Learning-Zone Energy: Online Data Selection for Efficient RL Post-Training
Pith reviewed 2026-05-20 15:45 UTC · model grok-4.3
The pith
Learning-Zone Energy scores prompts to keep only 40 percent of data in RL post-training while matching or exceeding full-data results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
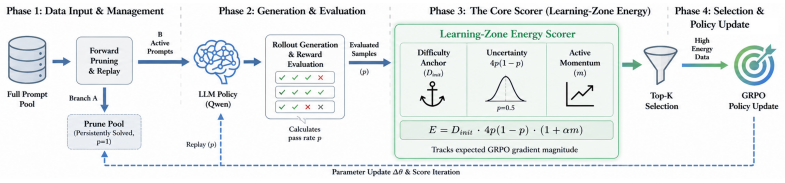
A closed-form Learning-Zone Energy Score fuses an initial-difficulty anchor, a normalized outcome-uncertainty term, and a pass-rate momentum into a single scalar that is provably aligned with the expected magnitude of group-relative policy gradient updates; a forward pruner with replay then skips rollout generation for persistently solved prompts while periodically rechecking them.
What carries the argument
Learning-Zone Energy Score: a closed-form scalar combining difficulty anchor, outcome uncertainty, and pass-rate momentum that aligns with policy-gradient update size to guide data pruning.
If this is right
- Retains only 40 percent of the training data per step
- Matches or surpasses full-data baselines across GSM8K, MATH, and DAPO-MATH
- Delivers larger gains on out-of-distribution sets such as AIME25 and AMC23
- Cuts estimated training FLOPs by 36 percent
Where Pith is reading between the lines
- The same scoring logic could be tested on non-math RL tasks such as code generation or instruction following to check whether compute savings generalize.
- If the alignment between score and gradient magnitude holds, the method might reduce the need for large replay buffers in other online RL settings.
- Periodic forgetting checks could be combined with curriculum scheduling to further stabilize training when data volume is reduced.
Load-bearing premise
The fused score is provably aligned with the expected magnitude of group-relative policy gradient updates.
What would settle it
Apply the same selection rule to a new model family or task suite and measure whether performance falls below the full-data baseline while data usage stays at 40 percent.
Figures





read the original abstract
Reinforcement Learning (RL) post-training has emerged as the dominant paradigm for eliciting mathematical reasoning in Large Language Models (LLMs), yet prevailing techniques such as GRPO and DAPO distribute rollout and gradient budgets nearly uniformly across prompts, squandering compute on samples that are already mastered or remain far beyond the model's current capability. To address this fundamental inefficiency, we propose Learning-Zone Energy (LZE), a theoretically grounded, fully online data selection framework that concentrates computation on the model's active learning frontier. At its core, we define a closed-form Learning-Zone Energy Score that fuses three complementary signals, an initial-difficulty anchor, a normalized outcome-uncertainty term, and a pass-rate momentum, into a single scalar that is provably aligned with the expected magnitude of group-relative policy gradient updates. A forward pruner with replay further reduces wall-clock time cost by skipping rollout generation for persistently solved prompts while periodically checking for forgetting. Evaluated on Qwen-family models (1.5B-8B) across GSM8K, MATH and DAPO-MATH, our method retains only 40% of the training data per step yet matches or surpasses full-data baselines, with especially pronounced out-of-distribution gains on AIME25 (+45.9%) and AMC23 (+18.2%), alongside an estimated 36% reduction in training FLOPs. Our code is available at https://github.com/Stellaris167/LZE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Learning-Zone Energy (LZE), an online data selection method for efficient RL post-training of LLMs on math reasoning. It introduces a closed-form LZE score fusing an initial-difficulty anchor, normalized outcome-uncertainty term, and pass-rate momentum, asserted to be provably aligned with the expected magnitude of group-relative policy gradient (GRPO) updates. A forward pruner with replay skips rollouts for solved prompts. On Qwen models (1.5B–8B) across GSM8K, MATH, and DAPO-MATH, the method retains 40% of data per step while matching or exceeding full-data baselines, with OOD gains on AIME25 (+45.9%) and AMC23 (+18.2%) and ~36% FLOPs reduction. Code is released.
Significance. If the claimed provable alignment holds and the efficiency gains prove robust without hidden selection bias, the work could meaningfully advance compute-efficient RL post-training by concentrating effort on the learning frontier. The OOD improvements and code release are positive indicators for practical impact in scaling mathematical reasoning.
major comments (2)
- [§3.2] §3.2 (LZE Score Derivation): The central claim that the closed-form LZE score is 'provably aligned' with the expected magnitude of GRPO updates lacks explicit derivation steps equating the fused signals (initial-difficulty anchor + normalized uncertainty + pass-rate momentum) to E[|advantage|] or the GRPO estimator. This alignment is load-bearing for the justification of bias-free data selection.
- [§3.1] §3.1 (Normalization): The normalization constants for the outcome-uncertainty term are not specified as fixed or batch-dependent; if data-dependent, this could undermine the claimed independence from the training distribution and the provable alignment.
minor comments (2)
- [Experiments] Experiments section: Reported gains on AIME25 and AMC23 lack error bars, number of runs, or variance details, which would strengthen assessment of robustness.
- [Introduction] The abstract and introduction could more explicitly contrast LZE against prior online data selection or curriculum methods in RL for LLMs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Where clarifications or additions are warranted, we have revised the manuscript to strengthen the presentation of the LZE derivation and normalization details.
read point-by-point responses
-
Referee: [§3.2] §3.2 (LZE Score Derivation): The central claim that the closed-form LZE score is 'provably aligned' with the expected magnitude of GRPO updates lacks explicit derivation steps equating the fused signals (initial-difficulty anchor + normalized uncertainty + pass-rate momentum) to E[|advantage|] or the GRPO estimator. This alignment is load-bearing for the justification of bias-free data selection.
Authors: We agree that the original presentation would benefit from more explicit steps. In the revised manuscript we have expanded §3.2 with a full derivation (now also summarized in a new appendix) that starts from the GRPO advantage estimator, takes the expectation of its absolute value, and shows term-by-term that the initial-difficulty anchor supplies the baseline scale, the normalized uncertainty term bounds the outcome variance contribution, and the pass-rate momentum corrects for temporal drift, yielding an expression proportional to E[|advantage|] under standard assumptions on the group-relative baseline. This establishes the claimed alignment without introducing selection bias. revision: yes
-
Referee: [§3.1] §3.1 (Normalization): The normalization constants for the outcome-uncertainty term are not specified as fixed or batch-dependent; if data-dependent, this could undermine the claimed independence from the training distribution and the provable alignment.
Authors: The normalization constants are fixed hyperparameters chosen once from a small calibration set of prompts evaluated before the main training run; they are never recomputed from the current training batch or distribution. We have added an explicit statement to this effect in the revised §3.1, together with the precise numerical values used, thereby confirming that the independence property and the subsequent alignment proof remain intact. revision: yes
Circularity Check
No significant circularity in the claimed derivation.
full rationale
The paper defines the LZE score as a closed-form fusion of an initial-difficulty anchor, normalized outcome-uncertainty term, and pass-rate momentum, then asserts that this scalar is provably aligned with the expected magnitude of group-relative policy gradient updates. This alignment is presented as a theoretical property of the construction rather than a fitted parameter or self-citation. No equations in the provided abstract reduce the score to its inputs by construction, nor does the text invoke self-citations for uniqueness or load-bearing premises. The central claim retains independent content as a proposed online selection heuristic, with empirical results evaluated on external benchmarks (GSM8K, MATH, AIME25) separate from the score definition itself. This is the most common honest finding for a paper whose derivation is self-contained against external validation.
Axiom & Free-Parameter Ledger
free parameters (1)
- normalization constants or fusion coefficients for the three signals
axioms (1)
- domain assumption The three signals (initial-difficulty anchor, normalized outcome-uncertainty term, pass-rate momentum) are complementary and together identify the active learning frontier.
invented entities (1)
-
Learning-Zone Energy Score
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the uncertainty term is aligned with the expected GRPO gradient variance under a standard fixed-baseline approximation (Theorem 1)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
4p(1−p) ... peaks at p=0.5 and vanishes at both extremes
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Amro Abbas, Kushal Tirumala, Daniel Simig, Surya Ganguli, and Ari S. Morcos. Semd- edup: Data-efficient learning at web-scale through semantic deduplication.arXiv preprint arXiv:2303.09540, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
Deepseek AI. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081):633–638, September 2025. ISSN 1476-4687. doi: 10.1038/s41586-025-094 22-z
-
[3]
Knowledge-Centric Hallucination Detection
Ahmadian Arash, Cremer Chris, Gallé Matthias, Fadaee Marzieh, Kreutzer Julia, Pietquin Olivier, Üstün Ahmet, and Hooker Sara. Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12248–12267....
-
[4]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, pages 41–48, 2009. ISBN 9781605585161. doi: 10.1145/1553374.1553380
-
[5]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott G...
work page 1901
-
[6]
Alpagasus: Training a better alpaca with fewer data
Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, and Hongxia Jin. Alpagasus: Training a better alpaca with fewer data. InInternational Conference on Learning Representations (ICLR), pages 34767–34797, 2024
work page 2024
-
[7]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
work page 2021
-
[8]
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, KaShun SHUM, and Tong Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment.Transactions on Machine Learning Research, 2023. ISSN 2835-8856
work page 2023
-
[9]
Reinforced self-training (rest) for language modeling, 2023
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, Wolfgang Macherey, Arnaud Doucet, Orhan Firat, and Nando de Freitas. Reinforced self-training (rest) for language modeling, 2023
work page 2023
-
[10]
JustRL: Scaling a 1.5b LLM with a simple RL recipe, 2025
Bingxiang He, Zekai Qu, Zeyuan Liu, Yinghao Chen, Yuxin Zuo, Cheng Qian, Kaiyan Zhang, Weize Chen, Chaojun Xiao, Ganqu Cui, Ning Ding, and Zhiyuan Liu. JustRL: Scaling a 1.5b LLM with a simple RL recipe, 2025
work page 2025
-
[11]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InProceedings of the Neural Information Processing Systems Track on Datasets and Bench- marks, volume 1, 2021
work page 2021
-
[12]
Wouter Kool, Herke van Hoof, and Max Welling. Buy 4 REINFORCE samples, get a baseline for free! InDeep Reinforcement Learning Meets Structured Prediction, ICLR 2019 Workshop, New Orleans, Louisiana, United States, May 6, 2019, 2019. 10
work page 2019
-
[13]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[14]
Kumar, Benjamin Packer, and Daphne Koller
M. Kumar, Benjamin Packer, and Daphne Koller. Self-paced learning for latent variable models. InAdvances in Neural Information Processing Systems, volume 23, pages 1189–1197, 2010
work page 2010
-
[15]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In International Conference on Learning Representations (ICLR), pages 39578–39601, 2024
work page 2024
-
[16]
(2017) Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. In2017 IEEE International Conference on Computer Vision (ICCV), pages 2999–3007, 2017. doi: 10.1109/ICCV.2017.324
-
[17]
Not all tokens are what you need for pretraining
Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, Yelong Shen, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, and Weizhu Chen. Not all tokens are what you need for pretraining. InAdvances in Neural Information Processing Systems, volume 37, pages 29029–29063, 2024. doi: 10.52202/079017-0914
-
[18]
Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning. In International Conference on Learning Representations (ICLR), pages 22353–22373, 2024
work page 2024
-
[19]
Understanding r1-zero-like training: A critical perspective, 2025
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective, 2025
work page 2025
-
[20]
#instag: Instruction tagging for analyzing supervised fine-tuning of large language models
Keming Lu, Hongyi Yuan, Zheng Yuan, Runji Lin, Junyang Lin, Chuanqi Tan, Chang Zhou, and Jingren Zhou. #instag: Instruction tagging for analyzing supervised fine-tuning of large language models. InInternational Conference on Learning Representations (ICLR), pages 36456–36474, 2024
work page 2024
-
[21]
Dynamics-Predictive Sampling for Active RL Finetuning of Large Reasoning Models
Yixiu Mao, Yun Qu, Cheems Wang, Heming Zou, and Xiangyang Ji. Dynamics-Predictive Sampling for Active RL Finetuning of Large Reasoning Models. InInternational Conference on Learning Representations (ICLR), 2026
work page 2026
- [22]
-
[23]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
work page 2022
-
[24]
Iterative Reasoning Preference Optimization
Richard Yuanzhe Pang, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, and Jason Weston. Iterative Reasoning Preference Optimization. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 116617–116637. Curran Associates, Inc.,
-
[25]
doi: 10.52202/079017-3702
-
[26]
Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. Curiosity-driven explo- ration by self-supervised prediction. In2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 488–489, 2017. doi: 10.1109/CVPRW.2017.70
-
[27]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
work page 2017
-
[28]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. 11
work page 2024
-
[29]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297. ACM, March 2025. doi: 10.1145/3689031.3696075. URL http://dx.doi.org/10.1145/3 689031.3696075
-
[30]
Training region-based object detectors with online hard example mining
Abhinav Shrivastava, Abhinav Gupta, and Ross Girshick. Training region-based object detectors with online hard example mining. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 761–769, June 2016
work page 2016
-
[31]
Avi Singh, John D Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron T Parisi, Abhishek Kumar, Alexan- der A Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Fathy Elsayed, Hanie Sedghi, Igor Mordatch, Isabelle Simpson, Izzeddin Gur, Jasper Snoek, Jeffrey P...
work page 2024
-
[32]
Beyond neural scaling laws: beating power law scaling via data pruning
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari Morcos. Beyond neural scaling laws: beating power law scaling via data pruning. InAdvances in Neural Information Processing Systems, volume 35, pages 19523–19536, 2022
work page 2022
-
[33]
Solving math word problems with process- and outcome-based feedback, 2022
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback, 2022
work page 2022
-
[34]
Learning from mistakes via cooperative study assistant for large language models
Danqing Wang and Lei Li. Learning from mistakes via cooperative study assistant for large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10667–10685, December 2023. doi: 10.18653/v1/2023.emnlp-m ain.659
-
[35]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[36]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837, 2022
work page 2022
-
[37]
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist re- inforcement learning.Mach. Learn., 8(3-4):229–256, May 1992. ISSN 0885-6125. doi: 10.1007/BF00992696
-
[38]
LESS: Selecting influential data for targeted instruction tuning
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. LESS: Selecting influential data for targeted instruction tuning. InForty-first International Conference on Machine Learning, Proceedings of Machine Learning Research, pages 54104–54132, 2024
work page 2024
-
[39]
Data selection for language models via importance resampling
Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy S Liang. Data selection for language models via importance resampling. InAdvances in Neural Information Processing Systems, volume 36, pages 34201–34227, 2023
work page 2023
-
[40]
A minimalist approach to LLM reasoning: from rejection sampling to reinforce, 2025
Wei Xiong, Jiarui Yao, Yuhui Xu, Bo Pang, Lei Wang, Doyen Sahoo, Junnan Li, Nan Jiang, Tong Zhang, Caiming Xiong, and Hanze Dong. A minimalist approach to LLM reasoning: from rejection sampling to reinforce, 2025
work page 2025
-
[41]
Qwen2.5 technical report, 2024
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page 2024
-
[42]
Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, 2024
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, 2024
work page 2024
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page 2025
-
[44]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 11809–11822. Curran Associates, Inc., 2023
work page 2023
-
[45]
Dapo: An open-source llm reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, juncai liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao...
work page 2025
-
[46]
Self-rewarding language models, 2024
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models, 2024
work page 2024
-
[47]
Scaling relationship on learning mathematical reasoning with large language models, 2023
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models, 2023
work page 2023
-
[48]
Star: Bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 15476–15488. Curran Associates, Inc., 2022
work page 2022
-
[49]
Generative verifiers: Reward modeling as next-token prediction
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Seyed Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative verifiers: Reward modeling as next-token prediction. InInterna- tional Conference on Learning Representations (ICLR), pages 12476–12505, 2025
work page 2025
-
[50]
Lima: Less is more for alignment
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, LILI YU, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. Lima: Less is more for alignment. InAdvances in Neural Information Processing Systems, volume 36, pages 55006–55021, 2023. 13 Appendices A Case Study: Data Selection Ra...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.