AuRA: Internalizing Audio Understanding into LLMs as LoRA
Pith reviewed 2026-06-27 14:16 UTC · model grok-4.3
The pith
AuRA internalizes audio understanding into LLMs by distilling hidden states from an ASR encoder into LoRA-adapted models via a lightweight embedding layer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
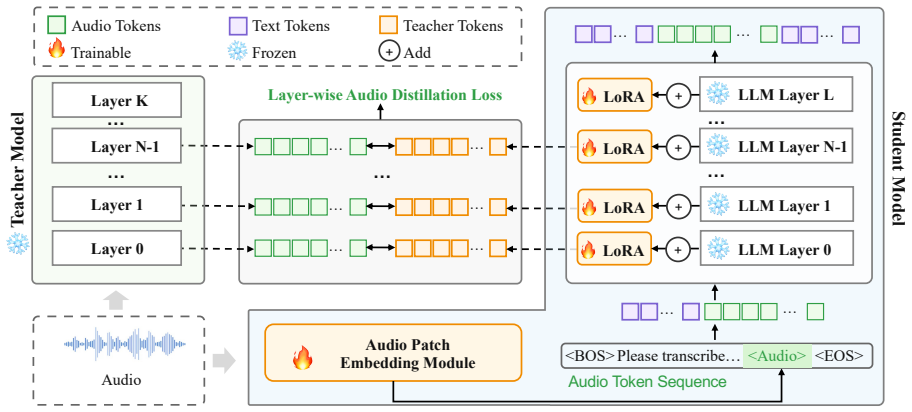
AuRA feeds the same speech input to an ASR encoder (teacher) and a LoRA-adapted LLM (student) through a lightweight audio embedding layer and applies layer-wise distillation to align the student's hidden states with the teacher's representations, thereby internalizing speech representations into lightweight LLM-side adaptations. This produces tighter speech-language joint modeling and efficient parallel end-to-end inference while reusing pretrained components instead of requiring large-scale multimodal training.
What carries the argument
Layer-wise distillation of hidden states from an ASR encoder to a LoRA-adapted LLM through a lightweight audio embedding layer, which aligns representations to internalize audio capability.
If this is right
- AuRA enables tighter speech-language joint modeling than cascaded or serial bridge methods.
- Efficient parallel end-to-end inference becomes possible without sequential processing steps.
- Pretrained speech and language models can be reused rather than training large multimodal models from scratch.
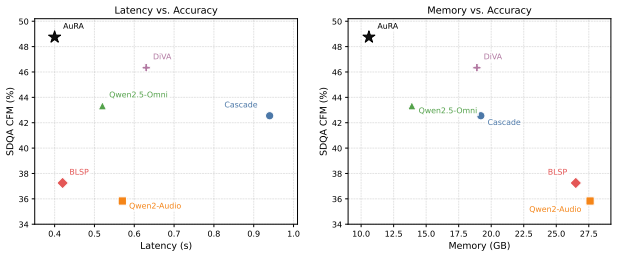
- The method outperforms cascaded systems, speech-to-LLM baselines, and large-scale multimodal models on multiple benchmarks in both accuracy and speed.
Where Pith is reading between the lines
- Systems that currently chain separate ASR and LLM components could potentially drop the ASR stage at inference time.
- The same distillation pattern might apply to other input modalities if suitable teacher encoders exist.
- Real-time voice applications could see reduced latency if the internalized representations support direct end-to-end processing.
Load-bearing premise
Layer-wise distillation through the lightweight audio embedding layer will successfully transfer useful speech representations into the LLM without representation mismatch or the need for large-scale additional training.
What would settle it
If AuRA fails to outperform cascaded ASR-LLM pipelines or other adaptation baselines on the reported speech-language benchmarks while keeping training costs low, the central claim would not hold.
Figures

read the original abstract
Recent efforts to extend large language models (LLMs) to speech inputs typically rely on cascaded ASR-LLM pipelines, end-to-end speech-language models, or bridge/distillation-based adaptation. While these routes respectively reuse strong pretrained components, enable native speech-language interaction, or offer lightweight adaptation, they often suffer from transcript-interface latency, costly multimodal training, or sequential speech-language coupling. To address these limitations, we present AuRA, a method that distills audio encoding capability into the LLM. Specifically, AuRA feeds the same speech input to an ASR encoder (as a teacher) and a LoRA-adapted LLM (as a student) through a lightweight audio embedding layer, and uses layer-wise distillation to align the student's hidden states with corresponding teacher representations, thereby internalizing speech representations into lightweight LLM-side adaptations. Compared with cascaded and serial bridge methods, AuRA enables tighter speech-language joint modeling and efficient parallel end-to-end inference, while also reusing pretrained speech and language models rather than requiring large-scale multimodal training. On multiple speech-language benchmarks, AuRA consistently outperforms cascaded systems, speech-to-LLM adaptation baselines, and large-scale speech-language and multimodal models in both effectiveness and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AuRA, a method for internalizing audio understanding into LLMs using LoRA adaptations. It involves feeding speech input to an ASR encoder as teacher and a LoRA-adapted LLM as student through a lightweight audio embedding layer, employing layer-wise distillation to align hidden states. The method claims to enable tighter speech-language joint modeling and efficient inference while outperforming cascaded systems, adaptation baselines, and large multimodal models on speech-language benchmarks in both effectiveness and efficiency.
Significance. If the distillation approach successfully bridges the representation gap without requiring large-scale multimodal training, AuRA could offer a practical and efficient way to extend LLMs to speech inputs, improving upon existing methods by reusing pretrained components and enabling parallel end-to-end inference.
major comments (2)
- [Abstract] The abstract asserts that 'AuRA consistently outperforms cascaded systems, speech-to-LLM adaptation baselines, and large-scale speech-language and multimodal models' but provides no quantitative metrics, specific benchmarks, baseline descriptions, or experimental setup details. This omission is load-bearing as it prevents any assessment of the central performance claim.
- The method's success hinges on the untested assumption that layer-wise hidden-state distillation from the ASR encoder will align effectively with the LLM's representations via the lightweight adapter, without suffering from representation mismatch. No evidence or analysis supporting this alignment is provided in the manuscript.
Simulated Author's Rebuttal
We thank the referee for their thoughtful feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts that 'AuRA consistently outperforms cascaded systems, speech-to-LLM adaptation baselines, and large-scale speech-language and multimodal models' but provides no quantitative metrics, specific benchmarks, baseline descriptions, or experimental setup details. This omission is load-bearing as it prevents any assessment of the central performance claim.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support. In the revised manuscript we will add key performance metrics (e.g., accuracy or WER improvements on the primary speech-language benchmarks), name the main baselines, and briefly note the evaluation protocol so that the central claim can be assessed directly from the abstract. revision: yes
-
Referee: The method's success hinges on the untested assumption that layer-wise hidden-state distillation from the ASR encoder will align effectively with the LLM's representations via the lightweight adapter, without suffering from representation mismatch. No evidence or analysis supporting this alignment is provided in the manuscript.
Authors: The manuscript reports consistent downstream gains from the layer-wise distillation objective relative to ablated variants that omit it; these results provide indirect empirical support for effective alignment. We nevertheless acknowledge that direct evidence (e.g., cosine similarity trends across layers or qualitative hidden-state visualizations) is currently limited. We will add such analysis in the revision. revision: yes
Circularity Check
No circularity: method is empirical description without self-referential derivations
full rationale
The provided abstract and description outline a distillation procedure (ASR teacher to LoRA-adapted LLM student via lightweight audio embedding and layer-wise hidden-state alignment) but contain no equations, parameter-fitting steps presented as predictions, self-citations used as load-bearing uniqueness proofs, or ansatzes smuggled through prior work. The central claim is an empirical performance comparison on benchmarks, not a closed derivation that reduces to its inputs by construction. This is the expected non-finding for a methods paper without mathematical claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP)
Salm: Speech-augmented language model with in- context learning for speech recognition and transla- tion. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP). IEEE. Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, and 1 others
2024
-
[2]
Qwen2-audio technical report.arXiv preprint arXiv:2407.10759. Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
In Findings of the Association for Computational Lin- guistics: EMNLP 2021, pages 3296–3315
Sd-qa: Spoken dialectal question answering for the real world. In Findings of the Association for Computational Lin- guistics: EMNLP 2021, pages 3296–3315. Yuan Gong, Hongyin Luo, Alexander H. Liu, Leonid Karlinsky, and James Glass
2021
-
[4]
Gaussian Error Linear Units (GELUs)
Gaus- sian error linear units (GELUs).Preprint, arXiv:1606.08415. Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Domini- can Republic
The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Domini- can Republic. Association for Computational Lin- guistics. Xiang Lisa Li and Percy Liang
2021
-
[6]
InFindings of the Association for Computa- tional Linguistics: EMNLP 2024, pages 9373–9398, Miami, Florida, USA
PEDANTS: Cheap but effective and interpretable answer equiva- lence. InFindings of the Association for Computa- tional Linguistics: EMNLP 2024, pages 9373–9398, Miami, Florida, USA. Association for Computational Linguistics. Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen
2024
-
[7]
Qwen2.5 technical report.Preprint, arXiv:2412.15115. 9 Alec Radford, Jong Wook Kim, Tao Xu, Greg Brock- man, Christine McLeavey, and Ilya Sutskever
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
InProceedings of the 2016 conference on empirical methods in natural language processing, pages 2383–2392
Squad: 100,000+ questions for machine comprehension of text. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 2383–2392. Zuhair Hasan Shaik, Pradyoth Hegde, Prashant Ban- nulmath, and Deepak K T
2016
-
[9]
InFindings of the Associ- ation for Computational Linguistics: EMNLP 2024, pages 8201–8211, Miami, Florida, USA
LaRA: Large rank adaptation for speech and text cross-modal learning in large language models. InFindings of the Associ- ation for Computational Linguistics: EMNLP 2024, pages 8201–8211, Miami, Florida, USA. Association for Computational Linguistics. Ying Shen, Zhiyang Xu, Qifan Wang, Yu Cheng, Wen- peng Yin, and Lifu Huang
2024
-
[10]
Blsp: Bootstrapping language-speech pre-training via behavior alignment of continuation writing,
Salmonn: Towards generic hearing abilities for large language models. InInternational Conference on Learning Representations. Chen Wang, Minpeng Liao, Zhongqiang Huang, Jin- liang Lu, Junhong Wu, Yuchen Liu, Chengqing Zong, and Jiajun Zhang. 2023a. Blsp: Boot- strapping language-speech pre-training via behavior alignment of continuation writing.arXiv prep...
-
[11]
Han Wang, Yongjie Ye, Bingru Li, Yuxiang Nie, Jinghui Lu, Jingqun Tang, Yanjie Wang, and Can Huang
Blsp-kd: Bootstrapping language-speech pre-training via knowledge distilla- tion.Preprint, arXiv:2405.19041. Han Wang, Yongjie Ye, Bingru Li, Yuxiang Nie, Jinghui Lu, Jingqun Tang, Yanjie Wang, and Can Huang
-
[12]
Vision as LoRA.arXiv preprint arXiv:2503.20680. Mingqiu Wang, Wei Han, Izhak Shafran, Zelin Wu, Chung-Cheng Chiu, Yuan Cao, Yongqiang Wang, Nanxin Chen, Yu Zhang, Hagen Soltau, Paul K. Rubenstein, Lukas Zilka, Dian Yu, Zhong Meng, Golan Pundak, Nikhil Siddhartha, Johan Schalkwyk, and Yonghui Wu. 2023b. Slm: Bridge the thin gap be- tween speech and text fo...
-
[13]
Heysquad: A spo- ken question answering dataset.arXiv preprint arXiv:2304.13689. Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin
-
[14]
Qwen2.5-omni technical report. Preprint, arXiv:2503.20215. Yahan Yu, Duzhen Zhang, Yong Ren, Xuanle Zhao, Xiuyi Chen, and Chenhui Chu
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
InFindings of the Association for Computational Linguistics: ACL 2025, pages 2779–2796, Vienna, Austria
Progressive LoRA for multimodal continual instruction tuning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 2779–2796, Vienna, Austria. Association for Computational Linguistics. Biao Zhang and Rico Sennrich
2025
-
[16]
In Findings of the Association for Computational Lin- guistics: EMNLP 2023, pages 15757–15773, Singa- pore
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. In Findings of the Association for Computational Lin- guistics: EMNLP 2023, pages 15757–15773, Singa- pore. Association for Computational Linguistics. 10 A Appendix A.1 Additional Experimental Details Training Data.For AuRA adaptation, we use a small mixture o...
2023
-
[17]
The results show that the advantage of AuRA persists even with the smaller backbone
This setting is intended to test whether AuRA’s gain depends on the larger 7B backbone used in the main experiments, or whether the same adaptation principle remains effective when the language model capacity is reduced. The results show that the advantage of AuRA persists even with the smaller backbone. On HeySquad, AuRA improves PEDANTS from 44.36 to 45...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.