Do Transformers Need Three Projections? Systematic Study of QKV Variants
Pith reviewed 2026-06-28 15:12 UTC · model grok-4.3
The pith
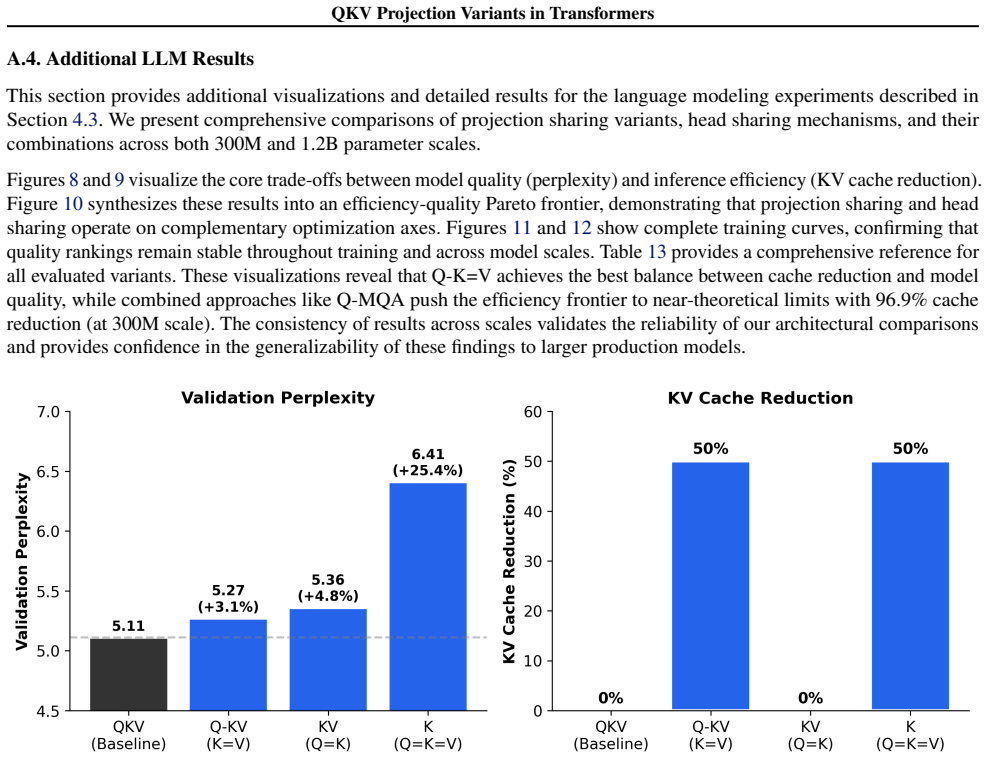
Sharing key and value projections halves KV cache size with 3.1 percent perplexity degradation in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
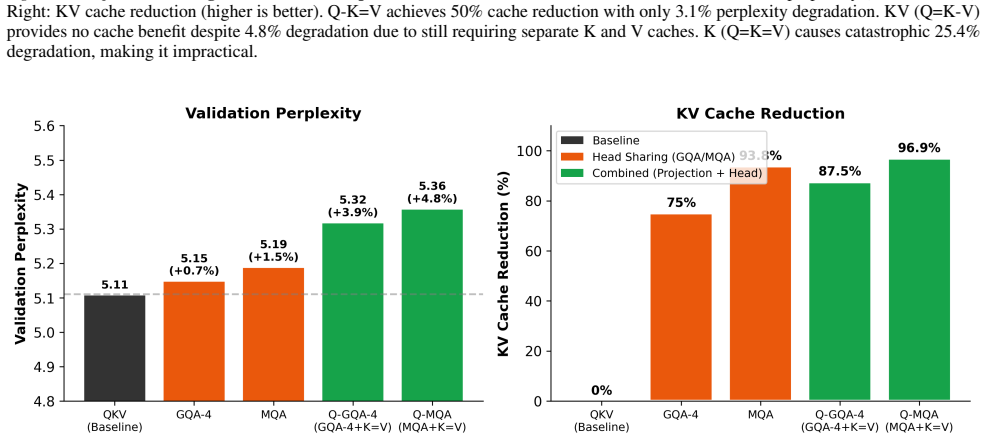
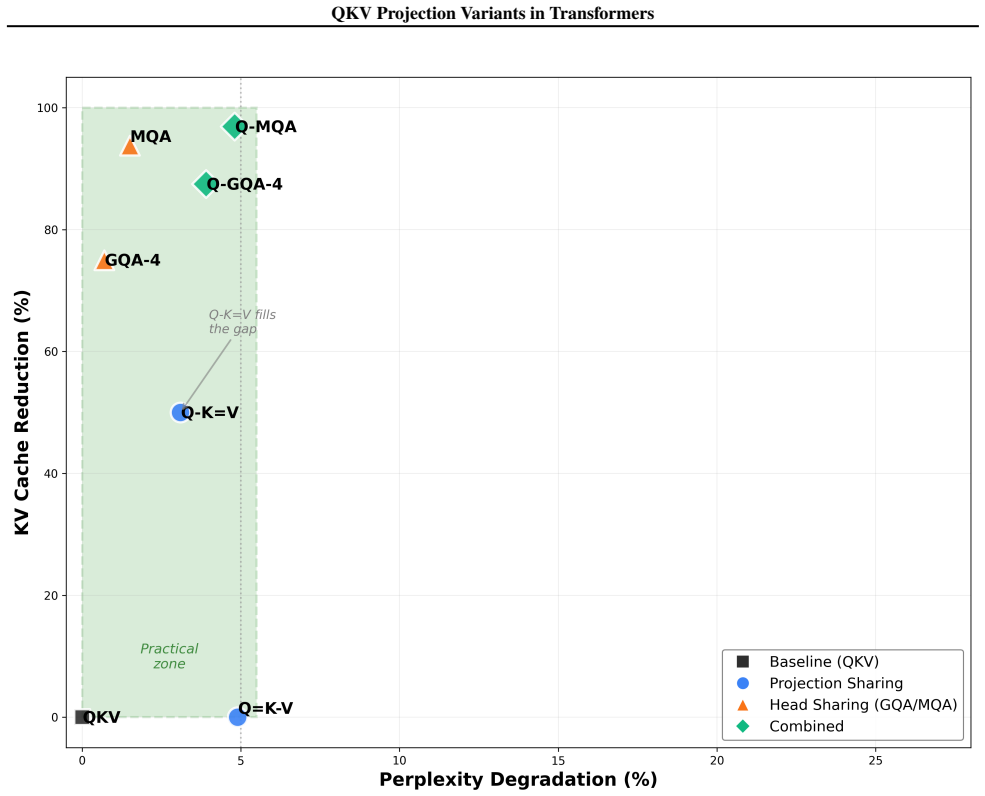
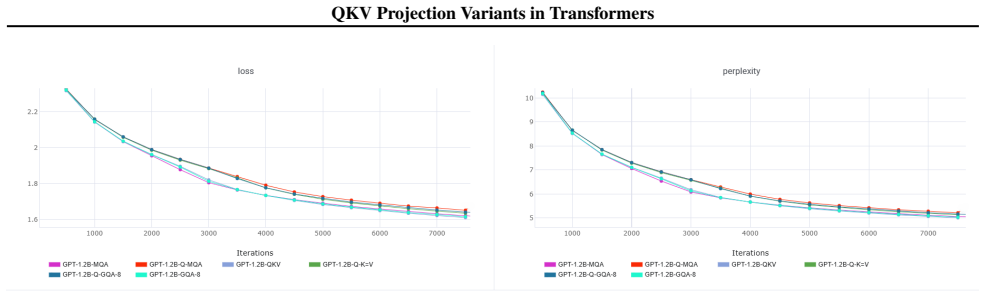
Q-K=V projection sharing achieves 50 percent KV cache reduction with only 3.1 percent perplexity degradation in language modeling, while Q=K-V and Q=K=V produce symmetric attention maps that degrade performance unless corrected by asymmetric positional encodings; the sharing is complementary to head-sharing methods such as GQA and MQA.
What carries the argument
The Q-K=V constraint that forces the key and value projection matrices to be identical.
If this is right
- Q-K=V combined with GQA-4 yields 87.5 percent KV cache reduction.
- Q-K=V combined with MQA yields 96.9 percent KV cache reduction.
- Projection sharing works on par with or better than standard QKV on vision and synthetic tasks.
- The technique is complementary to existing head-sharing methods.
Where Pith is reading between the lines
- The same sharing could be tested during training to reduce optimizer state memory.
- If the low-rank assumption holds, the method may extend to decoder-only models in other modalities.
- Alternative positional encodings might rescue the symmetric variants on additional tasks.
Load-bearing premise
Keys and values can occupy similar representational spaces in the low-rank attention regime across the tested scales and domains.
What would settle it
Significant perplexity rise or accuracy drop when Q-K=V is applied to models larger than 1.2B parameters or to non-language domains such as audio or code generation.
Figures


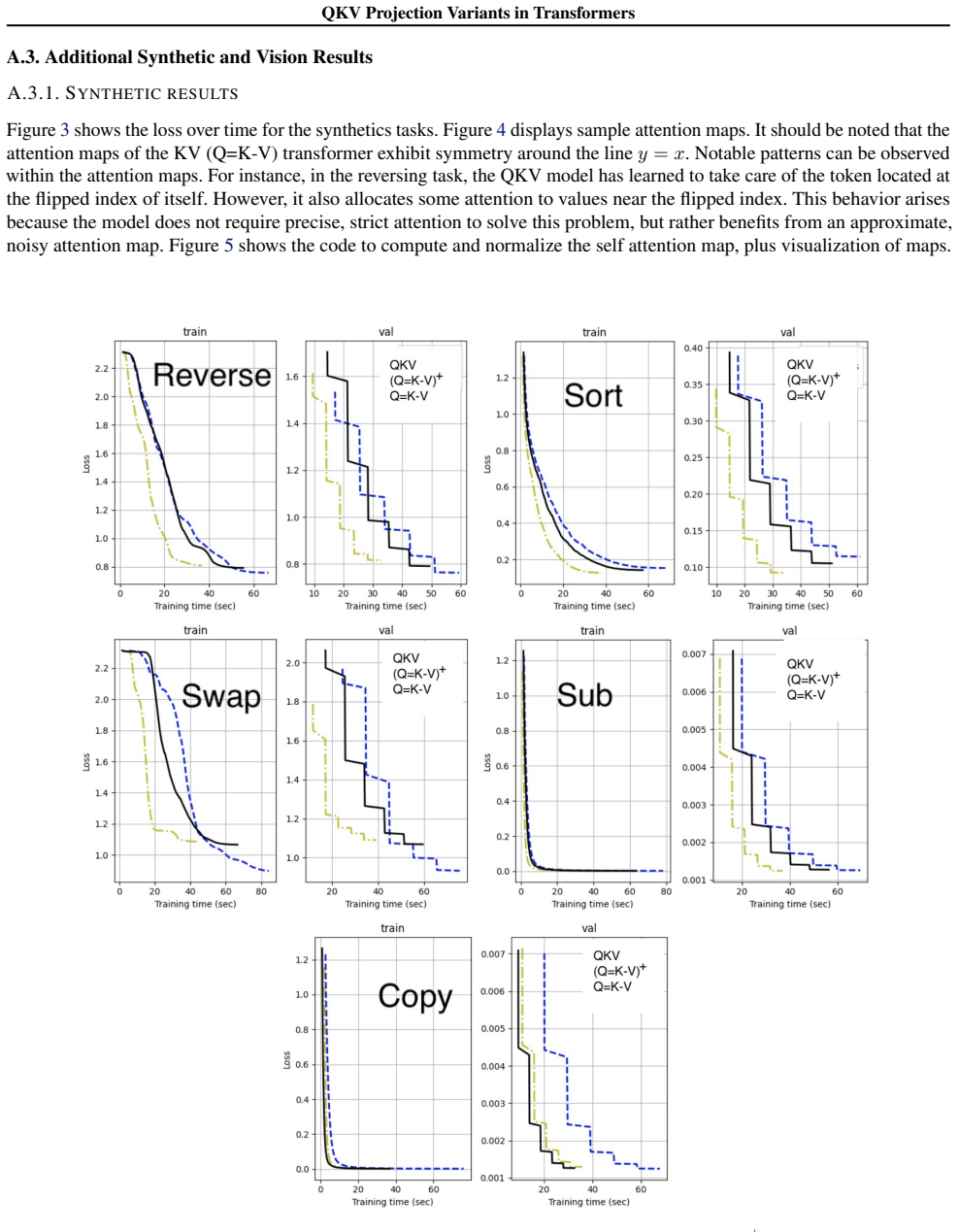
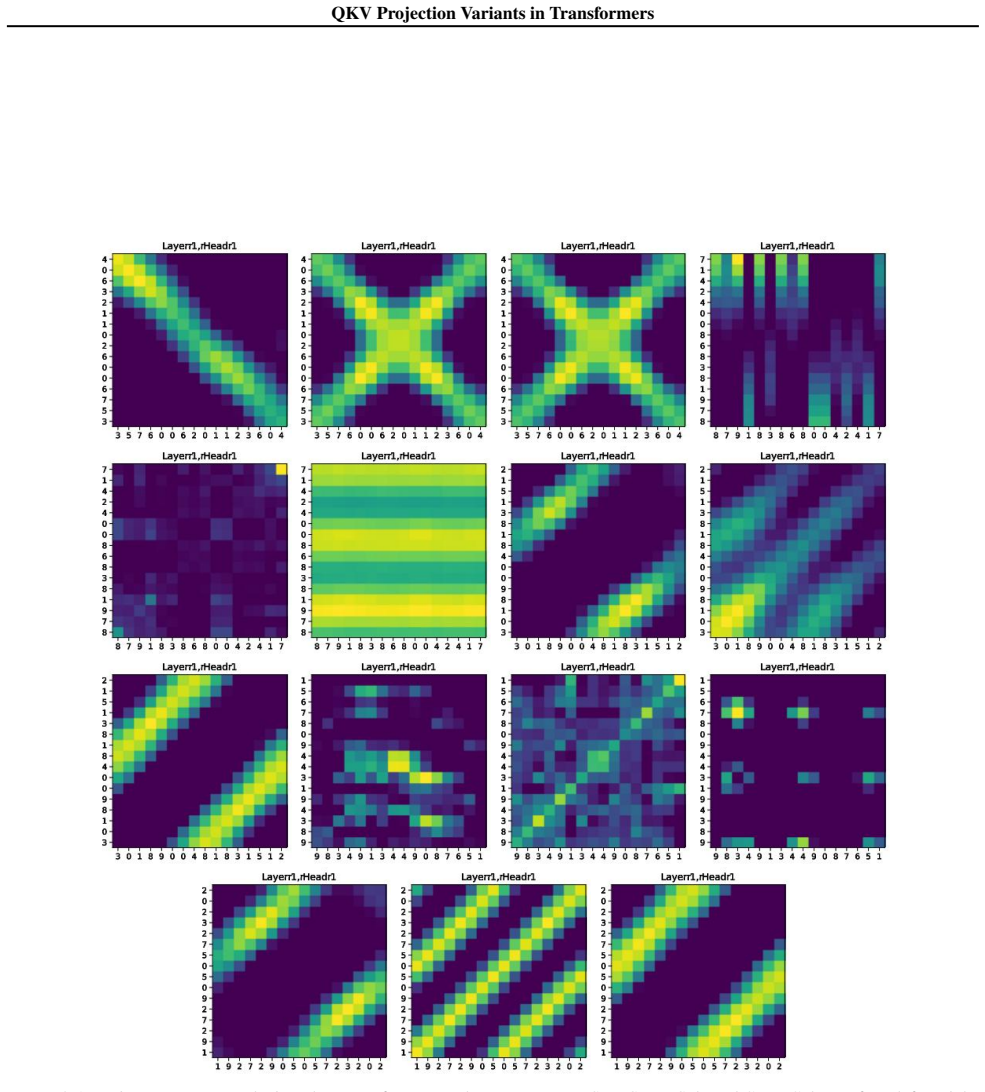
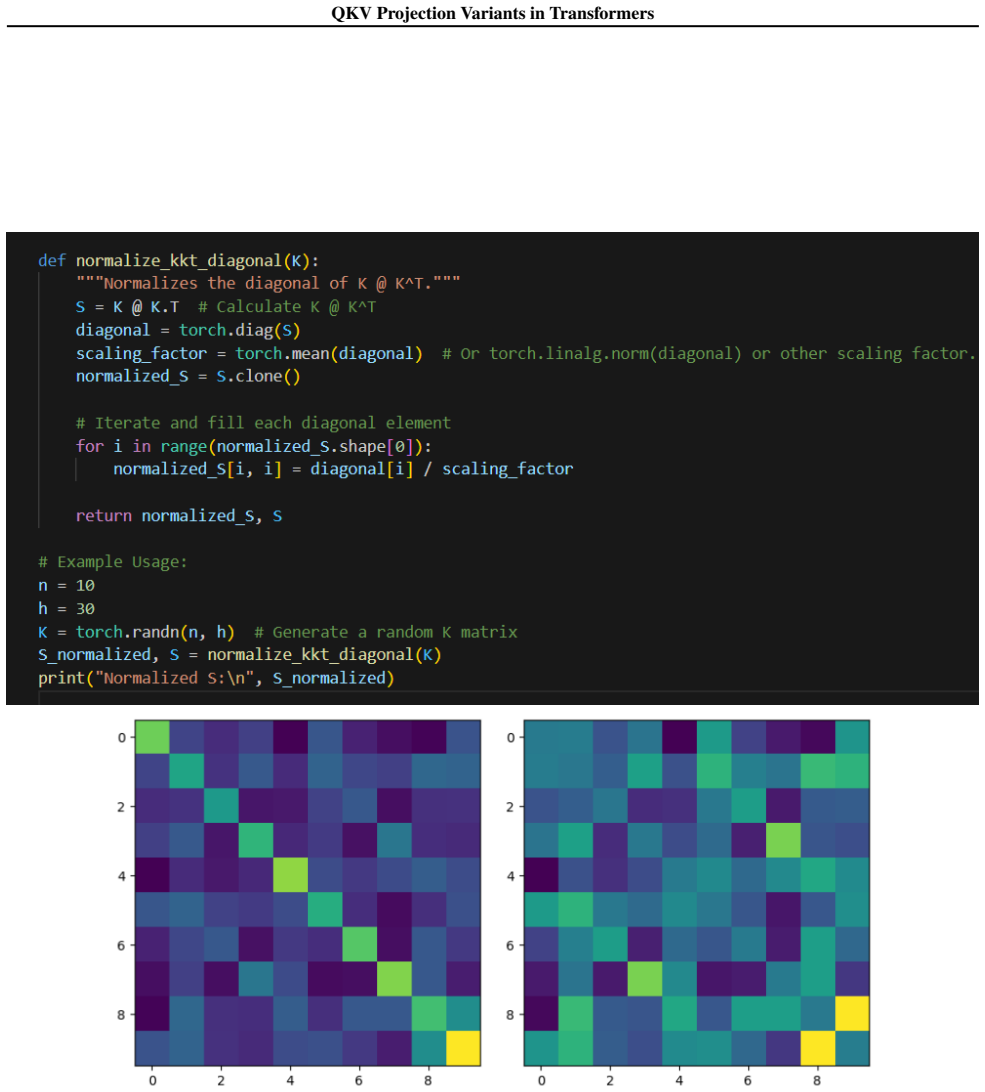

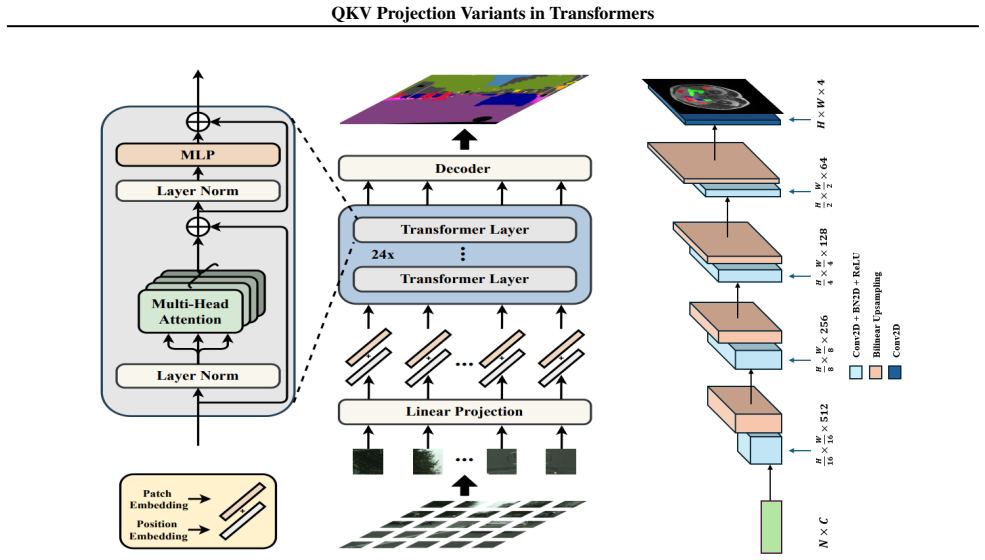
read the original abstract
Transformers have become the standard solution for various AI tasks, with the query, key, and value (QKV) attention formulation playing a central role. However, the individual contribution of these three projections and the impact of omitting some remain poorly understood. We systematically evaluate three projection sharing constraints: a) Q-K=V (shared key-value), b) Q=K-V (shared query-key), and c) Q=K=V (single projection). The last two variants produce symmetric attention maps; to address this, we also explore asymmetric attention via 2D positional encodings. Through experiments spanning synthetic tasks, vision (MNIST, CIFAR, TinyImageNet, anomaly), and language modeling (300M and 1.2B parameter models on 10B tokens), we discovered that our transformers perform on par or occasionally better than the QKV transformer. In language modeling, Q-K=V projection sharing achieves 50% KV cache reduction with only 3.1% perplexity degradation. Crucially, projection sharing is complementary to head sharing (GQA/MQA): combining Q-K=V with GQA-4 yields 87.5% cache reduction, while Q-K=V + MQA achieves 96.9%, enabling practical on-device inference. We show that Q-K=V preserves quality because keys and values can occupy similar representational spaces and attention operates in a low-rank regime, whereas Q=K-V breaks attention directionality. Our results systematically characterize projection sharing as an underexplored instance of weight tying in attention, with direct, quantifiable inference memory benefits, particularly valuable for edge deployment. The code is publicly available at https://github.com/Brainchip-Inc/Do-Transformers-Need-3-Projections
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper systematically ablates three QKV projection-sharing constraints (Q-K=V, Q=K-V, Q=K=V) plus asymmetric variants with 2D positional encodings. Across synthetic tasks, vision benchmarks (MNIST, CIFAR, TinyImageNet, anomaly detection), and language modeling (300M and 1.2B models on 10B tokens), it reports that Q-K=V matches or occasionally exceeds standard QKV performance while halving KV cache; combining it with GQA-4 or MQA yields 87.5–96.9% cache reduction. The authors attribute success to a low-rank attention regime in which keys and values occupy similar spaces, while Q=K-V breaks directionality. Public code is released.
Significance. If the reported numbers hold, the work supplies a simple, complementary weight-tying technique that delivers large, quantifiable KV-cache savings for on-device inference with negligible quality loss. The public implementation and breadth of tasks (synthetic through 1.2B-scale LM) are concrete strengths that facilitate direct verification and extension.
major comments (2)
- [Abstract] Abstract and language-modeling results: the headline 3.1% perplexity degradation for Q-K=V (and the 87.5–96.9% combined reductions) is stated without error bars, number of random seeds, or training-hyperparameter tables, preventing assessment of whether the small gap is statistically reliable or sensitive to optimization details.
- [Abstract] The mechanistic claim that 'Q-K=V preserves quality because keys and values can occupy similar representational spaces and attention operates in a low-rank regime' (Abstract) is presented as an explanation yet is unsupported by any reported measurement of attention-matrix rank, singular-value spectra, or K/V cosine similarity; without these diagnostics the low-rank justification remains an untested post-hoc interpretation rather than a verified finding.
minor comments (2)
- Vision and synthetic sections would benefit from explicit statement of whether the same hyper-parameters were used across all QKV variants or whether per-variant tuning occurred.
- The paper notes that Q=K-V and Q=K=V produce symmetric attention maps; a brief equation or diagram showing how the 2D positional encoding breaks this symmetry would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address the two major comments below and will make the indicated changes to strengthen the presentation of results and claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and language-modeling results: the headline 3.1% perplexity degradation for Q-K=V (and the 87.5–96.9% combined reductions) is stated without error bars, number of random seeds, or training-hyperparameter tables, preventing assessment of whether the small gap is statistically reliable or sensitive to optimization details.
Authors: We agree that reporting variability across seeds and providing hyperparameter details would allow better assessment of reliability. In the revised manuscript we will add results from three independent random seeds for the language-modeling experiments (reporting mean and standard deviation of perplexity), along with a supplementary table listing the key training hyperparameters for the 300M and 1.2B models. revision: yes
-
Referee: [Abstract] The mechanistic claim that 'Q-K=V preserves quality because keys and values can occupy similar representational spaces and attention operates in a low-rank regime' (Abstract) is presented as an explanation yet is unsupported by any reported measurement of attention-matrix rank, singular-value spectra, or K/V cosine similarity; without these diagnostics the low-rank justification remains an untested post-hoc interpretation rather than a verified finding.
Authors: The referee is correct that the low-rank-regime explanation is interpretive and not backed by direct measurements such as rank or cosine similarity in the current manuscript. We will revise the abstract (and the corresponding sentence in the conclusion) to present the statement as a hypothesis consistent with the empirical results rather than a verified mechanistic finding. If space permits, we will also add a brief appendix note on average K/V cosine similarity computed from the trained models. revision: yes
Circularity Check
No circularity: purely empirical ablation study with no derivations or self-referential predictions.
full rationale
The paper reports direct experimental measurements of perplexity, accuracy, and cache size across QKV sharing variants on synthetic, vision, and language tasks (300M/1.2B models, 10B tokens). No equations, first-principles derivations, or predictions are presented that reduce to fitted inputs by construction. The interpretive claim that Q-K=V works due to low-rank regime and K/V overlap is post-hoc explanation of results, not a load-bearing step that defines or predicts its own inputs. No self-citations are used to justify uniqueness or ansatzes. The study is self-contained against external benchmarks via reported ablations.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard transformer self-attention formulation with separate Q, K, V projections
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1409.0473 , year=
Neural machine translation by jointly learning to align and translate , author=. arXiv preprint arXiv:1409.0473 , year=
-
[2]
The handbook of brain theory and neural networks , volume=
Convolutional networks for images, speech, and time series , author=. The handbook of brain theory and neural networks , volume=. 1995 , publisher=
1995
-
[3]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[4]
ACM Computing Surveys , volume=
Efficient transformers: A survey , author=. ACM Computing Surveys , volume=. 2022 , publisher=
2022
-
[5]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[6]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil , title =. International Conference on Learning Representations , year=. doi:10.48550/ARXIV.2010.11929 , shorttitle=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.11929 2010
-
[8]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention is all you need , year=. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
-
[9]
Zheng, Sixiao and Lu, Jiachen and Zhao, Hengshuang and Zhu, Xiatian and Luo, Zekun and Wang, Yabiao and Fu, Yanwei and Feng, Jianfeng and Xiang, Tao and Torr, Philip H.S. and Zhang, Li , booktitle =. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers , year=. doi:10.1109/CVPR46437.2021.00681 , archiveprefix =. 2012....
-
[10]
doi:10.48550/arXiv.2102.04306 , adsurl=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2102.04306
-
[11]
Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers , year =
Using the Output Embedding to Improve Language Models , author =. Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers , year =
-
[12]
Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
Improve transformer models with better relative position embeddings , author=. Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
2020
-
[13]
2023 , url=
SlimPajama: A 627B token cleaned and deduplicated version of RedPajama , author=. 2023 , url=
2023
-
[14]
arXiv preprint arXiv:2204.14198 , year=
Flamingo: A Visual Language Model for Few-Shot Learning , author=. arXiv preprint arXiv:2204.14198 , year=
-
[15]
Proceedings of the 38th International Conference on Machine Learning (ICML) , year=
Learning Transferable Visual Models From Natural Language Supervision , author=. Proceedings of the 38th International Conference on Machine Learning (ICML) , year=
-
[16]
Proc IEEE Int Conf Comput Vis , year=
CvT: Introducing Convolutions to Vision Transformers , author=. Proc IEEE Int Conf Comput Vis , year=
-
[17]
2022 , url =
happyharrycn and Maggie and Culliton, Phil and Yadav, Poonam and Lee, Sangjune Laurence , title =. 2022 , url =
2022
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Big Bird: Transformers for Longer Sequences , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[19]
Proceedings of machine learning and systems , volume=
Efficiently scaling transformer inference , author=. Proceedings of machine learning and systems , volume=
-
[20]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[21]
IEEE Transactions on Visualization and Computer Graphics , volume=
Attention flows: Analyzing and comparing attention mechanisms in language models , author=. IEEE Transactions on Visualization and Computer Graphics , volume=. 2020 , publisher=
2020
-
[22]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
An empirical study of spatial attention mechanisms in deep networks , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[23]
International conference on machine learning , pages=
Scaling vision transformers to 22 billion parameters , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[24]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[25]
arXiv preprint arXiv:2503.10622 , year=
Transformers without Normalization , author=. arXiv preprint arXiv:2503.10622 , year=
-
[26]
arXiv preprint arXiv:1607.06450 , year=
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
-
[27]
arXiv preprint arXiv:1708.07747 , year=
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms , author=. arXiv preprint arXiv:1708.07747 , year=
-
[28]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=. 1998 , publisher=
1998
-
[29]
2009 , publisher=
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
2009
-
[30]
Advances in neural information processing systems , volume=
Imagenet classification with deep convolutional neural networks , author=. Advances in neural information processing systems , volume=
-
[31]
arXiv preprint arXiv:2503.01743 , year=
Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras , author=. arXiv preprint arXiv:2503.01743 , year=
-
[32]
International Conference on Machine Learning , pages=
Hyena hierarchy: Towards larger convolutional language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[33]
Nature Machine Intelligence , pages=
Transformers and genome language models , author=. Nature Machine Intelligence , pages=. 2025 , publisher=
2025
-
[34]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[35]
IEEE transactions on pattern analysis and machine intelligence , volume=
A survey on vision transformer , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2022 , publisher=
2022
-
[36]
arXiv preprint arXiv:2312.00752 , year=
Mamba: Linear-time sequence modeling with selective state spaces , author=. arXiv preprint arXiv:2312.00752 , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
Soft: Softmax-free transformer with linear complexity , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Sima: Simple softmax-free attention for vision transformers , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[39]
arXiv preprint arXiv:1605.00459 , year=
Multi30k: Multilingual english-german image descriptions , author=. arXiv preprint arXiv:1605.00459 , year=
-
[40]
arXiv preprint arXiv:1906.11024 , year=
Sharing attention weights for fast transformer , author=. arXiv preprint arXiv:1906.11024 , year=
Pith/arXiv arXiv 1906
-
[41]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Residualtransformer: Residual low-rank learning with weight-sharing for transformer layers , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Minivit: Compressing vision transformers with weight multiplexing , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[43]
arXiv preprint arXiv:2101.00234 , year=
Subformer: Exploring weight sharing for parameter efficiency in generative transformers , author=. arXiv preprint arXiv:2101.00234 , year=
-
[44]
arXiv preprint arXiv:2004.11886 , year=
Lite transformer with long-short range attention , author=. arXiv preprint arXiv:2004.11886 , year=
arXiv 2004
-
[45]
arXiv preprint arXiv:1909.11942 , year=
Albert: A lite bert for self-supervised learning of language representations , author=. arXiv preprint arXiv:1909.11942 , year=
Pith/arXiv arXiv 1909
-
[46]
arXiv preprint arXiv:1807.03819 , year=
Universal transformers , author=. arXiv preprint arXiv:1807.03819 , year=
-
[47]
arXiv preprint arXiv:1806.03280 , year=
Multilingual neural machine translation with task-specific attention , author=. arXiv preprint arXiv:1806.03280 , year=
-
[48]
arXiv preprint arXiv:2001.04451 , year=
Reformer: The efficient transformer , author=. arXiv preprint arXiv:2001.04451 , year=
Pith/arXiv arXiv 2001
-
[49]
arXiv preprint arXiv:1909.10351 , year=
Tinybert: Distilling bert for natural language understanding , author=. arXiv preprint arXiv:1909.10351 , year=
arXiv 1909
-
[50]
arXiv preprint arXiv:2301.00774 , year=
SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot , author=. arXiv preprint arXiv:2301.00774 , year=
-
[51]
arXiv preprint arXiv:2005.07683 , year=
Movement Pruning: Adaptive Sparsity by Fine-Tuning , author=. arXiv preprint arXiv:2005.07683 , year=
arXiv 2005
-
[52]
arXiv preprint arXiv:2109.14642 , year=
Block Pruning For Faster Transformers , author=. arXiv preprint arXiv:2109.14642 , year=
-
[53]
arXiv preprint arXiv:2011.00623 , year=
GOBO: Quantizing Attention-Based NLP Models for Reduced Size and Latency , author=. arXiv preprint arXiv:2011.00623 , year=
arXiv 2011
-
[54]
International conference on machine learning , pages=
Smoothquant: Accurate and efficient post-training quantization for large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[55]
arXiv preprint arXiv:2305.13253 , year=
OmniQuant: Weight and Activation Post-Training Quantization for Transformers , author=. arXiv preprint arXiv:2305.13253 , year=
-
[56]
ICLR Workshop Track , year=
To prune, or not to prune: exploring the efficacy of pruning for model compression , author=. ICLR Workshop Track , year=
-
[57]
SparseML: Libraries for applying sparsification recipes to neural networks with a few lines of code, enabling faster and smaller models , author=
-
[58]
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
HAQ: Hardware-Aware Automated Quantization with Mixed Precision , author=. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[59]
Joint Pruning, Quantization and Distillation for Efficient Inference of Transformers , author=
-
[60]
arXiv preprint arXiv:2402.05964 , year=
A Survey on Transformer Compression , author=. arXiv preprint arXiv:2402.05964 , year=
-
[61]
Model Compression Techniques for Transformer Models: A Survey , author=
-
[62]
Companion Proceedings of the ACM on Web Conference 2025 , pages=
Don't do rag: When cache-augmented generation is all you need for knowledge tasks , author=. Companion Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[63]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[64]
National Science Review , volume=
A survey on multimodal large language models , author=. National Science Review , volume=. 2024 , publisher=
2024
-
[65]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2023
-
[66]
Computer Vision and Image Understanding , volume=
Visual question answering: A survey of methods and datasets , author=. Computer Vision and Image Understanding , volume=. 2017 , publisher=
2017
-
[67]
Expert Systems with Applications , volume=
Abstractive summarization: An overview of the state of the art , author=. Expert Systems with Applications , volume=. 2019 , publisher=
2019
-
[68]
arXiv preprint arXiv:2406.06567 , year =
DHA: Learning Decoupled-Head Attention from Transformer Checkpoints via Adaptive Heads Fusion , author =. arXiv preprint arXiv:2406.06567 , year =
-
[69]
International conference on machine learning , pages=
Transformers are rnns: Fast autoregressive transformers with linear attention , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[70]
arXiv preprint arXiv:2105.14103 , year=
An Attention Free Transformer , author=. arXiv preprint arXiv:2105.14103 , year=
-
[71]
International Conference on Learning Representations (ICLR) , year=
Graph Attention Networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[72]
arXiv preprint arXiv:2204.02311 , year=
PaLM: Scaling Language Modeling with Pathways , author=. arXiv preprint arXiv:2204.02311 , year=
-
[73]
arXiv preprint arXiv:2310.06825 , year=
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
-
[74]
Advances in Neural Information Processing Systems , volume=
Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time , author=. Advances in Neural Information Processing Systems , volume=
-
[75]
arXiv preprint arXiv:2306.03078 , year=
SPQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression , author=. arXiv preprint arXiv:2306.03078 , year=
-
[76]
arXiv preprint arXiv:2303.06865 , year=
FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU , author=. arXiv preprint arXiv:2303.06865 , year=
-
[77]
arXiv preprint arXiv:1904.10509 , year=
Generating Long Sequences with Sparse Transformers , author=. arXiv preprint arXiv:1904.10509 , year=
Pith/arXiv arXiv 1904
-
[78]
arXiv preprint arXiv:2004.05150 , year=
Longformer: The Long-Document Transformer , author=. arXiv preprint arXiv:2004.05150 , year=
Pith/arXiv arXiv 2004
-
[79]
arXiv preprint arXiv:2311.16867 , year=
The Falcon Series of Open Language Models , author=. arXiv preprint arXiv:2311.16867 , year=
-
[80]
arXiv preprint arXiv:2307.09288 , year=
LLaMA 2: Open Foundation and Fine-Tuned Chat Models , author=. arXiv preprint arXiv:2307.09288 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.