OPRD: On-Policy Representation Distillation
Pith reviewed 2026-06-28 02:42 UTC · model grok-4.3
The pith
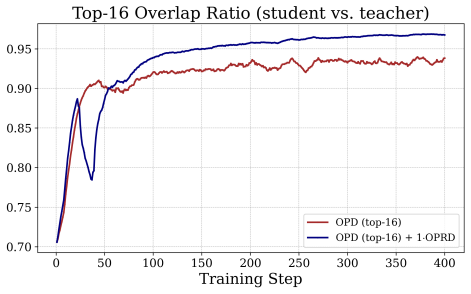
Aligning hidden states on on-policy rollouts lets student models close the performance gap to teachers on math benchmarks where output-space methods plateau.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
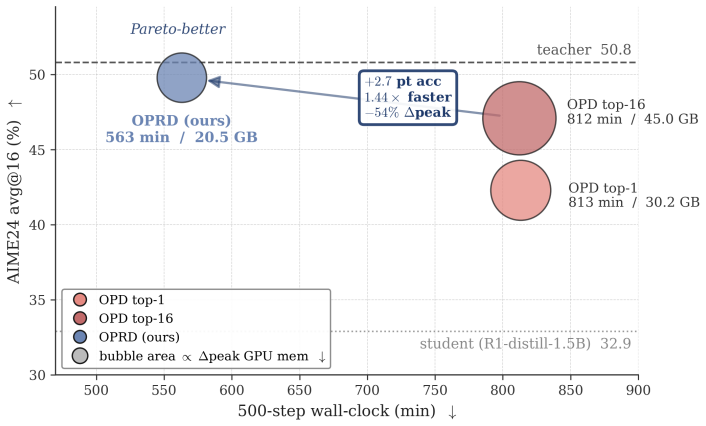
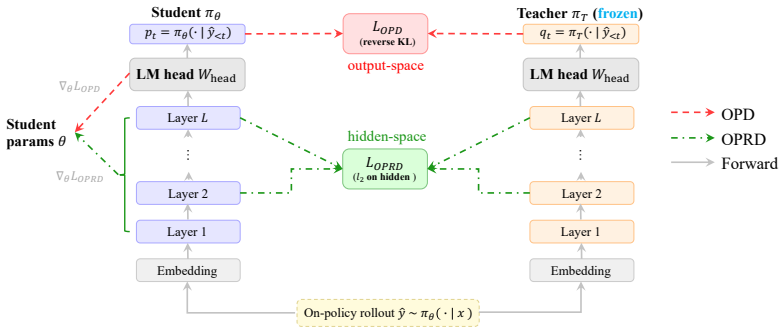
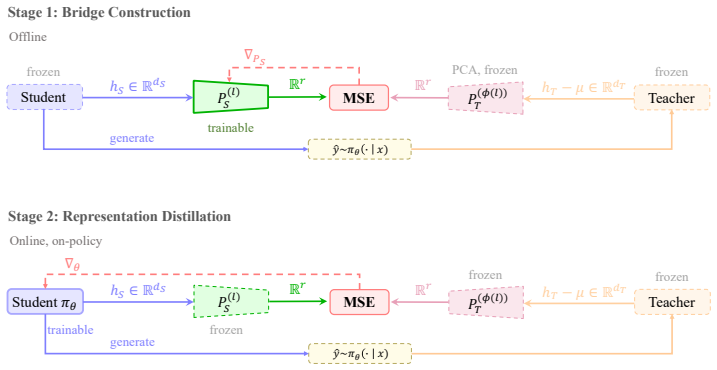
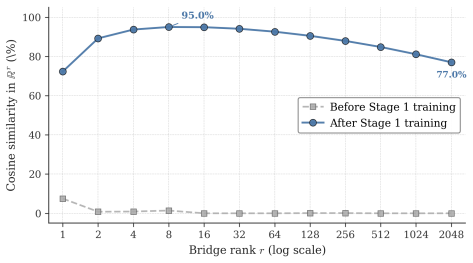
OPRD aligns student and teacher hidden states across selected layers on identical on-policy rollouts, delivering dense deterministic per-layer supervision that removes the high-variance gradient estimator and the LM-head information bottleneck of output-space distillation; the same approach with a frozen projector pair extends the alignment to heterogeneous models that differ in depth, width or tokenizer.
What carries the argument
On-policy hidden-state alignment at selected layers, using a frozen projector pair that exploits low-rank representational structure to bridge arbitrary model mismatches.
If this is right
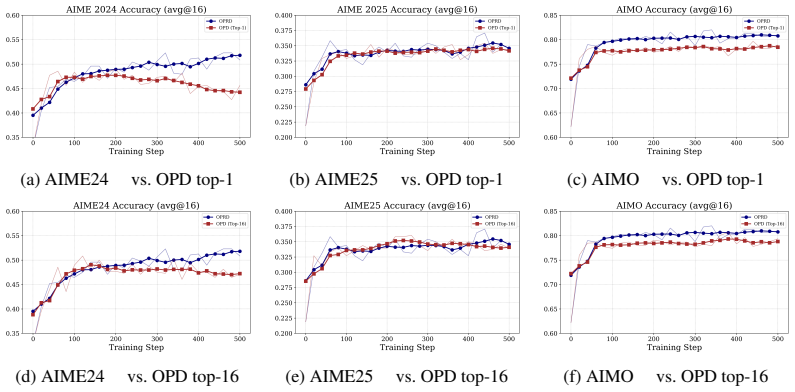
- Students reach teacher-level accuracy on competition mathematics where every output-space baseline plateaus below the teacher.
- Training runs 1.44 times faster and uses up to 54 percent less memory.
- The method supplies a deterministic per-sample gradient instead of the high-variance token-level estimator of output-space distillation.
- Successful transfer occurs even when models have no shared vocabulary, via representation-space alignment alone.
Where Pith is reading between the lines
- If the low-rank structure observation generalizes, representation distillation could become the default channel for transferring knowledge between models that lack a common tokenizer.
- The deterministic per-layer signal may combine more cleanly with reinforcement-learning objectives than noisy output-space distillation does.
- The same alignment mechanism could be tested on non-reasoning tasks to check whether intermediate representations carry transferable structure beyond mathematics benchmarks.
Load-bearing premise
Student and teacher hidden states at chosen layers remain meaningfully alignable on the same on-policy rollouts even when the models differ in depth and width.
What would settle it
A controlled run on AIME 2024 in which an OPRD-trained student still trails every output-space baseline by the same margin the paper reports for those baselines.
Figures
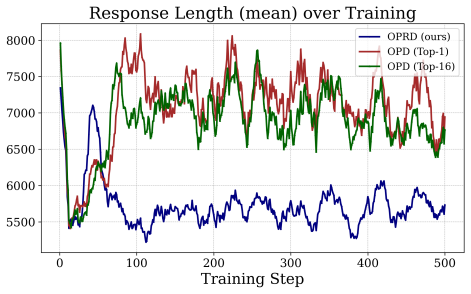
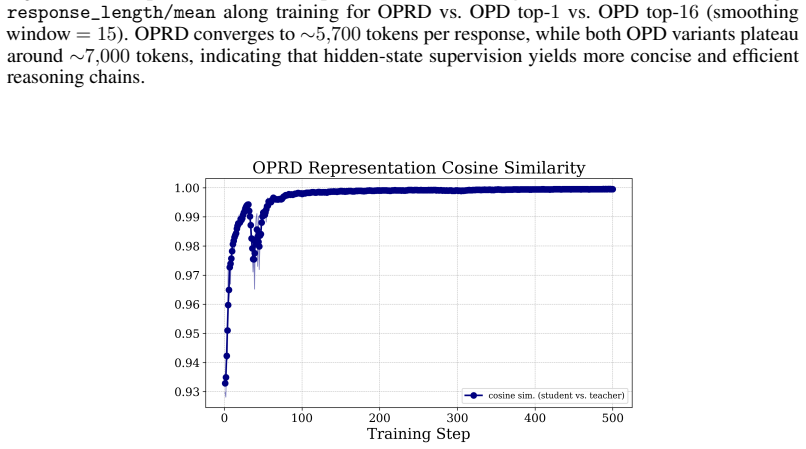

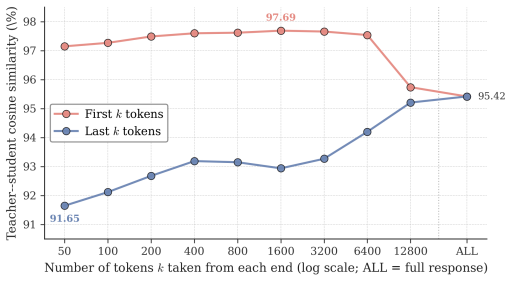
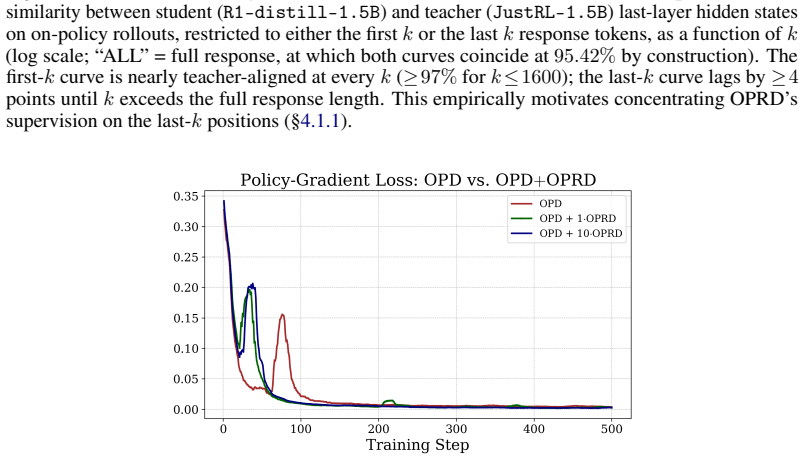
read the original abstract
On-policy distillation (OPD) supervises the student exclusively in the output space by matching next-token distributions. This paradigm suffers from two limitations: (i) a high-variance gradient estimator whose signal-to-noise ratio collapses as the student approaches the teacher, and (ii) an LM-head information bottleneck that discards the teacher's intermediate hidden states. We propose On-Policy Representation Distillation (OPRD), the first method to lift on-policy distillation into the hidden-state space. OPRD aligns student and teacher representations across selected layers on the same on-policy rollouts, providing dense, deterministic, per-layer supervision while bypassing the LM head entirely. Theoretically, OPRD provides a deterministic per-sample gradient, removing the token-level estimation variance that plagues OPD, and exposes structural information that any output-space objective necessarily discards. Empirically, OPRD closes the student-teacher gap on competition mathematics benchmarks (AIME 2024, AIME 2025, and AIMO), where every output-space baseline plateaus below the teacher, while training 1.44x faster and using up to 54% less memory. We further extend OPRD to the cross-architecture setting via OPRD-Bridge. By exploiting the observation that heterogeneous models share a low-rank representational structure, we construct a frozen projector pair that aligns representations across arbitrary depth and width mismatches, shifting the alignment from the output space (which depends on a shared vocabulary) to the representation space. We validate OPRD-Bridge on both cross-architecture (Qwen3-4B -> Qwen3-1.7B-Base) and cross-tokenizer (Phi-4-mini-reasoning -> Qwen3-1.7B-Base) settings, demonstrating successful knowledge transfer even when the vocabulary-based alignment channel is unavailable. Code: https://github.com/ShenzhiYang2000/OPRD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces On-Policy Representation Distillation (OPRD), which extends on-policy distillation from output-space next-token matching to hidden-state alignment on shared on-policy rollouts. It claims this yields deterministic per-sample gradients (removing token-level variance), bypasses the LM-head bottleneck, closes the student-teacher performance gap on AIME 2024/2025 and AIMO benchmarks where output-space baselines plateau, trains 1.44x faster, and uses up to 54% less memory. It further proposes OPRD-Bridge, which uses a frozen projector pair to enable cross-architecture and cross-tokenizer transfer by exploiting an observed low-rank representational structure shared across heterogeneous models.
Significance. If the empirical results and the low-rank bridge construction hold under scrutiny, the work would offer a concrete advance in LLM distillation by moving supervision into representation space, enabling transfer where vocabulary mismatch blocks output-space methods. The deterministic gradient property is a clear theoretical improvement over standard OPD. The cross-tokenizer result, if substantiated, would be particularly notable for heterogeneous model families.
major comments (2)
- [Abstract] Abstract: The central claim for OPRD-Bridge rests on the 'observation that heterogeneous models share a low-rank representational structure' permitting a frozen projector pair to align states across arbitrary depth/width/tokenizer mismatches. No rank measurements, covariance analysis, projector construction details, or ablation on on-policy rollouts are referenced to support that the structure is low-rank, stable, or task-relevant; without this, the claim that representation-space alignment succeeds where output-space fails cannot be evaluated.
- [Abstract] Abstract: The empirical claims (closing the gap on AIME 2024/2025/AIMO, 1.44x speedup, 54% memory reduction, successful cross-architecture transfer) are stated without any reference to experimental protocol, baselines, variance across seeds, ablation controls, or statistical significance. These numbers are load-bearing for the practical contribution and cannot be assessed from the given description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below. The full manuscript contains the requested analyses and experimental details; we will revise the abstract to include explicit references to the relevant sections, figures, and tables so that the claims can be evaluated directly from the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim for OPRD-Bridge rests on the 'observation that heterogeneous models share a low-rank representational structure' permitting a frozen projector pair to align states across arbitrary depth/width/tokenizer mismatches. No rank measurements, covariance analysis, projector construction details, or ablation on on-policy rollouts are referenced to support that the structure is low-rank, stable, or task-relevant; without this, the claim that representation-space alignment succeeds where output-space fails cannot be evaluated.
Authors: We agree that the abstract would be clearer with pointers to the supporting evidence. Section 3.3 and Figure 2 present singular-value spectra on on-policy rollouts demonstrating rapid decay (low effective rank), covariance matrices across model pairs, the SVD-based projector construction, and stability across depths. Section 5.3 contains the on-policy ablation. We will add citations to these in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: The empirical claims (closing the gap on AIME 2024/2025/AIMO, 1.44x speedup, 54% memory reduction, successful cross-architecture transfer) are stated without any reference to experimental protocol, baselines, variance across seeds, ablation controls, or statistical significance. These numbers are load-bearing for the practical contribution and cannot be assessed from the given description.
Authors: The experimental protocol, baselines (standard OPD, output-space KD, and variants), per-seed variance (reported as mean ± std over three seeds), ablation controls, and significance testing appear in Sections 5 and 6 with Tables 1–4 and Figure 4. We will insert references to these sections and tables in the abstract. revision: yes
Circularity Check
No significant circularity; proposal is self-contained
full rationale
The paper introduces OPRD as a new objective that aligns hidden states on on-policy rollouts and extends it via OPRD-Bridge using an empirical low-rank observation for projectors. No equations, fitted parameters, or self-citations are shown reducing the central claims to prior inputs by construction. The method is presented as a direct proposal bypassing output-space bottlenecks, with empirical validation on benchmarks serving as external check rather than internal redefinition. This qualifies as a normal non-circular case under the guidelines.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hidden representations at selected layers of student and teacher models are alignable on identical on-policy rollouts.
- domain assumption Heterogeneous models share a low-rank representational structure that permits alignment via a frozen projector pair despite depth and width differences.
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations, volume 2024, pages 21246–21263, 2024
2024
-
[2]
Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28, 2015
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28, 2015
2015
-
[3]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[4]
Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
2024
-
[5]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
AI DeepSeek. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[6]
Ken Ding. Hdpo: Hybrid distillation policy optimization via privileged self-distillation.arXiv preprint arXiv:2603.23871, 2026. 26
-
[7]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Jiacai Liu, Zhuo Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InInternational Conference on Learning Representations, volume 2024, pages 32694–32717, 2024
2024
-
[9]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[10]
Justrl: Scaling a 1.5 b llm with a simple rl recipe
Bingxiang He, Zekai Qu, Zeyuan Liu, Yinghao Chen, Yuxin Zuo, Cheng Qian, Kaiyan Zhang, Weize Chen, Chaojun Xiao, Ganqu Cui, et al. Justrl: Scaling a 1.5 b llm with a simple rl recipe. arXiv preprint arXiv:2512.16649, 2025
-
[11]
How far can unsupervised rlvr scale llm training? arXiv preprint arXiv:2603.08660, 2026
Bingxiang He, Yuxin Zuo, Zeyuan Liu, Shangziqi Zhao, Zixuan Fu, Junlin Yang, Cheng Qian, Kaiyan Zhang, Yuchen Fan, Ganqu Cui, et al. How far can unsupervised rlvr scale llm training? arXiv preprint arXiv:2603.08660, 2026
-
[12]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
Wenjin Hou, Shangpin Peng, Weinong Wang, Zheng Ruan, Yue Zhang, Zhenglin Zhou, Mingqi Gao, Yifei Chen, Kaiqi Wang, Hongming Yang, et al. Uni-opd: Unifying on-policy distillation with a dual-perspective recipe.arXiv preprint arXiv:2605.03677, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis.arXiv preprint arXiv:2405.07987, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Stable On-Policy Distillation through Adaptive Target Reformulation
Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, and Taesup Kim. Stable on-policy distillation through adaptive target reformulation.arXiv preprint arXiv:2601.07155, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Tinybert: Distilling bert for natural language understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding. InFindings of the association for computational linguistics: EMNLP 2020, pages 4163–4174, 2020
2020
-
[18]
Entropy-Aware On-Policy Distillation of Language Models
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models. arXiv preprint arXiv:2603.07079, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of llms?arXiv preprint arXiv:2603.24472, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Sequence-level knowledge distillation
Yoon Kim and Alexander M Rush. Sequence-level knowledge distillation. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 1317–1327, 2016
2016
-
[21]
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137, 2026
-
[22]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational conference on machine learning, pages 3519–3529. PMlR, 2019
2019
-
[23]
Deeply- supervised nets
Chen-Yu Lee, Saining Xie, Patrick Gallagher, Zhengyou Zhang, and Zhuowen Tu. Deeply- supervised nets. InArtificial intelligence and statistics, pages 562–570. Pmlr, 2015. 27
2015
-
[24]
Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimization via sample routing.arXiv preprint arXiv:2604.02288, 2026
-
[25]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Linearly mapping from image to text space.arXiv preprint arXiv:2209.15162, 2022
Jack Merullo, Louis Castricato, Carsten Eickhoff, and Ellie Pavlick. Linearly mapping from image to text space.arXiv preprint arXiv:2209.15162, 2022
-
[27]
Luca Moschella, Valentino Maiorca, Marco Fumero, Antonio Norelli, Francesco Locatello, and Emanuele Rodolà. Relative representations enable zero-shot latent space communication.arXiv preprint arXiv:2209.15430, 2022
-
[28]
FitNets: Hints for Thin Deep Nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: hints for thin deep nets (2014).arXiv preprint arXiv:1412.6550, 3, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[29]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. Crisp: Compressed reasoning via iterative self-policy distillation.arXiv preprint arXiv:2603.05433, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[31]
Multitask Prompted Training Enables Zero-Shot Task Generalization
Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. Multitask prompted training enables zero-shot task generalization.arXiv preprint arXiv:2110.08207, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Mo- bilebert: a compact task-agnostic bert for resource-limited devices
Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou. Mo- bilebert: a compact task-agnostic bert for resource-limited devices. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 2158–2170, 2020
2020
-
[34]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
2020
-
[35]
Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers
Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong, and Furu Wei. Minilmv2: Multi-head self-attention relation distillation for compressing pretrained transformers. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2140–2151, 2021
2021
-
[36]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[37]
MiMo-V2-Flash Technical Report
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Haoran Xu, Baolin Peng, Hany Awadalla, Dongdong Chen, Yen-Chun Chen, Mei Gao, Young Jin Kim, Yunsheng Li, Liliang Ren, Yelong Shen, et al. Phi-4-mini-reasoning: Exploring the limits of small reasoning language models in math.arXiv preprint arXiv:2504.21233, 2025
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128, 2026. 28
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Online Experiential Learning for Language Models
Tianzhu Ye, Li Dong, Qingxiu Dong, Xun Wu, Shaohan Huang, and Furu Wei. Online experiential learning for language models.arXiv preprint arXiv:2603.16856, 2026
work page internal anchor Pith review arXiv 2026
-
[43]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
A gift from knowledge distillation: Fast optimization, network minimization and transfer learning
Junho Yim, Donggyu Joo, Jihoon Bae, and Junmo Kim. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4133–4141, 2017
2017
-
[45]
Dapo: An open-source llm reinforcement learning system at scale.Advances in Neural Information Processing Systems, 38:113222– 113244, 2026
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.Advances in Neural Information Processing Systems, 38:113222– 113244, 2026
2026
-
[46]
Sergey Zagoruyko and Nikos Komodakis. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer.arXiv preprint arXiv:1612.03928, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[47]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 29 Table 7: Notation summary (Part I): models, architecture, distributions, and objectives. Symbol Mea...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
(OPRD) SNR(gOPRD) = +∞ as long as h(L) θ,t ̸=h (L) T,t (i.e., the OPRD loss has not yet converged). Proof. (OPD case.)By Lemma 1,∥¯g OPD∥2 2 =∥E p[ut∇logp]∥ 2
-
[51]
Since ¯u=DKL(p∥q)≤δ and Varp(ut)≤2δ+O(δ 2) by a standard Pinsker-type expansion oflog(p/q)aroundp=q, we have ∥¯gOPD∥2 2 =O(δ)
Applying Cauchy–Schwarz, ∥¯gOPD∥2 2 ≤E p[u2 t ]·E p[∥∇logp∥ 2 2] = (Var p(ut) + ¯u2)·Tr(F(θ)), where F(θ) is the Fisher information matrix. Since ¯u=DKL(p∥q)≤δ and Varp(ut)≤2δ+O(δ 2) by a standard Pinsker-type expansion oflog(p/q)aroundp=q, we have ∥¯gOPD∥2 2 =O(δ). Meanwhile, by Theorem 4 (Eq. 21), Tr(Cov[gOPD])≥Var p(ut)· F min(θ) = Θ(δ) . Since the num...
-
[52]
mostly signal
for the lower Lipschitz constant cℓ of ℓout, so the ratio between the two directions scales as (σ1/σd)2 up to constants determined byℓ out, recovering (29) after absorbing constants intoC ℓ. Remark2 (Intermediate layers).Theorems 7 and 8 concern only the last-layer hidden state, because any output-space ℓout is computed solely fromWhead h(L) and therefore...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.