How Generation Architecture Shapes Code Complexity in Multi-Agent LLM Systems: A Paired Study on HumanEval
Pith reviewed 2026-06-28 21:12 UTC · model grok-4.3
The pith
Six LLM code architectures collapse into two complexity clusters separated by a 50-130% gap with no accuracy gain for the heavier group.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
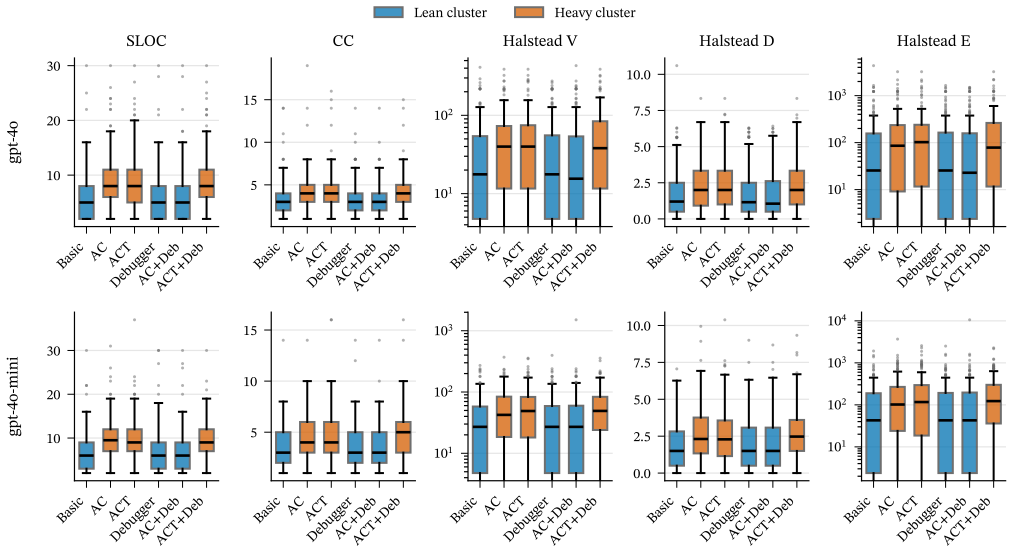
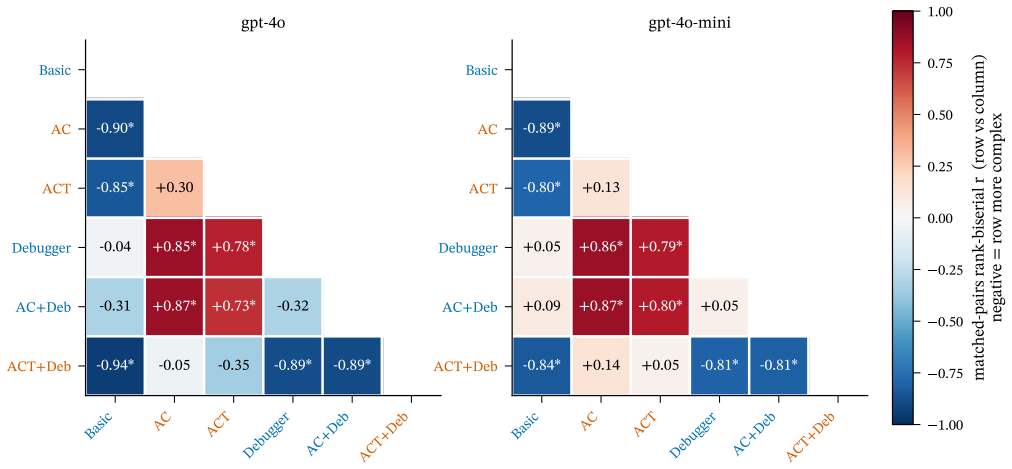
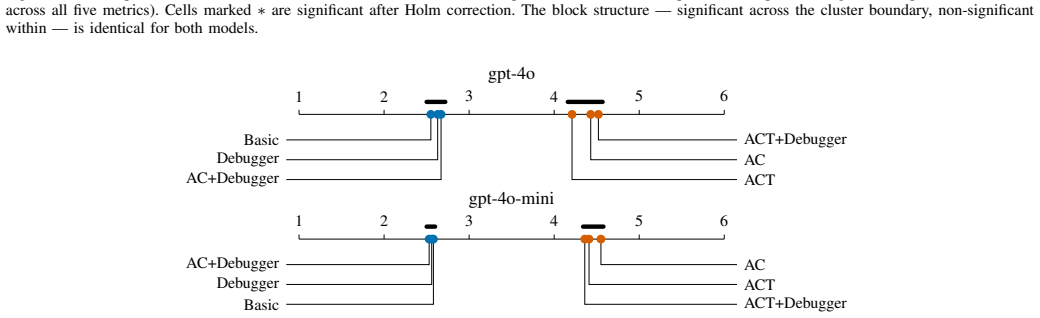
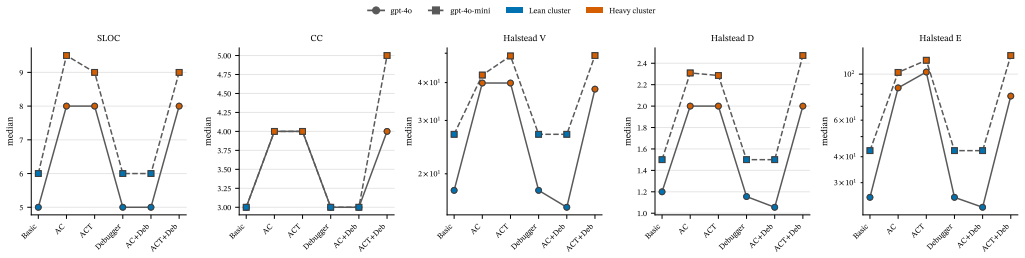
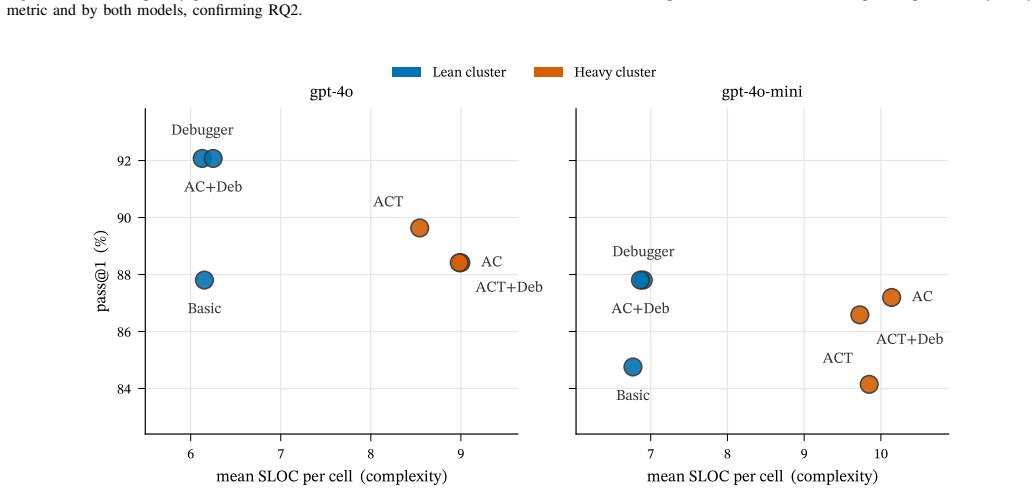
The six architectures collapse into two indistinguishable complexity clusters separated by a 50-130% gap, the same partition in both models and under both conditions; among the architectural layers, the analyst-coder split inflates complexity, the runtime debugger does not - and on the analyst-coder background actively deflates it - and the tester re-inflates it. The heavy cluster's additional complexity buys no pass@1 advantage: the leanest architectures match or beat the heaviest on accuracy.
What carries the argument
The paired non-parametric statistical pipeline (Friedman omnibus test followed by Wilcoxon signed-rank post-hoc tests with Holm correction) applied to RADON metrics across 1,968 paired observations from the six configurations.
If this is right
- Architectural layers in LLM code systems should be added only when they produce measurable gains on the target dimension rather than assumed to help.
- The analyst-coder split is the primary driver of elevated complexity across the tested setups.
- Adding a runtime debugger to an analyst-coder base can lower measured complexity.
- Re-introducing a tester layer after the debugger increases complexity once more.
- Complexity differences do not translate into functional accuracy differences on the tested tasks.
Where Pith is reading between the lines
- The clustering pattern may hold for other code-generation benchmarks beyond HumanEval.
- Teams building production multi-agent code systems could default to the leaner architectures to reduce unnecessary code complexity.
- Future studies might check whether the same layer effects appear when using different complexity metrics or open-source models.
- The results suggest that correctness-focused evaluations alone are insufficient for choosing among agent pipelines.
Load-bearing premise
The RADON metrics together with the paired statistical tests isolate the effect of architecture on complexity without being confounded by model biases or the specific choice of the 164 HumanEval tasks.
What would settle it
Repeating the experiment on a fresh benchmark set and finding either that the two clusters disappear or that the heavier cluster produces reliably higher pass@1 rates would falsify the central claim.
Figures

read the original abstract
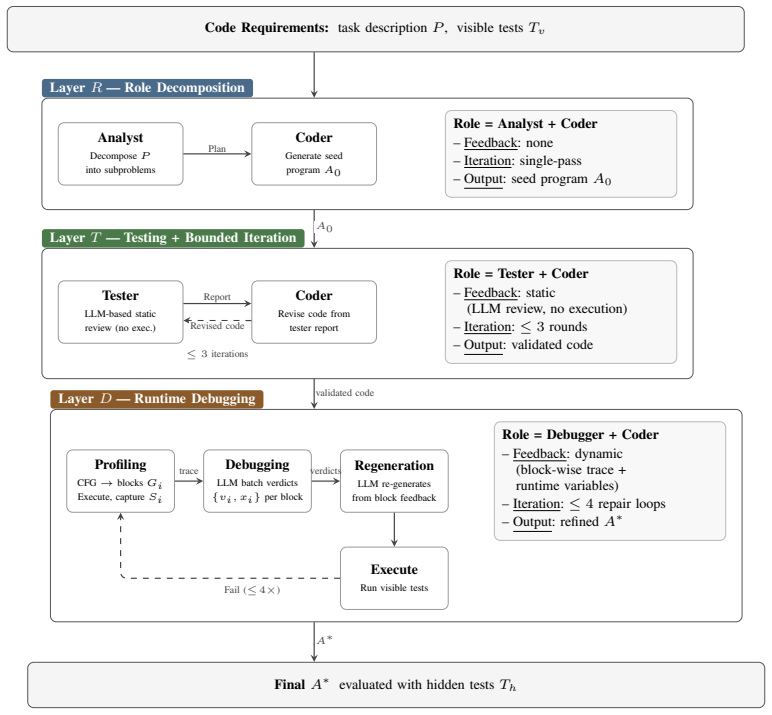
Large-language-model code generation has shifted from single-shot prompting to multi-agent orchestrations - analyst, coder, tester, and debugger pipelines - and is evaluated almost exclusively on functional correctness. Whether these architectures also affect the structural complexity of the code they produce, and which orchestration layers carry the cost, remains largely unexamined: prior work has documented prompt-level effects on code complexity, but the architecture-level question is open. We compare six widely-used multi-agent configurations (Basic, AC, ACT, Debugger, AC+Debugger, ACT+Debugger) under two models from the GPT-4o family across all 164 HumanEval tasks - 1,968 paired observations - using the five RADON complexity metrics (SLOC, cyclomatic complexity, and Halstead Volume, Difficulty, and Effort). We apply a paired non-parametric statistical pipeline (Friedman omnibus, Wilcoxon signed-rank post-hoc with Holm correction, Kendall's $W$ and matched-pairs rank-biserial effect sizes) in both all-completions and passing-only conditions. The six architectures collapse into two indistinguishable complexity clusters separated by a 50-130% gap, the same partition in both models and under both conditions; among the architectural layers, the analyst-coder split inflates complexity, the runtime debugger does not - and on the analyst-coder background actively deflates it - and the tester re-inflates it. The heavy cluster's additional complexity buys no pass@1 advantage: the leanest architectures match or beat the heaviest on accuracy. Architectural elaboration in LLM code generation should therefore be justified by measured benefit on the dimensions that matter, not assumed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a paired empirical comparison of six multi-agent LLM code-generation architectures (Basic, AC, ACT, Debugger, AC+Debugger, ACT+Debugger) on all 164 HumanEval tasks using two GPT-4o-family models, yielding 1968 observations. Complexity is measured with the five RADON metrics (SLOC, cyclomatic complexity, Halstead Volume/Difficulty/Effort). A non-parametric pipeline (Friedman omnibus, Holm-corrected Wilcoxon signed-rank, Kendall’s W, matched-pairs rank-biserial effect sizes) is applied in both the all-completions and passing-only conditions. The architectures partition into two stable complexity clusters separated by a 50–130 % gap; the analyst-coder layer increases complexity, the debugger reduces it on an AC background, and the tester increases it. The heavier cluster confers no pass@1 advantage.
Significance. If the reported cluster separation and layer-wise effects hold, the work supplies concrete evidence that architectural elaboration in multi-agent LLM systems can substantially raise structural complexity without improving functional correctness. The paired design across 1968 observations, dual models, and both completion conditions strengthens internal validity. Explicit credit is due for the use of standard non-parametric tests with multiplicity correction and for reporting both all-completions and passing-only analyses. The result supplies a falsifiable, architecture-level claim that can be tested on other benchmarks or models.
minor comments (3)
- [§3] §3 (Methods): the precise prompt templates and hand-off protocols for each of the six architectures are referenced but not reproduced; including them (or a pointer to a public repository) would improve replicability.
- [§4.2] §4.2 (Statistical pipeline): the exact rule used to filter completions for the passing-only condition (e.g., whether syntax errors or runtime failures are excluded before or after RADON measurement) is not stated; this detail is needed to evaluate possible selection bias.
- [Table 2] Table 2 / Figure 3: the reported 50–130 % gap should be accompanied by the specific pairwise rank-biserial effect sizes and the architectures assigned to each cluster so that readers can verify the partition without re-running the analysis.
Simulated Author's Rebuttal
We thank the referee for the positive and detailed summary of our work, the recognition of its internal validity, and the recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
Empirical measurement study with no derivational chain
full rationale
The paper is a purely empirical paired study applying standard non-parametric tests (Friedman omnibus, Holm-corrected Wilcoxon, Kendall's W, rank-biserial effect sizes) to RADON metrics on 1968 observations from HumanEval. No equations, fitted parameters, ansatzes, or self-citations appear in the reported pipeline or conclusions; the two-cluster partition, layer-wise effects, and accuracy comparisons are direct statistical outputs from the data rather than reductions of any claimed derivation to its own inputs. The methods are externally verifiable and do not rely on prior author work for uniqueness or load-bearing premises.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of Friedman omnibus test and Wilcoxon signed-rank test with Holm correction hold for the paired observations across architectures.
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Junet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
N. S. Ashrafi, S. Bouktif, and M. Mediani, “Enhancing LLM code generation: A systematic evaluation of multi-agent collaboration and runtime debugging for improved accuracy, reliability, and latency,” 2025, https://arxiv.org/abs/2505.02133
-
[3]
Unlocking code simplicity: The role of prompt patterns in managing LLM code complexity,
A. Della Porta, G. Recupito, S. Lambiase, D. Di Nucci, and F. Palomba, “Unlocking code simplicity: The role of prompt patterns in managing LLM code complexity,” inProceedings of the IEEE International Con- ference on Software Analysis, Evolution and Reengineering Workshops (SANER-W), 2025
2025
-
[4]
Programs, life cycles, and laws of software evolution,
M. M. Lehman, “Programs, life cycles, and laws of software evolution,” Proceedings of the IEEE, vol. 68, no. 9, pp. 1060–1076, 1980
1980
-
[5]
MetaGPT: Meta programming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, C. Zhang, J. Wang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber, “MetaGPT: Meta programming for a multi-agent collaborative framework,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[6]
ChatDev: Communicative agents for software development,
C. Qian, W. Liu, H. Liu, N. Chen, Y . Dang, J. Li, C. Yang, W. Chen, Y . Su, X. Conget al., “ChatDev: Communicative agents for software development,” inProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[7]
Self-Refine: Iterative Refinement with Self-Feedback
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yanget al., “Self-refine: Iterative refinement with self-feedback,”arXiv preprint arXiv:2303.17651, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” in Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[9]
MapCoder: Multi-agent code generation for competitive problem solving,
M. A. Islam, M. E. Ali, and M. R. Parvez, “MapCoder: Multi-agent code generation for competitive problem solving,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), Long Papers, 2024
2024
-
[10]
Code generation with Al- phaCodium: From prompt engineering to flow engineering,
T. Ridnik, D. Kredo, and I. Friedman, “Code generation with Al- phaCodium: From prompt engineering to flow engineering,” 2024, https://arxiv.org/abs/2401.08500
-
[11]
Is your code generated by ChatGPT really correct? Rigorous evaluation of large language models for code generation,
J. Liu, C. S. Xia, Y . Wang, and L. Zhang, “Is your code generated by ChatGPT really correct? Rigorous evaluation of large language models for code generation,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[12]
Why Do Multi-Agent LLM Systems Fail?
M. Cemri, M. Z. Pan, S. Yang, L. A. Agrawal, B. Chopra, R. Tiwari, K. Keutzer, A. Parameswaran, D. Klein, K. Ramchandran, M. Zaharia, J. E. Gonzalez, and I. Stoica, “Why do multi-agent LLM systems fail?” inAdvances in Neural Information Processing Systems (NeurIPS), Track on Datasets and Benchmarks, 2025, https://arxiv.org/abs/2503.13657
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
LDB: A large language model debugger via verifying runtime execution step-by-step,
L. Zhong, Z. Wang, and J. Shang, “LDB: A large language model debugger via verifying runtime execution step-by-step,”arXiv preprint arXiv:2402.16906, 2024
-
[14]
Executable code actions elicit better LLM agents,
X. Wang, Y . Chen, L. Yuan, Y . Zhang, Y . Li, H. Peng, and H. Ji, “Executable code actions elicit better LLM agents,” inProceedings of the 41st International Conference on Machine Learning (ICML), PMLR 235, 2024
2024
-
[15]
Do prompt patterns affect code quality? a first empirical assessment of ChatGPT-generated code,
A. Della Porta, S. Lambiase, and F. Palomba, “Do prompt patterns affect code quality? a first empirical assessment of ChatGPT-generated code,” inProceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering (EASE), 2025
2025
-
[16]
Program code generation: Single LLMs vs. multi-agent systems,
B. Idrisov, E. Eisenacher, and T. Schlippe, “Program code generation: Single LLMs vs. multi-agent systems,” inProceedings of the 7th International Conference on Natural Language Processing (ICNLP). IEEE, 2025
2025
-
[17]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in Proceedings of the 11th International Conference on Learning Repre- sentations (ICLR), 2023
2023
-
[18]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
D. Huang, Q. Bu, J. M. Zhang, M. Luck, and H. Cui, “AgentCoder: Multi-agent-based code generation with iterative testing and optimisa- tion,”arXiv preprint arXiv:2312.13010, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
SWE-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[20]
Radon: a Python tool that computes various metrics from the source code,
M. Lacchia, “Radon: a Python tool that computes various metrics from the source code,” https://radon.readthedocs.io/
-
[21]
A complexity measure,
T. J. McCabe, “A complexity measure,” inIEEE Transactions on Software Engineering, vol. SE-2, no. 4, 1976, pp. 308–320
1976
-
[22]
M. H. Halstead,Elements of Software Science. Elsevier North-Holland, 1977
1977
-
[23]
The use of ranks to avoid the assumption of normality implicit in the analysis of variance,
M. Friedman, “The use of ranks to avoid the assumption of normality implicit in the analysis of variance,”Journal of the American Statistical Association, vol. 32, no. 200, pp. 675–701, 1937
1937
-
[24]
Individual comparisons by ranking methods,
F. Wilcoxon, “Individual comparisons by ranking methods,”Biometrics Bulletin, vol. 1, no. 6, pp. 80–83, 1945
1945
-
[25]
A simple sequentially rejective multiple test procedure,
S. Holm, “A simple sequentially rejective multiple test procedure,” Scandinavian Journal of Statistics, vol. 6, no. 2, pp. 65–70, 1979
1979
-
[26]
The simple difference formula: An approach to teach- ing nonparametric correlation,
D. S. Kerby, “The simple difference formula: An approach to teach- ing nonparametric correlation,”Comprehensive Psychology, vol. 3, p. 11.IT.3.1, 2014
2014
-
[27]
Creative and correct: Requesting diverse code solutions from AI foundation models,
S. Blyth, M. Wagner, and C. Treude, “Creative and correct: Requesting diverse code solutions from AI foundation models,” inProceedings of the 1st ACM International Workshop on AI Foundation Models and Software Engineering (FORGE), 2024
2024
-
[28]
SWE-bench: Can language models resolve real- world GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “SWE-bench: Can language models resolve real- world GitHub issues?” inInternational Conference on Learning Repre- sentations (ICLR), 2024
2024
-
[29]
Enhancing LLM-based code generation with complexity metrics: A feedback-driven approach,
M. Sepidband, H. Taherkhani, S. Wang, and H. Hemmati, “Enhancing LLM-based code generation with complexity metrics: A feedback-driven approach,” 2025, https://arxiv.org/abs/2505.23953
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.