline within the same number of steps.
Figures
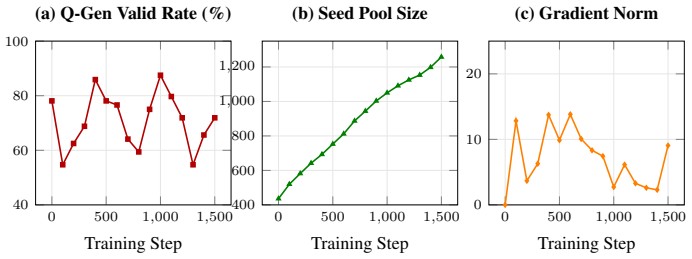
read the original abstract
We propose a paradigm shift toward open-ended curriculum self-play: rather than learning to answer on a fixed prompt set, a unified policy learns to question: generating verifiable problems, solving them, and turning verifier feedback into self-improvement without human-annotated solutions. We introduce ANCORA, in which the policy alternates between a Proposer that synthesizes novel specifications and a Solver that produces verified solutions, anchored by three load-bearing mechanisms: a two-level group-relative update coupling Proposer advantages across specifications with Solver advantages across solution attempts; iterative self-distilled SFT projecting the base model onto its valid-output manifold before RL; and a UCB-guided Curriculum DAG whose policy-induced problem set can provably expand under self-composition. Without these stabilizers, sparse verifier feedback drives Proposer collapse even under MLRL-aligned rewards; with them, ANCORA bootstraps a verifiable curriculum from zero human solutions. Instantiated in Verus, ANCORA lifts Dafny2Verus pass@1 from a 26.6% SFT baseline to 81.5% in test-time training (TTT, 0-shot), outperforming PSV self-play by 15.8 points despite PSV's 1-shot inference; in a transfer setting, training from Dafny2Verus seeds yields 36.2% and 17.2% pass@1 on held-out MBPP and HumanEval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ANCORA, a unified policy for open-ended curriculum self-play in verifiable reasoning. The policy alternates between a Proposer generating novel specifications and a Solver producing verified solutions, stabilized by a two-level group-relative advantage update, iterative self-distilled SFT to project onto the valid-output manifold, and a UCB-guided Curriculum DAG that expands under self-composition. The central empirical claim is that these mechanisms enable bootstrapping from zero human solutions, raising Dafny2Verus pass@1 from a 26.6% SFT baseline to 81.5% in 0-shot test-time training while outperforming PSV self-play by 15.8 points, with additional transfer gains on MBPP and HumanEval.
Significance. If the reported gains prove robust under controlled ablations and the three stabilizers demonstrably prevent Proposer collapse under sparse verifier feedback, the work would constitute a meaningful contribution to self-supervised curriculum learning for formal verification. The explicit framing of manifold-anchored self-play and the transfer results suggest potential broader impact on automated reasoning systems that can generate their own training distributions.
major comments (3)
- [Experimental results section] The abstract and central claim rest on the assertion that the three mechanisms (two-level group-relative update, iterative self-distilled SFT, UCB-guided Curriculum DAG) are jointly sufficient to prevent Proposer collapse; however, the manuscript provides no ablation results isolating each component's contribution or showing collapse when any one is removed, leaving the load-bearing status of the stabilizers unverified.
- [Curriculum DAG description] The claim that the Curriculum DAG 'can provably expand under self-composition' is presented as a key theoretical stabilizer, yet no theorem statement, proof sketch, or conditions for expansion appear in the provided text; without this, it is impossible to assess whether the UCB guidance actually guarantees non-collapse rather than relying on empirical tuning of the exploration coefficient.
- [Results and baselines] Performance numbers (26.6% to 81.5% pass@1, 15.8-point gain over PSV) are reported without error bars, number of independent runs, exact data splits, or implementation details for the group sizes and UCB coefficient, undermining confidence that the gains are attributable to the proposed mechanisms rather than uncontrolled factors in the test-time training loop.
minor comments (2)
- [Method] Notation for the two-level advantage update and the self-distillation projection step should be formalized with explicit equations to clarify how they couple Proposer and Solver updates without introducing hidden parameters.
- [Transfer experiments] The transfer setting (Dafny2Verus seeds to MBPP/HumanEval) would benefit from a clearer description of the 0-shot vs. 1-shot inference protocols used for the PSV baseline.
Simulated Author's Rebuttal
Thank you for your thorough and constructive review. We appreciate the emphasis on verifying the load-bearing role of the proposed stabilizers and on improving reproducibility. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental results section] The abstract and central claim rest on the assertion that the three mechanisms (two-level group-relative update, iterative self-distilled SFT, UCB-guided Curriculum DAG) are jointly sufficient to prevent Proposer collapse; however, the manuscript provides no ablation results isolating each component's contribution or showing collapse when any one is removed, leaving the load-bearing status of the stabilizers unverified.
Authors: We agree that isolating the contribution of each stabilizer is essential to substantiate the central claim. In the revised manuscript we will add a dedicated ablation subsection that removes each mechanism in turn (two-level group-relative update, iterative self-distilled SFT, and UCB-guided Curriculum DAG) while keeping all other factors fixed. We will report the resulting Proposer collapse rates and final pass@1 scores, thereby directly verifying the load-bearing status of the three components. revision: yes
-
Referee: [Curriculum DAG description] The claim that the Curriculum DAG 'can provably expand under self-composition' is presented as a key theoretical stabilizer, yet no theorem statement, proof sketch, or conditions for expansion appear in the provided text; without this, it is impossible to assess whether the UCB guidance actually guarantees non-collapse rather than relying on empirical tuning of the exploration coefficient.
Authors: The manuscript asserts that the policy-induced problem set can provably expand under self-composition, but we acknowledge that the formal statement and proof sketch were omitted from the main text. In the revision we will insert a new subsection containing (i) the precise theorem statement, (ii) a proof sketch establishing the expansion condition under self-composition, and (iii) the role of the UCB coefficient in guaranteeing non-collapse. This will clarify that the guarantee is not merely empirical. revision: yes
-
Referee: [Results and baselines] Performance numbers (26.6% to 81.5% pass@1, 15.8-point gain over PSV) are reported without error bars, number of independent runs, exact data splits, or implementation details for the group sizes and UCB coefficient, undermining confidence that the gains are attributable to the proposed mechanisms rather than uncontrolled factors in the test-time training loop.
Authors: We agree that additional statistical and implementation details are required for reproducibility. The revised manuscript will report (i) mean and standard deviation over at least five independent random seeds, (ii) the exact train/test splits used for Dafny2Verus, MBPP, and HumanEval, and (iii) all hyper-parameters including group sizes for the two-level advantage estimator and the precise UCB exploration coefficient. These additions will be placed in the experimental setup and results sections. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents ANCORA as an empirical self-play framework whose performance gains (26.6% to 81.5% pass@1) are reported as direct outcomes of the three described stabilizers rather than as quantities derived from fitted parameters or self-referential definitions. No equations appear in the provided text that equate a prediction to its own inputs by construction, and the central mechanisms (group-relative update, self-distilled SFT, UCB-guided DAG) are introduced as design choices whose sufficiency is asserted via experimental results, not via a load-bearing self-citation chain or uniqueness theorem imported from the authors' prior work. The claim that the Curriculum DAG 'can provably expand under self-composition' is stated at a high level without reducing to a prior fitted result or ansatz smuggled through citation. The derivation therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- UCB exploration coefficient
- group sizes for relative advantage updates
axioms (2)
- domain assumption The external verifier provides accurate and complete correctness signals for all generated solutions.
- ad hoc to paper Iterative self-distilled SFT keeps the policy on the valid-output manifold without degrading solution quality.
invented entities (2)
-
Curriculum DAG
no independent evidence
-
Manifold-anchored self-play
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Autoverus: Automated proof generation for rust code,
URLhttps://arxiv.org/abs/2508.03682. M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert,...
-
[2]
Likelihood displacement: Biased repulsion gradients reduce πθ(y+) for correct outputs that share parameter-space structure with over-penalized negatives (LLD)
-
[3]
Manifold erosion: Momentum drift during zero-gradient steps moves the policy away from the SFT manifold, reducingp M
-
[4]
The expected sequencep (0) M , p(1) M ,
Starvation amplification: Reduced pM increases the fraction of zero-gradient groups (Theorem B.1), lengthening drift episodes and further amplifying distortion. The expected sequencep (0) M , p(1) M , . . .exhibits a monotone decreasing trend with attractorp ∗ = 0. 16 Sketch. Let pk =p (k) M , and let τk = 1/(N pk) be the expected inter-arrival of informa...
-
[5]
SFT Warm-Up (Breaking Theorem B.1):Fine-tuning on expert demonstrations raises pM from near-zero to a level where N pM ≫1 , ensuring that most groups contain at least one valid sample for positive-advantage gradients
-
[6]
This eliminates the most damaging source of directional misalignment
Pure Binary Rewards (Mitigating Theorem B.3):By using binary rewards R∈ {0,1} with filtering as accept/reject gating (rather than tiered heuristic scores), zero-hit groups produceexactly zerogradient rather than arbitrary off-manifold gradients. This eliminates the most damaging source of directional misalignment. Heuristic scores were found experi- menta...
work page 2025
-
[7]
Smooth homotopy path (assumption-level).If Jguided and Jintrinsic are twice continuously differentiable and the Hessian ∇2 θJ(θ, λ) is non-singular along the path, the implicit function theorem produces a continuous curve θ∗(λ) from the guided to the intrinsic optimum. We treat this as astructural hypothesisthat motivates the schedule rather than as a ver...
-
[8]
As λt →0 , continuity of ∇J in λ implies bt →0
Bias–variance decomposition.Writing θt+1 =θ t +η tˆgt, we decompose the stochastic gradient relative to the zero-shot target∇J 0(θt): ˆgt =∇J 0(θt)| {z } target +b t|{z} annealing bias +ξ t|{z} noise , where bt :=∇J λt(θt)− ∇J 0(θt) and ξt := ˆgt − ∇J λt(θt). As λt →0 , continuity of ∇J in λ implies bt →0 . Under bounded rewards and Lipschitz-smooth polic...
-
[9]
ODE-tracking sketch (under stronger assumptions). Ifthe step sizes additionally satisfied the Robbins–Monro conditionsP t ηt =∞ ,P t η2 t <∞ (which AdamW doesnot, and our finite training horizon does not need to), the stochastic-approximation theory for slowly varying targets (e.g., Borkar 2008) would predict that θt tracks the ODE ˙θ=∇J 0(θ) and converge...
work page 2008
-
[10]
Parent core: Identify the core objective in plain language
-
[11]
Direction target: Restate the requested direction (up/down)
-
[12]
Solver-skill focus: Name the one reusable solver obligation the child should teach
-
[13]
Minimal decomposition: For up, explain why no further decomposition is needed; for down, isolate the smallest blocker subproblem
-
[14]
Stepping-stone rationale: Explain why this child is the right next step
-
[15]
Next-step child choice: Formulate the minimal plan by choosing the best child
-
[16]
Hard bans: - No rename-only mutation
Check: Verify the full reasoning chain for consistency. Hard bans: - No rename-only mutation. - No child whose extra property is already implied by the seed. - No child whose difficulty cannot be tied to a reusable S-Gen proof skill. E.2 Proposer Curriculum Template (Abridged) The curriculum template provides a seed specification and a direction (up or do...
-
[17]
Longer responses are not necessarily pathological.In late training, some increase in response length reflects explicit invariant narration and postcondition checking rather than raw repetition
-
[18]
spec recap + invariant-driven implementation + brief proof sketch
The dominant style is “spec recap + invariant-driven implementation + brief proof sketch.”This is consistent with the intended solver behavior in ANCORA, where reusable proof obligations are surfaced explicitly. At the same time, these examples also show that the model often producesover-explainedsolutions. The extra length typically comes from rephrasing...
work page 2008
-
[19]
Boundedness( Rt ∈[0,1] ): enforced by the two-gate construction (30); the three q_reward_modevariants (band_1of8,4p1p,exp_decay) each return values in[0,1]
-
[20]
Solved-only admission(Lemma G.1): enforced by the best_ans guard in the trainer admission path, combined with thestrict_passrequirement of the solver-verification loop. 3.ϵ -packing(Lemma G.2): enforced by SeedPoolGate.check with the dedup thresh- olds specified in our main configuration ( max_pool_sim=0.72, max_sibling_sim=0.55, duplicate_struct_sim_thre...
-
[21]
Piecewise stationarity with variation budget ΥT : not verifiable from code alone; this is an assumption on thesolver learning dynamics, equivalent to requiring that policy updates do not induce unbounded drift between successive steps. Empirically ˆτt =s_ability_ema evolves slowly (per-step changes <0.05 in the first 200 steps), giving an order-of-magnitu...
-
[22]
Hierarchical root/stay/child actions. mcts_select first chooses a root via _root_score (global denominator log(_total_visits+1)/(nt(q)+1)), then at each descent step compares _stay_score(q) against maxq′_child_score(q,q’). Stay and child scores useparent-local denominators log(nt(qparent)+1)/(nstay t (q)+1) and log(nt(qparent)+1)/(nedge t (qparent, q′)+1)...
-
[23]
ucb_exploit_mode defaults to ratchet; our Main run and its Ratchet-4p1p variant both run ratchet
Default ratchet exploit. ucb_exploit_mode defaults to ratchet; our Main run and its Ratchet-4p1p variant both run ratchet. The Empirical-Band and Empirical-4p1p ablations override to empirical, and both crashed within 300 steps—see the negative ablation in §D.5, which also argues that the ratchet choice is the practical mechanism enforcing Assumption (4)
-
[24]
Cold-start neighborhood prior. _node_value returns st(q)/nt(q) only on visited arms (nt(q)>0); on unvisited arms it falls back through a three-step neighborhood_pass_rate chain (own pass_rate→ mean child pass_rate→ global positive-pass-rate mean → constant 0.15). The surrogate abstracts this warm-start prior away; in the code it is what allows freshly ins...
-
[25]
Additive selection priors.Under empirical mode, _exploit returns ˆµt(q)+λZPD ZPD(q,ˆat); and _root_score/_child_score/_stay_score each further add a bounded kinship prior λkin ¯µ(KinN(q)). These areselection-timebonuses attached to Ut, distinct from the backed-up rewardR t of Equation (30). All three priors lie in[0,1]up to their (bounded) weights
-
[26]
Adaptive difficulty window and root quota.Each step, an α=ucb_root_ratio fraction of prompts is reserved for root-level sampling (α= 0.50 in the main run, leaving the other 50% for DAG descent), and candidates are restricted to the difficulty window[ˆat−δ/2,ˆat+δ/2] around the solver-ability estimate ˆat. Both constrain the feasible action set; neither al...
-
[27]
we were unable to find the license for the dataset we used
Batch repulsion and descend margin.Within-batch penalties discourage repeated root/edge/stay actions, and ucb_descend_margin biases the stay-vs-child comparison by a small additive constant. These alter selection probabilities inside a batch but preserve the one-step reward boundedness the regret proof uses. All six deviations are bounded admissible pertu...
-
[28]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.