Duet: Dual-Robot Understanding via Efficient Teaching
Pith reviewed 2026-06-26 16:44 UTC · model grok-4.3
The pith
Pretraining dual-robot policies on human coordination data from VR achieves equal or better task performance than robot-only training while cutting human effort by 5.4 times on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
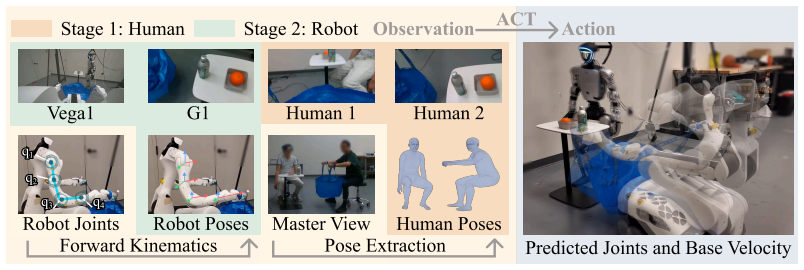
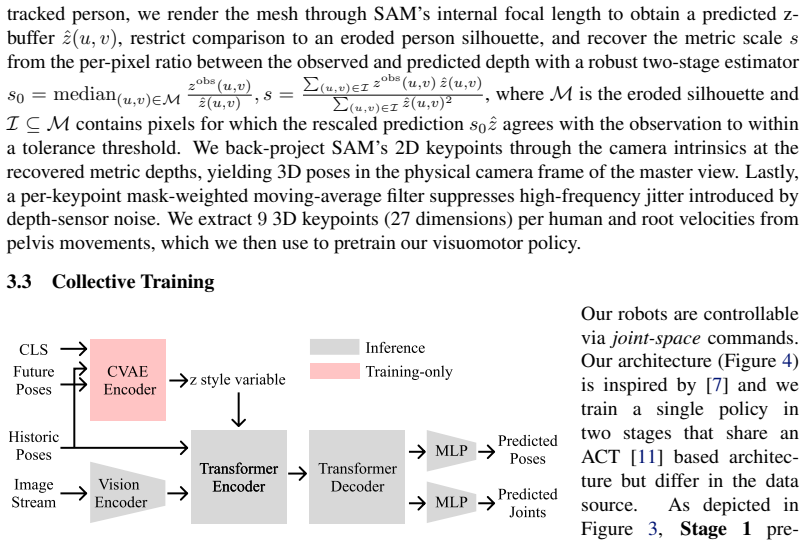
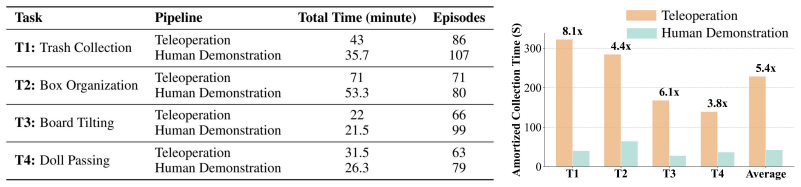
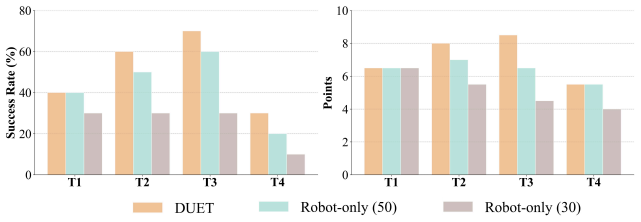
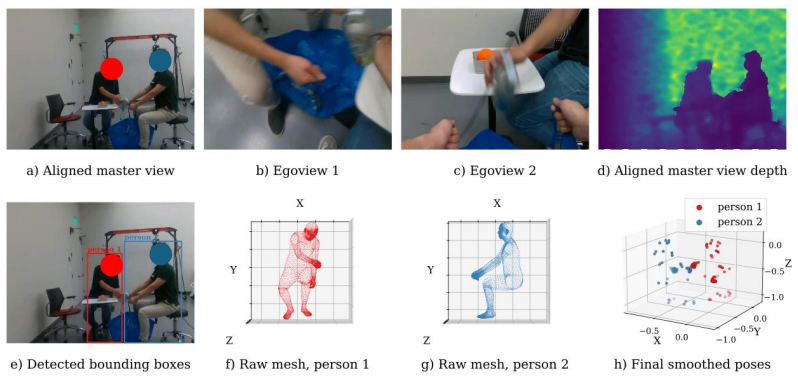
DUET uses a unified VR-based teleoperation pipeline to record human-human coordination and collaborative mobile manipulation priors, then pretrains collaborative policies with an Action Chunking Transformer on these efficient human demonstrations before fine-tuning on a minimal set of real-robot trajectories. On a benchmark of four collaborative tasks with a Unitree G1 humanoid and Dexmate Vega1 mobile manipulator, policies trained this way yield superior or comparable task performance to robot-only baselines while the human data collection pipeline accelerates data gathering by 5.4 times on average relative to direct teleoperation.
What carries the argument
Action Chunking Transformer that first pretrains collaborative policies on human-human VR demonstrations before fine-tuning on limited real-robot teleoperation trajectories.
If this is right
- Dual-robot policies for tasks exceeding single-robot reach can be trained with substantially less direct robot teleoperation time.
- Human coordination priors captured in VR improve or maintain performance on coordinated transport and handover tasks after fine-tuning.
- The synchronized VR collection system enables faster acquisition of in-domain data for heterogeneous robot pairs.
- Fine-tuning after human pretraining sufficiently bridges embodiment differences between humans and the tested robot platforms.
Where Pith is reading between the lines
- The same pretraining-then-fine-tune pattern might reduce data needs for other multi-robot coordination problems beyond the dual case tested here.
- If VR hardware is unavailable, alternative motion-capture methods could be substituted but would require separate validation of transfer quality.
- Increasing the volume or diversity of human-human demonstrations during pretraining could further shrink the required robot fine-tuning set.
- Real-world deployment would still need checks for safety when human-derived coordination patterns interact with physical robot constraints not present in VR.
Load-bearing premise
Human-human coordination data collected in VR transfers to heterogeneous robot embodiments with only minimal fine-tuning and little domain gap.
What would settle it
Train identical Action Chunking Transformer policies on the same four tasks using only the real-robot teleoperation data without the human pretraining stage and compare success rates and completion times to the full DUET pipeline; equal or higher performance in the robot-only case would falsify the value of the human priors.
Figures





read the original abstract
Dual-robot collaboration enables tasks that exceed the reach and payload of a single robot, such as collaboratively transporting objects across environments and executing coordinated handovers. Data acquisition is the primary bottleneck for training these systems. To this end, we introduce DUET, a dual-robot learning framework for mobile manipulation. For efficient data collection, we create a unified dual-embodiment synchronized VR-based teleoperation system for in-domain heterogeneous robot data collection. We further develop a complementary tracking pipeline that records human-human coordination and collaborative mobile manipulation priors. To allow efficient learning, we introduce an Action Chunking Transformer based architecture that first pretrains collaborative policies on efficient human-human demonstrations, before finetuning them on a minimal set of real-robot teleoperation trajectories. We develop a benchmark of four collaborative tasks to evaluate our framework using a Unitree G1 humanoid and a Dexmate Vega1 mobile manipulator. The results demonstrate that harnessing human priors not only yields superior task performance compared to baselines trained only on robot data, but also reduces the total human effort required for data collection. Our human data collection pipeline achieves 5.4x acceleration on average from teleoperation, but we perform equally or better than robot-only data trained policies across all tasks. Our project page is available at https://zhaoy37.github.io/Duet/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DUET, a dual-robot learning framework for mobile manipulation that collects human-human coordination priors via a unified VR-based synchronized teleoperation and tracking pipeline, pretrains an Action Chunking Transformer policy on these demonstrations, and fine-tunes on a minimal set of real-robot trajectories. It evaluates the approach on four collaborative tasks using a Unitree G1 humanoid and Dexmate Vega1 mobile manipulator, claiming superior task performance over robot-only baselines together with a 5.4x average acceleration in human data collection effort relative to teleoperation.
Significance. If the transfer from human-human VR priors to heterogeneous robot embodiments holds with the reported performance gains, the framework would meaningfully reduce the data-collection bottleneck for dual-robot collaborative systems by substituting expensive robot teleoperation with faster human-human demonstrations.
major comments (1)
- [Abstract] Abstract: the claim that human-human VR coordination data supplies priors that transfer to the Unitree G1 + Dexmate Vega1 pair with minimal domain gap after fine-tuning on only a minimal robot-teleop set is load-bearing for both the performance superiority and 5.4x effort-reduction assertions, yet the manuscript provides no quantitative transfer metrics, embodiment-mapping details, or ablation isolating the pretraining contribution versus architecture or data volume.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We address the concern below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that human-human VR coordination data supplies priors that transfer to the Unitree G1 + Dexmate Vega1 pair with minimal domain gap after fine-tuning on only a minimal robot-teleop set is load-bearing for both the performance superiority and 5.4x effort-reduction assertions, yet the manuscript provides no quantitative transfer metrics, embodiment-mapping details, or ablation isolating the pretraining contribution versus architecture or data volume.
Authors: We agree the abstract would benefit from greater specificity. The reported performance gains are measured against robot-only baselines trained on equivalent or larger volumes of real-robot data, and the 5.4x figure is a direct measurement of human collection time (VR human-human vs. robot teleoperation). To isolate the pretraining contribution we will add (i) an ablation comparing the same ACT architecture trained from scratch on the minimal robot set versus pretrained on human-human data then fine-tuned, (ii) quantitative transfer metrics such as success-rate deltas and sample-efficiency curves attributable to the human priors, and (iii) a concise description of the embodiment mapping realized by the unified VR teleoperation pipeline. These additions will be placed in the experiments section and referenced from the abstract. revision: yes
Circularity Check
No circularity; empirical claims rest on benchmark comparisons
full rationale
The manuscript presents a robotics framework for dual-robot collaboration via VR human-human pretraining followed by robot fine-tuning, evaluated on four tasks with a Unitree G1 and Dexmate Vega1. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Performance superiority and 5.4x effort reduction are asserted via direct experimental comparison to robot-only baselines, not by construction from the inputs themselves. The central transfer assumption is an empirical claim open to falsification rather than a self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-human coordination priors collected via VR transfer effectively to heterogeneous robot-robot collaboration after fine-tuning
Reference graph
Works this paper leans on
-
[1]
J. Fink, M. A. Hsieh, and V . Kumar. Multi-robot manipulation via caging in environments with obstacles. In2008 IEEE International Conference on Robotics and Automation, pages 1471–1476. IEEE, 2008
2008
-
[2]
M. Lai, K. Go, Z. Li, T. Kr ¨oger, S. Schaal, K. Allen, and J. Scholz. Roboballet: Planning for multirobot reaching with graph neural networks and reinforcement learning.Science Robotics, 10(106):eads1204, 2025
2025
-
[3]
Wang and M
Z. Wang and M. Schwager. Multi-robot manipulation without communication. InDistributed autonomous robotic systems: The 12th international symposium, pages 135–149. Springer, 2016
2016
-
[4]
Z. Fu, T. Z. Zhao, and C. Finn. Mobile ALOHA: Learning bimanual mobile manipulation using low-cost whole-body teleoperation. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=FO6tePGRZj
2024
-
[5]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=ZMnD6QZAE6
2024
-
[6]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[7]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Con- ference on Robotics and Automation (ICRA), pages 13226–13233. IEEE, 2025
2025
-
[8]
Hoque, P
R. Hoque, P. Huang, D. J. Yoon, M. sivapurapu, and J. Zhang. Egodex: Learning dexter- ous manipulation from large-scale egocentric video. InThe F ourteenth International Con- ference on Learning Representations, 2026. URLhttps://openreview.net/forum?id= FFxkFMU89E. 9
2026
-
[9]
R. Punamiya, S. Kareer, Z. Liu, J. Citron, R.-Z. Qiu, X. Cai, A. Gavryushin, J. Chen, D. Li- conti, L. Y . Zhu, et al. Egoverse: An egocentric human dataset for robot learning from around the world.arXiv preprint arXiv:2604.07607, 2026
Pith/arXiv arXiv 2026
-
[10]
X. Yang, D. Kukreja, D. Pinkus, A. Sagar, T. Fan, J. Park, S. Shin, J. Cao, J. Liu, N. Ugrinovic, et al. Sam 3d body: Robust full-body human mesh recovery.arXiv preprint arXiv:2602.15989, 2026
arXiv 2026
-
[11]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi:10.15607/RSS.2023.XIX.016
-
[12]
T. Z. Zhao, J. Tompson, D. Driess, P. Florence, S. K. S. Ghasemipour, C. Finn, and A. Wahid. ALOHA unleashed: A simple recipe for robot dexterity. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=gvdXE7ikHI
2024
-
[13]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
-
[14]
S. Dass, W. Ai, Y . Jiang, S. Singh, J. Hu, R. Zhang, P. Stone, B. Abbatematteo, and R. Mart´ın- Mart´ın. Telemoma: A modular and versatile teleoperation system for mobile manipulation. arXiv preprint arXiv:2403.07869, 2024
arXiv 2024
-
[15]
Jiang, R
Y . Jiang, R. Zhang, J. Wong, C. Wang, Y . Ze, H. Yin, C. Gokmen, S. Song, J. Wu, and L. Fei- Fei. BEHA VIOR robot suite: Streamlining real-world whole-body manipulation for everyday household activities. In9th Annual Conference on Robot Learning, 2025. URLhttps:// openreview.net/forum?id=v2KevjWScT
2025
-
[16]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Uni- versal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots. InProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024. doi: 10.15607/RSS.2024.XX.045
-
[17]
H. Choi, Y . Hou, C. Pan, S. Hong, A. Patel, X. Xu, M. R. Cutkosky, and S. Song. In-the-wild compliant manipulation with umi-ft, 2026. URLhttps://arxiv.org/abs/2601.09988
arXiv 2026
-
[18]
H. Etukuru, N. Naka, Z. Hu, S. Lee, J. Mehu, A. Edsinger, C. Paxton, S. Chintala, L. Pinto, and N. M. Mahi Shafiullah. Robot utility models: General policies for zero-shot deployment in new environments. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8275–8283, 2025. doi:10.1109/ICRA55743.2025.11127857
-
[19]
S. Wei, H. Jing, B. Li, Z. Zhao, J. Mao, Z. Ni, S. He, J. Liu, X. Liu, K. Kang, et al.Ψ 0: An open foundation model towards universal humanoid loco-manipulation.arXiv preprint arXiv:2603.12263, 2026. 10
arXiv 2026
-
[20]
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Castaneda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[21]
J. Li, X. Cheng, T. Huang, S. Yang, R.-Z. Qiu, and X. Wang. AMO: Adaptive Motion Opti- mization for Hyper-Dexterous Humanoid Whole-Body Control. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi:10.15607/RSS.2025.XXI.061
-
[22]
Y . Li, Y . Lin, J. Cui, T. Liu, W. Liang, Y . Zhu, and S. Huang. CLONE: Closed-loop whole-body humanoid teleoperation for long-horizon tasks. In9th Annual Conference on Robot Learning,
-
[23]
URLhttps://openreview.net/forum?id=Bw9NHYjDqR
-
[24]
Y . Ze, S. Zhao, W. Wang, A. Kanazawa, R. Duan, P. Abbeel, G. Shi, J. Wu, and C. K. Liu. Twist2: Scalable, portable, and holistic humanoid data collection system.arXiv preprint arXiv:2511.02832, 2025
arXiv 2025
-
[25]
C. Mattson, V . Raveendra, E. Novoseller, N. Waytowich, V . J. Lawhern, and D. S. Brown. R2bc: Multi-agent imitation learning from single-agent demonstrations.arXiv preprint arXiv:2510.18085, 2025
Pith/arXiv arXiv 2025
-
[26]
K. Song, S. Ma, G. Chen, N. Jin, G. Zhao, M. Ding, Z. Xiong, and J. Pan. Collabot: Vision- language guided simultaneous collaborative manipulation.arXiv preprint arXiv:2508.03526, 2025
Pith/arXiv arXiv 2025
-
[27]
W. Zhang, C. Street, and M. Mansouri. Multi-nonholonomic robot object transportation with obstacle crossing using a deformable sheet. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 7349–7355, 2025. doi:10.1109/ICRA55743.2025. 11128313
-
[28]
N. Michael, J. Fink, and V . Kumar. Cooperative manipulation and transportation with aerial robots. InProceedings of Robotics: Science and Systems, Seattle, USA, June 2009. doi: 10.15607/RSS.2009.V .001
-
[29]
C. Yang, G. N. Sue, Z. Li, L. Yang, H. Shen, Y . Chi, A. Rai, J. Zeng, and K. Sreenath. Col- laborative navigation and manipulation of a cable-towed load by multiple quadrupedal robots. IEEE Robotics and Automation Letters, 7(4):10041–10048, 2022
2022
-
[30]
R. T. Fawcett, L. Amanzadeh, J. Kim, A. D. Ames, and K. A. Hamed. Distributed data- driven predictive control for multi-agent collaborative legged locomotion. In2023 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 9924–9930, 2023. doi: 10.1109/ICRA48891.2023.10160914
-
[31]
Y . Wang, M. Damani, P. Wang, Y . Cao, and G. Sartoretti. Distributed reinforcement learning for robot teams: A review.Current Robotics Reports, 3(4):239–257, 2022
2022
- [32]
- [33]
-
[34]
Pandit, A
B. Pandit, A. Gupta, M. S. Gadde, A. Johnson, A. K. Shrestha, H. Duan, J. Dao, and A. Fern. Learning decentralized multi-biped control for payload transport. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=vhGkyWgctu
2024
-
[35]
J. Zeng, A. M. Gimenez, E. Vinitsky, J. Alonso-Mora, and S. Sun. Decentralized aerial manipulation of a cable-suspended load using multi-agent reinforcement learning. In2nd Workshop on Safe and Robust Robot Learning for Operation in the Real World, 2025. URL https://openreview.net/forum?id=yYYmqMv7Al. 11
2025
-
[36]
K. Shibata, R. Sota, S. D. Bosch, Y . Kadokawa, T. Yoshihisa, and T. Matsubara. Dereco: Decoupling representation and coordination learning for object-adaptive decentralized multi- robot cooperative transport.arXiv preprint arXiv:2603.08111, 2026
arXiv 2026
-
[37]
S. Chen, Z.-a. Cao, Z. Luo, F. Casta ˜neda, C. Li, T. Wang, Y . Yuan, L. Fan, C. K. Liu, Y . Zhu, et al. Chip: Adaptive compliance for humanoid control through hindsight perturbation.arXiv preprint arXiv:2512.14689, 2025
arXiv 2025
-
[38]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, brian ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Wa...
2025
-
[39]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. San- keti, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Jul...
2023
-
[40]
L. Heng, Y . Tang, J. Xu, H. Bao, D. Huang, and Y . Wang. Humdex: Humanoid dexterous manipulation made easy.arXiv preprint arXiv:2603.12260, 2026
arXiv 2026
-
[41]
J. Fan, Z. Zhao, Y . Zhang, C. Chen, P. Wang, H. Zhang, and Z. Cheng. Robopaint: From human demonstration to any robot and any view.arXiv preprint arXiv:2602.05325, 2026
arXiv 2026
-
[42]
M. Shi, S. Peng, J. Chen, H. Jiang, Y . Li, D. Huang, P. Luo, H. Li, and L. Chen. Egohu- manoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration. arXiv preprint arXiv:2602.10106, 2026
Pith/arXiv arXiv 2026
-
[43]
R. Nai, B. Zheng, J. Zhao, H. Zhu, S. Dai, Z. Chen, Y . Hu, Y . Hu, T. Zhang, C. Wen, et al. Hu- manoid manipulation interface: Humanoid whole-body manipulation from robot-free demon- strations.arXiv preprint arXiv:2602.06643, 2026
arXiv 2026
-
[44]
H. Chen, W. Zhang, P. Li, S. Ma, K. Ma, Y . Jin, Z. Xu, X. Wang, Y . Zheng, Z. Wang, et al. Rhythm: Learning interactive whole-body control for dual humanoids.arXiv preprint arXiv:2603.02856, 2026
Pith/arXiv arXiv 2026
-
[45]
W.-J. Huang, Y .-Y . Zhang, Y .-L. Wei, Z.-W. Xia, J. Tan, Y .-M. Li, Z. Zhao, and W.-S. Zheng. Learning whole-body human-humanoid interaction from human-human demonstrations.arXiv preprint arXiv:2601.09518, 2026
arXiv 2026
-
[46]
J. Mao, S. Zhao, S. Song, C. Hong, T. Shi, J. Ye, M. Zhang, H. Geng, J. Malik, V . Guizilini, and Y . Wang. Universal humanoid robot pose learning from internet human videos. In2025 IEEE-RAS 24th International Conference on Humanoid Robots (Humanoids), pages 1–8, 2025. doi:10.1109/Humanoids65713.2025.11203143
-
[47]
J. P. Araujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu. Retargeting matters: General motion retargeting for humanoid motion tracking.arXiv preprint arXiv:2510.02252, 2025. 12
arXiv 2025
-
[48]
Redmon, S
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real- time object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016
2016
-
[49]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InPro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[50]
Russakovsky, J
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge.Interna- tional journal of computer vision, 115(3):211–252, 2015
2015
-
[51]
Cadene, S
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zouitine, S. Palma, P. Kooijmans, M. Ar- actingi, M. Shukor, D. Aubakirova, M. Russi, F. Capuano, C. Pascal, J. Choghari, J. Moss, and T. Wolf. Lerobot: State-of-the-art machine learning for real-world robotics in pytorch. https://github.com/huggingface/lerobot, 2024. 13 Contents 1 Introduction 2 2 Relate...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.