ROSUM-MCTS: Monte Carlo Tree Search-Inspired HDL Code Summarization with Structural Rewards
Pith reviewed 2026-06-27 20:20 UTC · model grok-4.3
The pith
ROSUM-MCTS refines HDL code summaries through MCTS-inspired exploration and a composite reward function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
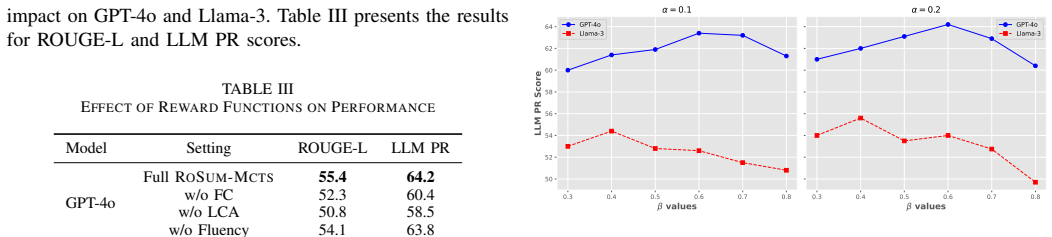
ROSUM-MCTS demonstrates consistent outperformance over baseline methods on the VHDL-eval and Verilog-eval datasets by leveraging structured bottom-up refinement and reinforcement-based optimization, while remaining robust to superficial modifications such as variable renaming.
What carries the argument
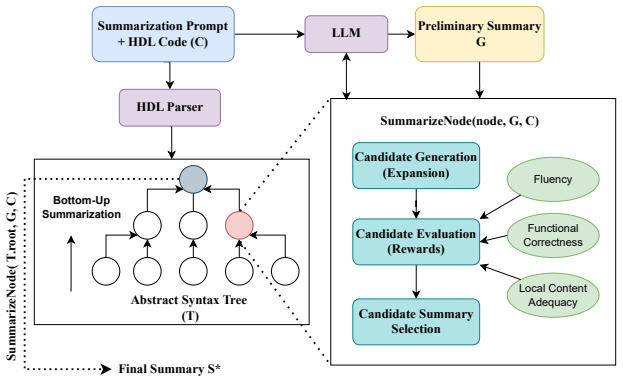
The hierarchical candidate expansion mechanism inspired by Monte Carlo Tree Search that combines local and global context, guided by a composite reward balancing functional correctness, local content adequacy, and fluency.
If this is right
- Both local and global expansion steps are required for the strongest results.
- Balancing functional correctness and local content adequacy in the reward yields the best summaries.
- The method maintains performance under variable renaming where plain LLM baselines decline.
- Ablation tests confirm that removing either expansion strategy or reward component degrades output.
Where Pith is reading between the lines
- The same MCTS-style refinement loop could be tested on summarization of software code in languages like Python or C.
- The structural reward approach might transfer to other HDL-related tasks such as bug detection or test generation.
- Extending the method to multi-file HDL modules would reveal whether global context scaling remains effective.
Load-bearing premise
The composite reward function accurately measures summary quality in a way that matches human judgment and guides useful optimization.
What would settle it
Human raters scoring ROSUM-MCTS summaries no higher than baseline LLM summaries on the VHDL-eval or Verilog-eval datasets would falsify the performance claim.
Figures

read the original abstract
Large language models (LLMs) have shown promise in code summarization, yet their effectiveness for Hardware Description Languages (HDLs) like VHDL and Verilog remains underexplored. We propose ROSUM-MCTS, an LLM-guided approach inspired by Monte Carlo Tree Search (MCTS) that refines summaries through structured exploration and reinforcement-driven optimization. Our method integrates both local and global context via a hierarchical candidate expansion mechanism and optimizes summaries using a composite reward function balancing functional correctness (FC), local content adequacy (LCA), and fluency. We evaluate ROSUM-MCTS on the VHDL-eval and Verilog-eval datasets, demonstrating its consistent outperformance over baseline methods by leveraging structured bottom-up refinement and reinforcement-based optimization. Ablation studies confirm the necessity of both local and global expansion strategies, as well as the importance of balancing FC and LCA for optimal performance. Furthermore, ROSUM-MCTS proves robust against superficial modifications, such as variable renaming, maintaining summary quality where baselines degrade. These results establish ROSUM-MCTS as an effective and robust HDL summarization framework, paving the way for further research into reinforcement-enhanced code summarization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ROSUM-MCTS, an LLM-guided method for HDL code summarization (VHDL and Verilog) that draws on Monte Carlo Tree Search principles. It performs hierarchical candidate expansion to integrate local and global context and optimizes summaries via reinforcement using a composite reward that balances functional correctness (FC), local content adequacy (LCA), and fluency. The manuscript claims consistent outperformance over baselines on the VHDL-eval and Verilog-eval datasets, robustness to superficial changes such as variable renaming, and the necessity of both local/global expansion and FC/LCA balance, as shown by ablation studies.
Significance. If the empirical results are substantiated with quantitative metrics and the composite reward is shown to align with human judgments of summary quality, the work would offer a structured, reinforcement-driven framework for an underexplored domain (HDL summarization). The hierarchical MCTS-inspired refinement and explicit structural rewards represent a potentially reusable approach for code-related generation tasks.
major comments (2)
- [Abstract] Abstract: the central claims of 'consistent outperformance' and 'robustness' are asserted without any quantitative metrics, error bars, dataset sizes, statistical tests, or numerical ablation results. This absence leaves the primary empirical contribution without verifiable support.
- [Method / Evaluation] Method / Evaluation (reward definition and ablation studies): the composite reward (FC + LCA + fluency) is the load-bearing mechanism for both the MCTS search and the reinforcement updates, yet no human evaluation (e.g., Likert ratings, preference judgments, or rank correlation) is reported to establish that the scalar reward correlates with expert assessments of HDL summary usefulness. Without this validation, the reported ablations on FC/LCA balance and the robustness claim to variable renaming optimize an unverified proxy rather than demonstrated summary quality.
minor comments (1)
- [Abstract] The abstract would be strengthened by the inclusion of at least one key quantitative result (e.g., improvement delta or dataset size) to allow readers to gauge the scale of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'consistent outperformance' and 'robustness' are asserted without any quantitative metrics, error bars, dataset sizes, statistical tests, or numerical ablation results. This absence leaves the primary empirical contribution without verifiable support.
Authors: We agree that the abstract should provide quantitative support for its claims. The current version is high-level, but the evaluation section contains the supporting numbers. In the revised manuscript we will update the abstract to report key metrics (e.g., performance deltas on VHDL-eval and Verilog-eval), error bars or standard deviations from repeated runs, dataset sizes, and references to the ablation results and any statistical tests performed. revision: yes
-
Referee: [Method / Evaluation] Method / Evaluation (reward definition and ablation studies): the composite reward (FC + LCA + fluency) is the load-bearing mechanism for both the MCTS search and the reinforcement updates, yet no human evaluation (e.g., Likert ratings, preference judgments, or rank correlation) is reported to establish that the scalar reward correlates with expert assessments of HDL summary usefulness. Without this validation, the reported ablations on FC/LCA balance and the robustness claim to variable renaming optimize an unverified proxy rather than demonstrated summary quality.
Authors: We acknowledge that the manuscript contains no human evaluation (Likert scores, preference judgments, or rank correlation) linking the composite reward to expert judgments. FC is defined via objective functional equivalence checks that can be verified by simulation; LCA and fluency follow established automated metrics from the code-summarization literature. The ablations show that altering the FC/LCA balance measurably affects performance on the same automated metrics used for final evaluation. We will add an expanded justification of the reward design in the method section and a limitations paragraph stating that direct human validation of the reward was not performed and remains future work, thereby making the proxy nature explicit to readers. revision: partial
Circularity Check
No derivation chain or self-referential fitting present
full rationale
The paper describes an empirical LLM-guided MCTS method for HDL summarization, defining a composite reward (FC + LCA + fluency) by construction and evaluating it on VHDL-eval/Verilog-eval datasets with ablations. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The approach is framed as a practical optimization technique rather than a mathematical result that reduces to its inputs. The lack of human correlation for the reward is a validity concern, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Llm4plc: Harnessing large language models for verifiable programming of plcs in industrial control systems,
M. Fakih, R. Dharmaji, Y . Moghaddas, G. Quiros, O. Ogundare, and M. A. Al Faruque, “Llm4plc: Harnessing large language models for verifiable programming of plcs in industrial control systems,” inPro- ceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice, pp. 192–203, 2024
2024
-
[2]
Ircoder: Intermediate representa- tions make language models robust multilingual code generators,
I. Paul, G. Glava ˇs, and I. Gurevych, “Ircoder: Intermediate representa- tions make language models robust multilingual code generators,”arXiv preprint arXiv:2403.03894, 2024
-
[3]
Magicoder: Empower- ing code generation with oss-instruct,
Y . Wei, Z. Wang, J. Liu, Y . Ding, and L. Zhang, “Magicoder: Empower- ing code generation with oss-instruct,”arXiv preprint arXiv:2312.02120, 2023
-
[4]
Harnessing the power of large language models for natural language to first-order logic translation,
Y . Yang, S. Xiong, A. Payani, E. Shareghi, and F. Fekri, “Harnessing the power of large language models for natural language to first-order logic translation,”arXiv preprint arXiv:2305.15541, 2023
-
[5]
Knowledge transfer from high-resource to low-resource programming languages for code llms,
F. Cassano, J. Gouwar, F. Lucchetti, C. Schlesinger, A. Freeman, C. J. Anderson, M. Q. Feldman, M. Greenberg, A. Jangda, and A. Guha, “Knowledge transfer from high-resource to low-resource programming languages for code llms,”Proceedings of the ACM on Programming Languages, vol. 8, no. OOPSLA2, pp. 677–708, 2024
2024
-
[6]
StarCoder: may the source be with you!
R. Li, L. B. Allal, Y . Zi, N. Muennighoff, D. Kocetkov, C. Mou, M. Marone, C. Akiki, J. Li, J. Chim,et al., “Starcoder: may the source be with you!,”arXiv preprint arXiv:2305.06161, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Code Llama: Open Foundation Models for Code
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remez,et al., “Code llama: Open foundation models for code,”arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Codev: Empowering llms for verilog generation through multi-level summarization,
Y . Zhao, D. Huang, C. Li, P. Jin, Z. Nan, T. Ma, L. Qi, Y . Pan, Z. Zhang, R. Zhang,et al., “Codev: Empowering llms for verilog generation through multi-level summarization,”arXiv preprint arXiv:2407.10424, 2024
-
[9]
Origen: Enhancing rtl code generation with code-to-code augmentation and self-reflection,
F. Cui, C. Yin, K. Zhou, Y . Xiao, G. Sun, Q. Xu, Q. Guo, D. Song, D. Lin, X. Zhang,et al., “Origen: Enhancing rtl code generation with code-to-code augmentation and self-reflection,”arXiv preprint arXiv:2407.16237, 2024
-
[10]
Autovcoder: A systematic framework for automated verilog code gen- eration using llms,
M. Gao, J. Zhao, Z. Lin, W. Ding, X. Hou, Y . Feng, C. Li, and M. Guo, “Autovcoder: A systematic framework for automated verilog code gen- eration using llms,” in2024 IEEE 42nd International Conference on Computer Design (ICCD), pp. 162–169, IEEE, 2024
2024
-
[11]
Betterv: Con- trolled verilog generation with discriminative guidance,
Z. Pei, H.-L. Zhen, M. Yuan, Y . Huang, and B. Yu, “Betterv: Con- trolled verilog generation with discriminative guidance,”arXiv preprint arXiv:2402.03375, 2024
-
[12]
Au- tochip: Automating hdl generation using llm feedback,
S. Thakur, J. Blocklove, H. Pearce, B. Tan, S. Garg, and R. Karri, “Au- tochip: Automating hdl generation using llm feedback,”arXiv preprint arXiv:2311.04887, 2023
-
[13]
Classification-based automatic hdl code generation using llms,
W. Sun, B. Li, G. L. Zhang, X. Yin, C. Zhuo, and U. Schlichtmann, “Classification-based automatic hdl code generation using llms,”arXiv preprint arXiv:2407.18326, 2024
-
[14]
Chain- of-descriptions: Improving code llms for vhdl code generation and summarization,
P. Vijayaraghavan, A. Nitsure, C. Mackin, L. Shi, S. Ambrogio, A. Ha- ran, V . Paruthi, A. Elzein, D. Coops, D. Beymer,et al., “Chain- of-descriptions: Improving code llms for vhdl code generation and summarization,” inProceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, pp. 1–10, 2024
2024
-
[15]
Rethinkmcts: Refining erroneous thoughts in monte carlo tree search for code generation,
Q. Li, W. Xia, K. Du, X. Dai, R. Tang, Y . Wang, Y . Yu, and W. Zhang, “Rethinkmcts: Refining erroneous thoughts in monte carlo tree search for code generation,”arXiv preprint arXiv:2409.09584, 2024
-
[16]
Generating code world models with large language models guided by monte carlo tree search,
N. Dainese, M. Merler, M. Alakuijala, and P. Marttinen, “Generating code world models with large language models guided by monte carlo tree search,”arXiv preprint arXiv:2405.15383, 2024
-
[17]
A survey of monte carlo tree search methods,
C. B. Browne, E. Powley, D. Whitehouse, S. M. Lucas, P. I. Cowling, P. Rohlfshagen, S. Tavener, D. Perez, S. Samothrakis, and S. Colton, “A survey of monte carlo tree search methods,”IEEE Transactions on Computational Intelligence and AI in games, vol. 4, no. 1, pp. 1–43, 2012
2012
-
[18]
Verilogeval: Evaluating large language models for verilog code generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “Verilogeval: Evaluating large language models for verilog code generation,” in2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), pp. 1–8, IEEE, 2023
2023
-
[19]
Vhdl-eval: A framework for evaluating large language models in vhdl code generation,
P. Vijayaraghavan, L. Shi, S. Ambrogio, C. Mackin, A. Nitsure, D. Beymer, and E. Degan, “Vhdl-eval: A framework for evaluating large language models in vhdl code generation,” in2024 IEEE LLM Aided Design Workshop (LAD), pp. 1–6, IEEE, 2024
2024
-
[20]
Source code summarization in the era of large language models,
W. Sun, Y . Miao, Y . Li, H. Zhang, C. Fang, Y . Liu, G. Deng, Y . Liu, and Z. Chen, “Source code summarization in the era of large language models,”arXiv preprint arXiv:2407.07959, 2024
-
[21]
Pyverilog: A python-based hardware design processing toolkit for verilog hdl,
S. Takamaeda-Yamazaki, “Pyverilog: A python-based hardware design processing toolkit for verilog hdl,” inApplied Reconfigurable Comput- ing, vol. 9040 ofLecture Notes in Computer Science, pp. 451–460, Springer International Publishing, Apr 2015
2015
-
[22]
pyvhdlparser: A vhdl parser written in python,
P. Lehmann, “pyvhdlparser: A vhdl parser written in python,” 2019
2019
-
[23]
Simcse: Simple contrastive learning of sentence embeddings,
T. Gao, X. Yao, and D. Chen, “Simcse: Simple contrastive learning of sentence embeddings,” inInternational Conference on Learning Representations, 2021
2021
-
[24]
Rouge: A package for automatic evaluation of summaries,
C.-Y . Lin, “Rouge: A package for automatic evaluation of summaries,” inText Summarization Branches Out, 2004
2004
-
[25]
Evaluating instruction-tuned large language models on code comprehension and generation,
Z. Yuan, J. Liu, Q. Zi, M. Liu, X. Peng, and Y . Lou, “Evaluating instruction-tuned large language models on code comprehension and generation,”arXiv preprint arXiv:2308.01240, 2023
-
[26]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga,et al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[27]
Chatgpt api
OpenAI, “Chatgpt api.” https://openai.com/blog/chatgpt/, 2023. APPENDIX TABLE IV PROMPT TEMPLATES USED FOR CANDIDATE GENERATION IN ROSUM-MCTS. HERE,N c =|node.children|,DENOTES THE NUMBER OF CHILD NODES FOR THE CURRENTASTNODE. Variation Type Prompt Template Local Summary Con- text Combine the following child summaries to form a concise summary:[S child1 ,...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.