Learning What to Forget: Improving LLM Unlearning via Learned Token-Level Importance
Pith reviewed 2026-06-28 02:14 UTC · model grok-4.3
The pith
Joint optimization of model parameters and token weights recovers oracle forget-specific tokens under a separation condition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a natural separation condition, the joint optimization over model parameters and token weights recovers the oracle forget-specific token support. Motivated by this, ATWU learns token forget-specificity via a simple linear scorer over hidden states during unlearning, achieving state-of-the-art forget-retain trade-offs on TOFU and RWKU while aligning learned scores better with ground truth spans.
What carries the argument
The joint optimization problem over model parameters and token weights, solved by alternating updates where token weights are produced by a linear scorer on the model's hidden states.
If this is right
- ATWU outperforms sample-level methods, probability-based heuristics, and auxiliary-model approaches on forget-retain trade-offs.
- The learned token scores align substantially better with ground truth forget-specific spans.
- Token-level forget-specificity can be learned unsupervised directly from model representations with minimal computational overhead.
- Retain conflict provides an effective criterion for identifying what to forget in language models.
Where Pith is reading between the lines
- This could extend to identifying important tokens in other model adaptation tasks like fine-tuning or editing.
- If the separation condition is approximately satisfied in practice, it may enable more targeted and efficient unlearning in deployed systems.
- Similar conflict-based weighting might improve performance in related areas such as differential privacy or continual learning.
- Future work could test whether the linear scorer generalizes across different model architectures without retraining.
Load-bearing premise
The natural separation condition between forget and retain objectives must hold for the joint optimization to recover the oracle forget-specific token support.
What would settle it
Running ATWU on a synthetic dataset where forget and retain objectives are deliberately entangled and observing that the recovered token support does not match the known oracle would falsify the recovery claim.
Figures
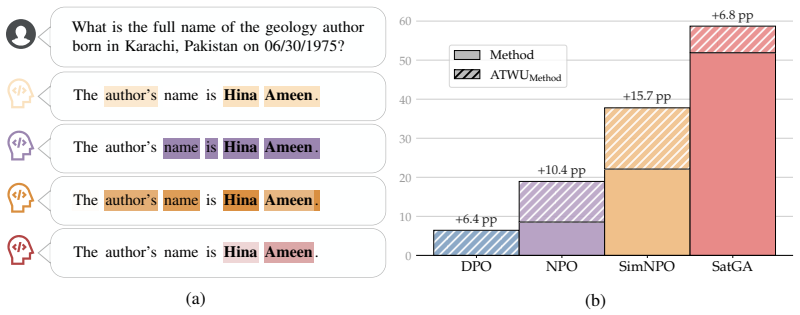
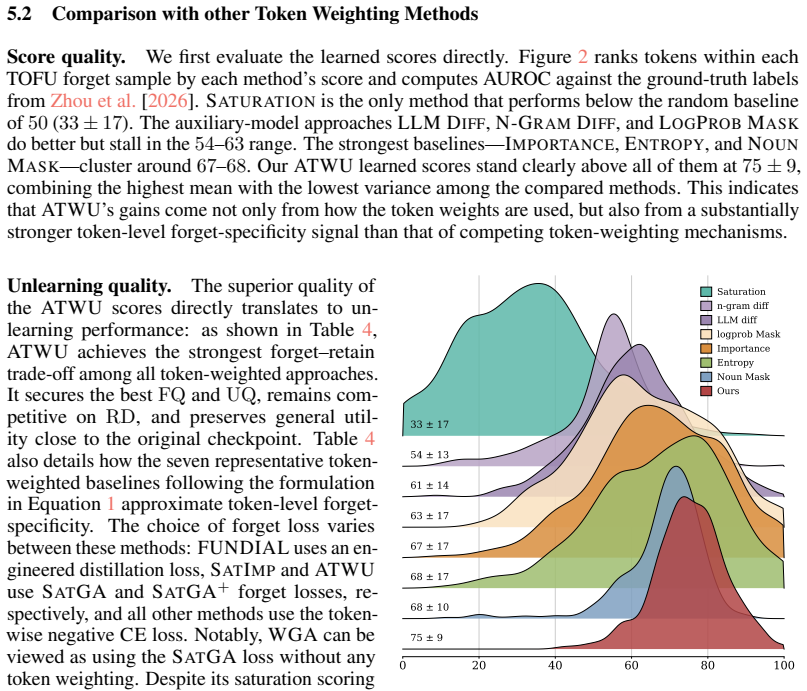

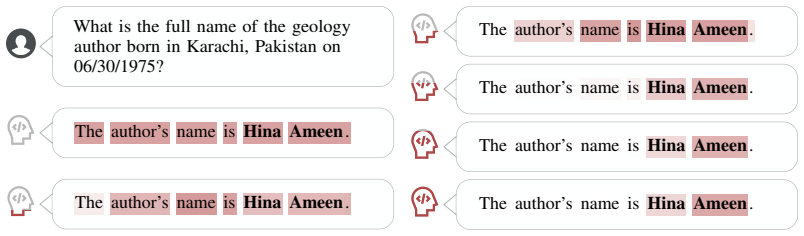
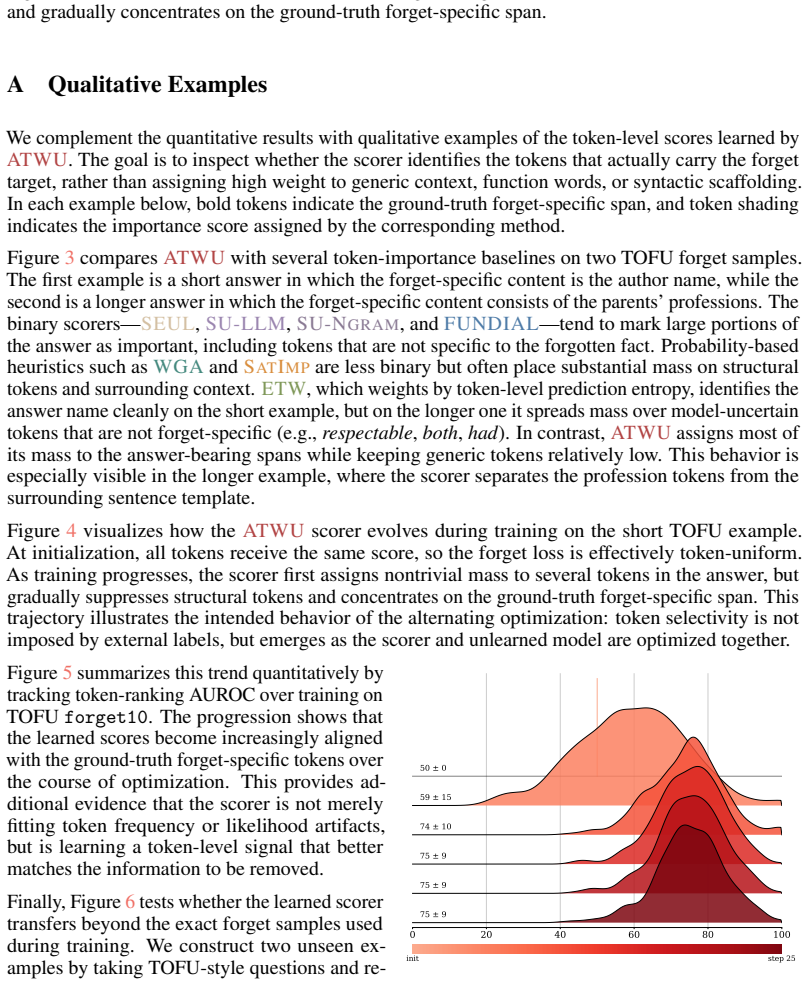


read the original abstract
Machine unlearning aims to remove targeted knowledge from a trained model while preserving its general capabilities. For autoregressive language models, not all tokens in a forget sample are equally relevant to forgetting. Existing approaches either ignore this heterogeneity or rely on auxiliary models, heuristics, or external annotations to estimate each token's relevance for forgetting. We instead characterize it through the interaction with the retain objective: a token is forget-specific to the extent that minimizing the forget loss on that token does not conflict with retain optimality. We formalize this perspective as a joint optimization problem over the model parameters and the token weights and show that, under a natural separation condition, the resulting objective recovers the oracle forget-specific token support. Motivated by this formulation, we introduce Alternating Token-Weighted Unlearning (ATWU), a lightweight framework that jointly learns token forget-specificity and model parameters during unlearning using a simple linear scorer over the hidden states, without external token level supervision. Across TOFU and RWKU, ATWU achieves state of the art forget-retain trade-offs, outperforming sample-level methods, probability-based token weighting heuristics, and auxiliary-model-based approaches. Moreover, the learned scores align substantially better with ground truth forget-specific spans, indicating that ATWU identifies semantically meaningful token level forgetting signals. Overall, our results suggest that retain conflict provides an effective criterion for identifying what language models should forget, enabling unsupervised learning of token level forget-specificity directly from model representations with minimal computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that token forget-specificity in LLM unlearning can be characterized by the degree to which minimizing forget loss on a token conflicts with retain optimality. It formalizes this as a joint optimization over model parameters and token weights, proves that under a natural separation condition the objective recovers the oracle forget-specific token support, and introduces ATWU, which learns a linear scorer over hidden states to estimate token weights without external supervision. Experiments on TOFU and RWKU show ATWU achieves SOTA forget-retain trade-offs over sample-level, heuristic, and auxiliary-model baselines, with learned scores aligning better with ground-truth forget spans.
Significance. If the separation condition holds and the empirical gains are robust, the work supplies a lightweight, unsupervised criterion for token-level unlearning that avoids auxiliary models or annotations. The alignment of learned scores with ground-truth spans and the outperformance on standard benchmarks indicate a practical advance in precise, retain-preserving unlearning for autoregressive models.
major comments (3)
- [§3] §3 (formalization and separation condition): The central theoretical claim—that joint optimization recovers the oracle forget-specific support—rests on an unstated or only informally described 'natural separation condition.' No explicit mathematical statement, proof sketch, or empirical check (e.g., gradient-overlap statistics on TOFU/RWKU) is provided; if the condition fails when retain and forget gradients overlap on many tokens, the derivation does not hold and ATWU reduces to an ad-hoc linear scorer whose superiority must be justified purely empirically.
- [§4] §4 (ATWU algorithm and linear scorer): The alternating optimization jointly learns the linear scorer and model parameters, yet no ablation isolates the contribution of the learned token weights versus the alternating schedule or the choice of hidden-state features; without these controls it is unclear whether the reported trade-off improvements are attributable to the proposed token-level mechanism.
- [Table 1 / §5] Table 1 / §5 (forget-retain trade-offs): The SOTA claims are presented without reported variance across random seeds or statistical significance tests against the strongest baselines (probability-based heuristics and auxiliary-model methods); a single-run comparison is insufficient to establish reliable superiority on TOFU and RWKU.
minor comments (2)
- Notation for the token-weight vector and the linear scorer parameters is introduced without a consolidated table of symbols, making it difficult to track definitions across the formalization and algorithm sections.
- Figure captions for the alignment plots with ground-truth spans should explicitly state the metric used (e.g., precision@K or IoU) and the number of samples averaged.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, agreeing where revisions are needed to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (formalization and separation condition): The central theoretical claim—that joint optimization recovers the oracle forget-specific support—rests on an unstated or only informally described 'natural separation condition.' No explicit mathematical statement, proof sketch, or empirical check (e.g., gradient-overlap statistics on TOFU/RWKU) is provided; if the condition fails when retain and forget gradients overlap on many tokens, the derivation does not hold and ATWU reduces to an ad-hoc linear scorer whose superiority must be justified purely empirically.
Authors: We agree that the separation condition requires a more explicit treatment. In the revised manuscript we will add a formal mathematical statement of the condition (including the precise gradient non-overlap requirement), include a concise proof sketch in §3 or the appendix, and report an empirical verification via gradient-overlap statistics computed on the TOFU and RWKU datasets. These additions will clarify the scope of the theoretical guarantee and allow readers to assess when the recovery result applies. revision: yes
-
Referee: [§4] §4 (ATWU algorithm and linear scorer): The alternating optimization jointly learns the linear scorer and model parameters, yet no ablation isolates the contribution of the learned token weights versus the alternating schedule or the choice of hidden-state features; without these controls it is unclear whether the reported trade-off improvements are attributable to the proposed token-level mechanism.
Authors: We acknowledge the value of targeted ablations. The revision will include additional experiments that (i) compare ATWU against a uniform-weight baseline (removing the learned scorer), (ii) contrast the alternating schedule with a joint-optimization variant, and (iii) ablate different hidden-state feature choices (last-layer vs. averaged layers). These controls will isolate the contribution of the token-weighting mechanism and the optimization procedure. revision: yes
-
Referee: [Table 1 / §5] Table 1 / §5 (forget-retain trade-offs): The SOTA claims are presented without reported variance across random seeds or statistical significance tests against the strongest baselines (probability-based heuristics and auxiliary-model methods); a single-run comparison is insufficient to establish reliable superiority on TOFU and RWKU.
Authors: We agree that single-run results limit the strength of the empirical claims. In the revised manuscript we will rerun all methods with at least three random seeds, report mean and standard deviation for the forget-retain metrics, and include paired statistical significance tests (e.g., t-tests) against the strongest baselines. This will provide a more rigorous assessment of the observed improvements. revision: yes
Circularity Check
No significant circularity; derivation is conditional and self-contained
full rationale
The paper's core formalization is a joint optimization over parameters and token weights, with recovery of oracle support shown only under an explicitly invoked 'natural separation condition' between forget and retain objectives. This is a standard conditional theorem rather than a tautology or fit-by-construction. The ATWU linear scorer is learned jointly during unlearning without external supervision, but claims of alignment with ground-truth spans and SOTA trade-offs are presented as empirical outcomes on TOFU/RWKU, not as predictions forced by the inputs. No self-citations appear load-bearing, no ansatz is smuggled, and no known result is merely renamed. The derivation introduces an independent retain-conflict criterion and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption natural separation condition between forget and retain objectives
Reference graph
Works this paper leans on
-
[1]
2024 , url=
Pratyush Maini and Zhili Feng and Avi Schwarzschild and Zachary Chase Lipton and J Zico Kolter , booktitle=. 2024 , url=
2024
-
[2]
OpenUnlearning: Accelerating
Vineeth Dorna and Anmol Reddy Mekala and Wenlong Zhao and Andrew McCallum and J Zico Kolter and Zachary Chase Lipton and Pratyush Maini , booktitle=. OpenUnlearning: Accelerating. 2026 , url=
2026
-
[3]
Smith and Chiyuan Zhang , booktitle=
Weijia Shi and Jaechan Lee and Yangsibo Huang and Sadhika Malladi and Jieyu Zhao and Ari Holtzman and Daogao Liu and Luke Zettlemoyer and Noah A. Smith and Chiyuan Zhang , booktitle=. 2025 , url=
2025
-
[4]
Rethinking
Qizhou Wang and Jin Peng Zhou and Zhanke Zhou and Saebyeol Shin and Bo Han and Kilian Q Weinberger , booktitle=. Rethinking. 2025 , url=
2025
-
[5]
2025 , eprint=
Unlearning That Lasts: Utility-Preserving, Robust, and Almost Irreversible Forgetting in LLMs , author=. 2025 , eprint=
2025
-
[6]
The Ninth International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. The Ninth International Conference on Learning Representations , year=
-
[7]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[8]
Exploring Criteria of Loss Reweighting to Enhance
Puning Yang and Qizhou Wang and Zhuo Huang and Tongliang Liu and Chengqi Zhang and Bo Han , booktitle=. Exploring Criteria of Loss Reweighting to Enhance. 2025 , url=
2025
-
[9]
Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Optuna: A next-generation hyperparameter optimization framework , author=. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[10]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal=. The
-
[12]
2024 , eprint=
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. 2024 , eprint=
2024
-
[13]
2024 , url=
Zhuoran Jin and Pengfei Cao and Chenhao Wang and Zhitao He and Hongbang Yuan and Jiachun Li and Yubo Chen and Kang Liu and Jun Zhao , booktitle=. 2024 , url=
2024
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Selective forgetting: Advancing machine unlearning techniques and evaluation in language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
Undial: Self-distillation with adjusted logits for robust unlearning in large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[17]
Nathaniel Li and Alexander Pan and Anjali Gopal and Summer Yue and Daniel Berrios and Alice Gatti and Justin D. Li and Ann-Kathrin Dombrowski and Shashwat Goel and Gabriel Mukobi and Nathan Helm-Burger and Rassin Lababidi and Lennart Justen and Andrew Bo Liu and Michael Chen and Isabelle Barrass and Oliver Zhang and Xiaoyuan Zhu and Rishub Tamirisa and Bh...
2024
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Not all tokens are meant to be forgotten , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Knowledge unlearning for mitigating privacy risks in language models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[20]
Advances in neural information processing systems , volume=
Quark: Controllable text generation with reinforced unlearning , author=. Advances in neural information processing systems , volume=
-
[21]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[22]
First Conference on Language Modeling , year=
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning , author=. First Conference on Language Modeling , year=
-
[23]
Simplicity Prevails: Rethinking Negative Preference Optimization for
Chongyu Fan and Jiancheng Liu and Licong Lin and Jinghan Jia and Ruiqi Zhang and Song Mei and Sijia Liu , booktitle=. Simplicity Prevails: Rethinking Negative Preference Optimization for. 2026 , url=
2026
-
[24]
The Thirteenth International Conference on Learning Representations , year=
Scalable Extraction of Training Data from Aligned, Production Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[27]
The Eleventh International Conference on Learning Representations , year=
Quantifying Memorization Across Neural Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[28]
2023 , month =
Eldan, Ronen and Russinovich, Mark , title =. 2023 , month =
2023
-
[29]
Right to be forgotten in the Era of large language models: implications, challenges, and solutions
Right to be forgotten in the. AI and Ethics , author =. 2025 , pages =. doi:10.1007/s43681-024-00573-9 , abstract =
-
[31]
and Jia, Hengrui and Travers, Adelin and Zhang, Baiwu and Lie, David and Papernot, Nicolas , booktitle=
Bourtoule, Lucas and Chandrasekaran, Varun and Choquette-Choo, Christopher A. and Jia, Hengrui and Travers, Adelin and Zhang, Baiwu and Lie, David and Papernot, Nicolas , booktitle=. Machine Unlearning , year=
-
[33]
2026 , eprint=
Forget What Matters, Keep the Rest: Selective Unlearning of Informative Tokens , author=. 2026 , eprint=
2026
-
[37]
2017 , url=
Understanding intermediate layers using linear classifier probes , author=. 2017 , url=
2017
-
[39]
Phi-3 technical report: A highly capable language model locally on your phone, 2024
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, and Others. Phi-3 technical report: A highly capable language model locally on your phone, 2024. URL https://arxiv.org/abs/2404.14219
Pith/arXiv arXiv 2024
-
[40]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2623--2631, 2019
2019
-
[41]
Understanding intermediate layers using linear classifier probes, 2017
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes, 2017. URL https://openreview.net/forum?id=ryF7rTqgl
2017
-
[42]
Identifying and mitigating the security risks of generative ai
Clark Barrett, Brad Boyd, Elie Bursztein, Nicholas Carlini, Brad Chen, Jihye Choi, Amrita Roy Chowdhury, Mihai Christodorescu, Anupam Datta, Soheil Feizi, Kathleen Fisher, Tatsunori Hashimoto, Dan Hendrycks, Somesh Jha, Daniel Kang, Florian Kerschbaum, Eric Mitchell, John Mitchell, Zulfikar Ramzan, Khawaja Shams, Dawn Song, Ankur Taly, and Diyi Yang. Iden...
-
[43]
Yonatan Belinkov, Nadir Durrani, Fahim Dalvi, Hassan Sajjad, and James Glass. What do neural machine translation models learn about morphology? In Regina Barzilay and Min-Yen Kan, editors, Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 861--872, Vancouver, Canada, July 2017. Associati...
-
[44]
Adversary instantiation: Lower bounds for differentially private machine learning,
Lucas Bourtoule, Varun Chandrasekaran, Christopher A. Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. In 2021 IEEE Symposium on Security and Privacy (SP), pages 141--159, 2021. doi:10.1109/SP40001.2021.00019
-
[45]
Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, SP '15, page 463–480, USA, 2015. IEEE Computer Society. ISBN 9781467369497. doi:10.1109/SP.2015.35. URL https://doi.org/10.1109/SP.2015.35
-
[46]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=TatRHT_1cK
2023
-
[47]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. What does BERT look at? an analysis of BERT ' s attention. In Tal Linzen, Grzegorz Chrupa a, Yonatan Belinkov, and Dieuwke Hupkes, editors, Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 276--286, Florence, Italy, August 201...
-
[48]
Undial: Self-distillation with adjusted logits for robust unlearning in large language models
Yijiang River Dong, Hongzhou Lin, Mikhail Belkin, Ramon Huerta, and Ivan Vuli \'c . Undial: Self-distillation with adjusted logits for robust unlearning in large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)...
2025
-
[49]
Openunlearning: Accelerating LLM unlearning via unified benchmarking of methods and metrics
Vineeth Dorna, Anmol Reddy Mekala, Wenlong Zhao, Andrew McCallum, J Zico Kolter, Zachary Chase Lipton, and Pratyush Maini. Openunlearning: Accelerating LLM unlearning via unified benchmarking of methods and metrics. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026. URL https://openreview.ne...
2026
-
[50]
Who's Harry Potter ? A pproximate unlearning in LLMs
Ronen Eldan and Mark Russinovich. Who's Harry Potter ? A pproximate unlearning in LLMs . arXiv, October 2023. URL https://www.microsoft.com/en-us/research/publication/whos-harry-potter-approximate-unlearning-in-llms/
2023
-
[51]
Simplicity prevails: Rethinking negative preference optimization for LLM unlearning
Chongyu Fan, Jiancheng Liu, Licong Lin, Jinghan Jia, Ruiqi Zhang, Song Mei, and Sijia Liu. Simplicity prevails: Rethinking negative preference optimization for LLM unlearning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=JbvSQm5h1l
2026
-
[52]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac'h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
arXiv 2024
-
[53]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The L lama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[54]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In The Ninth International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[55]
John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 4129--...
-
[56]
Knowledge unlearning for mitigating privacy risks in language models
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. Knowledge unlearning for mitigating privacy risks in language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14389--14408, 2023
2023
-
[57]
RWKU : Benchmarking real-world knowledge unlearning for large language models
Zhuoran Jin, Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, and Jun Zhao. RWKU : Benchmarking real-world knowledge unlearning for large language models. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL https://openreview.net/forum?id=wOmtZ5FgMH
2024
-
[58]
Copyright violations and large language models
Antonia Karamolegkou, Jiaang Li, Li Zhou, and Anders S gaard. Copyright violations and large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7403--7412, Singapore, December 2023. Association for Computational Linguistics. doi:10.18653/v1/2...
-
[59]
Forget what matters, keep the rest: Selective unlearning of informative tokens, 2026
Seunghee Koh, Sunghyun Baek, Youngdong Kim, and Junmo Kim. Forget what matters, keep the rest: Selective unlearning of informative tokens, 2026. URL https://arxiv.org/abs/2604.17785
Pith/arXiv arXiv 2026
-
[60]
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew Bo Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Ariel Herbert-Voss, Cort B Breuer, Andy Zo...
2024
-
[61]
Quark: Controllable text generation with reinforced unlearning
Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, and Yejin Choi. Quark: Controllable text generation with reinforced unlearning. Advances in neural information processing systems, 35: 0 27591--27609, 2022
2022
-
[62]
TOFU : A task of fictitious unlearning for LLM s
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary Chase Lipton, and J Zico Kolter. TOFU : A task of fictitious unlearning for LLM s. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=B41hNBoWLo
2024
-
[63]
Feder Cooper, Daphne Ippolito, Christopher A
Milad Nasr, Javier Rando, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A. Choquette-Choo, Florian Tram \`e r, and Katherine Lee. Scalable extraction of training data from aligned, production language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://open...
2025
-
[64]
A Survey of Machine Unlearning
Thanh Tam Nguyen, Thanh Trung Huynh, Zhao Ren, Phi Le Nguyen, Alan Wee-Chung Liew, Hongzhi Yin, and Quoc Viet Hung Nguyen. A survey of machine unlearning. ACM Trans. Intell. Syst. Technol., 16 0 (5), September 2025. ISSN 2157-6904. doi:10.1145/3749987. URL https://doi.org/10.1145/3749987
-
[65]
GPT-5.4 mini , 2026
OpenAI . GPT-5.4 mini , 2026. URL https://developers.openai.com/api/docs/models/gpt-5.4-mini. OpenAI API documentation
2026
-
[66]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=HPuSIXJaa9
2023
-
[67]
Smith, and Chiyuan Zhang
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A. Smith, and Chiyuan Zhang. MUSE : Machine unlearning six-way evaluation for language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=TArmA033BU
2025
-
[68]
Unlearning that lasts: Utility-preserving, robust, and almost irreversible forgetting in llms, 2025
Naman Deep Singh, Maximilian Müller, Francesco Croce, and Matthias Hein. Unlearning that lasts: Utility-preserving, robust, and almost irreversible forgetting in llms, 2025. URL https://arxiv.org/abs/2509.02820
arXiv 2025
-
[69]
Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT rediscovers the classical NLP pipeline. In Anna Korhonen, David Traum, and Llu \'i s M \`a rquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593--4601, Florence, Italy, July 2019. Association for Computational Linguistics. doi:10.18653/v1/P19-14...
-
[70]
Yixin Wan, Anil Ramakrishna, Kai-Wei Chang, Volkan Cevher, and Rahul Gupta. Not every token needs forgetting: Selective unlearning balancing forgetting and utility in large language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computational Linguistics: EMNLP 2025, page...
-
[71]
Selective forgetting: Advancing machine unlearning techniques and evaluation in language models
Lingzhi Wang, Xingshan Zeng, Jinsong Guo, Kam-Fai Wong, and Georg Gottlob. Selective forgetting: Advancing machine unlearning techniques and evaluation in language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 843--851, 2025 a
2025
-
[72]
Rethinking LLM unlearning objectives: A gradient perspective and go beyond
Qizhou Wang, Jin Peng Zhou, Zhanke Zhou, Saebyeol Shin, Bo Han, and Kilian Q Weinberger. Rethinking LLM unlearning objectives: A gradient perspective and go beyond. In The Thirteenth International Conference on Learning Representations, 2025 b . URL https://openreview.net/forum?id=huo8MqVH6t
2025
-
[73]
Exploring criteria of loss reweighting to enhance LLM unlearning
Puning Yang, Qizhou Wang, Zhuo Huang, Tongliang Liu, Chengqi Zhang, and Bo Han. Exploring criteria of loss reweighting to enhance LLM unlearning. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=mGOugCZlAq
2025
-
[74]
Negative preference optimization: From catastrophic collapse to effective unlearning
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=MXLBXjQkmb
2024
-
[75]
Not all tokens are meant to be forgotten
Xiangyu Zhou, Yao Qiang, Saleh Zare Zade, Douglas Zytko, Prashant Khanduri, and Dongxiao Zhu. Not all tokens are meant to be forgotten. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 38173--38182, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.