Event-Driven Reinforcement Learning Enables Long-Horizon Control in Semiconductor Fabrication
Pith reviewed 2026-06-27 14:12 UTC · model grok-4.3
The pith
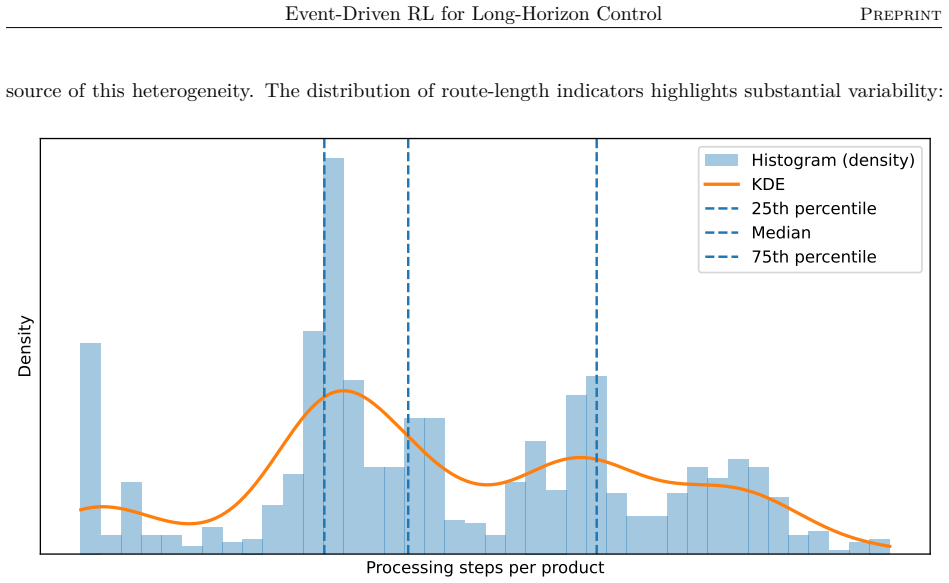
An event-driven reinforcement learning framework delivers significant gains in throughput and utilization for semiconductor fabrication.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
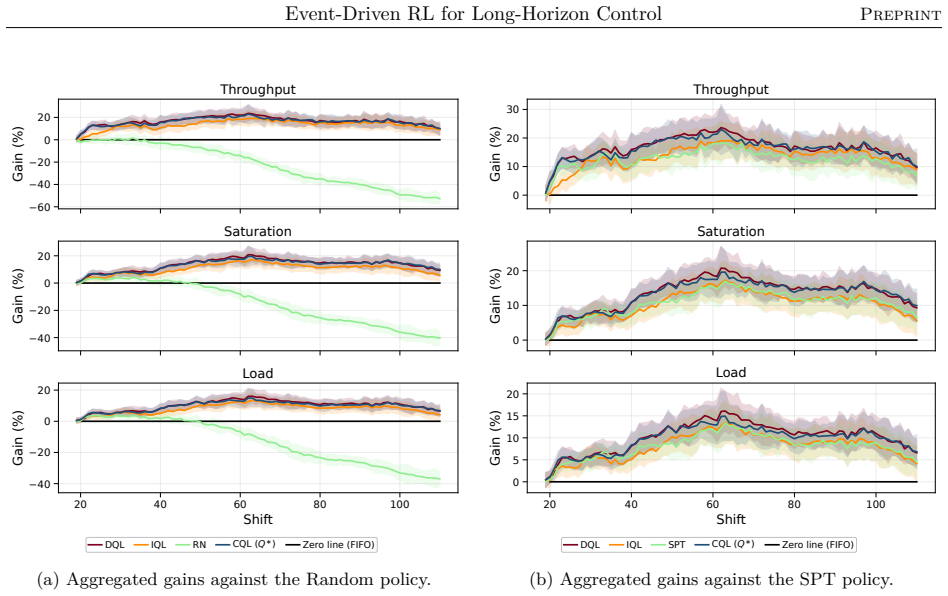
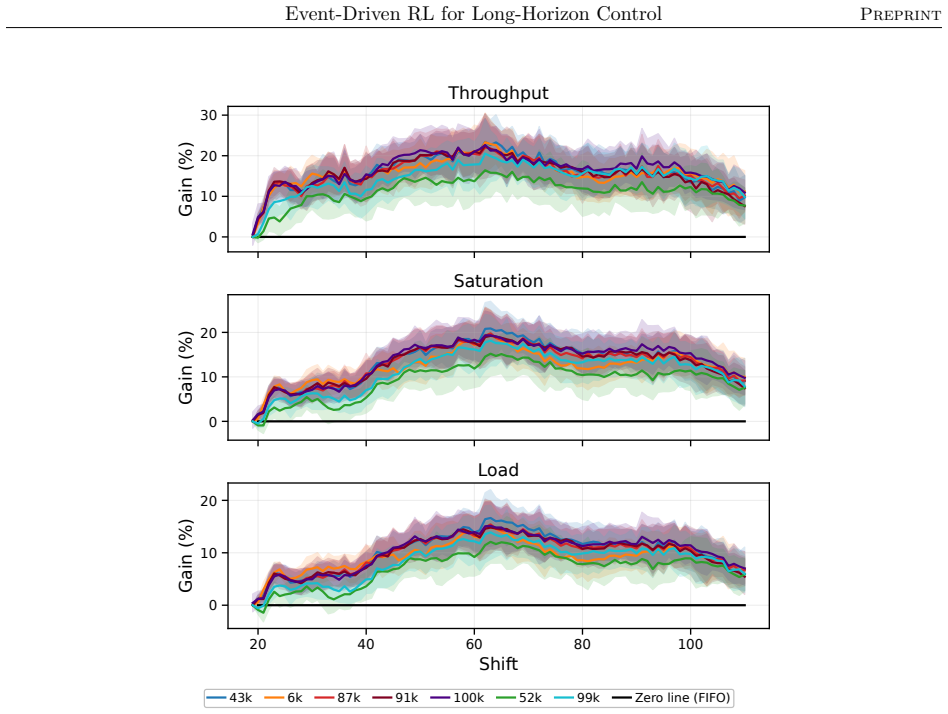
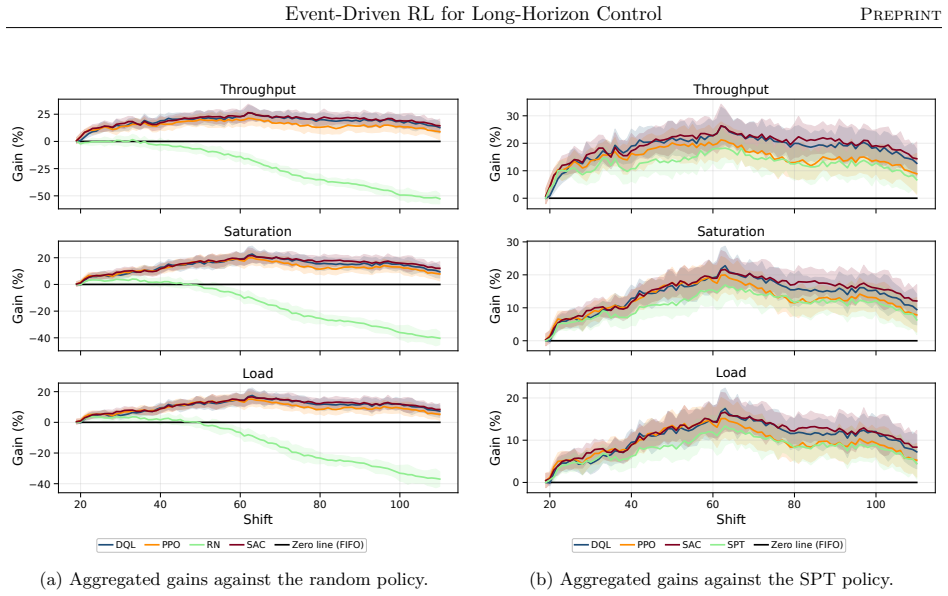
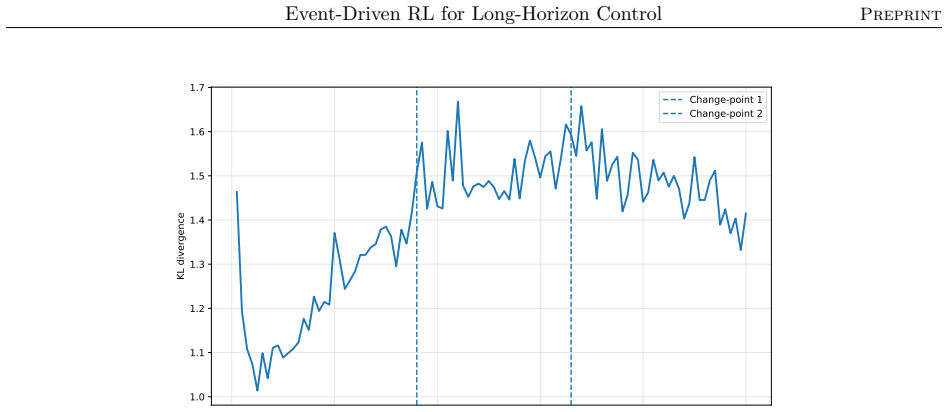
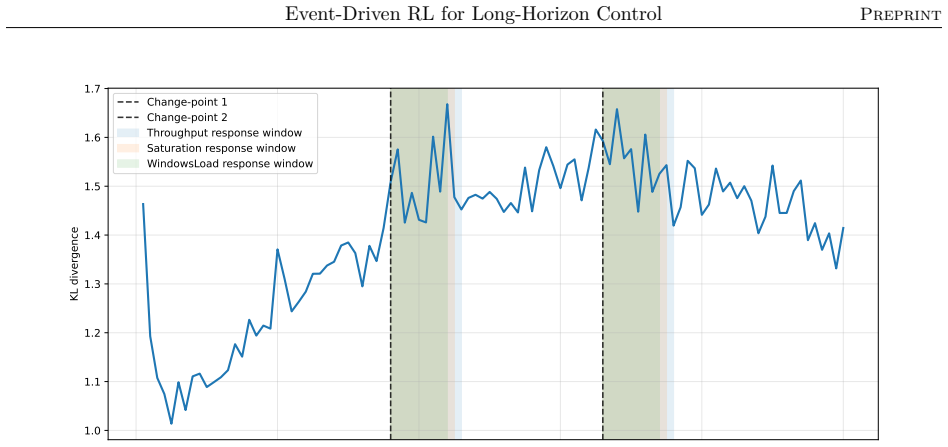
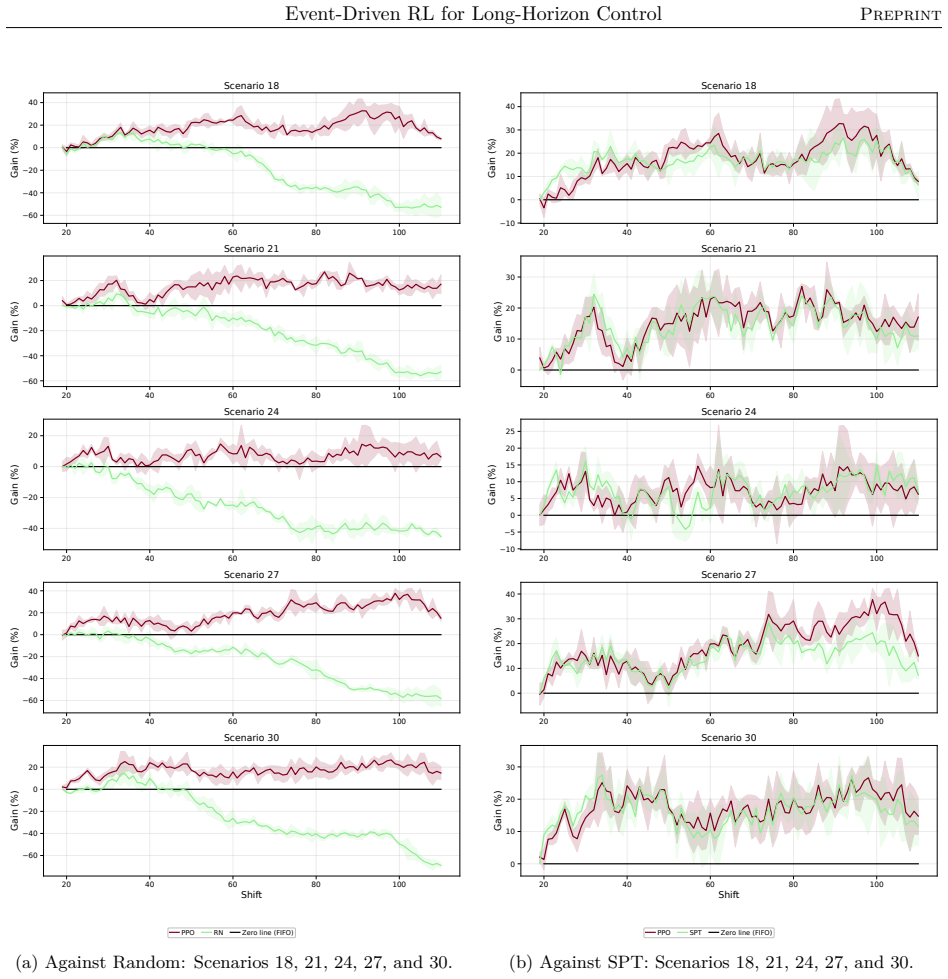
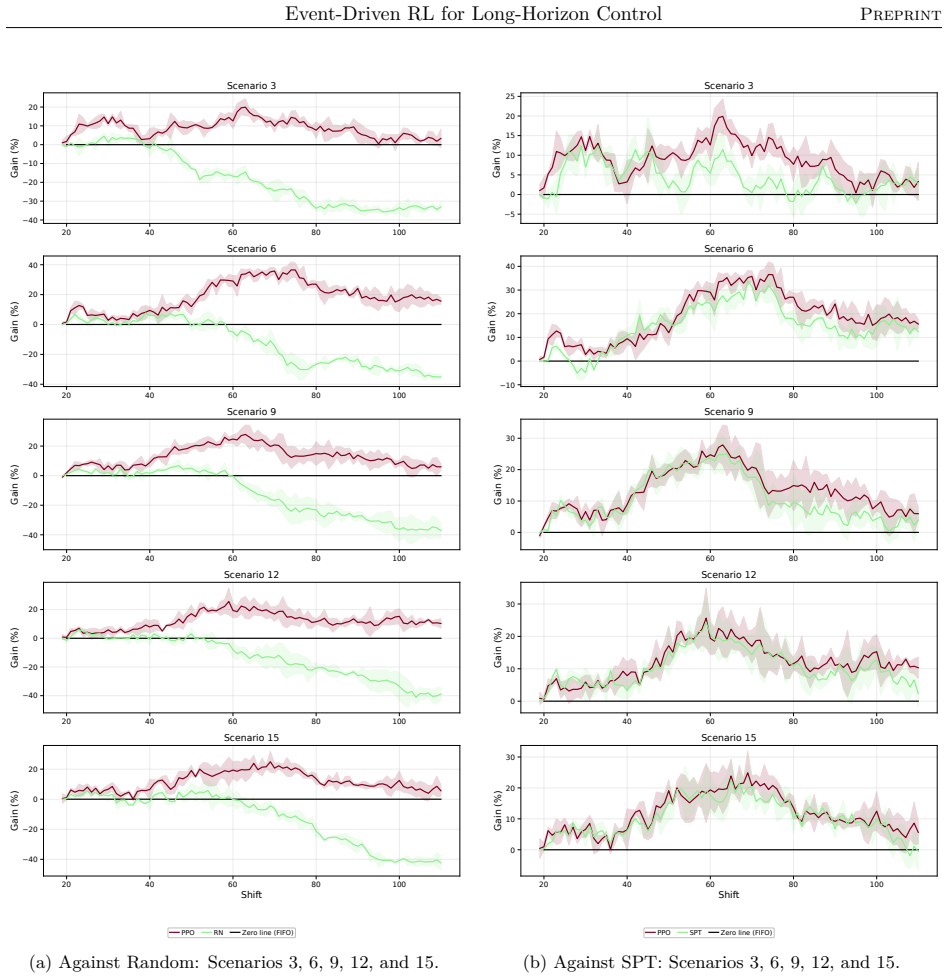
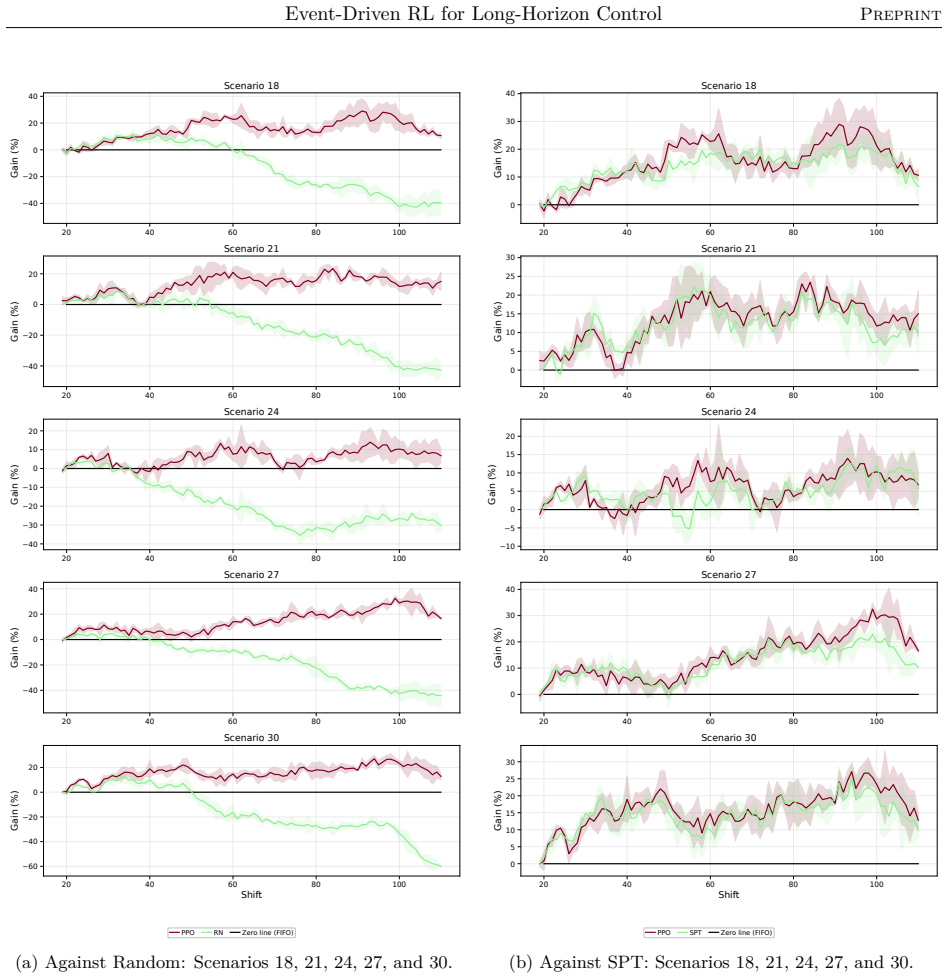
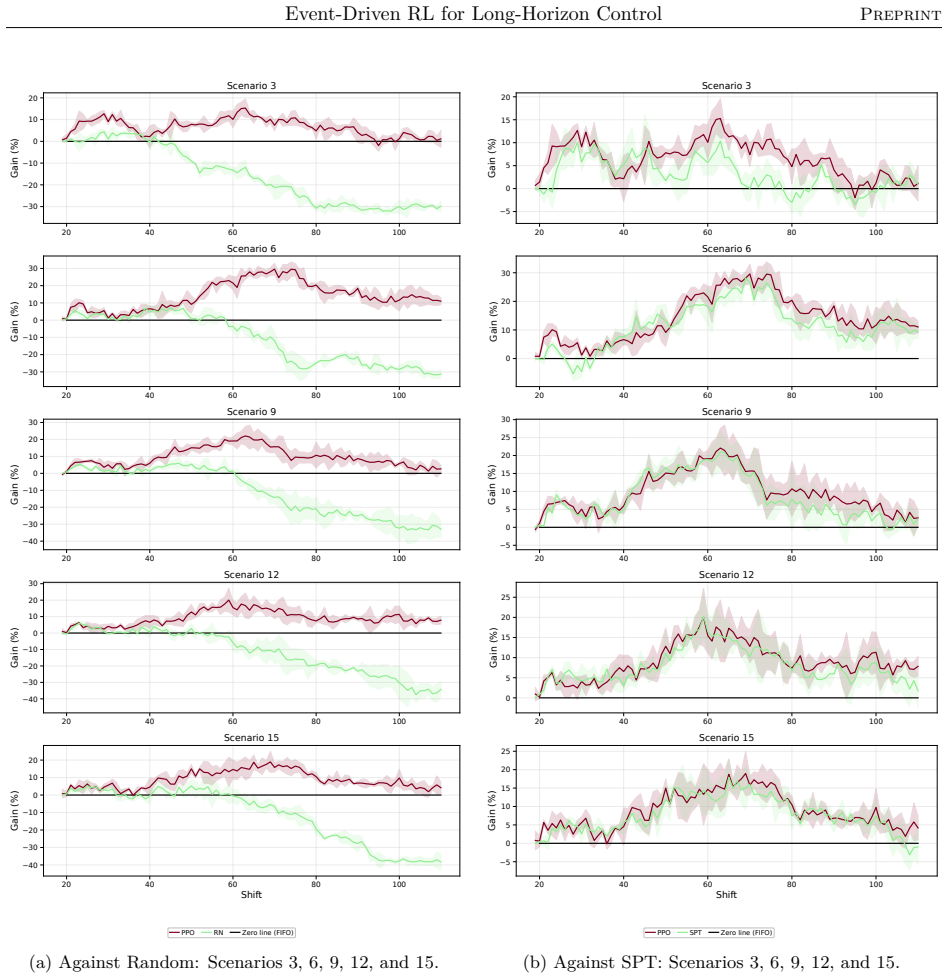
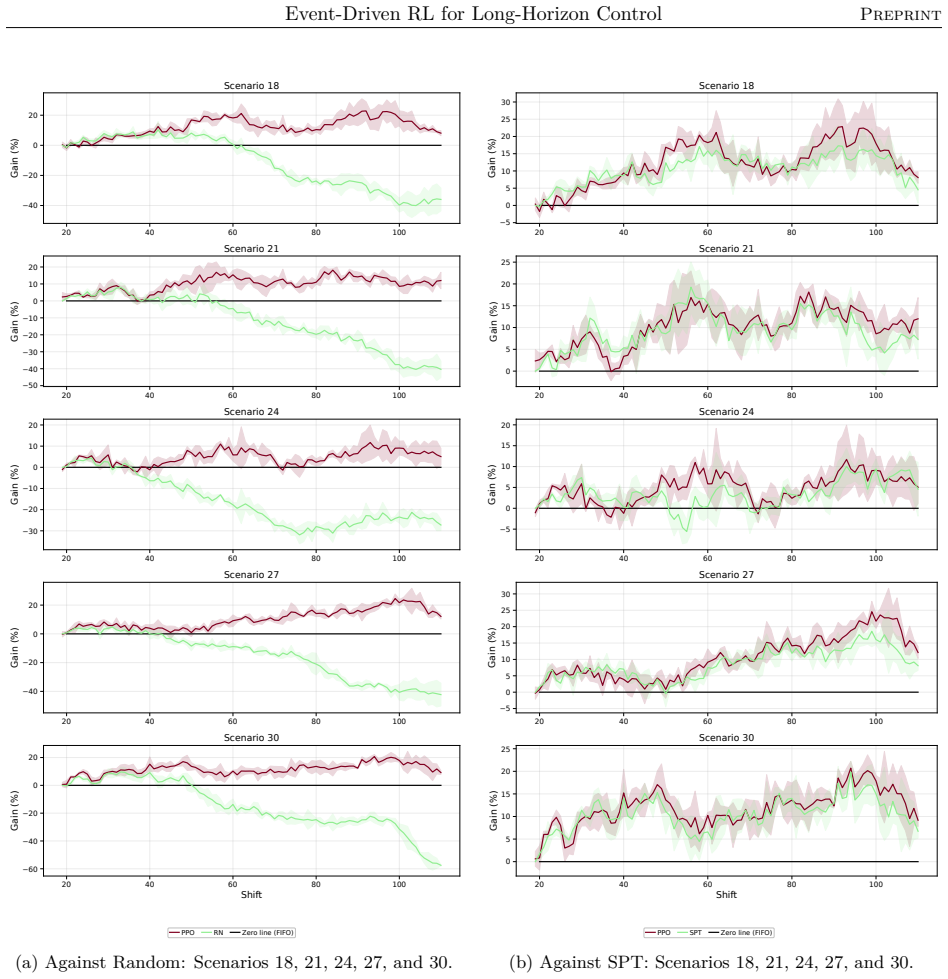
The authors claim that their event-driven temporal-difference formulation, integrated into a centralized multi-objective RL framework, enables effective policy optimization in stochastic, constrained semiconductor systems, yielding significant and consistent gains in throughput and utilization across offline and online training in diverse industry-real simulations, while also clarifying relative strengths of different RL algorithms.
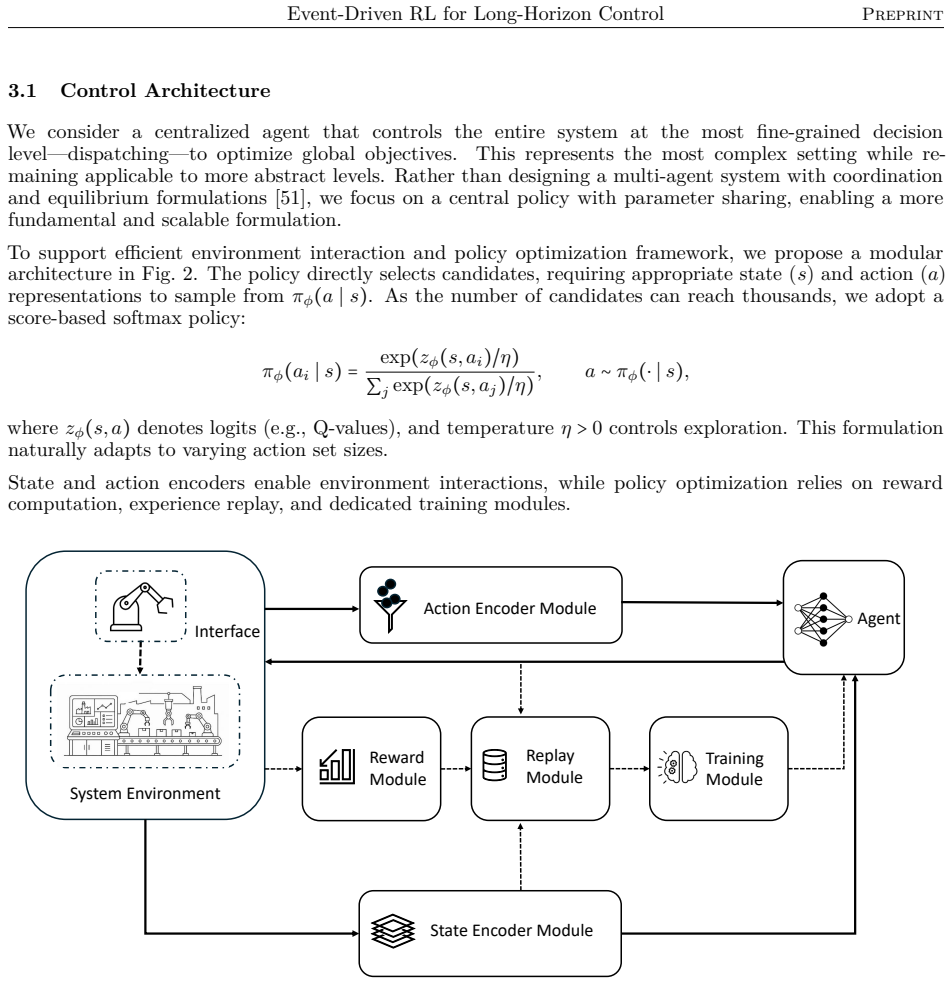
What carries the argument
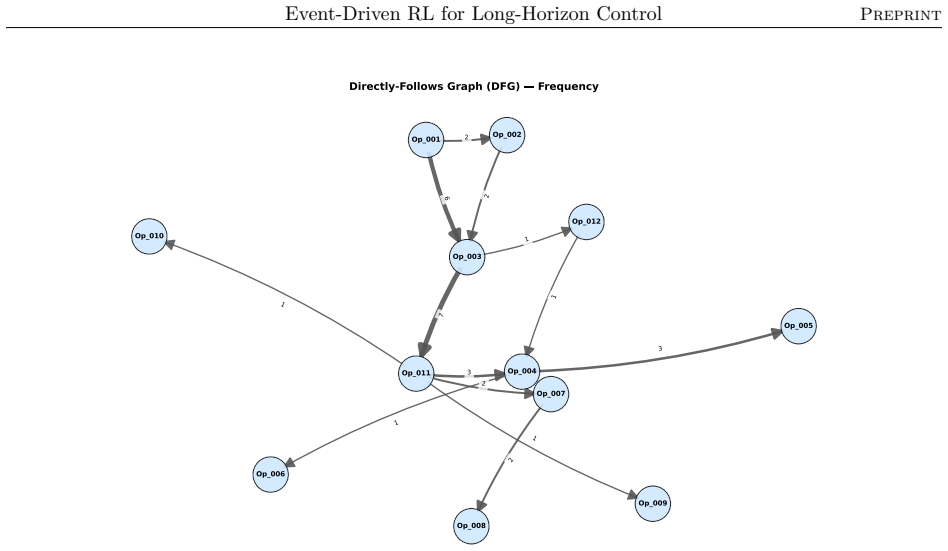
The event-driven temporal-difference formulation, which represents system evolution as an interconnected temporal process driven by discrete events and supports integration with policy optimization methods.
If this is right
- Agents achieve significant and consistent gains in throughput and utilization in both offline and online settings.
- The framework scales to systems with hundreds of processing steps and extensive equipment networks.
- Performance generalizes across different training phases and operating scenarios.
- Different model-free RL algorithms can be incorporated, with relative strengths clarified.
- The approach supports transferability to controlling other event-driven complex adaptive systems.
Where Pith is reading between the lines
- Similar event-driven formulations might apply to other manufacturing or logistics domains with delayed feedback and discrete events.
- If the simulation-to-reality gap is small, the framework could enable real-time adaptive control in operating fabs.
- Extending the centralized agent to distributed decision making could address even larger scales.
- Combining the method with physics-informed constraints might further improve sample efficiency.
Load-bearing premise
High-fidelity simulations of diverse industry-real operating scenarios accurately represent the stochasticity, constraints, and event dynamics of actual semiconductor fabrication systems.
What would settle it
Running the trained policies on a physical semiconductor production line and measuring whether throughput and utilization match the simulated gains would confirm or refute the results.
Figures



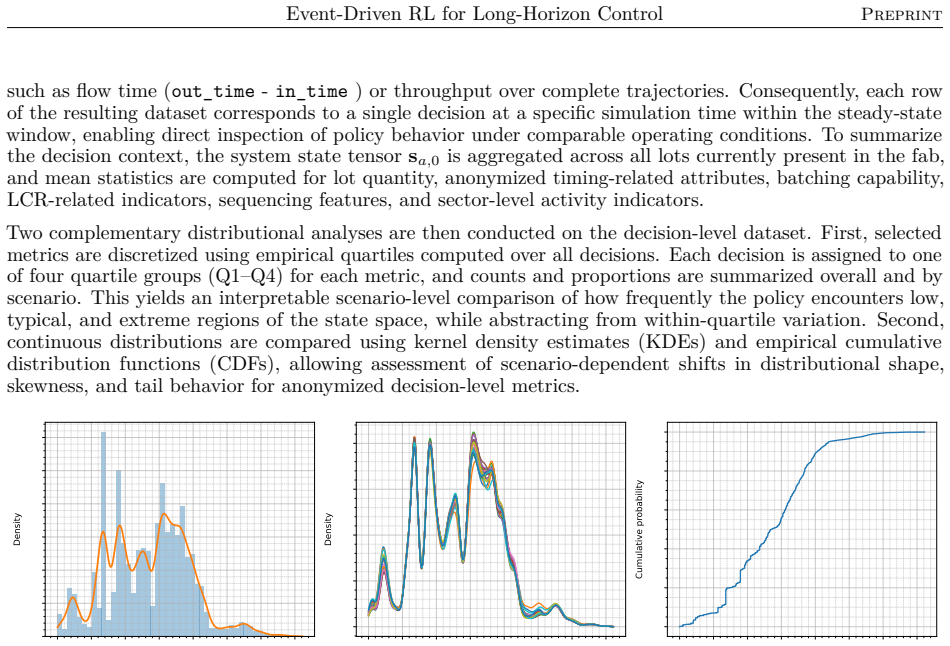
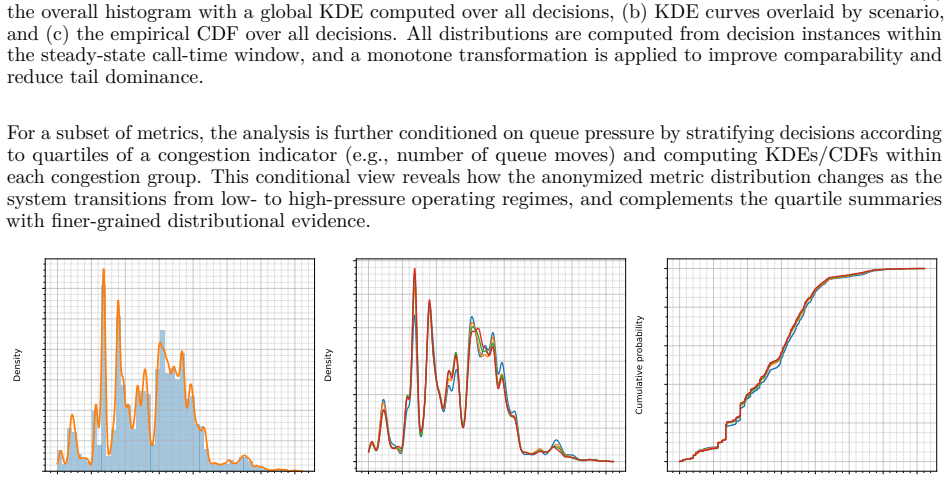

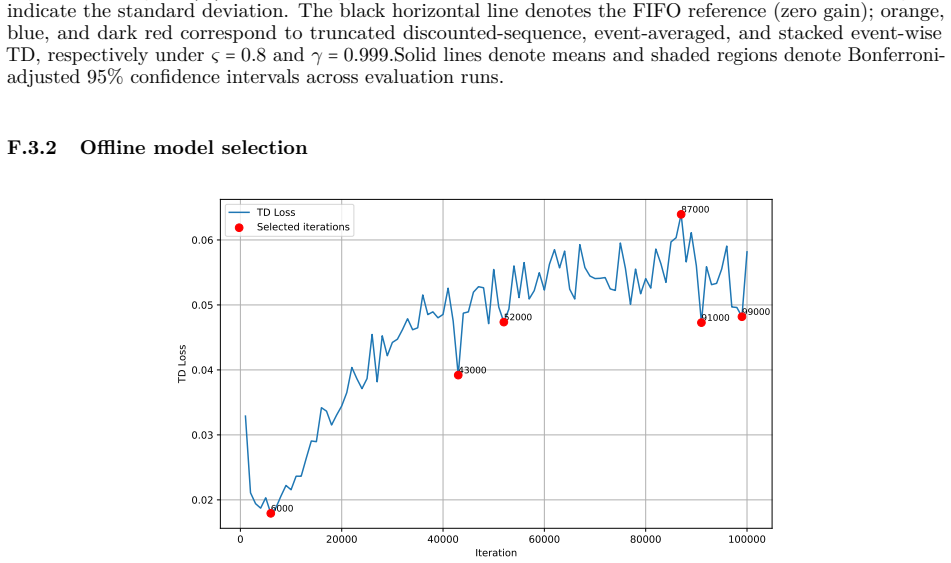
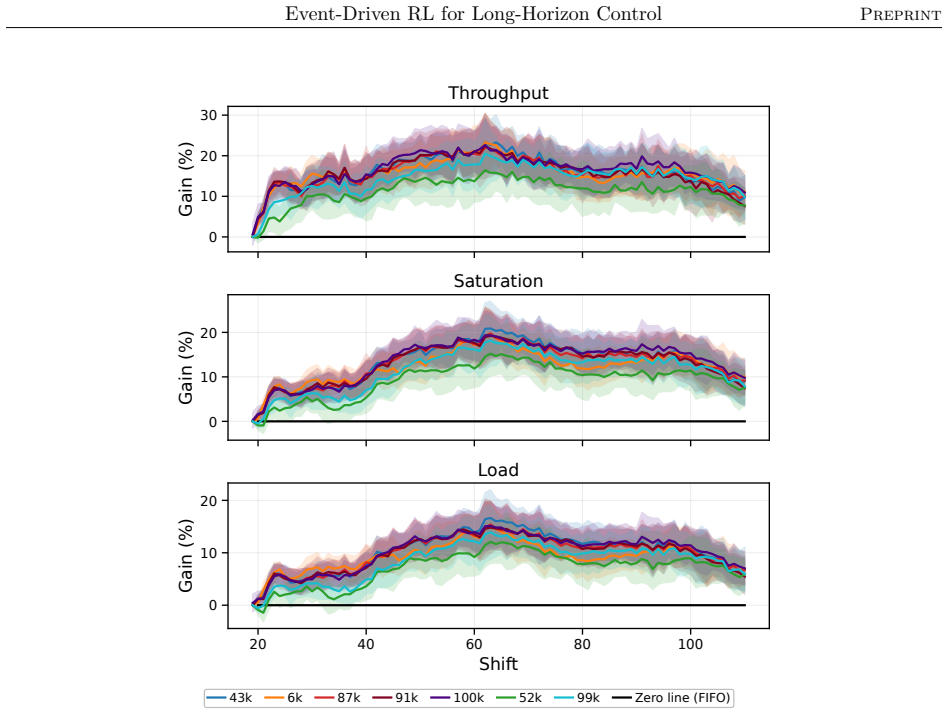
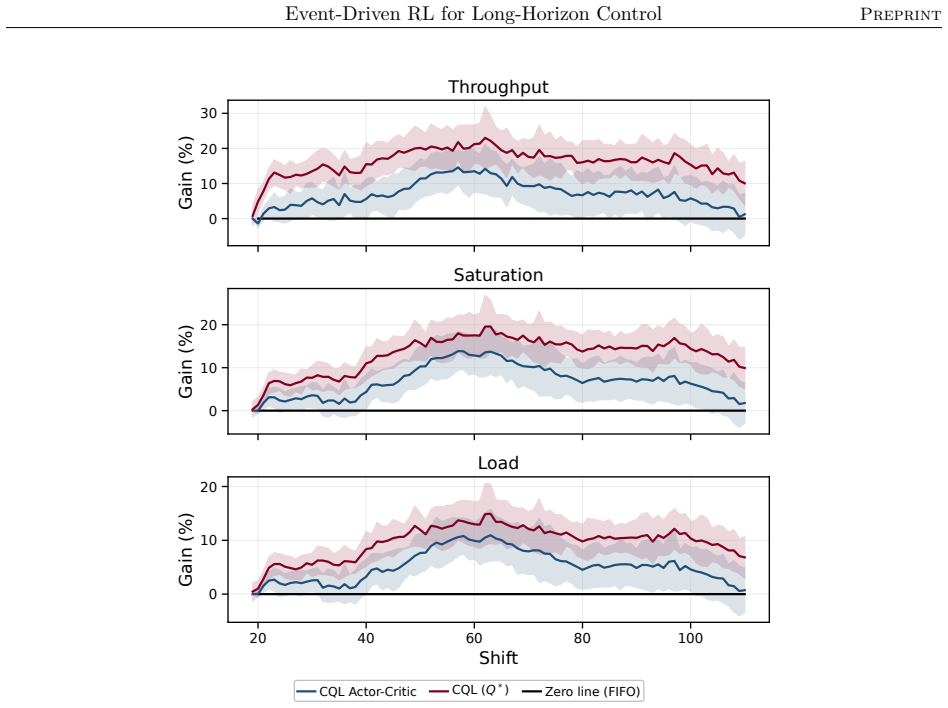
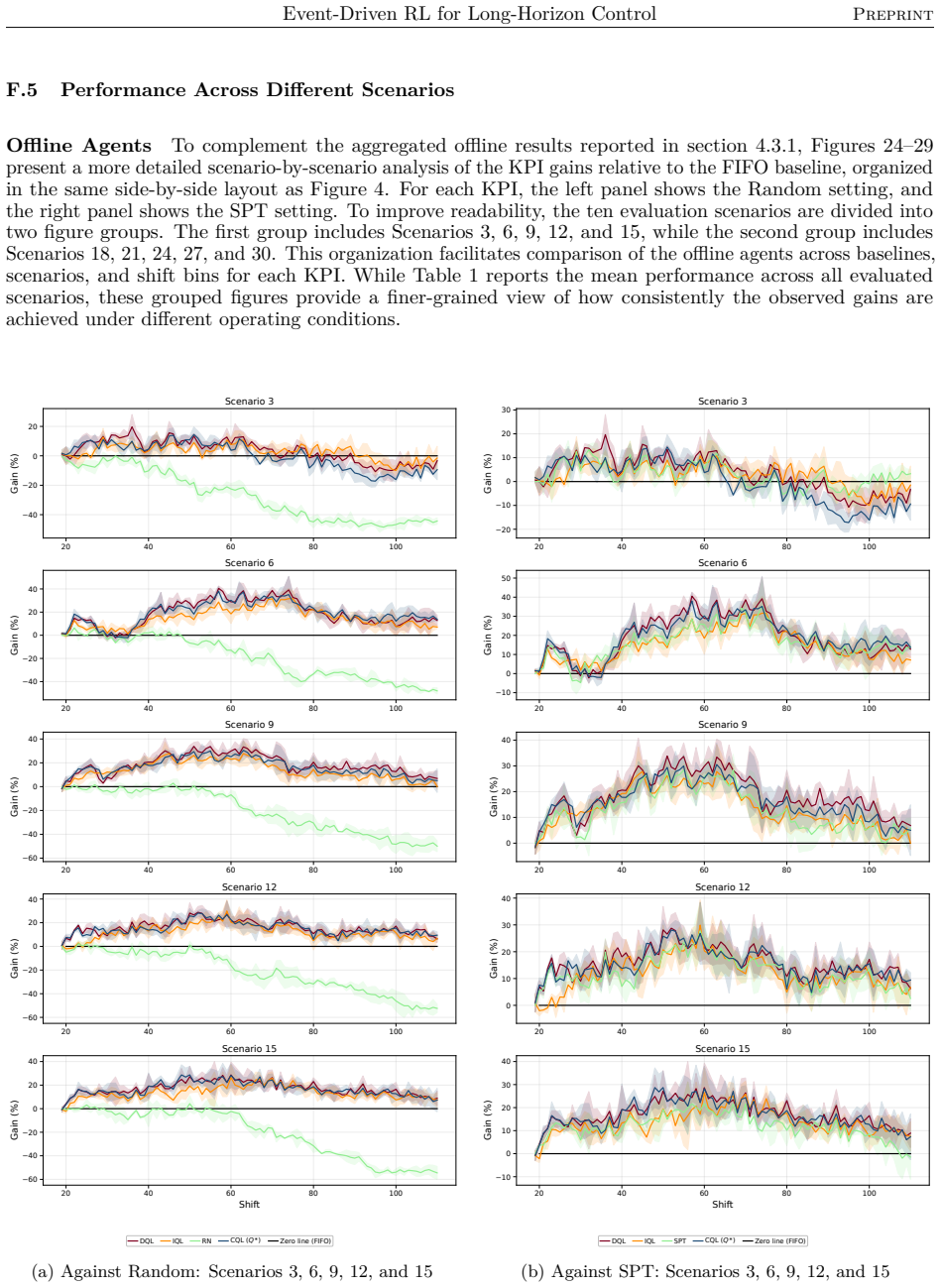
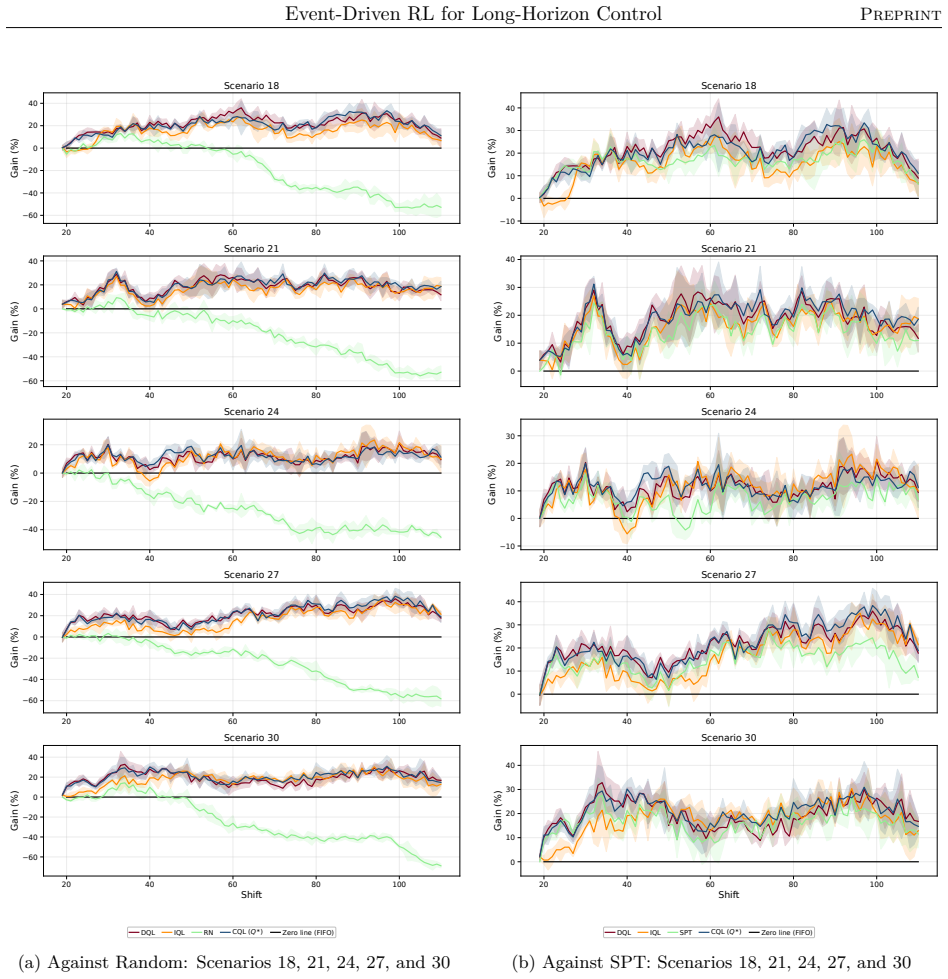
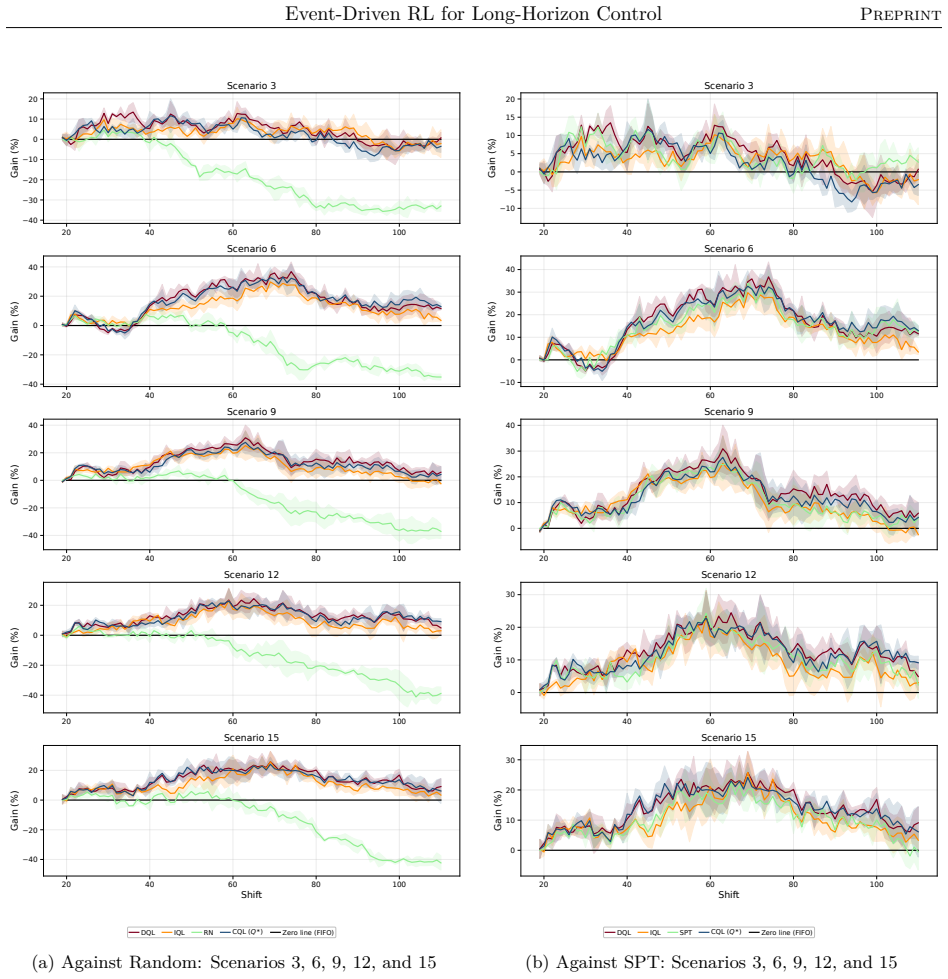
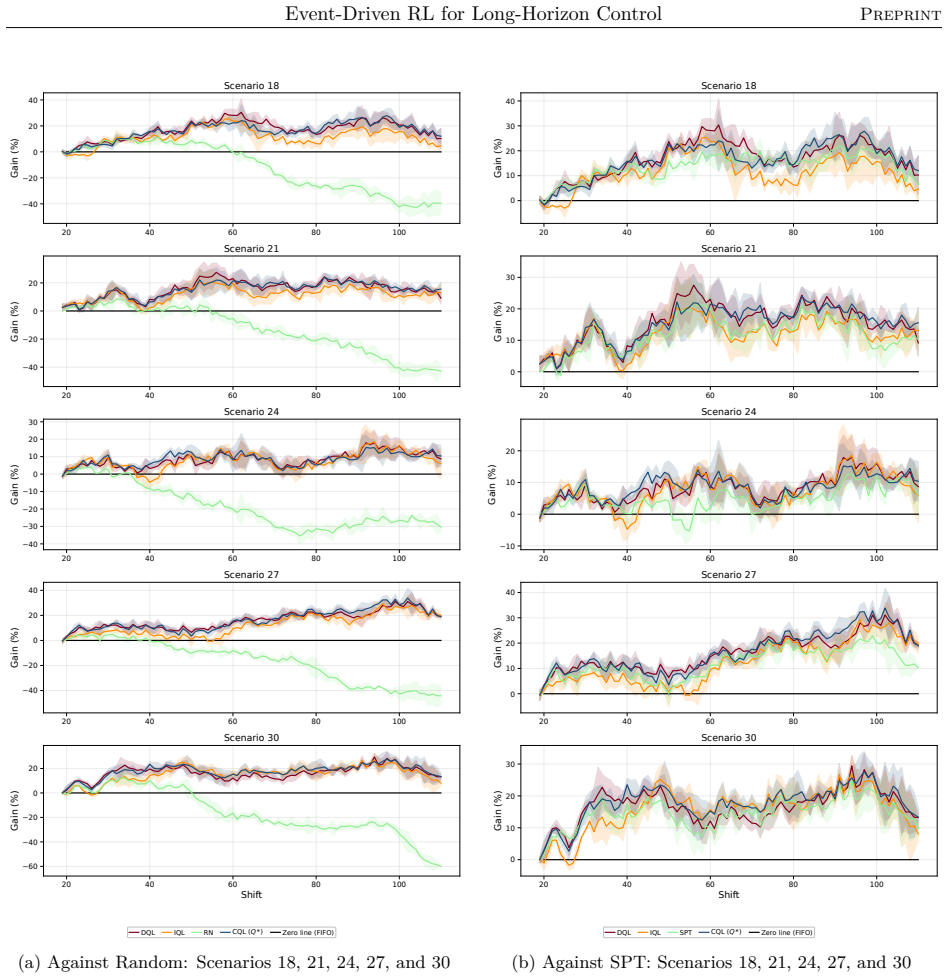
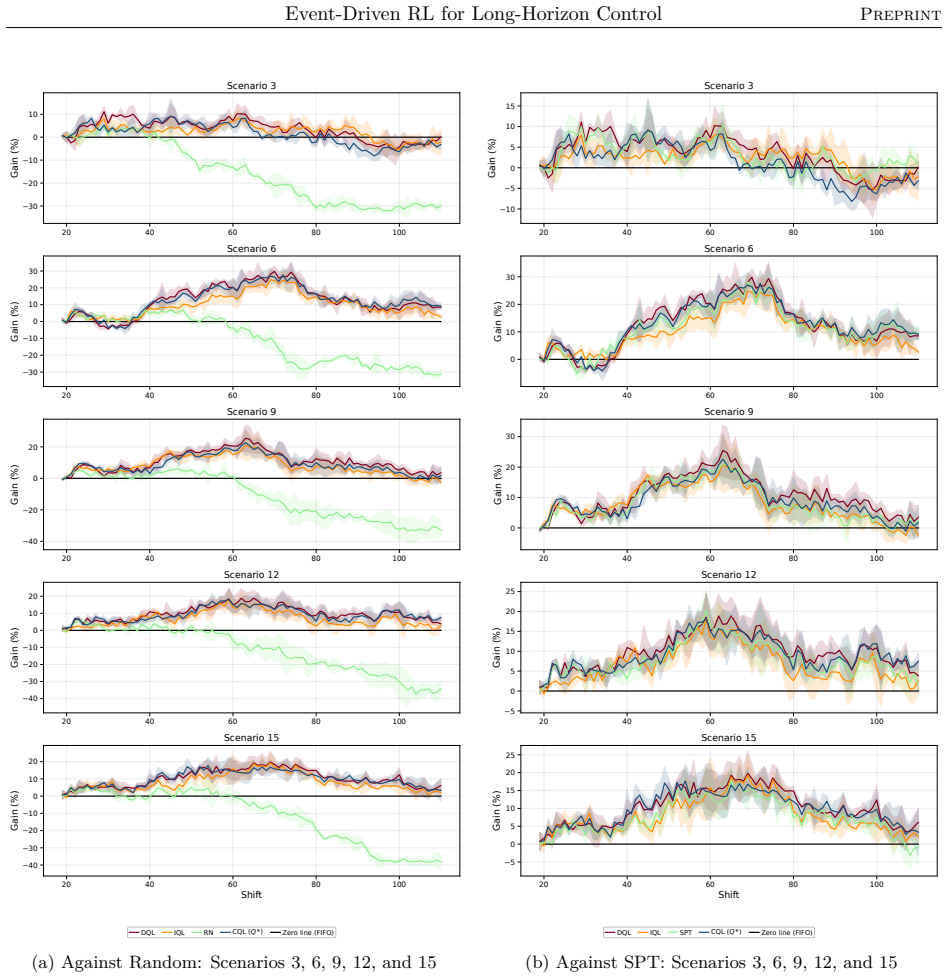
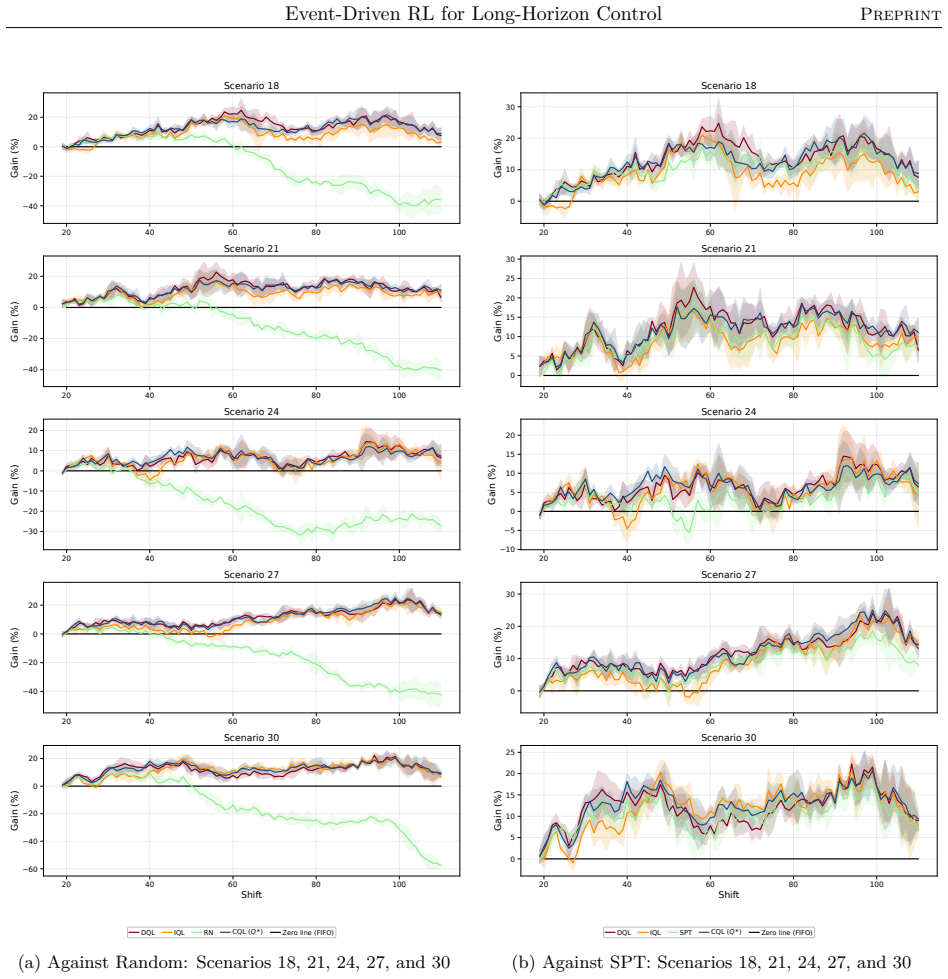
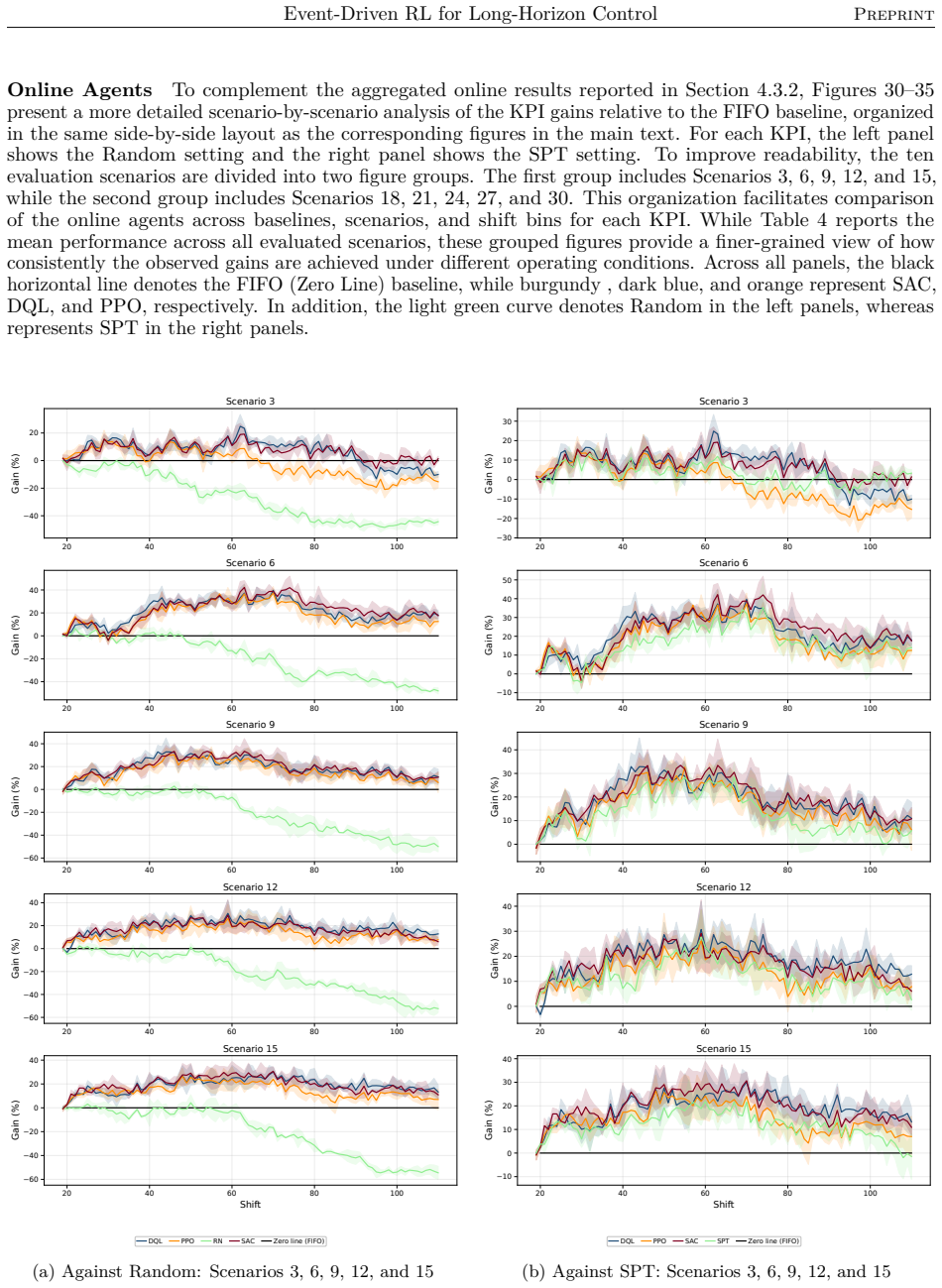
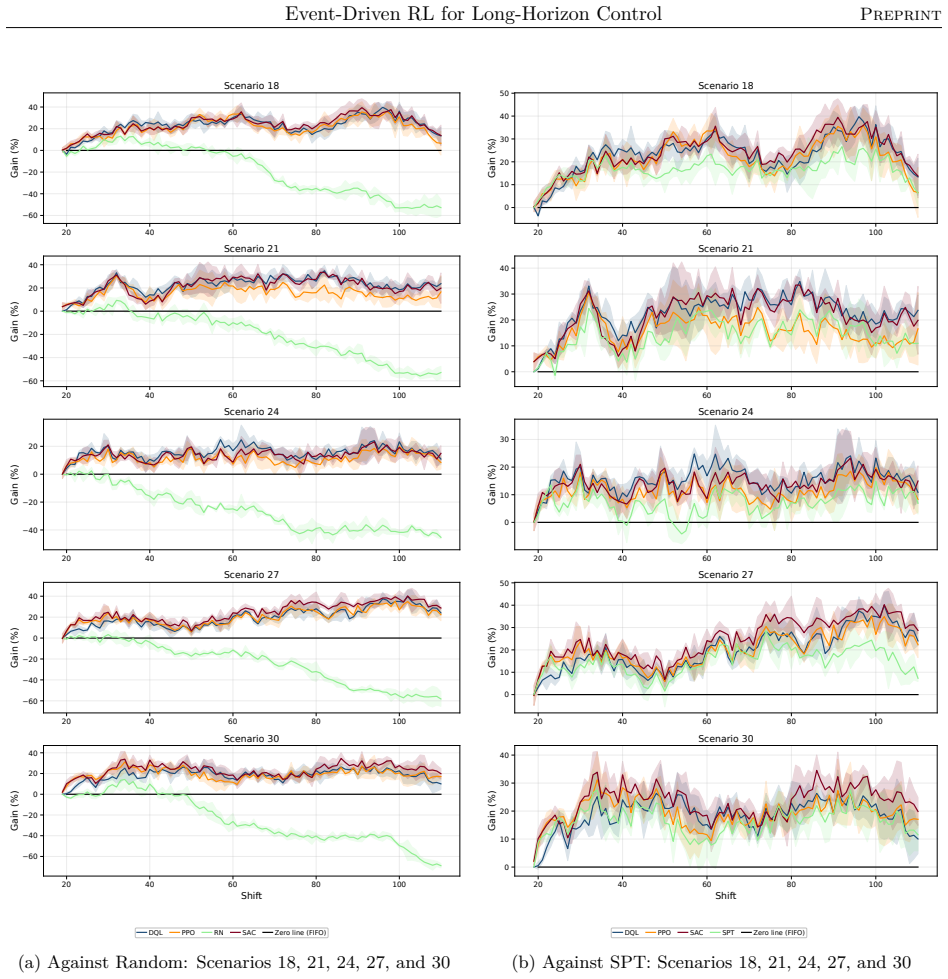
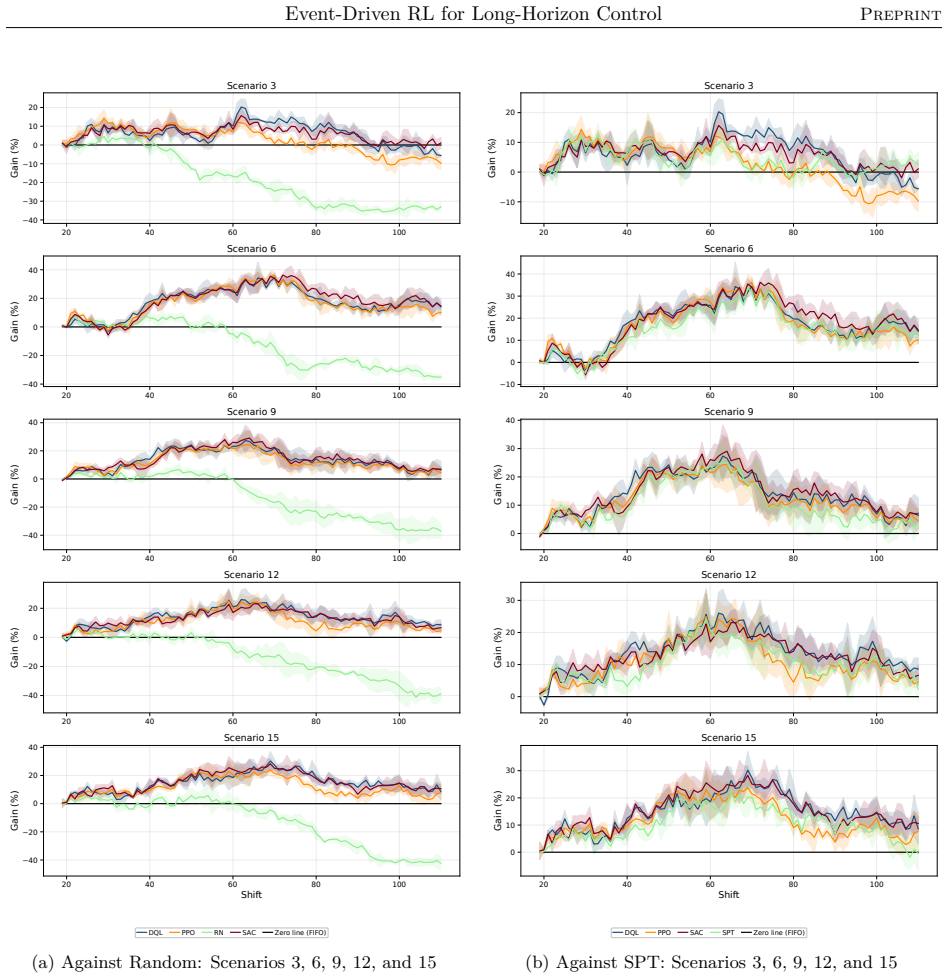
read the original abstract
Reinforcement learning promises to optimize sequential decisions in large-scale systems. Semiconductor manufacturing systems are stochastic and highly constrained environments where heterogeneous wafers traverse hundreds of processing steps across extensive equipment networks. These characteristics yield complex, high-dimensional decision problems with delayed feedback and long-horizon requirements, complicating production planning and control. We propose a deep reinforcement learning framework for multi-objective policy optimization at this scale. Specifically, we formulate control as a centralized-agent problem, where a core policy coordinates system-wide decisions, while system evolution is represented as an interconnected temporal process driven by discrete events. Accordingly, we develop a tailored event-driven temporal-difference formulation that remains general and can be integrated with various policy optimization methods under relevant training settings. We investigate several core model-free algorithms incorporated into this framework and evaluate their effectiveness using high-fidelity simulations of diverse, industry-real operating scenarios. Across extensive validation experiments, agents trained in both offline and online settings show significant and consistent gains in throughput and utilization. We further evaluate performance and generalization across training phases, clarifying the relative strengths of alternative reinforcement learning formulations and algorithms. Overall, the results support the scalability, generality, and transferability of the proposed framework for controlling event-driven complex adaptive systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a deep reinforcement learning framework for multi-objective policy optimization in semiconductor fabrication systems. It formulates the problem as a centralized-agent task with system evolution modeled as an interconnected temporal process driven by discrete events, develops a tailored event-driven temporal-difference formulation integrable with various model-free algorithms, and evaluates it via high-fidelity simulations of industry-real scenarios. Agents trained offline and online show significant consistent gains in throughput and utilization, with further analysis of performance and generalization across training phases.
Significance. If the simulation results hold under rigorous experimental controls, the work offers a scalable, general approach to applying RL in high-dimensional, stochastic, long-horizon manufacturing domains. The event-driven formulation and investigation of multiple algorithms under offline/online regimes are strengths that could support broader use in event-driven complex adaptive systems.
minor comments (2)
- The abstract refers to 'several core model-free algorithms' without naming them; the main text should explicitly list the algorithms (e.g., DQN, PPO) and their integration with the event-driven TD formulation.
- The evaluation description mentions 'extensive validation experiments' and 'significant and consistent gains'; the paper should include quantitative effect sizes, baseline descriptions, and statistical reporting (e.g., confidence intervals or p-values) to allow assessment of the internal validity of the gains.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation of minor revision. The assessment correctly captures the core contributions of the event-driven temporal-difference formulation and its evaluation under offline and online regimes. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper presents an event-driven RL framework for semiconductor fabrication control, formulates it as a centralized policy problem with a tailored temporal-difference method, and reports empirical performance gains from offline and online training in high-fidelity simulations. No load-bearing derivation reduces a claimed prediction or result to its own inputs by construction, no fitted parameters are relabeled as predictions, and no self-citation chain or uniqueness theorem is invoked to force the central outcomes. The evaluation rests on observed simulation metrics rather than any self-referential mathematical equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-fidelity simulations accurately capture real semiconductor fabrication dynamics and constraints.
Reference graph
Works this paper leans on
-
[1]
Springer Science & Business Media, 2012
Lars Mönch, John W Fowler, and Scott J Mason.Production planning and control for semiconductor wafer fabrication facilities: modeling, analysis, and systems, volume 52. Springer Science & Business Media, 2012. 1, 2, 4, 10, 24
2012
-
[2]
Reinforcement learning for adaptive order dispatching in the semiconductor industry.CIRP Annals, 67(1):511–514, 2018
Nicole Stricker, Andreas Kuhnle, Roland Sturm, and Simon Friess. Reinforcement learning for adaptive order dispatching in the semiconductor industry.CIRP Annals, 67(1):511–514, 2018. 2, 27, 29, 30
2018
-
[3]
Deep reinforcement learning for semiconductor production scheduling
Bernd Waschneck, André Reichstaller, Lenz Belzner, Thomas Altenmüller, Thomas Bauernhansl, Alexan- der Knapp, and Andreas Kyek. Deep reinforcement learning for semiconductor production scheduling. In2018 29th annual SEMI advanced semiconductor manufacturing conference (ASMC), pages 301–306. IEEE, 2018. 2, 3, 26, 30, 31
2018
-
[4]
Re- inforcement learning for online optimization of job-shop scheduling in a smart manufacturing factory
Tong Zhou, Haihua Zhu, Dunbing Tang, Changchun Liu, Qixiang Cai, Wei Shi, and Yong Gui. Re- inforcement learning for online optimization of job-shop scheduling in a smart manufacturing factory. Advances in Mechanical Engineering, 14(3):16878132221086120, 2022. 3, 27, 30, 31
2022
-
[5]
Semiconductor fab scheduling with self-supervised and reinforcement learning
Pierre Tassel, Benjamin Kovács, Martin Gebser, Konstantin Schekotihin, Patrick Stöckermann, and Georg Seidel. Semiconductor fab scheduling with self-supervised and reinforcement learning. In2023 Winter Simulation Conference (WSC), pages 1924–1935. IEEE, 2023. 2, 3
1924
-
[6]
MIT press, 2018
Richard S Sutton and Andrew G Barto.Reinforcement learning: An introduction. MIT press, 2018. 2, 7, 8, 9
2018
-
[7]
Deep learning.nature, 521(7553):436–444, 2015
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning.nature, 521(7553):436–444, 2015. 2
2015
-
[8]
Springer Nature, 2023
Christopher M Bishop and Hugh Bishop.Deep learning: Foundations and concepts. Springer Nature, 2023
2023
-
[9]
The expressive power of neural networks: A view from the width.Advances in neural information processing systems, 30, 2017
Zhou Lu, Hongming Pu, Feicheng Wang, Zhiqiang Hu, and Liwei Wang. The expressive power of neural networks: A view from the width.Advances in neural information processing systems, 30, 2017. 2
2017
-
[10]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015. 2
2015
-
[11]
Magnetic control of tokamak plasmas through deep reinforcement learning.Nature, 602(7897):414–419, 2022
Jonas Degrave, Federico Felici, Jonas Buchli, Michael Neunert, Brendan Tracey, Francesco Carpanese, Timo Ewalds, Roland Hafner, Abbas Abdolmaleki, Diego de Las Casas, et al. Magnetic control of tokamak plasmas through deep reinforcement learning.Nature, 602(7897):414–419, 2022
2022
-
[12]
A graph placement methodology for fast chip design.Nature, 594(7862):207–212, 2021
Azalia Mirhoseini, Anna Goldie, Mustafa Yazgan, Joe Wenjie Jiang, Ebrahim Songhori, Shen Wang, Young-Joon Lee, Eric Johnson, Omkar Pathak, Azade Nova, et al. A graph placement methodology for fast chip design.Nature, 594(7862):207–212, 2021
2021
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Deep reinforcement learning for machine scheduling: Methodology, the state-of-the-art, and future directions.Computers & Industrial Engineering, 200:110856, 2025
Maziyar Khadivi, Todd Charter, Marjan Yaghoubi, Masoud Jalayer, Maryam Ahang, Ardeshir Sho- jaeinasab, and Homayoun Najjaran. Deep reinforcement learning for machine scheduling: Methodology, the state-of-the-art, and future directions.Computers & Industrial Engineering, 200:110856, 2025. 2, 3
2025
-
[15]
Autonomous order dispatching in the semiconductor industry using reinforcement learning.Procedia Cirp, 79:391–396, 2019
Andreas Kuhnle, Nicole Röhrig, and Gisela Lanza. Autonomous order dispatching in the semiconductor industry using reinforcement learning.Procedia Cirp, 79:391–396, 2019. 2, 3, 27, 29, 30, 31 19 Event-Driven RL for Long-Horizon ControlPreprint
2019
-
[16]
Active inference meeting energy-efficient control of parallel and identical machines
Yavar Taheri Yeganeh, Mohsen Jafari, and Andrea Matta. Active inference meeting energy-efficient control of parallel and identical machines. InInternational Conference on Machine Learning, Optimization, and Data Science, pages 479–493. Springer, 2024. 2, 6
2024
-
[17]
Martin Klissarov, Akhil Bagaria, Ziyan Luo, George Konidaris, Doina Precup, and Marlos C Machado. Discovering temporal structure: An overview of hierarchical reinforcement learning.arXiv preprint arXiv:2506.14045, 2025. 2, 3
-
[18]
Patrick Stöckermann, Henning Südfeld, Alessandro Immordino, Thomas Altenmüller, Marc Wegmann, Martin Gebser, Konstantin Schekotihin, Georg Seidel, Chew Wye Chan, and Fei Fei Zhang. Scalability of reinforcement learning methods for dispatching in semiconductor frontend fabs: a comparison of open-source models with real industry datasets.The International J...
2025
-
[19]
Supporting fab operations using multi-agent reinforcement learning
Ishaan Sood, Abhinav Kaushik, Tom Bulgerin, Prashant Kumar, Subham Rath, Abdelhak Khemiri, Johnny Chang, Sam Hsu, and Jeroen Bédorf. Supporting fab operations using multi-agent reinforcement learning. In2024 35th Annual SEMI Advanced Semiconductor Manufacturing Conference (ASMC), pages 1–6. IEEE, 2024. 2, 3
2024
-
[20]
Agentic large language models, a survey.Journal of Artificial Intelligence Research, 84, 2025
Aske Plaat, Max van Duijn, Niki Van Stein, Mike Preuss, Peter van der Putten, and Kees Joost Batenburg. Agentic large language models, a survey.Journal of Artificial Intelligence Research, 84, 2025. 2
2025
-
[21]
Revisiting bellman errors for offline model selection
Joshua P Zitovsky, Daniel De Marchi, Rishabh Agarwal, and Michael Rene Kosorok. Revisiting bellman errors for offline model selection. InInternational conference on machine learning, pages 43369–43406. PMLR, 2023. 2, 8, 17
2023
-
[22]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018. 8, 9
2018
-
[23]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. arXiv preprint arXiv:2110.06169, 2021. 2, 8, 9, 17
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
A reinforcement learning approach for improved photolithography schedules
Tao Zhang, Kamil Erkan Kabak, Cathal Heavey, and Oliver Rose. A reinforcement learning approach for improved photolithography schedules. In2023 Winter Simulation Conference (WSC), pages 2136–2147. IEEE, 2023. 3
2023
-
[25]
Deep reinforcement learning based scheduling within production plan in semiconductor fabrication.Expert Systems with Applications, 191:116222, 2022
Young Hoon Lee and Seunghoon Lee. Deep reinforcement learning based scheduling within production plan in semiconductor fabrication.Expert Systems with Applications, 191:116222, 2022. 3, 27, 30
2022
-
[26]
Simulation and deep reinforcement learning for adaptive dispatching in semiconductor manufacturing systems.Journal of Intelligent Manufacturing, 34(3):1311–1324, 2023
Ahmed H Sakr, Ayman Aboelhassan, Soumaya Yacout, and Samuel Bassetto. Simulation and deep reinforcement learning for adaptive dispatching in semiconductor manufacturing systems.Journal of Intelligent Manufacturing, 34(3):1311–1324, 2023. 6, 27, 30, 31
2023
-
[27]
Dynamic scheduling method for job-shop manufacturing systems by deep reinforcement learning with proximal policy optimization
Ming Zhang, Yang Lu, Youxi Hu, Nasser Amaitik, and Yuchun Xu. Dynamic scheduling method for job-shop manufacturing systems by deep reinforcement learning with proximal policy optimization. sustainability, 14(9):5177, 2022. 3, 30, 31
2022
-
[28]
A novel double q-learning with invalid action masking for semiconductor ion implantation scheduling problem.Computers & Industrial Engineering, page 111620, 2025
Hung-Kai Wang, Ting-Yun Yang, and Yan-Cheng Lin. A novel double q-learning with invalid action masking for semiconductor ion implantation scheduling problem.Computers & Industrial Engineering, page 111620, 2025. 3
2025
-
[29]
Distributed scheduling method for smart shop floor based on qmix
Jianmin Xing, Yumin Ma, Jingwen Cai, Jiaxuan Shi, and Juan Liu. Distributed scheduling method for smart shop floor based on qmix. In2023 IEEE 19th International Conference on Automation Science and Engineering (CASE), pages 1–6. IEEE, 2023. 3, 30, 31
2023
-
[30]
Juan Liu, Fei Qiao, Minjie Zou, Jonas Zinn, Yumin Ma, and Birgit Vogel-Heuser. Dynamic scheduling for semiconductor manufacturing systems with uncertainties using convolutional neural networks and reinforcement learning.Complex & Intelligent Systems, 8(6):4641–4662, 2022. 3, 26, 27
2022
-
[31]
Deep learning enabling digital twin applications in production scheduling: Case of flexible job shop manufac- turing environment
Amir Ghasemi, Yavar Taheri Yeganeh, Andrea Matta, Kamil Erkan Kabak, and Cathal Heavey. Deep learning enabling digital twin applications in production scheduling: Case of flexible job shop manufac- turing environment. In2023 Winter Simulation Conference (WSC), pages 2148–2159. IEEE, 2023. 3, 4
2023
-
[32]
A compre- hensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S Yu. A compre- hensive survey on graph neural networks.IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020. 3 20 Event-Driven RL for Long-Horizon ControlPreprint
2020
-
[33]
Graph representation and embedding for semiconductor manufacturing fab states
Benedikt Schulz, Christoph Jacobi, Andrej Gisbrecht, Angelidis Evangelos, Chew Wye Chan, and Boon Ping Gan. Graph representation and embedding for semiconductor manufacturing fab states. In 2022 Winter Simulation Conference (WSC), pages 3382–3393. IEEE, 2022. 3
2022
-
[34]
Flexible job shop scheduling problem using graph neural networks and reinforcement learning.Computers & Operations Research, 182:107139, 2025
Xi Liu, Xin Chen, Vincent Chau, Jedrzej Musial, and Jacek Blazewicz. Flexible job shop scheduling problem using graph neural networks and reinforcement learning.Computers & Operations Research, 182:107139, 2025. 3
2025
-
[35]
Learning to dispatch for job shop scheduling via deep reinforcement learning.Advances in neural information processing systems, 33:1621–1632, 2020
Cong Zhang, Wen Song, Zhiguang Cao, Jie Zhang, Puay Siew Tan, and Xu Chi. Learning to dispatch for job shop scheduling via deep reinforcement learning.Advances in neural information processing systems, 33:1621–1632, 2020. 3
2020
-
[36]
Deep reinforcement learning for dynamic flexible job shop scheduling with random job arrival.Processes, 10(4):760, 2022
Jingru Chang, Dong Yu, Yi Hu, Wuwei He, and Haoyu Yu. Deep reinforcement learning for dynamic flexible job shop scheduling with random job arrival.Processes, 10(4):760, 2022. 3, 30, 31
2022
-
[37]
A fuzzy hierarchical reinforce- ment learning based scheduling method for semiconductor wafer manufacturing systems.Journal of Manufacturing Systems, 61:239–248, 2021
Junliang Wang, Pengjie Gao, Peng Zheng, Jie Zhang, and WH Ip. A fuzzy hierarchical reinforce- ment learning based scheduling method for semiconductor wafer manufacturing systems.Journal of Manufacturing Systems, 61:239–248, 2021
2021
-
[38]
Deep reinforcement learning for queue-time management in semiconductor manufacturing
Harel Yedidsion, Prafulla Dawadi, David Norman, and Emrah Zarifoglu. Deep reinforcement learning for queue-time management in semiconductor manufacturing. In2022 Winter Simulation Conference (WSC), pages 3275–3284. IEEE, 2022. 3
2022
-
[39]
Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning
Shu Luo. Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning. Applied Soft Computing, 91:106208, 2020. 3, 27, 30, 31
2020
-
[40]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 3, 7, 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
An adaptive multi-objective multi-task scheduling method by hierarchical deep reinforcement learning
Jianxiong Zhang, Bing Guo, Xuefeng Ding, Dasha Hu, Jun Tang, Ke Du, Chao Tang, and Yuming Jiang. An adaptive multi-objective multi-task scheduling method by hierarchical deep reinforcement learning. Applied Soft Computing, 154:111342, 2024. 3, 30, 31
2024
-
[42]
Explainable ai for reinforcement learning based dynamic scheduling solutions in semiconductor manufacturing: A
Alessandro Immordino, Patrick Stöckermann, Niels Hayen, Thomas Altenmüller, Gian Antonio Susto, Martin Gebser, Konstantin Schekotihin, and Georg Seidel. Explainable ai for reinforcement learning based dynamic scheduling solutions in semiconductor manufacturing: A. immordino et al.Journal of Intelligent Manufacturing, pages 1–17, 2025. 3, 30, 31
2025
-
[43]
Dispatching in real frontend fabs with industrial grade discrete-event simulations by deep reinforcement learning with evolution strategies
Patrick Stöckermann, Alessandro Immordino, Thomas Altenmüller, Georg Seidel, Martin Gebser, Pierre Tassel, Chew Wye Chan, and Feifei Zhang. Dispatching in real frontend fabs with industrial grade discrete-event simulations by deep reinforcement learning with evolution strategies. In2023 Winter Simulation Conference (WSC), pages 3047–3058. IEEE, 2023. 3
2023
-
[44]
Yavar Taheri Yeganeh, Mohsen Jafari, and Andrea Matta. Deep active inference agents for delayed and long-horizon environments.arXiv preprint arXiv:2505.19867, 2025. 3, 6, 17, 18
-
[45]
Rudder: Return decomposition for delayed rewards.Advances in Neural Information Processing Systems, 32, 2019
Jose A Arjona-Medina, Michael Gillhofer, Michael Widrich, Thomas Unterthiner, Johannes Brandstetter, and Sepp Hochreiter. Rudder: Return decomposition for delayed rewards.Advances in Neural Information Processing Systems, 32, 2019. 3, 7, 18
2019
-
[46]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
AshvinNair, AbhishekGupta, MurtazaDalal, andSergeyLevine. Awac: Acceleratingonlinereinforcement learning with offline datasets.arXiv preprint arXiv:2006.09359, 2020. 3, 8, 9
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[47]
Conservative q-learning for offline reinforcement learning.Advances in neural information processing systems, 33:1179–1191, 2020
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning.Advances in neural information processing systems, 33:1179–1191, 2020. 3, 8, 9
2020
-
[48]
Temporal abstraction in reinforcement learning with the successor representation.Journal of machine learning research, 24(80): 1–69, 2023
Marlos C Machado, Andre Barreto, Doina Precup, and Michael Bowling. Temporal abstraction in reinforcement learning with the successor representation.Journal of machine learning research, 24(80): 1–69, 2023. 4
2023
-
[49]
Hierarchical decision-making for qualification management in wafer fabs: a simulation study.IEEE Transactions on Automation Science and Engineering, 20(1):320–333, 2022
Denny Kopp and Lars Mönch. Hierarchical decision-making for qualification management in wafer fabs: a simulation study.IEEE Transactions on Automation Science and Engineering, 20(1):320–333, 2022. 4
2022
-
[50]
Average-reward learning and planning with options.Advances in Neural Information Processing Systems, 34:22758–22769, 2021
Yi Wan, Abhishek Naik, and Rich Sutton. Average-reward learning and planning with options.Advances in Neural Information Processing Systems, 34:22758–22769, 2021. 4
2021
-
[51]
Mean field multi-agent reinforcement learning
Yaodong Yang, Rui Luo, Minne Li, Ming Zhou, Weinan Zhang, and Jun Wang. Mean field multi-agent reinforcement learning. InInternational conference on machine learning, pages 5571–5580. PMLR, 2018. 5 21 Event-Driven RL for Long-Horizon ControlPreprint
2018
-
[52]
Digital twins paradigm: A systematic review from the reinforcement learning perspective.ACM Computing Surveys, 58(7):1–33, 2026
Shahmir Khan Mohammed, Shakti Singh, Rabeb Mizouni, Hadi Otrok, and Ernesto Damiani. Digital twins paradigm: A systematic review from the reinforcement learning perspective.ACM Computing Surveys, 58(7):1–33, 2026. 5
2026
-
[53]
Hsuan-An Kuo, Tzu-Yen Hong, and Chen-Fu Chien. A deep reinforcement learning based digital twin framework for resilient production planning under demand uncertainty and an empirical study in semiconductor wafer fabrication.Computers & Industrial Engineering, page 111389, 2025. 5
2025
-
[54]
Comprehensive overview of reward engineering and shaping in advancing reinforcement learning applications.IEEE Access, 12: 175473–175500, 2024
Sinan Ibrahim, Mostafa Mostafa, Ali Jnadi, Hadi Salloum, and Pavel Osinenko. Comprehensive overview of reward engineering and shaping in advancing reinforcement learning applications.IEEE Access, 12: 175473–175500, 2024. 6, 11, 17
2024
-
[55]
Rainbow: Combining improvements in deep reinforcement learning
Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: Combining improvements in deep reinforcement learning. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018. 7
2018
-
[56]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018. 7, 10
2018
-
[57]
Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2):181–211, 1999
Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2):181–211, 1999. 8
1999
-
[58]
Deep Reinforcement Learning and the Deadly Triad
Hado Van Hasselt, Yotam Doron, Florian Strub, Matteo Hessel, Nicolas Sonnerat, and Joseph Modayil. Deep reinforcement learning and the deadly triad.arXiv preprint arXiv:1812.02648, 2018. 8
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[59]
Deep reinforcement learning with double q-learning
Hado Van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. InProceedings of the AAAI conference on artificial intelligence, volume 30, 2016. 8
2016
-
[60]
Soft actor-critic for discrete action settings.arXiv preprint arXiv:1910.07207,
Petros Christodoulou. Soft actor-critic for discrete action settings.arXiv preprint arXiv:1910.07207,
-
[61]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219, 2020. 9
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[62]
Boltzmann exploration done right.Advances in neural information processing systems, 30, 2017
Nicolò Cesa-Bianchi, Claudio Gentile, Gábor Lugosi, and Gergely Neu. Boltzmann exploration done right.Advances in neural information processing systems, 30, 2017. 9
2017
-
[63]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015. 9
2015
-
[64]
Asynchronous methods for deep reinforcement learning
Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In International conference on machine learning, pages 1928–1937. PmLR, 2016. 10
1928
-
[65]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438, 2015. 10
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[66]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
General agents contain world models, 2025
Jonathan Richens, David Abel, Alexis Bellot, and Tom Everitt. General agents contain world models. arXiv preprint arXiv:2506.01622, 2025. 10
-
[68]
Manufacturing cycle time reduction using balance control in the semiconductor fabrication line.Production Planning & Control, 13(6):529–540, 2002
Young Hoon Lee and Taeheon Kim. Manufacturing cycle time reduction using balance control in the semiconductor fabrication line.Production Planning & Control, 13(6):529–540, 2002. 11
2002
-
[69]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models. arXiv preprint arXiv:2509.24527, 2025. 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
A customizable simulator for artificial intelligence research to schedule semiconductor fabs
Benjamin Kovács, Pierre Tassel, Ramsha Ali, Mohammed El-Kholany, Martin Gebser, and Georg Seidel. A customizable simulator for artificial intelligence research to schedule semiconductor fabs. In2022 33rd Annual SEMI Advanced Semiconductor Manufacturing Conference (ASMC), pages 1–6. IEEE, 2022. 26, 27, 30, 31
2022
-
[71]
Crc press, 2017
Pascal Dennis.Lean Production simplified: A plain-language guide to the world’s most powerful production system. Crc press, 2017. 26
2017
-
[72]
McGraw-Hill Education New York, 2014
William J Stevenson, Mehran Hojati, and James Cao.Operations management. McGraw-Hill Education New York, 2014. 27 22 Event-Driven RL for Long-Horizon ControlPreprint
2014
-
[73]
Prentice Hall Upper Saddle River, NJ, 1998
JR Tony Arnold, Stephen N Chapman, Lloyd M Clive, and Ann K Gatewood.Introduction to materials management. Prentice Hall Upper Saddle River, NJ, 1998. 27
1998
-
[74]
Operations management: Sustainability and supply chain management
Jay Heizer, Barry Render, Charles Lee Munson, and Paul Griffin. Operations management: Sustainability and supply chain management. 2020. 27
2020
-
[75]
McGraw-Hill, Inc., 2004
Peter Van Zant.Microchip fabrication. McGraw-Hill, Inc., 2004. 27
2004
-
[76]
Simulation based multi-objective fab scheduling by using reinforcement learning
Won-Jun Lee, Byung-Hee Kim, Keyhoon Ko, and Hayong Shin. Simulation based multi-objective fab scheduling by using reinforcement learning. In2019 Winter Simulation Conference (WSC), pages 2236–2247. IEEE, 2019. 27, 30
2019
-
[77]
Waveland Press, 2015
Steven Nahmias and Tava Lennon Olsen.Production and operations analysis. Waveland Press, 2015. 27
2015
-
[78]
Manufacturing planning and control for supply chain management: the cpim reference.(No Title), 2018
F Robert Jacobs, William L Berry, D Clay Whybark, and Thomas E Vollmann. Manufacturing planning and control for supply chain management: the cpim reference.(No Title), 2018. 27
2018
-
[79]
Deep reinforce- ment learning approach for a dynamic flexible job shop problem with sequence dependent setup times
Binxiao Yan, Xinbao Liu, Shaojun Lu, Chaoming Hu, Xubiao Wang, and Zhiping Zhou. Deep reinforce- ment learning approach for a dynamic flexible job shop problem with sequence dependent setup times. Computers & Industrial Engineering, page 111310, 2025. 30, 31
2025
-
[80]
Tzu-Yen Hong and Kuan-Han Li. Large language model driven adaptive deep reinforcement learning with dynamic definition refinement for flexible job shop scheduling problem.Applied Soft Computing, page 114253, 2025. 30, 31
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.