Thinking with Patterns: Breaking the Perceptual Bottleneck in Visual Planning via Pattern Induction
Pith reviewed 2026-05-19 20:40 UTC · model grok-4.3
The pith
Vision-language models overcome perceptual limits in visual planning by inducing reusable patterns that build accurate internal world models step by step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Formulating thinking with images as iterative construction and reflection on an internal world model produces a training-free planning method that solves tasks beyond the models' initial one-step visual capacity; pattern inference then recognizes known visual patterns to infer local model structures directly, while pattern induction supplies those patterns by treating them as autonomously discovered and optimized composite experts from experience, yielding a practical accuracy-efficiency trade-off.
What carries the argument
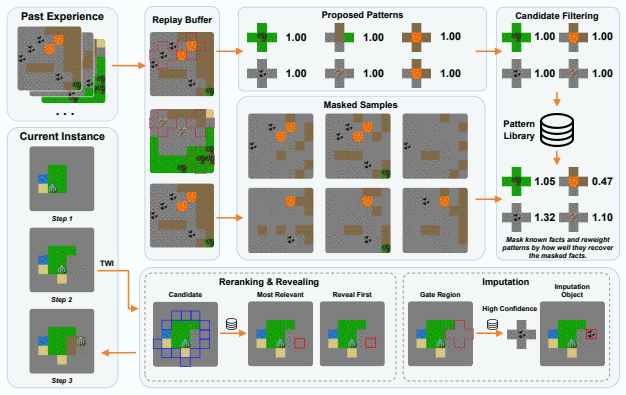
Pattern induction, which treats visual patterns as composite and reusable experts that are discovered and optimized online from experience to support direct inference of world-model fragments.
If this is right
- VLMs gain the ability to solve visual planning problems that exceed their native one-step perception range using only iterative thinking with images.
- Pattern inference reduces the number of required image operations by letting the model recognize known structures and infer the corresponding local world-model components immediately.
- Pattern induction supplies the reusable experts through online experience, removing the need for task-specific fine-tuning or labeled data.
- The combined approach delivers comparable accuracy to full iterative thinking with images but at lower overall computational cost across the tested domains.
Where Pith is reading between the lines
- The same pattern-induction loop could be applied to transfer learned structures from simulation environments to physical robot tasks without retraining.
- If patterns prove stable across related domains, the method might shrink the data requirements for training future vision-language planners.
- Extending induction to multi-step pattern sequences could further compress long planning traces into compact reusable chunks.
Load-bearing premise
Visual patterns can be treated as composite and reusable experts that are autonomously discovered and optimized from experience in a way that directly improves inference efficiency without requiring task-specific retraining or external supervision.
What would settle it
Running the same planning episodes in Crafter or CubeBench with and without the induced patterns and finding that the pattern version requires the same or higher number of thinking-with-images steps while showing no gain in task success rate would falsify the efficiency claim.
Figures






read the original abstract
Planning from raw visual input remains a significant challenge for current Vision-Language Models (VLMs), when the complexity of input is beyond their one-step perception capability. Motivated by recent advances in Thinking with Images (TWI), a reasonable solution is to decompose the perception process into simpler steps by iteratively acquiring and incorporating local visual evidence. However, even though current VLMs are well-trained in general TWI ability, their perceptual bottleneck in the planning domain remains. To tackle this challenge, we formulate TWI as a tool to gradually build and reflect an accurate internal world model. We find that the resulting training-free planning strategy enables VLMs to solve tasks that are far beyond their initial capabilities, at the cost that too many TWI operations would significantly increase the computational overhead. To further improve efficiency, we propose Pattern Inference, a novel TWI strategy enabling VLMs to actively recognize known visual patterns in the new tasks and directly infer local world model structures. To obtain these patterns, we propose Pattern Induction, an online inductive learning strategy treating visual patterns as composite and reusable experts, which are autonomously discovered and optimized from experience. Experimental evaluations in FrozenLake, Crafter and CubeBench domains show that our approaches achieve a desirable balance between accuracy and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that formulating Thinking with Images (TWI) as a process to iteratively build an internal world model enables VLMs to overcome perceptual bottlenecks in visual planning. It introduces Pattern Inference as a TWI strategy for recognizing known visual patterns to infer local world model structures, and Pattern Induction as an online inductive learning method that treats visual patterns as autonomously discovered, composite, reusable experts optimized from experience. This training-free approach is said to solve tasks beyond initial VLM capabilities in FrozenLake, Crafter, and CubeBench while achieving a desirable accuracy-efficiency balance.
Significance. If the central claims hold with rigorous validation, the work would be significant for computer vision and VLM planning research by demonstrating a training-free method to extend perceptual and reasoning capabilities through pattern-based induction. The explicit framing of patterns as reusable experts discovered online could provide a reusable primitive for efficiency gains in iterative visual reasoning, and the multi-domain experimental evaluations (if quantitatively supported) would offer concrete evidence of practical utility.
major comments (2)
- [Pattern Induction mechanism (abstract and §3)] The description of Pattern Induction (abstract and methods) asserts that visual patterns are 'autonomously discovered and optimized from experience' in a training-free manner without task-specific retraining or external supervision, yet provides no explicit induction objective, pattern representation, or optimization loop. This is load-bearing for the training-free guarantee and efficiency claims, as the process could implicitly rely on the VLM's existing priors or repeated prompting that amounts to task-specific adaptation.
- [Experimental evaluations (§4)] The experimental evaluations section claims that the approaches 'achieve a desirable balance between accuracy and efficiency' across FrozenLake, Crafter, and CubeBench, but the absence of quantitative results, error bars, ablation studies, or direct comparisons to raw TWI baselines makes it impossible to verify the claimed trade-off or the improvement over the perceptual bottleneck.
minor comments (1)
- [Abstract] The abstract would benefit from a brief sentence clarifying the representation used for induced patterns to aid reader comprehension of the induction process.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below and have revised the manuscript to incorporate clarifications and additional evidence where needed.
read point-by-point responses
-
Referee: [Pattern Induction mechanism (abstract and §3)] The description of Pattern Induction (abstract and methods) asserts that visual patterns are 'autonomously discovered and optimized from experience' in a training-free manner without task-specific retraining or external supervision, yet provides no explicit induction objective, pattern representation, or optimization loop. This is load-bearing for the training-free guarantee and efficiency claims, as the process could implicitly rely on the VLM's existing priors or repeated prompting that amounts to task-specific adaptation.
Authors: We have expanded Section 3 with an explicit description of the induction objective (discovering abstractions that minimize repeated perceptual queries during planning), pattern representation (textual descriptions of visual composites extracted from trajectories), and the optimization loop (iterative proposal, reuse-frequency evaluation, and retention of patterns via VLM prompting across episodes). No parameter updates or external supervision occur, preserving the training-free property; patterns generalize across tasks rather than adapting to a single one. Pseudocode and examples have been added to the revision. revision: yes
-
Referee: [Experimental evaluations (§4)] The experimental evaluations section claims that the approaches 'achieve a desirable balance between accuracy and efficiency' across FrozenLake, Crafter, and CubeBench, but the absence of quantitative results, error bars, ablation studies, or direct comparisons to raw TWI baselines makes it impossible to verify the claimed trade-off or the improvement over the perceptual bottleneck.
Authors: We agree that stronger quantitative support is warranted. The revised Section 4 now includes tables reporting success rates, average TWI steps, and wall-clock costs with error bars from five independent runs per environment. Ablation studies (with/without Pattern Induction and Inference) and direct comparisons to raw TWI baselines have been added, confirming the accuracy-efficiency gains and alleviation of the perceptual bottleneck. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper proposes Pattern Inference as a TWI strategy for recognizing known visual patterns and Pattern Induction as an online inductive learning approach treating patterns as composite reusable experts discovered from experience. No equations, fitted parameters, or self-citations appear in the provided text that would reduce these proposals or the training-free planning claim to inputs by construction. The methods are framed as novel additions to address perceptual bottlenecks, with experimental evaluations in FrozenLake, Crafter, and CubeBench serving as independent validation rather than tautological redefinitions or post-hoc fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Current VLMs are well-trained in general Thinking-with-Images ability
invented entities (2)
-
Pattern Inference strategy
no independent evidence
-
Pattern Induction mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On top of this, we plan the shortest path
We assume every unrevealed grid is passable. On top of this, we plan the shortest path
-
[2]
If there aren’t any unrevealed grids on the path, the algorithm stops and returns the path
-
[3]
If there are, we check the unrevealed grids one by one from start to goal
-
[4]
If an impassable grid is ever encountered during this process, we immediately go back to step 1 to get another plan
-
[5]
If all checked grids are passable, the algorithm stops and returns the path. Thepolicy-generation procedureworks at step (4) above. Each time, it outputs the first unrevealed grid from start to goal. CRAFTERThis environment, just like the original Minecraft, contains many achievements, The success condition is to finish all 14 achievements in Fig. 6. Insp...
work page 2025
-
[6]
We partition each 16x16 map in the replay buffer into 16 non-overlapping 4x4 minimaps
-
[7]
Minimaps containing fewer than 8 revealed grids are discarded to ensure sufficient informa- tion density
-
[8]
We randomly sample 5 minimaps from the remaining candidates
-
[9]
This proposal will be triggered every 5 maps
These 5 minimaps are subsequently integrated into our prompt template. This proposal will be triggered every 5 maps. So for in total 100 episodes, there will be 19 proposals. CRAFTER
-
[10]
For each 64x64 map in the replay buffer, we identify the minimal bounding box enclosing all revealed grids and subsequently crop the map to these boundaries. Basically, a grid being passable means you can either directly walk through it, or do so after using your existing tools like pickaxe. 15
-
[11]
To accommodate cross- shaped patterns, these minimaps maintain at least a 3x3 overlap
Each cropped map is subdivided into multiple 15x15 minimaps. To accommodate cross- shaped patterns, these minimaps maintain at least a 3x3 overlap. We optimize the minimap locations such that the maximum overlap is minimized
-
[12]
We randomly sample 5 minimaps from the resulting set
-
[13]
This proposal will be triggered every 5 maps
These 5 minimaps are integrated into our prompt template. This proposal will be triggered every 5 maps. So for in total 100 episodes, there will be 19 proposals. CUBEBENCH
-
[14]
We select unreflected states from the replay buffer, prioritizing failed reconstructions and using successful reconstructions only when additional examples are needed
-
[15]
For each selected state, we extract the eight corner cubies and represent each corner by its three-color token
-
[16]
We add the corner cubie-to-sticker-index mapping and a deduplicated summary of observed corner tokens with their multiplicities
-
[17]
These examples are integrated into our prompt template, and the model proposes single- corner patterns in strict JSON format. This proposal will be triggered every 10 episodes. So for in total 100 episodes, there will be 9 proposals, since no proposal is needed after the final episode. The prompts are listed below. The minimaps will be filled into each “{...
work page 2024
-
[20]
We randomly sample the start and goal
-
[21]
Our experiments are done with the minimal length of 25
If the length of the shortest path in between is less than the minimum, we discard this map and go back to step (1); otherwise, we return this map. Our experiments are done with the minimal length of 25. This generation method is basically rejection sampling, ensuring more uniform distribution. However, for our OOD test, where we need to generate 32x32 ma...
-
[22]
First divide the 16x16 map into 16 4x4 minimaps
-
[23]
For each minimap, we randomly put one of six 4x4 macro patterns there
-
[24]
We calculate the length of shortest path between all pairs of grids using all_pairs_shortest_path_lengthfromnetworkx
-
[25]
We filter all pairs whose lengths are smaller than minimum
-
[26]
Essentially, this is still rejection sampling, but with much better efficiency
If there’s no pairs left, we discard this map and go back to step (1); otherwise, we uniformly sample one pair as start and goal, and return the map. Essentially, this is still rejection sampling, but with much better efficiency. C.2 CRAFTER The original CRAFTERhas 17 actions available. For our purpose, we removed action Noop and Sleep. The remaining acti...
-
[27]
Collect Sapling, Place Plant, & Eat Plant: While these could technically be integrated into the planner, they do not serve our research goals. Since the player always spawns on grass, these tasks can be completed through repetitive actions in a single location (e.g., harvesting grass until a sapling drops). Because they require no environmental exploratio...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.