SMMBench: A Benchmark for Source-Distributed Multimodal Agent Memory
Pith reviewed 2026-05-20 19:07 UTC · model grok-4.3
The pith
Multimodal agents struggle to retrieve and compose evidence scattered across independent sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SMMBench is a benchmark containing 1877 samples grounded in 264 sources that directly measures an agent's ability to retrieve, align, and compose multimodal evidence distributed across independently originated artifacts rather than reasoning inside a single curated context.
What carries the argument
SMMBench benchmark, which supplies tasks that require agents to handle multimodal evidence fragmented across multiple heterogeneous sources.
If this is right
- Agents must develop explicit mechanisms to track and align evidence that originates from separate sources.
- Conflict resolution between pieces of evidence from different origins becomes a necessary capability.
- Preference reasoning and action prediction improve only when memory systems can operate across source boundaries.
- Evaluation protocols for multimodal agents should move beyond single-context settings to include source-distributed scenarios.
Where Pith is reading between the lines
- Future agent designs may need built-in provenance tracking so that evidence from each source can be weighted or updated independently.
- The same source-distribution challenge likely appears in multi-agent collaboration where information arrives from different participants.
- Extending SMMBench with dynamic source addition or real-time updates would test whether systems can maintain coherence as new evidence arrives.
Load-bearing premise
The 1877 samples from 264 sources adequately represent the diversity, fragmentation, and real-world complexity of source-distributed multimodal evidence.
What would settle it
A new agent architecture that scores highly on SMMBench yet still fails when deployed on naturally occurring, uncurated collections of conversations, images, and documents would indicate the benchmark does not capture the intended difficulty.
Figures




















read the original abstract
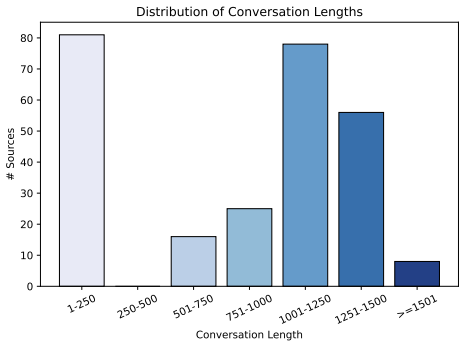
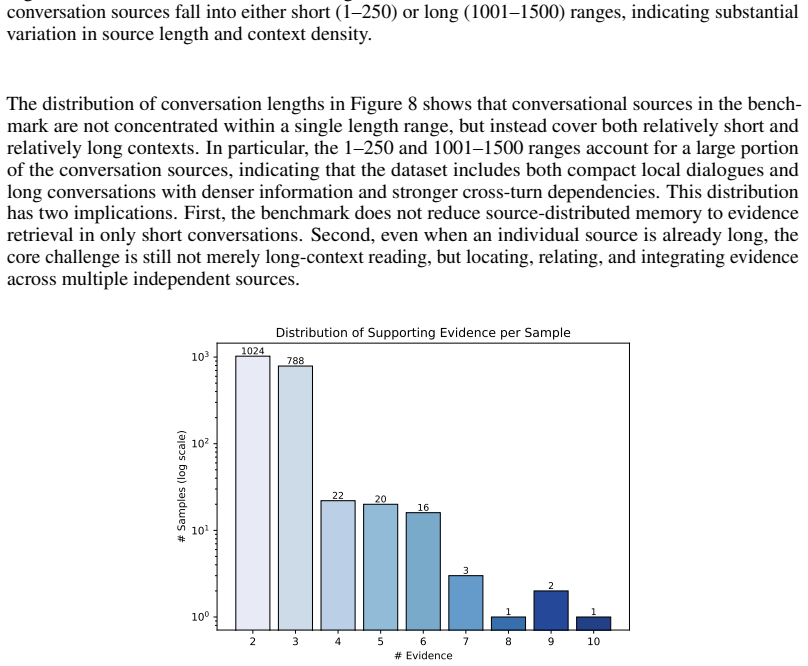
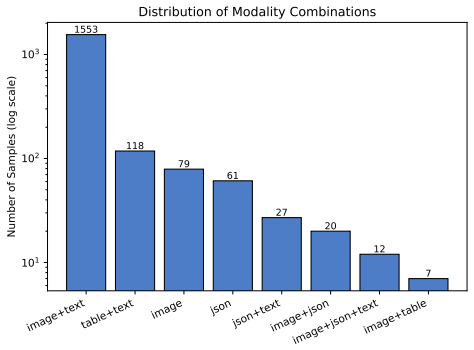
Existing benchmarks for multimodal memory reasoning largely evaluate systems within pre-assembled contexts, but under-evaluate whether agents can use evidence distributed across independently originated sources. We argue that source-distributed memory composition is an important and under-examined bottleneck in multimodal agent memory, especially when relevant evidence is fragmented across heterogeneous artifacts such as conversations, profiles, screenshots, tables, images, and documents. To address this gap, we introduce Source-distributed Multimodal Memory Benchmark(SMMBench), which measures whether agents can retrieve, align, and compose multimodal evidence scattered across multiple sources rather than reason within a single curated context. SMMBench evaluates four core capabilities: (1) cross-source multimodal reasoning; (2) conflict resolution; (3) preference reasoning; (4) memory-grounded action prediction. The benchmark contains 1877 samples grounded in 264 sources. Experiments on representative memory-style and retrieval-based baselines show that current systems still struggle on these capabilities, positioning source-distributed multimodal memory as an important and still under-evaluated challenge for multimodal agents. Our data are available at https://huggingface.co/datasets/HuacanChai/SMMBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
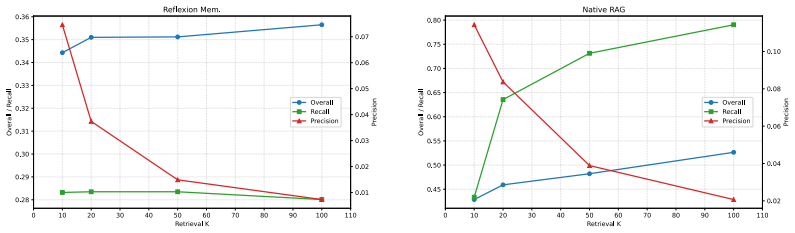
Summary. The paper introduces SMMBench, a benchmark with 1877 samples grounded in 264 sources, to evaluate multimodal agents on source-distributed memory. It argues that existing benchmarks under-evaluate agents' ability to retrieve, align, and compose evidence across independently originated heterogeneous sources (conversations, profiles, screenshots, tables, images, documents). The benchmark targets four capabilities—cross-source multimodal reasoning, conflict resolution, preference reasoning, and memory-grounded action prediction—and reports that representative memory-style and retrieval-based baselines struggle on these tasks, positioning source-distributed multimodal memory as an under-evaluated challenge. The dataset is publicly released on Hugging Face.
Significance. If the sample selection and annotation processes are shown to capture genuine fragmentation and diversity across sources, the benchmark could help shift evaluation practices toward more realistic multimodal agent scenarios. The public data release supports reproducibility and external validation, which strengthens the contribution for a field that relies on shared benchmarks.
major comments (2)
- [Benchmark construction] Benchmark construction section: the criteria for selecting the 264 sources and the 1877 samples, including how source independence, multimodal heterogeneity, and fragmentation were ensured, are not specified. This detail is load-bearing for the central claim that observed struggles arise specifically from source distribution rather than other factors such as sample difficulty or annotation artifacts.
- [Evaluation and metrics] Evaluation and metrics section: the precise definitions and computation of the metrics for the four core capabilities (especially cross-source reasoning and conflict resolution) are not provided. Without these, the baseline results cannot be fully interpreted or compared to future work.
minor comments (1)
- [Introduction] The abstract and introduction could more explicitly contrast SMMBench with prior multimodal memory benchmarks to clarify the precise novelty of the source-distribution focus.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to provide the requested details on benchmark construction and metric definitions.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the criteria for selecting the 264 sources and the 1877 samples, including how source independence, multimodal heterogeneity, and fragmentation were ensured, are not specified. This detail is load-bearing for the central claim that observed struggles arise specifically from source distribution rather than other factors such as sample difficulty or annotation artifacts.
Authors: We agree that additional detail on selection criteria is warranted to strengthen the central claim. In the revised Benchmark construction section we will add explicit criteria: sources were selected from distinct real-world origins (e.g., separate user sessions or applications) to guarantee independence; multimodal heterogeneity was enforced by requiring coverage across conversations, profiles, screenshots, tables, images, and documents with balanced representation; fragmentation was ensured by design, with each sample requiring evidence from at least two non-overlapping sources. For the 1877 samples we will describe the stratified sampling procedure and annotation guidelines used to verify cross-source necessity while controlling for difficulty and minimizing artifacts. These additions will be supported by summary statistics on source diversity. revision: yes
-
Referee: [Evaluation and metrics] Evaluation and metrics section: the precise definitions and computation of the metrics for the four core capabilities (especially cross-source reasoning and conflict resolution) are not provided. Without these, the baseline results cannot be fully interpreted or compared to future work.
Authors: We concur that precise metric definitions are essential for interpretability. The revised Evaluation and metrics section will include formal definitions and computation procedures. Cross-source multimodal reasoning will be scored as the fraction of questions answered correctly only when evidence from two or more distinct sources is integrated. Conflict resolution will measure the rate at which the model both detects contradictions across sources and selects the resolution consistent with explicit priority rules (e.g., recency). Preference reasoning and memory-grounded action prediction will receive analogous step-by-step scoring rules with example calculations. We will also supply pseudocode for each metric to enable direct replication and comparison. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an externally verifiable benchmark (SMMBench with 1877 samples from 264 sources, public Hugging Face release) and reports empirical baseline results showing struggles on cross-source reasoning, conflict resolution, preference reasoning, and action prediction. No derivation chain, equations, fitted parameters, or self-citations are present that reduce the central claim to inputs by construction. The evaluation is independent and falsifiable outside the paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four core capabilities (cross-source multimodal reasoning, conflict resolution, preference reasoning, memory-grounded action prediction) represent the primary bottlenecks for source-distributed multimodal agent memory.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce Source-distributed Multimodal Memory Benchmark (SMMBench), which measures whether agents can retrieve, align, and compose multimodal evidence scattered across multiple sources rather than reason within a single curated context.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on representative memory-style and retrieval-based baselines show that current systems still struggle on these capabilities
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering
Chenyu Zhou, Huacan Chai, Wenteng Chen, Zihan Guo, Rong Shan, Yuanyi Song, Tianyi Xu, Yingxuan Yang, Aofan Yu, Weiming Zhang, et al. Externalization in llm agents: A unified review of memory, skills, protocols and harness engineering.arXiv preprint arXiv:2604.08224, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Holos: A Web-Scale LLM-Based Multi-Agent System for the Agentic Web
Xiaohang Nie, Zihan Guo, Zicai Cui, Jiachi Yang, Zeyi Chen, Leheyi De, Yu Zhang, Junwei Liao, Bo Huang, Yingxuan Yang, et al. Holos: A web-scale llm-based multi-agent system for the agentic web.arXiv preprint arXiv:2604.02334, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Skill- probe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration,
Zihan Guo, Zhiyu Chen, Xiaohang Nie, Jianghao Lin, Yuanjian Zhou, and Weinan Zhang. Skill- probe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration,
- [4]
-
[5]
Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems,
Yingxuan Yang, Huacan Chai, Shuai Shao, Yuanyi Song, Siyuan Qi, Renting Rui, and Weinan Zhang. Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems,
- [6]
-
[7]
Position: The real barrier to llm agent usability is agentic roi, 2026
Weiwen Liu, Jiarui Qin, Xu Huang, Xingshan Zeng, Yunjia Xi, Jianghao Lin, Chuhan Wu, Yasheng Wang, Lifeng Shang, Ruiming Tang, Defu Lian, Yong Yu, and Weinan Zhang. Position: The real barrier to llm agent usability is agentic roi, 2026. URL https://arxiv.org/abs/ 2505.17767
-
[8]
Dannong Xu, Zhongyu Yang, Jun Chen, Yingfang Yuan, Ming Hu, Lei Sun, Luc Van Gool, Danda Pani Paudel, and Chun-Mei Feng. Multihaystack: Benchmarking multimodal retrieval and reasoning over 40k images, videos, and documents.arXiv preprint arXiv:2603.05697, 2026
-
[9]
Mm-bright: A multi-task multimodal benchmark for reasoning-intensive retrieval, 2026
Abdelrahman Abdallah, Mohamed Darwish Mounis, Mahmoud Abdalla, Mahmoud SalahEldin Kasem, Mostafa Farouk Senussi, Mohamed Mahmoud, Mohammed Ali, Adam Jatowt, and Hyun-Soo Kang. Mm-bright: A multi-task multimodal benchmark for reasoning-intensive retrieval, 2026. URLhttps://arxiv.org/abs/2601.09562
-
[10]
Evolutionary perspectives on the evaluation of llm-based ai agents: A comprehensive survey, 2025
Jiachen Zhu, Menghui Zhu, Renting Rui, Rong Shan, Congmin Zheng, Bo Chen, Yunjia Xi, Jianghao Lin, Weiwen Liu, Ruiming Tang, Yong Yu, and Weinan Zhang. Evolutionary perspectives on the evaluation of llm-based ai agents: A comprehensive survey, 2025. URL https://arxiv.org/abs/2506.11102
-
[11]
Milebench: Benchmarking mllms in long context.arXiv preprint arXiv:2404.18532, 2024
Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, and Benyou Wang. Milebench: Benchmarking mllms in long context.arXiv preprint arXiv:2404.18532, 2024
-
[12]
Xiyao Wang, Yuhang Zhou, Xiaoyu Liu, Hongjin Lu, Yuancheng Xu, Feihong He, Jaehong Yoon, Taixi Lu, Gedas Bertasius, Mohit Bansal, Huaxiu Yao, and Furong Huang. Mementos: A comprehensive benchmark for multimodal large language model reasoning over image sequences.arXiv preprint arXiv:2401.10529, 2024
-
[13]
Yuanchen Bei, Tianxin Wei, Xuying Ning, Yanjun Zhao, Zhining Liu, Xiao Lin, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. Mem-gallery: Benchmarking multimodal long-term conversational memory for mllm agents.arXiv preprint arXiv:2601.03515, 2026
-
[14]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in llm agents via incremental multi-turn interactions.arXiv preprint arXiv:2507.05257, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Evaluating the long-term memory of large language models
Zixi Jia, Qinghua Liu, Hexiao Li, Yuyan Chen, and Jiqiang Liu. Evaluating the long-term memory of large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 19759–19777, Vienna, Austria, July 2025. Association for Computational Li...
-
[17]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
work page 2024
-
[18]
Ziyu Liu, Tao Chu, Yuhang Zang, Xilin Wei, Xiaoyi Dong, Pan Zhang, Zijian Liang, Yuanjun Xiong, Yu Qiao, Dahua Lin, et al. Mmdu: A multi-turn multi-image dialog understanding benchmark and instruction-tuning dataset for lvlms.Advances in Neural Information Processing Systems, 37:8698–8733, 2024
work page 2024
-
[19]
Haochen Xue, Feilong Tang, Ming Hu, Yexin Liu, Qidong Huang, Yulong Li, Chengzhi Liu, Zhongxing Xu, Chong Zhang, Chun-Mei Feng, et al. Mmrc: A large-scale benchmark for understanding multimodal large language model in real-world conversation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),...
work page 2025
-
[20]
Benchmarking retrieval-augmented generation in multi-modal contexts
Zhenghao Liu, Xingsheng Zhu, Tianshuo Zhou, Xinyi Zhang, Xiaoyuan Yi, Yukun Yan, Ge Yu, and Maosong Sun. Benchmarking retrieval-augmented generation in multi-modal contexts. Proceedings of the 33rd ACM International Conference on Multimedia, 2025. URL https: //api.semanticscholar.org/CorpusID:276575528
work page 2025
-
[21]
Zeyu Zhang, Quanyu Dai, Xu Chen, Rui Li, Zhongyang Li, and Zhenhua Dong. Memengine: A unified and modular library for developing advanced memory of llm-based agents.arXiv preprint arXiv:2505.02099, 2025
-
[22]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[23]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
work page 2023
-
[24]
Enhancing large language model with self-controlled memory framework
Bing Wang, Xinnian Liang, Jian Yang, Hui Huang, Shuangzhi Wu, Peihao Wu, Lu Lu, Zejun Ma, and Zhoujun Li. Enhancing large language model with self-controlled memory framework. arXiv preprint arXiv:2304.13343, 2023
-
[25]
MIRIX: Multi-Agent Memory System for LLM-Based Agents
Yu Wang and Xi Chen. Mirix: Multi-agent memory system for llm-based agents.arXiv preprint arXiv:2507.07957, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Memverse: Multimodal memory for lifelong learning agents.arXiv preprint arXiv:2512.03627, 2025
Junming Liu, Yifei Sun, Weihua Cheng, Haodong Lei, Yirong Chen, Licheng Wen, Xuemeng Yang, Daocheng Fu, Pinlong Cai, Nianchen Deng, et al. Memverse: Multimodal memory for lifelong learning agents.arXiv preprint arXiv:2512.03627, 2025
-
[28]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Jiaqi Liu, Zipeng Ling, Shi Qiu, Yanqing Liu, Siwei Han, Peng Xia, Haoqin Tu, Zeyu Zheng, Cihang Xie, Charles Fleming, Mingyu Ding, and Huaxiu Yao. Omni-SimpleMem: Autoresearch- guided discovery of lifelong multimodal agent memory.arXiv preprint arXiv:2604.01007, 2026
-
[30]
Hm-rag: Hierarchical multi-agent multimodal retrieval augmented generation
Pei Liu, Xin Liu, Ruoyu Yao, Junming Liu, Siyuan Meng, Ding Wang, and Jun Ma. Hm-rag: Hierarchical multi-agent multimodal retrieval augmented generation. InProceedings of the 33rd ACM international conference on multimedia, pages 2781–2790, 2025
work page 2025
-
[31]
UniversalRAG: Retrieval-Augmented Generation over Corpora of Diverse Modalities and Granularities
Woongyeong Yeo, Kangsan Kim, Soyeong Jeong, Jinheon Baek, and Sung Ju Hwang. Univer- salrag: Retrieval-augmented generation over corpora of diverse modalities and granularities. arXiv preprint arXiv:2504.20734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Qiuchen Wang, Ruixue Ding, Yu Zeng, Zehui Chen, Lin Chen, Shihang Wang, Pengjun Xie, Fei Huang, and Feng Zhao. Vrag-rl: Empower vision-perception-based rag for visually rich information understanding via iterative reasoning with reinforcement learning.arXiv preprint arXiv:2505.22019, 2025
-
[33]
Introducing GPT-4.1 in the api
OpenAI. Introducing GPT-4.1 in the api. https://openai.com/index/gpt-4-1/, 2025. Accessed: 2026-05-05
work page 2025
-
[34]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Rizwan Parvez, Enamul Hoque, and Shafiq R
Ahmed Masry, Mohammed Saidul Islam, Mahir Ahmed, Aayush Bajaj, Firoz Kabir, Aarya- man Kartha, Md Tahmid Rahman Laskar, Mizanur Rahman, Shadikur Rahman, Mehrad Shahmohammadi, Megh Thakkar, Md. Rizwan Parvez, Enamul Hoque, and Shafiq R. Joty. Chartqapro: A more diverse and challenging benchmark for chart question answering. In Annual Meeting of the Associa...
work page 2025
-
[36]
Ryota Tanaka, Kyosuke Nishida, Kosuke Nishida, Taku Hasegawa, Itsumi Saito, and Ku- niko Saito. Slidevqa: A dataset for document visual question answering on multiple im- ages.ArXiv, abs/2301.04883, 2023. URL https://api.semanticscholar.org/CorpusID: 255749397
-
[37]
Benchmarking retrieval-augmented multimodal generation for document question answering
Kuicai Dong, Yujing Chang, Shijie Huang, Yasheng Wang, Ruiming Tang, and Yong Liu. Benchmarking retrieval-augmented multimodal generation for document question answering. arXiv preprint arXiv:2505.16470, 2025
-
[38]
Piecing it all together: Verifying multi-hop multimodal claims
Haoran Wang, Aman Rangapur, Xiongxiao Xu, Yueqing Liang, Haroon Gharwi, Carl Yang, and Kai Shu. Piecing it all together: Verifying multi-hop multimodal claims. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, p...
work page 2025
-
[39]
Bench- marking multimodal knowledge conflict for large multimodal models.ArXiv, abs/2505.19509,
Yifan Jia, Kailin Jiang, Yuyang Liang, Qihan Ren, Yi Xin, Rui Yang, Fenze Feng, Mingcai Chen, Hengyang Lu, Haozhe Wang, Xiaoye Qu, Dongrui Liu, Lizhen Cui, and Yuntao Du. Bench- marking multimodal knowledge conflict for large multimodal models.ArXiv, abs/2505.19509,
-
[40]
URLhttps://api.semanticscholar.org/CorpusID:278904487
-
[41]
Yuntao Du, Kailin Jiang, Zhi Gao, Chenrui Shi, Zilong Zheng, Siyuan Qi, and Qing Li. Mmke-bench: A multimodal editing benchmark for diverse visual knowledge.arXiv preprint arXiv:2502.19870, 2025. 12
-
[42]
Mmpb: It’s time for multi-modal personalization.arXiv preprint arXiv:2509.22820, 2025
Jaeik Kim, Woojin Kim, Woohyeon Park, and Jaeyoung Do. Mmpb: It’s time for multi-modal personalization.arXiv preprint arXiv:2509.22820, 2025
-
[43]
Feiyu Duan, Xuanjing Huang, and Zhongyu Wei. Lifesim: Long-horizon user life simulator for personalized assistant evaluation.arXiv preprint arXiv:2603.12152, 2026
-
[44]
Yang Zhou, Mingyu Zhao, Zhenting Wang, Difei Gu, Bangwei Guo, Ruosong Ye, Ligong Han, Can Jin, and Dimitris N Metaxas. Mˆ 3-bench: Multi-modal, multi-hop, multi-threaded tool-using mllm agent benchmark.arXiv preprint arXiv:2511.17729, 2025
-
[45]
C-pack: Packaged resources to advance general chinese embedding, 2023
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general chinese embedding, 2023
work page 2023
-
[46]
the answer is correct and derivable
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3- embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation, 2024. 13 Appendix Contents A Problem Formulation 15 B Benchmark Construction Details 16 B.1 Sources of Benchmark . . . . . . . . . . . . . . . . . . . . . ...
-
[47]
Judge only based on the provided evidence
-
[48]
Do not rely on background knowledge or external reasoning
-
[49]
If the correct answer cannot be uniquely determined, output No
-
[50]
### Output Format Output only one word: Yes or No
If the evidence is sufficient to correctly and unambiguously support the answer, output Yes. ### Output Format Output only one word: Yes or No. Figure 20: Prompt template for evidence necessity verification. E.3 Distractor Generation Prompt for Distractor Generation ### Task You are an assistant tasked with creating distractor options for a multiple-choic...
-
[51]
The distractors should be plausible enough to be considered potential answers, but not the correct one
-
[52]
The distractors should have a similar format and length to the original answer, but be clearly different
-
[53]
### Output Format Output one distractor option per line
The distractors should not be trivial or too far-fetched. ### Output Format Output one distractor option per line. Do not provide explanations or extra text. Figure 21: Prompt template for distractor generation. 38 E.4 Metadata and Caption Generation Prompt for Metadata and Caption Generation ### Task You are an assistant tasked with topic classification ...
-
[54]
Output all selected topics on a single line, separated by commas
-
[55]
If usingothers, it must appear at the beginning of the output
-
[56]
Figure 22: Prompt template for metadata and caption generation
Do not output explanations or extra text. Figure 22: Prompt template for metadata and caption generation. E.5 Conversation Theme Planning Prompt for Conversation Theme Planning ### Task You are a group chat topic control agent. Your job is to help guide and control the flow of the group chat conversation based on the provided inputs. You will be given the...
-
[57]
Encourage natural use of the multimodal content, but do not explicitly mention it as a gold clue
-
[58]
Phrase sub-topics mainly as declarative sentences
-
[59]
Encourage productive discussion, decision making, and problem solving
-
[60]
Keep the group on track and avoid derailment
-
[61]
### Output Format Generate 10–20 sub-topics, one per line, mainly as declarative sentences
Do not mention the question-answer pair directly. ### Output Format Generate 10–20 sub-topics, one per line, mainly as declarative sentences. Figure 23: Prompt template for conversation theme planning. 39 E.6 Turn-Level Conversation Generation Prompt for Turn-Level Conversation Generation ### Task You are an assistant tasked with replying to a group chat....
-
[62]
A series of messages from the group chat
-
[63]
A specific topic to be aware of when replying
-
[64]
Your personal preferences. ### Step 1 Internally decide whether the reply should be SHORT (1–2 sentences) or LONG (5–8 sentences) based on the conversation length. ### Step 2 Generate the reply accordingly. ### Requirements - Respond relevantly to the ongoing conversation. - Break echo chambers by introducing new perspectives when needed. - Avoid repetiti...
-
[65]
Use only the information available in the conversation and images
-
[66]
Pay attention to earlier parts of the conversation if they contain necessary definitions, assumptions, or details
-
[67]
If the question cannot be answered from the given context and images alone, do not guess
-
[68]
If that information is insufficient, answer cautiously
Some runs may provide only captions or descriptions instead of the original multimodal evidence. If that information is insufficient, answer cautiously. ### Output Format Output exactly one choice from(A),(B),(C), or(D), and nothing else. If the question cannot be answered from the available information, output: No, I can not answer this question based on...
-
[69]
### Output Format Output only a single integer, orNONEif no position is suitable
Timing. ### Output Format Output only a single integer, orNONEif no position is suitable. Figure 26: Prompt template for insertion anchor selection. E.9 Scaffold and Smoothing Prompt for Scaffold and Smoothing You are a conversational conversation generator for group chats. The user will provide:
-
[70]
A central topic, which may be a piece of text, an image, or a table
-
[71]
A conversation history in "SpeakerName: message" format, involving multiple speakers
-
[72]
The next speaker’s name - you must generate a message as if this person is speaking. Your task is to generate a single message from the specified speaker’s perspective: - The message should naturally continue the discussion based on the existing turns and the given topic. - Write as if you are that specific speaker: use first-person perspective (I, my, et...
-
[73]
The generated message should be casual, realistic, and human-like. Do not output emojis
-
[74]
Reply in a relaxed, natural tone—like how a real person would talk
-
[75]
Keep it concise: one or two sentences is appropriate, not too long
-
[76]
Direct descriptions of images and tables are forbidden; you can extend the discussion around their content
-
[77]
Do NOT include the speaker’s name in your output—output only the message content, as if the speaker is typing it. ### Output format Output ONLY the message text that the specified speaker would say. No prefix, no "Name:", no quotes. Just the raw message. Figure 27: Prompt template for scaffold and smoothing. 41 E.10 Non-Text Captioning Prompt Prompt for N...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.