Why Do Safety Guardrails Degrade Across Languages?
Pith reviewed 2026-05-20 14:13 UTC · model grok-4.3
The pith
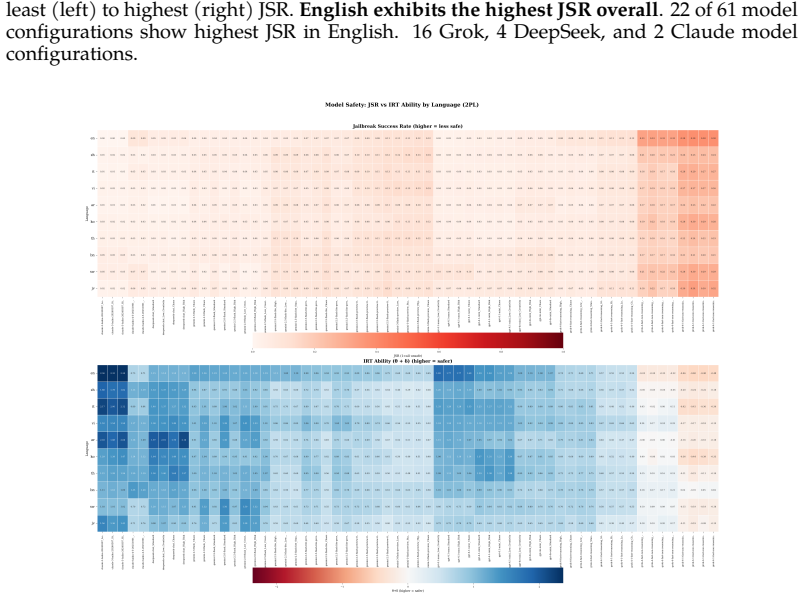
A statistical model shows safety failures in language models are often worse in English than low-resource languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Multi-Group IRT framework decouples safety-driving factors such as language-agnostic safety robustness, intrinsic prompt hardness, global language processing difficulty, and a prompt-specific cross-lingual safety gap. Exploratory Factor Analysis shows safety is primarily unidimensional. Across 61 model configurations and 10 languages, 22 configurations are more vulnerable in English than in low-resource languages. Low-resource languages produce more uncertain responses. High-gap prompts cluster in physical harm categories and lower-resource languages. The framework achieves AUC of 0.940 in predicting safe refusal.
What carries the argument
Multi-Group Item Response Theory framework that separates four latent factors to model the probability a model refuses an unsafe prompt.
Load-bearing premise
That four underlying factors are enough to explain all variation in refusal behavior and that a statistical check correctly shows safety works as one single trait across different harm types.
What would settle it
Refusal data collected on a fresh set of languages or prompt types where the model's predicted refusal rates deviate substantially from what actually happens, dropping predictive accuracy well below the reported level.
Figures

































read the original abstract
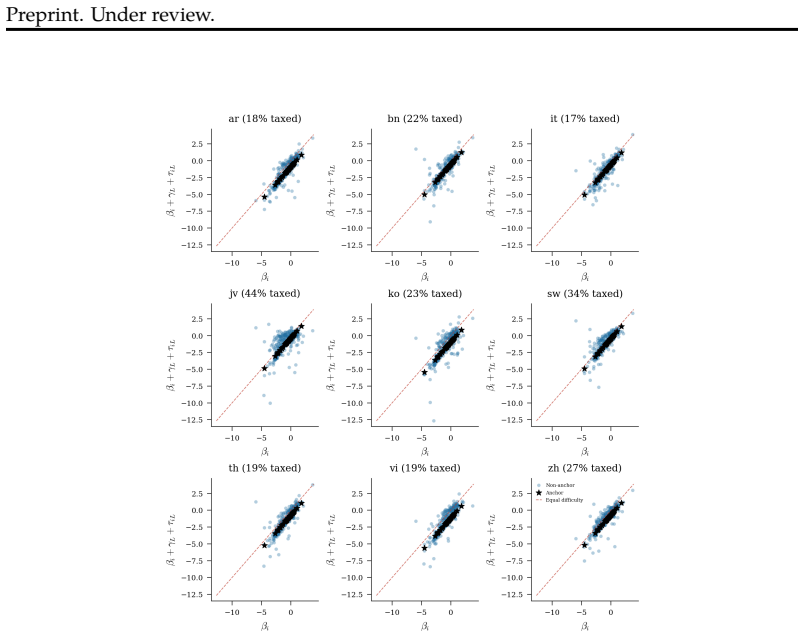
Large language models exhibit safety degradation in non-English languages. Standard evaluation relies on Jailbreak Success Rate (JSR), which confounds several safety-driving factors into one, obscuring the specific cause(s) of safety failure. We introduce a latent variable model, a Multi-Group Item Response Theory (IRT) framework, that decouples safety-driving factors such as language-agnostic safety robustness ($\theta$), intrinsic prompt hardness ($\beta$), global language processing difficulty ($\gamma$), and a prompt-specific cross-lingual safety gap ($\tau$). Using the MultiJail dataset, we evaluate the safety robustness of 61 model configurations across 5 closed-model families and 10 languages of varying resource, aggregating a dataset of 1.9 million rows. Exploratory Factor Analysis shows safety is primarily unidimensional: models refuse different harm types mainly through a shared mechanism. Contrary to the expected trend that safety degrades largely in low-resource languages, 22 model configurations are more vulnerable in English than in low-resource languages. Low-resource languages produce more uncertain responses (high entropy) than high-resource languages. Also, high-$\tau$ prompts cluster in physical harm categories like Theft and Weapons and lower-resource languages, trends validated through cross-dataset generalization. While global translation quality shows low correlation with $\tau$, severe mistranslations drive high-bias outliers, as validated by native speakers. Cultural and conceptual grounding mismatches also contribute to $\tau$. In predictive validation, the IRT framework achieves $\mathrm{AUC} = 0.940$, outperforming simpler baselines in predicting safe refusal of unsafe prompts. Our framework reveals concept-language vulnerabilities that aggregate metrics obscure, enabling fairer cross-lingual safety evaluation and targeted improvements in dataset construction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Multi-Group Item Response Theory (IRT) framework to decouple factors behind safety degradation in LLMs across languages, including language-agnostic robustness (theta), prompt hardness (beta), language difficulty (gamma), and cross-lingual safety gap (tau). Analyzing 1.9 million rows from the MultiJail dataset across 61 model configurations and 10 languages, Exploratory Factor Analysis indicates safety is primarily unidimensional. The study finds that 22 model configurations are more vulnerable in English than in low-resource languages, with high-tau prompts clustering in physical harm categories, and achieves an AUC of 0.940 in predicting safe refusals.
Significance. If the IRT model assumptions hold, particularly the unidimensionality of safety and the validity of the four latent factors, this work offers a significant advance over aggregate metrics like Jailbreak Success Rate by providing interpretable, disentangled insights into cross-lingual safety vulnerabilities. The large-scale evaluation and strong predictive performance support its potential to inform targeted improvements in multilingual safety alignment and dataset design. The counter-intuitive finding regarding English vulnerability and the analysis of mistranslations add novel perspectives.
major comments (2)
- [Exploratory Factor Analysis] The claim that safety is primarily unidimensional rests on EFA results, but without reporting the variance explained by the first factor or conducting tests for residual correlations between harm categories, it is unclear whether local independence holds. This is critical because unmodeled correlations (e.g., in physical harm prompts due to translation artifacts) could affect the reliability of the prompt-specific tau parameter and the interpretation of cross-lingual gaps.
- [Multi-Group IRT framework] The four latent factors (theta, beta, gamma, tau) are estimated from the refusal data; while held-out predictive validation is reported, the manuscript lacks uncertainty quantification on the latent variable estimates themselves. This weakens the post-hoc interpretations of tau clusters and the identification of 22 model configurations more vulnerable in English.
minor comments (2)
- [Abstract] The abstract mentions 'high-τ prompts cluster in physical harm categories like Theft and Weapons and lower-resource languages'; consider specifying the exact clustering method or threshold used for 'high-τ'.
- [Methods] Clarify the definition and estimation procedure for the global language processing difficulty parameter γ in the IRT model equations.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and valuable suggestions. Below, we provide point-by-point responses to the major comments and describe the revisions we plan to implement.
read point-by-point responses
-
Referee: [Exploratory Factor Analysis] The claim that safety is primarily unidimensional rests on EFA results, but without reporting the variance explained by the first factor or conducting tests for residual correlations between harm categories, it is unclear whether local independence holds. This is critical because unmodeled correlations (e.g., in physical harm prompts due to translation artifacts) could affect the reliability of the prompt-specific tau parameter and the interpretation of cross-lingual gaps.
Authors: We agree that reporting the variance explained by the first factor and assessing residual correlations would enhance the support for unidimensionality and local independence. We will include these analyses in the revised manuscript, specifically reporting the proportion of variance explained and examining residual correlations among harm categories to ensure they do not undermine the tau parameter interpretations. revision: yes
-
Referee: [Multi-Group IRT framework] The four latent factors (theta, beta, gamma, tau) are estimated from the refusal data; while held-out predictive validation is reported, the manuscript lacks uncertainty quantification on the latent variable estimates themselves. This weakens the post-hoc interpretations of tau clusters and the identification of 22 model configurations more vulnerable in English.
Authors: We acknowledge that uncertainty quantification on the latent estimates would bolster the post-hoc analyses. We will incorporate this in the revision by providing standard errors or confidence intervals for the estimated factors, particularly for tau and the identification of vulnerable models, using appropriate statistical methods from the IRT framework. revision: yes
Circularity Check
No significant circularity in Multi-Group IRT derivation
full rationale
The paper fits a Multi-Group IRT model to refusal data from the MultiJail dataset and applies Exploratory Factor Analysis to assess unidimensionality of safety. The key results, including the reported AUC of 0.940 for predicting safe refusal, rely on predictive validation using held-out prompts that is independent of the fitted parameters used for interpretation. No equations or steps reduce by construction to the inputs, no self-citations are load-bearing for the central claims, and the framework uses standard latent variable techniques without self-definitional loops or renaming of known results. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- language-agnostic safety robustness (theta)
- prompt-specific cross-lingual safety gap (tau)
axioms (1)
- domain assumption Safety refusal behavior is adequately captured by a unidimensional latent trait plus three additional factors.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a latent variable model, a Multi-Group Item Response Theory (IRT) framework, that decouples safety-driving factors such as language-agnostic safety robustness (θ), intrinsic prompt hardness (β), global language processing difficulty (γ), and a prompt-specific cross-lingual safety gap (τ).
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Exploratory Factor Analysis shows safety is primarily unidimensional: models refuse different harm types mainly through a shared mechanism.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Wang, Wenxuan and Tu, Zhaopeng and Chen, Chang and Yuan, Youliang and Huang, Jen-tse and Jiao, Wenxiang and Lyu, Michael R. , month = jun, year =. All. doi:10.48550/arXiv.2310.00905 , abstract =
-
[2]
An. Psychometrika , author =. 1974 , pages =. doi:10.1007/BF02291575 , abstract =
-
[3]
Educational and Psychological Measurement , author =
Anchor. Educational and Psychological Measurement , author =. 2015 , pages =. doi:10.1177/0013164414529792 , abstract =
-
[4]
Lord, F. M. , month = nov, year =. Applications of. doi:10.4324/9780203056615 , language =
-
[5]
Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation
Huang, Yangsibo and Gupta, Samyak and Xia, Mengzhou and Li, Kai and Chen, Danqi , month = oct, year =. Catastrophic. doi:10.48550/arXiv.2310.06987 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06987
-
[6]
Rei, Ricardo and C. De Souza, José G. and Alves, Duarte and Zerva, Chrysoula and Farinha, Ana C and Glushkova, Taisiya and Lavie, Alon and Coheur, Luisa and Martins, André F. T. , year =. Proceedings of the. doi:10.18653/v1/2022.wmt-1.52 , language =
-
[7]
Cometkiwi: Ist-unbabel 2022 submission for the quality estimation shared task
Rei, Ricardo and Treviso, Marcos and Guerreiro, Nuno M. and Zerva, Chrysoula and Farinha, Ana C. and Maroti, Christine and Souza, José G. C. de and Glushkova, Taisiya and Alves, Duarte M. and Lavie, Alon and Coheur, Luisa and Martins, André F. T. , month = sep, year =. doi:10.48550/arXiv.2209.06243 , abstract =
-
[8]
Feder and Barocas, Solon and Palia, Abhinav and Vann, Dan and Wallach, Hanna , month = jan, year =
Chouldechova, Alexandra and Cooper, A. Feder and Barocas, Solon and Palia, Abhinav and Vann, Dan and Wallach, Hanna , month = jan, year =. Comparison Requires Valid Measurement:. doi:10.48550/arXiv.2601.18076 , abstract =
-
[9]
Peng, Qiwei and Søgaard, Anders , month = oct, year =. Concept. doi:10.48550/arXiv.2410.01079 , abstract =
-
[10]
Applied Psychological Measurement , author =
Effects of. Applied Psychological Measurement , author =. 1984 , pages =. doi:10.1177/014662168400800201 , abstract =
-
[11]
doi:10.1002/j.2333-8504.1968.tb00153.x , abstract =
ETS Research Bulletin Series , author =. doi:10.1002/j.2333-8504.1968.tb00153.x , abstract =
-
[12]
Truong, Sang and Tu, Yuheng and Hardy, Michael and Reuel, Anka and Tang, Zeyu and Burapacheep, Jirayu and Perera, Jonathan and Uwakwe, Chibuike and Domingue, Ben and Haber, Nick and Koyejo, Sanmi , month = nov, year =. Fantastic. doi:10.48550/arXiv.2511.16842 , abstract =
-
[13]
The American Journal of Psychology , author =
". The American Journal of Psychology , author =. 1904 , pages =. doi:10.2307/1412107 , number =
-
[14]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , month = dec, year =. Judging. doi:10.48550/arXiv.2306.05685 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685
-
[15]
Language-agnostic BERT sentence embedding, 2022
Feng, Fangxiaoyu and Yang, Yinfei and Cer, Daniel and Arivazhagan, Naveen and Wang, Wei , month = mar, year =. Language-agnostic. doi:10.48550/arXiv.2007.01852 , abstract =
-
[16]
doi:10.48550/arXiv.2508.12733 , abstract =
Ning, Zhiyuan and Gu, Tianle and Song, Jiaxin and Hong, Shixin and Li, Lingyu and Liu, Huacan and Li, Jie and Wang, Yixu and Lingyu, Meng and Teng, Yan and Wang, Yingchun , month = aug, year =. doi:10.48550/arXiv.2508.12733 , abstract =
-
[17]
Educational and Psychological Measurement , author =
Little. Educational and Psychological Measurement , author =. 1974 , pages =. doi:10.1177/001316447403400115 , language =
-
[18]
Multilingualjailbreakchallengesinlargelanguagemodels
Deng, Yue and Zhang, Wenxuan and Pan, Sinno Jialin and Bing, Lidong , month = mar, year =. Multilingual. doi:10.48550/arXiv.2310.06474 , abstract =
-
[19]
Spiliopoulou, Evangelia and Fogliato, Riccardo and Burnsky, Hanna and Soliman, Tamer and Ma, Jie and Horwood, Graham and Ballesteros, Miguel , month = aug, year =. Play. doi:10.48550/arXiv.2508.06709 , abstract =
-
[20]
Pyro: Deep Universal Probabilistic Programming
Bingham, Eli and Chen, Jonathan P. and Jankowiak, Martin and Obermeyer, Fritz and Pradhan, Neeraj and Karaletsos, Theofanis and Singh, Rohit and Szerlip, Paul and Horsfall, Paul and Goodman, Noah D. , month = oct, year =. Pyro:. doi:10.48550/arXiv.1810.09538 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.09538
-
[21]
Wang, Xinpeng and Wang, Mingyang and Liu, Yihong and Schütze, Hinrich and Plank, Barbara , month = feb, year =. Refusal. doi:10.48550/arXiv.2505.17306 , abstract =
-
[22]
doi:10.4324/9780203357811 , url =
Differential Item Functioning , year =. doi:10.4324/9780203357811 , url =
-
[23]
Kendall,M. G. , title =. 1948 , pages =
work page 1948
-
[24]
Refusal in Language Models Is Mediated by a Single Direction
Arditi, Andy and Obeso, Oscar and Syed, Aaquib and Paleka, Daniel and Panickssery, Nina and Gurnee, Wes and Nanda, Neel , month = oct, year =. Refusal in. doi:10.48550/arXiv.2406.11717 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.11717
-
[25]
Truong, Sang and Tu, Yuheng and Liang, Percy and Li, Bo and Koyejo, Sanmi , month = mar, year =. Reliable and. doi:10.48550/arXiv.2503.13335 , abstract =
-
[26]
Chen, Hongyu and Goldfarb-Tarrant, Seraphina , month = jul, year =. Safer or. doi:10.48550/arXiv.2503.09347 , abstract =
- [27]
-
[28]
Wollschläger, Tom and Elstner, Jannes and Geisler, Simon and Cohen-Addad, Vincent and Günnemann, Stephan and Gasteiger, Johannes , month = feb, year =. The. doi:10.48550/arXiv.2502.17420 , abstract =
-
[29]
Pan, Wenbo and Liu, Zhichao and Chen, Qiguang and Zhou, Xiangyang and Yu, Haining and Jia, Xiaohua , month = may, year =. The. doi:10.48550/arXiv.2502.09674 , abstract =
-
[30]
Larsen, Erik , month = dec, year =. The. doi:10.48550/arXiv.2512.12066 , abstract =
-
[31]
Journal of the American Statistical Association , year =
Variational. Journal of the American Statistical Association , author =. 2017 , pages =. doi:10.1080/01621459.2017.1285773 , language =
-
[32]
He, Luxi and Xia, Mengzhou and Henderson, Peter , month = aug, year =. What is in. doi:10.48550/arXiv.2404.01099 , abstract =
-
[33]
and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, André F
Guerreiro, Nuno M. and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, André F. T. , month = oct, year =. doi:10.48550/arXiv.2310.10482 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.