LLM Agents Can See Code Repositories
Pith reviewed 2026-06-27 05:20 UTC · model grok-4.3
The pith
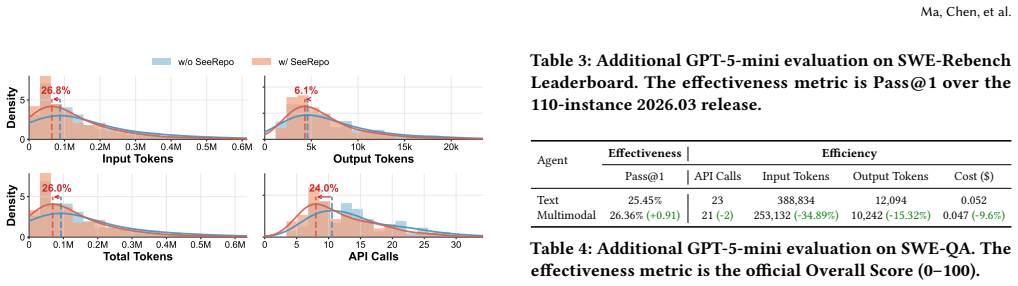
Visual graphs of code repositories let LLM agents use 26% fewer tokens while solving issues at equal or better accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
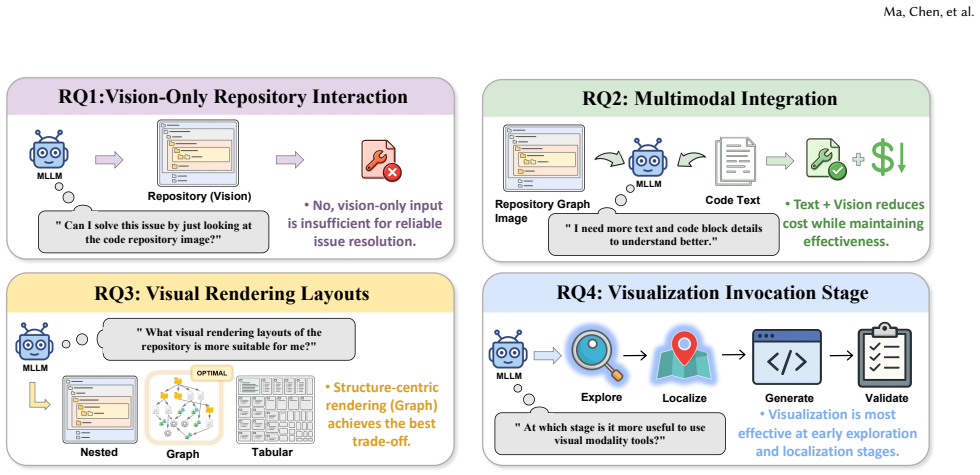
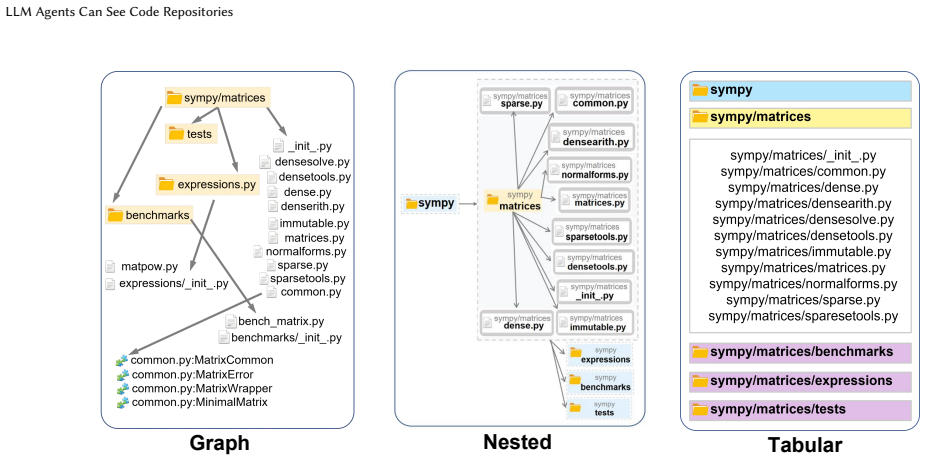
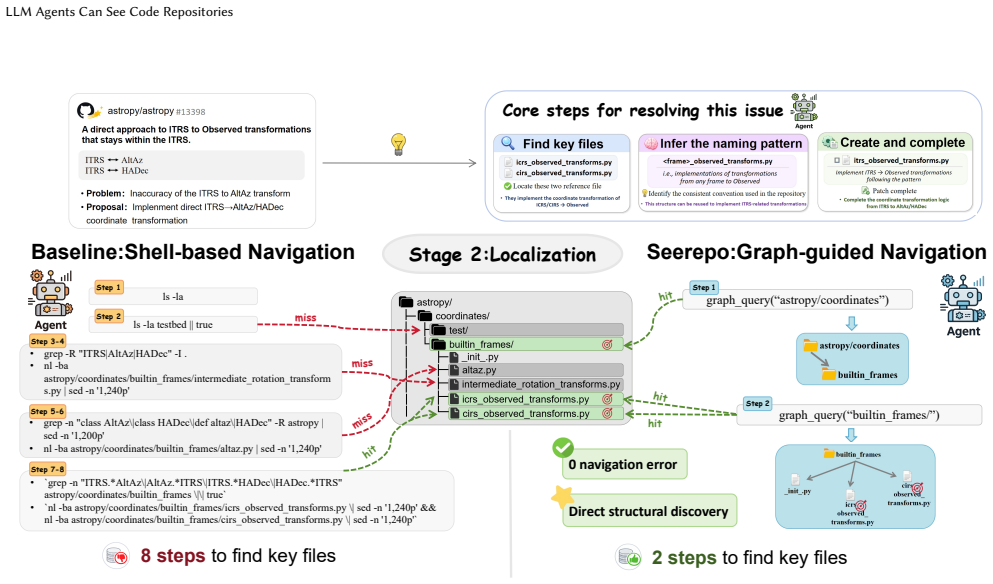
Agents that receive visual graphs of repository structure alongside text inputs consume up to 26% fewer input tokens and achieve equal or higher accuracy on issue-resolution tasks than text-only baselines. Purely visual setups degrade both metrics because agents lack sufficient symbolic detail and compensate with repeated visual queries. The visual modality is most effective for fault localization and when the agent autonomously controls exploration depth.
What carries the argument
Visual graphs of repository structure used as a supplementary modality alongside text inputs for multimodal LLM agents.
If this is right
- Input token consumption decreases by up to 26% on repository-level issue resolution tasks.
- Issue-resolution accuracy is maintained or improved relative to text-only agents.
- Visualization is most useful during fault localization.
- Agents benefit when they autonomously control exploration depth with the visual input.
- Pure vision-only configurations increase token costs due to repeated queries for symbolic detail.
Where Pith is reading between the lines
- Agents could request visual graphs only on demand when text alone fails to convey structure.
- The same hybrid input pattern may extend to other structured domains such as database schemas or dependency graphs outside software.
- Models fine-tuned on code-specific visualizations could produce larger efficiency gains than general multimodal models.
- Lower token use could allow agents to handle larger repositories within fixed context limits.
Load-bearing premise
The visual graphs supply information that the multimodal models can actually exploit beyond what is already present in the text representation, and the chosen issue-resolution tasks and metrics reflect meaningful real-world performance differences.
What would settle it
An experiment on the same tasks and models that adds visual graphs conveying only information already present in the text and finds no reduction in token use or change in accuracy would falsify the claim that the supplementary modality improves efficiency.
Figures

read the original abstract
Coding agents powered by large language models have demonstrated strong performance on software engineering tasks. Yet most agents consume repositories almost entirely as text, which differs from how human developers use visual structure such as folder hierarchies and dependency relationships to orient themselves in large codebases. With multimodal large language models (MLLMs), it is an open question whether agents can effectively benefit from visual representations of repositories. This paper presents the first systematic empirical study of visual repository representations for LLM-based agents on repository-level issue resolution. We evaluate four recent multimodal models. Our results show that a strictly vision-only setup degrades accuracy and increases token cost, because agents lack sufficient symbolic detail and compensate with repeated visual queries. In contrast, integrating visual graphs of repository structure as a supplementary modality alongside standard text interfaces helps agents understand structure more efficiently: input token consumption decreases by up to 26% while issue-resolution accuracy is maintained or improved. Visualization is most useful during fault localization and when the agent autonomously controls exploration depth. These findings point to a practical hybrid text-and-vision design for next-generation coding agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first systematic empirical study of visual repository representations for LLM-based agents on repository-level issue resolution tasks. It evaluates four recent multimodal models and claims that a strictly vision-only setup degrades accuracy and increases token cost, while integrating visual graphs of repository structure as a supplementary modality to standard text interfaces reduces input token consumption by up to 26% while maintaining or improving issue-resolution accuracy. Visualization is reported as most useful during fault localization and when the agent controls exploration depth, pointing to a hybrid text-and-vision design for coding agents.
Significance. If the central empirical result holds after addressing controls, the work would provide actionable evidence for incorporating visual modalities into coding agents, distinguishing cases where vision adds value beyond text. The study is positioned as the first systematic evaluation on this topic and includes concrete metrics on token efficiency and accuracy across models and tasks.
major comments (2)
- [Abstract / Evaluation] The experimental design (as described in the abstract and evaluation) compares the visual-graph + text condition only against standard text interfaces, without an ablation using an equivalent text-based graph representation (e.g., indented tree, adjacency list, or structured textual hierarchy derived from the same repository data). This is load-bearing for the claim that MLLMs extract and exploit structural cues specifically from the visual modality, as opposed to the graph structure itself.
- [Abstract] The abstract reports the headline 26% token reduction and accuracy claims but supplies no experimental details on datasets, task selection criteria, statistical tests, variance across runs, or controls for post-hoc choices. This prevents assessment of whether the efficiency gains are robust.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, agreeing where revisions are warranted to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract / Evaluation] The experimental design (as described in the abstract and evaluation) compares the visual-graph + text condition only against standard text interfaces, without an ablation using an equivalent text-based graph representation (e.g., indented tree, adjacency list, or structured textual hierarchy derived from the same repository data). This is load-bearing for the claim that MLLMs extract and exploit structural cues specifically from the visual modality, as opposed to the graph structure itself.
Authors: We agree this ablation would more cleanly isolate the contribution of the visual encoding. Our primary baseline is the standard text-only interface used by existing agents, which is the most relevant comparison for practical adoption. However, to address the concern, we will add a new ablation experiment in the revised manuscript comparing the visual-graph condition against an equivalent text-based graph representation (e.g., adjacency list or indented tree) derived from the same repository data. This will allow us to quantify whether the efficiency and accuracy gains are attributable to the visual modality specifically. revision: yes
-
Referee: [Abstract] The abstract reports the headline 26% token reduction and accuracy claims but supplies no experimental details on datasets, task selection criteria, statistical tests, variance across runs, or controls for post-hoc choices. This prevents assessment of whether the efficiency gains are robust.
Authors: The abstract is a concise summary; full experimental details—including datasets (SWE-bench repositories), task selection criteria, statistical tests, variance across runs, and controls—are reported in the Evaluation section. We will revise the abstract to briefly note the key setup elements (e.g., models evaluated, task type, and that full details and statistical analysis appear in the body) while keeping it within length limits. revision: yes
Circularity Check
No circularity: purely empirical evaluation study
full rationale
The paper reports experimental results from evaluating four MLLMs on repository-level issue resolution tasks, measuring input token consumption and accuracy across text-only vs. text+vision conditions. No equations, parameter fitting, derivations, or load-bearing self-citations appear in the provided text. Claims rest on direct empirical comparisons rather than any reduction of outputs to inputs by construction. This is the expected outcome for an evaluation study without mathematical modeling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Ibragim Badertdinov, Alexander Golubev, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Andrei Andriushchenko, Maria Trofimova, Daria Litvintseva, and Boris Yangel. 2026. Swe-rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents.Advances in Neural Information Processing Systems38 (2026)
2026
-
[3]
ByteDance. 2026. Doubao Seed 2.0: General-Purpose Agent Models. https: //www.volcengine.com. Released February 2026
2026
- [4]
- [5]
- [6]
-
[7]
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. 2024. SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics
2024
-
[8]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [9]
-
[10]
Kai Huang, Jian Zhang, Xiaofei Xie, and Chunyang Chen. 2025. Seeing is Fixing: Cross-Modal Reasoning with Multimodal LLMs for Visual Software Issue Fixing. arXiv:2506.16136 [cs.SE] https://arxiv.org/abs/2506.16136
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Zhonghao Jiang, Xiaoxue Ren, Meng Yan, Wei Jiang, Yong Li, and Zhongxin Liu
- [12]
-
[13]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [14]
- [15]
- [16]
- [17]
-
[18]
Moonshot AI. 2026. Kimi K2.5: Native Multimodal Agentic Model. https://kimi. moonshot.cn. Released January 2026
2026
-
[19]
Fangwen Mu, Junjie Wang, Lin Shi, Song Wang, Shoubin Li, and Qing Wang
-
[20]
Experepair: Dual-memory enhanced llm-based repository-level program repair.arXiv preprint arXiv:2506.10484(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
OpenAI. 2024. SWE-bench Verified. https://openai.com/index/introducing-swe- bench-verified/
2024
-
[22]
OpenAI. 2025. GPT-5: OpenAI’s Next Generation Language Model. https: //openai.com. Released August 2025
2025
-
[23]
OpenAI. 2025. GPT-5.1: Enhanced Reasoning and Personalization. https://openai. com. Released November 2025
2025
-
[24]
Weihan Peng, Yuling Shi, YINGWEI MA, Longfei Yun, Beijun Shen, and Xiaodong Gu. [n. d.]. DeepRepoQA: Code Repository Question Answering with Deep Agent Exploration. ([n. d.])
-
[25]
Weihan Peng, Yuling Shi, Yuhang Wang, Xinyun Zhang, Beijun Shen, and Xi- aodong Gu. 2025. Swe-qa: Can language models answer repository-level code questions?arXiv preprint arXiv:2509.14635(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [26]
-
[27]
Yuling Shi, Songsong Wang, Chengcheng Wan, Min Wang, and Xiaodong Gu
- [28]
-
[29]
Yuling Shi, Chaoxiang Xie, Zhensu Sun, Yeheng Chen, Chenxu Zhang, Longfei Yun, Chengcheng Wan, Hongyu Zhang, David Lo, and Xiaodong Gu. 2026. CodeOCR: On the Effectiveness of Vision Language Models in Code Under- standing.arXiv preprint arXiv:2602.01785(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Yuling Shi, Hongyu Zhang, Chengcheng Wan, and Xiaodong Gu. 2025. Between lines of code: Unraveling the distinct patterns of machine and human program- mers. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 1628–1639
2025
-
[31]
Aditya Bharat Soni, Boxuan Li, Xingyao Wang, Valerie Chen, and Graham Neubig
-
[32]
arXiv:2506.03011 [cs.CL] https://arxiv.org/abs/2506.03011
Coding Agents with Multimodal Browsing are Generalist Problem Solvers. arXiv:2506.03011 [cs.CL] https://arxiv.org/abs/2506.03011
- [33]
- [34]
-
[35]
Yuhang Wang, Yuling Shi, Mo Yang, Rongrui Zhang, Shilin He, Heng Lian, Yuting Chen, Siyu Ye, Kai Cai, and Xiaodong Gu. 2026. SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents.arXiv preprint arXiv:2601.16746(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Yifei Wang, Ziteng Wang, Yuling Shi, Silin Chen, Xinrui Wang, Yueqi Wang, Beijun Shen, Linjing Li, Xiaodong Gu, Julian McAuley, et al. 2026. Context Com- pression for LLM Agents: A Survey of Methods, Failure Modes, and Evaluation. (2026)
2026
-
[37]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in neural information processing systems 35 (2022), 24824–24837
2022
-
[38]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang
-
[39]
Agentless: Demystifying LLM-based Software Engineering Agents
Agentless: Demystifying LLM-based Software Engineering Agents. arXiv:2407.01489 [cs.SE] https://arxiv.org/abs/2407.01489
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R. Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[41]
John Yang, Carlos E Jimenez, Alex L Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R Narasimhan, Diyi Yang, Sida I Wang, and Ofir Press. 2025. SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?. InThe Thirteenth International Confer- ence on Learning Representations. https://ope...
2025
- [42]
- [43]
-
[44]
Shaoqiu Zhang, Yuhang Wang, Jialiang Liang, Yuling Shi, Wenhao Zeng, Mao- quan Wang, Shilin He, Ningyuan Xu, Siyu Ye, Kai Cai, et al . 2026. SWE- Explore: Benchmarking How Coding Agents Explore Repositories.arXiv preprint arXiv:2606.07297(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [45]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.