PromptAudit: Auditing Prompt Sensitivity in LLM-Based Vulnerability Detection
Pith reviewed 2026-06-30 16:22 UTC · model grok-4.3
The pith
Vulnerability detection behavior in LLMs is jointly determined by the model and the prompt used.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
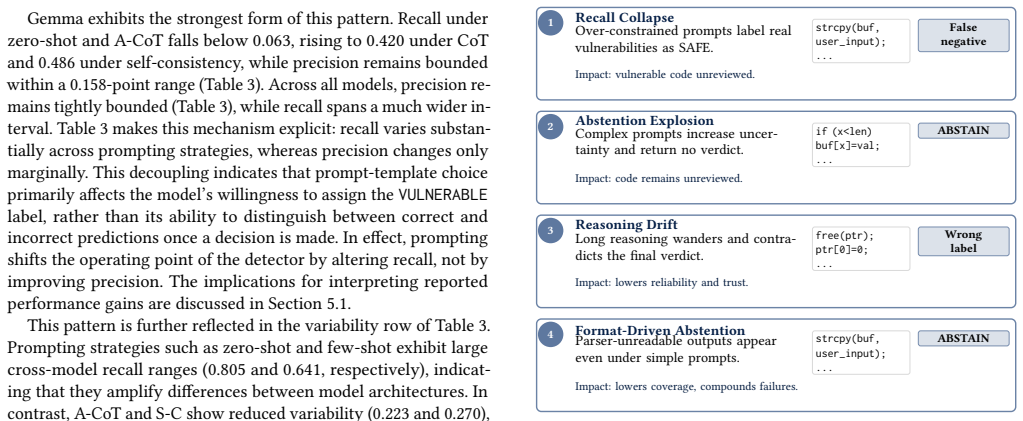
PromptAudit shows that LLM vulnerability detection performance varies with prompting strategy in model-specific ways. Standard chain-of-thought achieves the best operational metrics, few-shot prompting yields benefits concentrated in prompt-sensitive models, adaptive chain-of-thought suppresses recall, and self-consistency drives high abstention that lowers effective F1. These patterns establish that detection outcomes arise from the interaction of model and prompt rather than from either factor alone.
What carries the argument
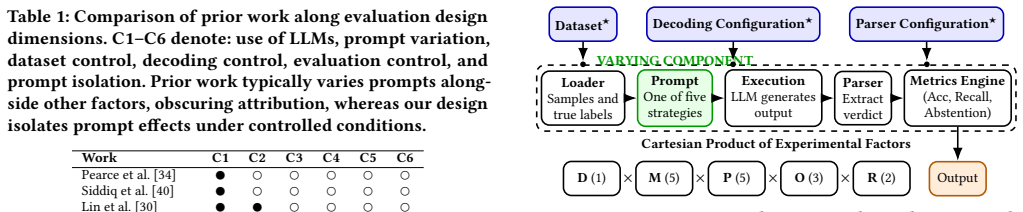
The PromptAudit controlled evaluation framework that isolates prompt effects by fixing dataset, decoding parameters, and output parsing while varying only the prompting strategy across accuracy, recall, abstention, coverage, and effective F1.
If this is right
- Standard chain-of-thought prompting produces the strongest overall operational performance across models.
- Few-shot prompting delivers benefits that appear mainly in models already shown to be prompt-sensitive.
- Adaptive chain-of-thought prompting reduces recall and should be avoided for this task.
- Self-consistency prompting produces excessive abstention that sharply lowers effective F1.
- Prompt sensitivity must be characterized explicitly during both evaluation and deployment of LLM vulnerability detectors.
Where Pith is reading between the lines
- The same joint model-prompt determination likely appears in other LLM code tasks such as repair or summarization, suggesting PromptAudit-style auditing could apply more broadly.
- Security teams may need model-specific prompt libraries instead of one-size-fits-all strategies.
- Model updates or fine-tuning would require repeating prompt audits to preserve detection behavior.
- Benchmarks for LLM security tools could add prompt variation as a required evaluation axis.
Load-bearing premise
Holding the dataset, decoding, and parsing fixed while varying only the prompt fully isolates prompt effects and the chosen metrics reflect real security workflow performance.
What would settle it
A deployment test on the same models and CVE data where the ranking of prompting strategies by effective F1 differs from the controlled PromptAudit ordering.
Figures




read the original abstract
Large language models are increasingly used for vulnerability detection, yet their reliability under different prompt formulations remains uncharacterized. We present PromptAudit, a controlled evaluation framework that isolates prompt effects by fixing the dataset, decoding, and parsing while varying only the prompting strategy. Using five prompting strategies across five open-weight models on 1,000 CVEs (6,074 code samples spanning 16 programming languages), we evaluate accuracy, recall, abstention, coverage, and effective F1. We find that standard chain-of-thought prompting achieves the strongest overall operational performance, while few-shot prompting provides model-dependent benefits that are most pronounced for prompt-sensitive models. In contrast, adaptive chain-of-thought frequently suppresses recall and self-consistency induces excessive abstention, sharply reducing effective performance. These results show that vulnerability detection behavior is jointly determined by the model and the prompt, and that prompt sensitivity is a first-class system property that must be explicitly characterized in evaluation and deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PromptAudit, a controlled evaluation framework for LLM-based vulnerability detection that isolates prompt effects by holding the dataset (1,000 CVEs, 6,074 samples across 16 languages), decoding, and parsing fixed while varying only the prompting strategy. Across five strategies (standard CoT, adaptive CoT, few-shot, self-consistency, and baseline) and five open-weight models, the authors evaluate accuracy, recall, abstention, coverage, and effective F1, reporting that standard chain-of-thought achieves the strongest overall performance, few-shot benefits are model-dependent, and adaptive CoT/self-consistency degrade recall or induce excessive abstention. The central claim is that detection behavior is jointly determined by model and prompt, making prompt sensitivity a first-class property requiring explicit characterization in evaluation and deployment.
Significance. If the isolation of prompt effects holds, the work supplies concrete evidence that prompt choice materially affects operational metrics in security workflows and that model-prompt interactions are not uniform, supporting the need for prompt-audit protocols in LLM security tooling. The emphasis on effective F1 (which incorporates abstention) and coverage is a methodological strength for translating results to deployment contexts.
major comments (1)
- [Abstract] Abstract: The claim that 'fixing ... parsing while varying only the prompting strategy' fully isolates prompt effects is load-bearing for the central claim but rests on an unverified assumption. Standard CoT, adaptive CoT, few-shot, and self-consistency strategies typically elicit outputs with distinct structures, lengths, and delimiters; a single fixed parser applied uniformly therefore risks differential parsing success rates that are artifacts of format compatibility rather than intrinsic model-prompt interaction. Without explicit verification that the parser was not tuned per strategy and that coverage differences are not driven by parsing robustness, the reported performance gaps cannot be attributed solely to prompt sensitivity.
minor comments (2)
- [Abstract] Abstract: The definition and computation of 'effective F1' (including how abstention thresholds are set) are not stated, making it impossible to assess whether the metric meaningfully reflects operational performance.
- [Abstract] Abstract: No numerical results, statistical tests, or error bars are supplied despite the headline findings on relative strategy performance; these details are required to evaluate support for the model-dependent claims.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of rigorously verifying that our fixed parser does not introduce differential success rates across prompting strategies. This is a substantive methodological point that bears directly on the isolation claim. We respond below and will revise the manuscript to include the requested verification.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'fixing ... parsing while varying only the prompting strategy' fully isolates prompt effects is load-bearing for the central claim but rests on an unverified assumption. Standard CoT, adaptive CoT, few-shot, and self-consistency strategies typically elicit outputs with distinct structures, lengths, and delimiters; a single fixed parser applied uniformly therefore risks differential parsing success rates that are artifacts of format compatibility rather than intrinsic model-prompt interaction. Without explicit verification that the parser was not tuned per strategy and that coverage differences are not driven by parsing robustness, the reported performance gaps cannot be attributed solely to prompt sensitivity.
Authors: We agree that explicit verification is necessary to support the isolation claim. The parser in PromptAudit is a single, fixed implementation (a combination of regex patterns for common delimiters and JSON extraction fallbacks) that was not tuned or customized per prompting strategy; the same code was applied uniformly. However, the manuscript does not currently report per-strategy parsing success rates or an ablation isolating parsing failures from model abstention. We will add this verification in the revised version, including (1) parsing success rates broken down by strategy and model, (2) confirmation that any parsing failure is treated as abstention (and thus reflected in coverage and effective F1), and (3) a sensitivity check recomputing metrics only on successfully parsed outputs. If these checks reveal that coverage gaps are partly driven by format compatibility, we will qualify the isolation claim accordingly. This addresses the concern without altering the core experimental design. revision: yes
Circularity Check
No circularity: purely empirical comparison
full rationale
The paper conducts a controlled empirical evaluation that holds dataset, decoding, and parsing fixed while varying only prompting strategies across models and reports observed differences in accuracy, recall, abstention, coverage, and effective F1. No derivations, equations, fitted parameters, predictions derived from inputs, or self-citations appear in the provided text or abstract. The central claim that vulnerability detection is jointly determined by model and prompt follows directly from the experimental design and results without reduction to any self-defined or self-cited quantity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hattan Althebeiti, Mohammed Alkinoon, Manar Mohaisen, Saeed Salem, Dae- Hun Nyang, and David Mohaisen. 2025. Enhancing Vulnerability Reports with Automated and Augmented Description Summarization.IEEE Transactions on Big Data(2025)
2025
-
[2]
Hattan Althebeiti, Brett Fazio, William Chen, Jamen Park, and David Mohaisen
-
[3]
Mujaz: A Summarization-based Approach for Normalized Vulnerability Description.IEEE Transactions on Dependable and Secure Computing(2025)
2025
-
[4]
Daniel Arp, Erwin Quiring, Feargus Pendlebury, Alexander Warnecke, Fabio Pierazzi, Christian Wressnegger, Lorenzo Cavallaro, and Konrad Rieck. 2022. Dos and don’ts of machine learning in computer security. In31st USENIX Security Symposium (USENIX Security 22). 3971–3988
2022
-
[5]
2024.From Vulnerabilities to Remediation: A Systematic Literature Review of LLMs in Code Security
Enna Basic and Alberto Giaretta. 2024.From Vulnerabilities to Remediation: A Systematic Literature Review of LLMs in Code Security. https://doi.org/10.48550/ arXiv.2412.15004
-
[6]
Guru Bhandari, Amara Naseer, and Leon Moonen. 2021. CVEfixes: automated collection of vulnerabilities and their fixes from open-source software. InProceed- ings of the 17th International Conference on Predictive Models and Data Analytics in Software Engineering (PROMISE 2021). Association for Computing Machinery, New York, NY, USA, 30–39. https://doi.org/...
-
[7]
Saikat Chakraborty, Rahul Krishna, Yangruibo Ding, and Baishakhi Ray. 2021. Deep learning based vulnerability detection: Are we there yet?IEEE Transactions on Software Engineering48, 9 (2021), 3280–3296
2021
-
[8]
Anwoy Chatterjee, H S V N S Kowndinya Renduchintala, Sumit Bhatia, and Tan- moy Chakraborty. 2024. POSIX: A Prompt Sensitivity Index For Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2024. Association for Computational Linguistics, Miami, Florida, USA, 14550–14565. https://doi.org/10.18653/v1/2024.findings-emnlp.852
- [9]
-
[10]
Yizheng Chen, Zhoujie Ding, Lamya Alowain, Xinyun Chen, and David Wagner
-
[11]
InProceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses
DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection. InProceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses. ACM, Hong Kong China, 654–668. https://doi.org/10.1145/3607199.3607242
-
[12]
2007.Secure programming with static analysis
Brian Chess and Jacob West. 2007.Secure programming with static analysis. Pearson Education
2007
-
[13]
Xiaohu Du, Ming Wen, Jiahao Zhu, Zifan Xie, Bin Ji, Huijun Liu, Xuanhua Shi, and Hai Jin. 2024. Generalization-Enhanced Code Vulnerability Detection via Multi- Task Instruction Fine-Tuning. InFindings of the Association for Computational Lin- guistics ACL 2024. Association for Computational Linguistics, Bangkok, Thailand and virtual meeting, 10507–10521. ...
-
[14]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. 2023. Large language models for software engineer- ing: Survey and open problems. In2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE, 31–53
2023
-
[15]
Jiahao Fan, Yi Li, Shaohua Wang, and Tien N. Nguyen. 2020. A C/C++ Code Vulnerability Dataset with Code Changes and CVE Summaries. InProceedings of the 17th International Conference on Mining Software Repositories (MSR ’20). Association for Computing Machinery, New York, NY, USA, 508–512. https: //doi.org/10.1145/3379597.3387501
-
[16]
Z Feng. 2020. Codebert: A pre-trained model for program-ming and natural languages.arXiv preprint arXiv:2002.08155(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[17]
Michael Fu and Chakkrit Tantithamthavorn. 2022. LineVul: a transformer-based line-level vulnerability prediction. InProceedings of the 19th International Con- ference on Mining Software Repositories. ACM, Pittsburgh Pennsylvania, 608–620. https://doi.org/10.1145/3524842.3528452
-
[18]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, et al. 2020. Graphcodebert: Pre-training code representations with data flow.arXiv preprint arXiv:2009.08366 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al . 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Hazim Hanif and Sergio Maffeis. 2022. Vulberta: Simplified source code pre- training for vulnerability detection. In2022 International joint conference on neural networks (IJCNN). IEEE, 1–8
2022
-
[21]
Jingxuan He and Martin Vechev. 2023. Large Language Models for Code: Security Hardening and Adversarial Testing. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security (CCS ’23). Association for Computing Machinery, New York, NY, USA, 1865–1879. https://doi.org/10.1145/ 3576915.3623175
-
[22]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[23]
Andong Hua, Kenan Tang, Chenhe Gu, Jindong Gu, Eric Wong, and Yao Qin. [n. d.]. Flaw or Artifact? Rethinking Prompt Sensitivity in Evaluating LLMs. ([n. d.])
-
[24]
Xuefeng Jiang, Lvhua Wu, Sheng Sun, Jia Li, Jingjing Xue, Yuwei Wang, Tingting Wu, and Min Liu. 2025. Investigating Large Language Models for Code Vulnerabil- ity Detection: An Experimental Study. https://doi.org/10.48550/arXiv.2412.18260 arXiv:2412.18260 [cs]
-
[25]
Brittany Johnson, Yoonki Song, Emerson Murphy-Hill, and Robert Bowdidge
-
[26]
In 2013 35th International Conference on Software Engineering (ICSE)
Why don’t software developers use static analysis tools to find bugs?. In 2013 35th International Conference on Software Engineering (ICSE). IEEE, 672–681
2013
-
[27]
Mohammed F Kharma, Soohyeon Choi, Mohammad Alkhanafseh, and David Mohaisen. 2026. Security and quality in llm-generated code: A multi-language, multi-model analysis.IEEE Transactions on Dependable and Secure Computing (2026)
2026
-
[28]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners.Advances in neural information processing systems35 (2022), 22199–22213
2022
-
[29]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. Starcoder: may the source be with you!arXiv preprint arXiv:2305.06161(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Ziyang Li, Saikat Dutta, and Mayur Naik. 2025. IRIS: LLM-Assisted Static Analysis for Detecting Security Vulnerabilities.International Conference on Representation Learning2025 (May 2025), 35735–35758
2025
-
[31]
Zhen Li, Deqing Zou, Shouhuai Xu, Xinyu Ou, Hai Jin, Sujuan Wang, Zhijun Deng, and Yuyi Zhong. 2018. VulDeePecker: A Deep Learning-Based System for Vulnerability Detection. InProceedings 2018 Network and Distributed System Security Symposium. https://doi.org/10.14722/ndss.2018.23158 arXiv:1801.01681 [cs]
-
[32]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michi- hiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hud- son, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Ho...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.09110 2023
-
[33]
Jie Lin and David Mohaisen. 2025. From Large to Mammoth: A Comparative Evaluation of Large Language Models in Zero-Shot Vulnerability Detection. In Proceedings 2025 Network and Distributed System Security Symposium. Internet Society, San Diego, CA, USA. https://doi.org/10.14722/ndss.2025.241491
-
[34]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173
2024
-
[35]
Lilian Ngweta, Kiran Kate, Jason Tsay, and Yara Rizk. 2025. Towards LLMs Robustness to Changes in Prompt Format Styles. https://doi.org/10.48550/arXiv. 2504.06969 arXiv:2504.06969 [cs]
work page internal anchor Pith review doi:10.48550/arxiv 2025
- [36]
-
[37]
Hammond Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, and Brendan Dolan-Gavitt. 2023. Examining zero-shot vulnerability repair with large language models. In2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2339–2356
2023
- [38]
-
[39]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Rebecca Russell, Louis Kim, Lei Hamilton, Tomo Lazovich, Jacob Harer, Onur Ozdemir, Paul Ellingwood, and Marc McConley. 2018. Automated vulnerability detection in source code using deep representation learning. In2018 17th IEEE international conference on machine learning and applications (ICMLA). IEEE, 757–762
2018
-
[41]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2024. Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I 13 learned to start worrying about prompt formatting.International Conference on Representation Learning2024 (May 2024), 25055–25083
2024
-
[42]
Konstantin Serebryany, Derek Bruening, Alexander Potapenko, and Dmitriy Vyukov. 2012. {AddressSanitizer}: A fast address sanity checker. In2012 USENIX annual technical conference (USENIX ATC 12). 309–318
2012
-
[43]
Mohammed Latif Siddiq, Shafayat H Majumder, Maisha R Mim, Sourov Jajodia, and Joanna CS Santos. 2022. An empirical study of code smells in transformer- based code generation techniques. In2022 IEEE 22nd International Working Conference on Source Code Analysis and Manipulation (SCAM). IEEE, 71–82
2022
-
[44]
Benjamin Steenhoek, Md Mahbubur Rahman, Richard Jiles, and Wei Le. 2023. An Empirical Study of Deep Learning Models for Vulnerability Detection. In Proceedings of the 45th International Conference on Software Engineering (ICSE ’23). IEEE Press, Melbourne, Victoria, Australia, 2237–2248. https://doi.org/10. 1109/ICSE48619.2023.00188
-
[45]
Saad Ullah, Mingji Han, Saurabh Pujar, Hammond Pearce, Ayse Coskun, and Gianluca Stringhini. 2024. Llms cannot reliably identify and reason about security vulnerabilities (yet?): A comprehensive evaluation, framework, and benchmarks. In2024 IEEE symposium on security and privacy (SP). IEEE, 862–880
2024
-
[46]
John Viega, Jon-Thomas Bloch, Yoshi Kohno, and Gary McGraw. 2000. ITS4: A static vulnerability scanner for C and C++ code. InProceedings 16th Annual Computer Security Applications Conference (ACSAC’00). IEEE, 257–267
2000
-
[47]
Xingchen Wan, Ruoxi Sun, Hanjun Dai, Sercan O. Arik, and Tomas Pfis- ter. 2023. Better Zero-Shot Reasoning with Self-Adaptive Prompting. arXiv:2305.14106 [cs.CL] https://arxiv.org/abs/2305.14106
-
[48]
Xingchen Wan, Ruoxi Sun, Hootan Nakhost, Hanjun Dai, Julian Martin Eisensch- los, Sercan O. Arik, and Tomas Pfister. 2023. Universal Self-Adaptive Prompting. arXiv:2305.14926 [cs.CL] https://arxiv.org/abs/2305.14926
-
[49]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. https://doi.org/10.48550/ arXiv.2203.11171 arXiv:2203.11171 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in neural information processing systems 35 (2022), 24824–24837
2022
-
[51]
Jules White, Sam Hays, Quchen Fu, Jesse Spencer-Smith, and Douglas C Schmidt
-
[52]
InGenerative AI for Effective Software Development
Chatgpt prompt patterns for improving code quality, refactoring, require- ments elicitation, and software design. InGenerative AI for Effective Software Development. Springer, 71–108
-
[53]
Chenyuan Yang, Zijie Zhao, Zichen Xie, Haoyu Li, and Lingming Zhang. 2025. KNighter: Transforming Static Analysis with LLM-Synthesized Checkers. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 655–669. https://doi.org/10.1145/3731569.3764827 arXiv:2503.09002 [cs]
-
[54]
Give the required verdict first, then explain your reasoning starting on the second line
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. 2019. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks.Advances in neural information processing systems32 (2019). Ethical Considerations This research evaluates prompt sensitivity in LLM-based vulnera- bility detection u...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.