NASDAQ: Normalized Observation Space Dynamics-Augmented Q-Learning
Pith reviewed 2026-06-26 14:37 UTC · model grok-4.3
The pith
Normalizing observations balances reconstruction losses and enables effective dynamics-augmented Q-learning across observation types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that normalizing the observation space before performing dynamics prediction corrects the unbalanced losses, providing a unified treatment for different input types and improving the effectiveness of observation-predictive RL.
What carries the argument
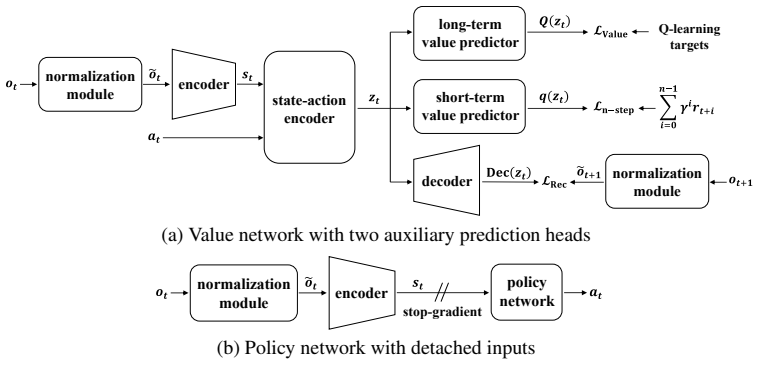
The NASDAQ framework, which couples value learning with auxiliary short-term value prediction and next normalized observation prediction tasks.
Load-bearing premise
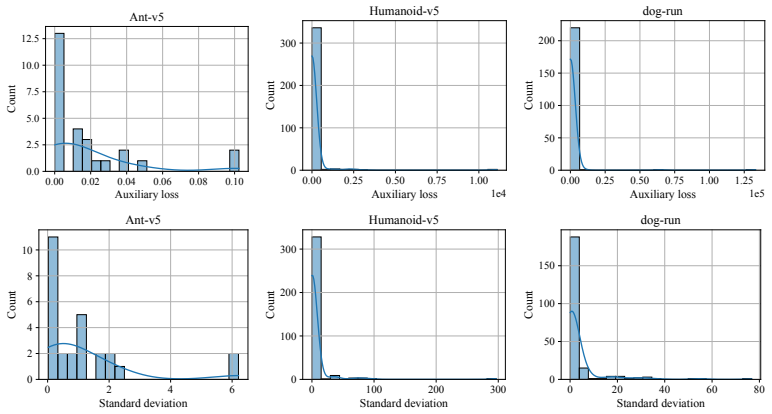
The main reason prior observation-predictive RL underperforms on low-dimensional tasks is unbalanced reconstruction losses across observation dimensions.
What would settle it
Running the proposed normalization on low-dimensional benchmark tasks and observing no improvement in performance or no reduction in loss imbalance would falsify the central claim.
Figures
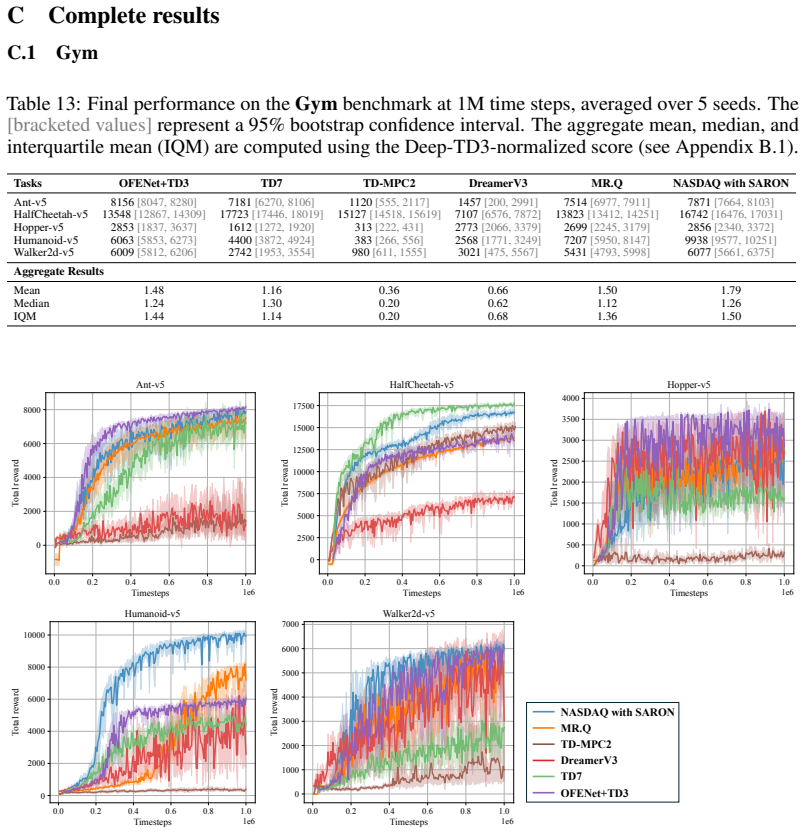
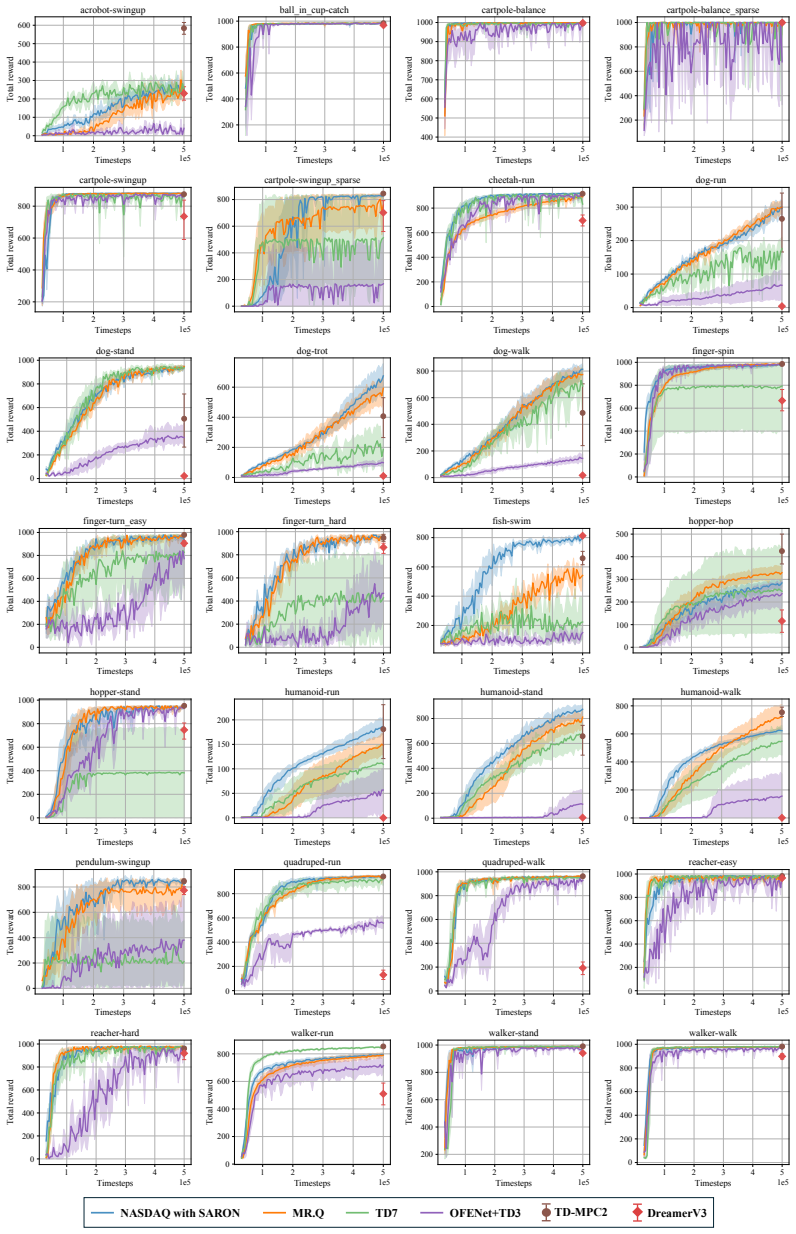
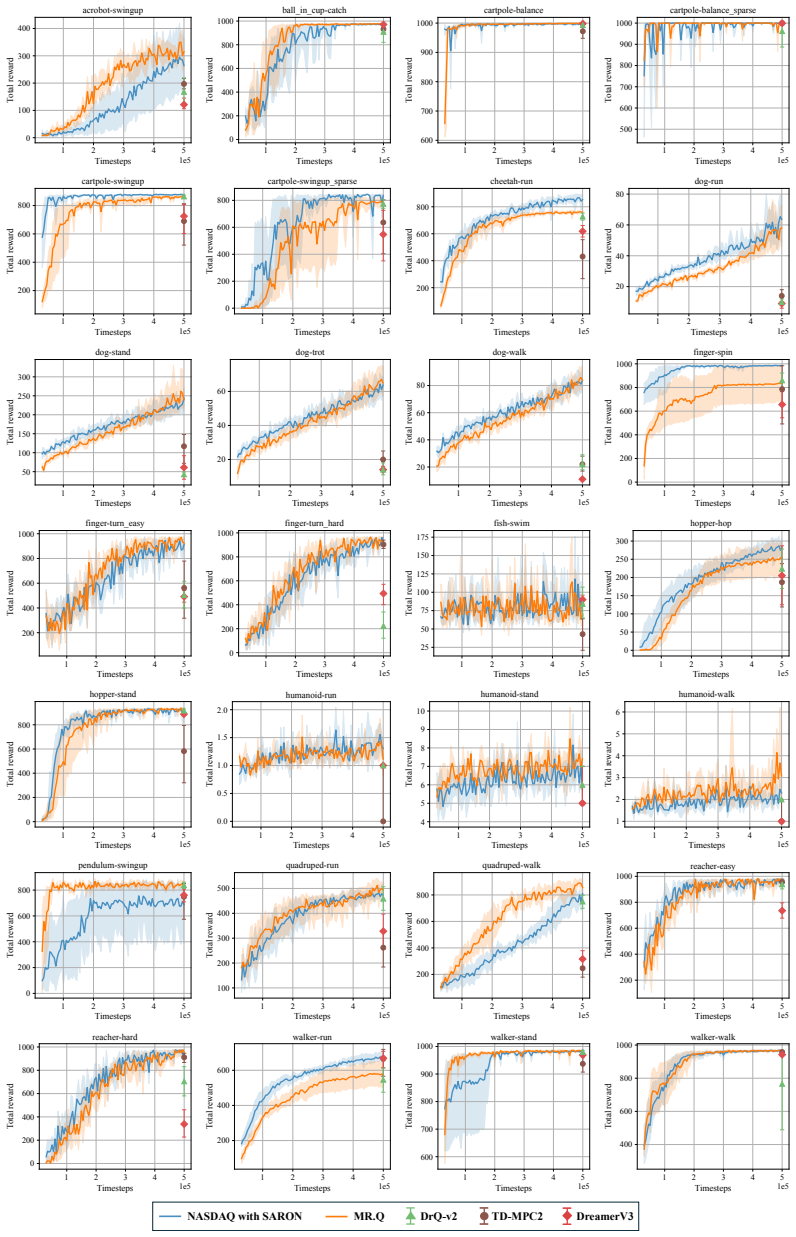
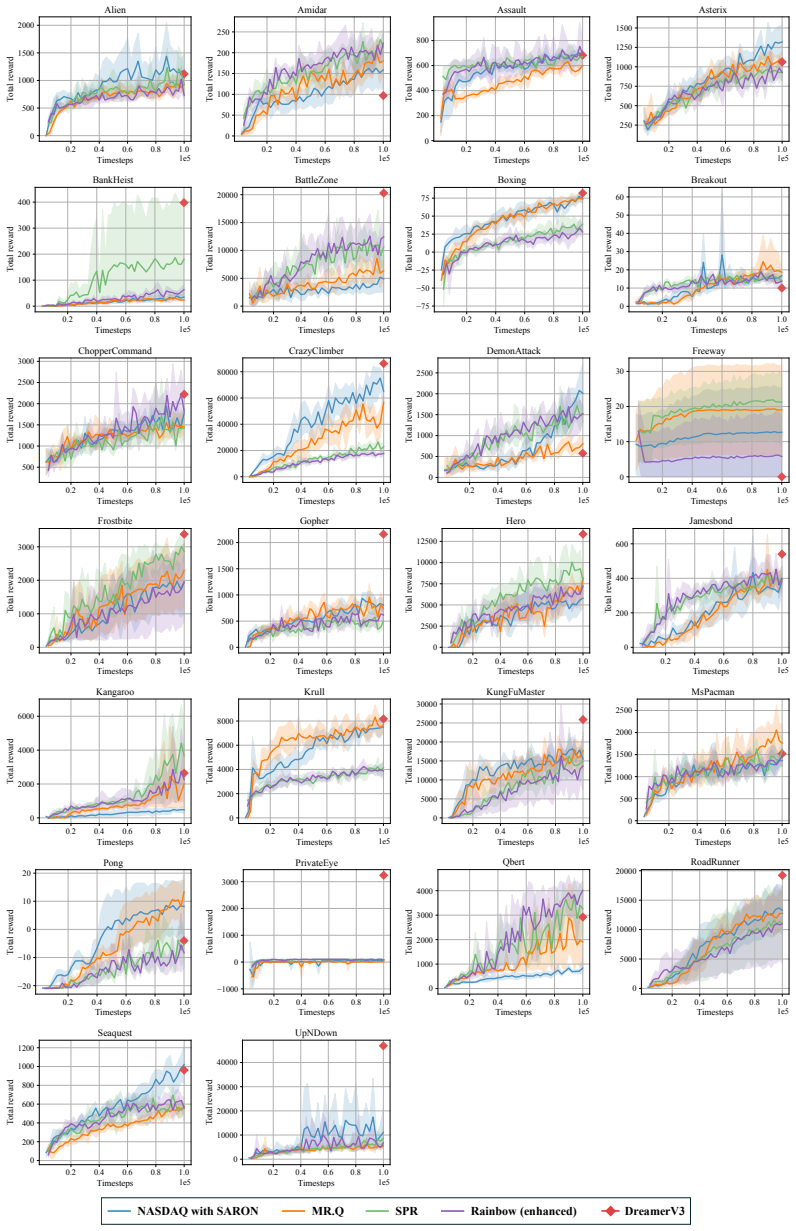
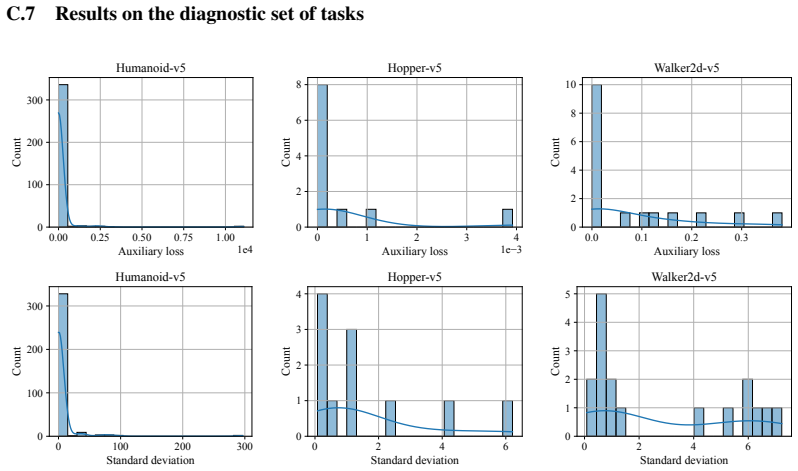
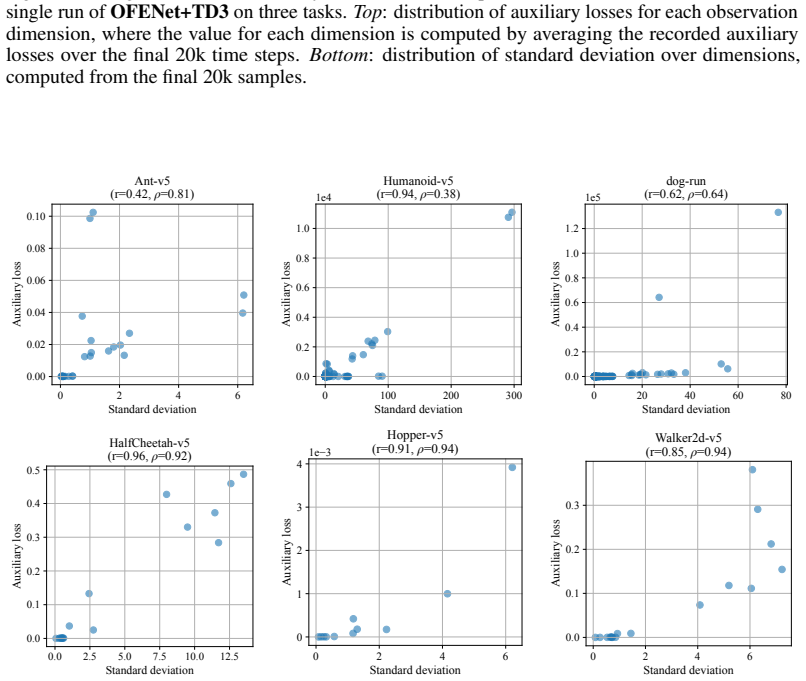
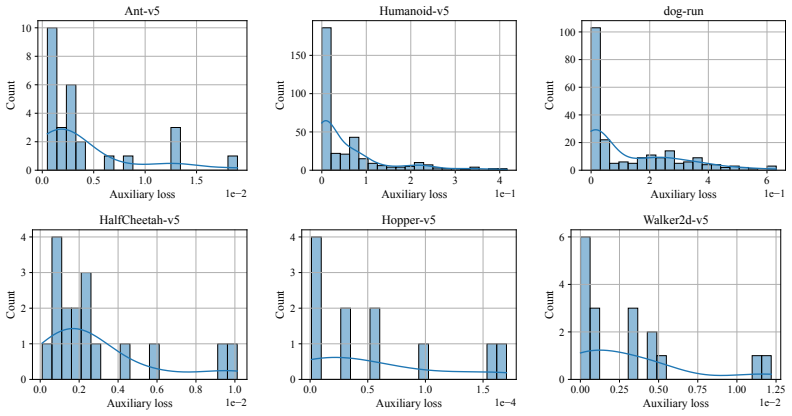
read the original abstract
Augmenting model-free reinforcement learning (RL) with representations learned through observation dynamics prediction (observation-predictive RL) can improve sample efficiency and performance, with minor modifications and limited additional computation. However, this approach still struggles in challenging tasks with low-dimensional observations. In this paper, we identify a key factor behind this problem: unbalanced reconstruction losses across observation dimensions, where dimensions with larger value ranges dominate the loss. This encourages the agent to neglect dimensions with relatively small ranges, leading to degraded performance. To address this issue, we propose a novel normalization method tailored to online RL, which normalizes low-dimensional observations and balances the resulting losses and gradients. Beyond balancing reconstruction losses, observation normalization enables dynamics prediction to be performed in a normalized observation space, thereby providing a unified treatment of low- and high-dimensional inputs (e.g., physical states and images). Building on this idea, we further introduce Normalized Observation Space Dynamics-Augmented Q-learning (NASDAQ), a framework for observation-predictive RL applicable across diverse domains. NASDAQ learns state-action representations by coupling value learning with two auxiliary tasks: short-term value prediction and next normalized observation prediction. Extensive experiments demonstrate that NASDAQ achieves competitive or superior performance compared with state-of-the-art model-based and self-predictive RL methods, while requiring significantly less training wall-time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies unbalanced per-dimension reconstruction losses as the cause of poor performance in observation-predictive RL on low-dimensional tasks. It proposes an online-RL-tailored normalization that balances losses and gradients, enabling dynamics prediction in normalized space. The resulting NASDAQ framework augments Q-learning with short-term value prediction and next-observation prediction auxiliaries, claiming competitive or superior performance to SOTA model-based and self-predictive methods at substantially lower wall-clock time.
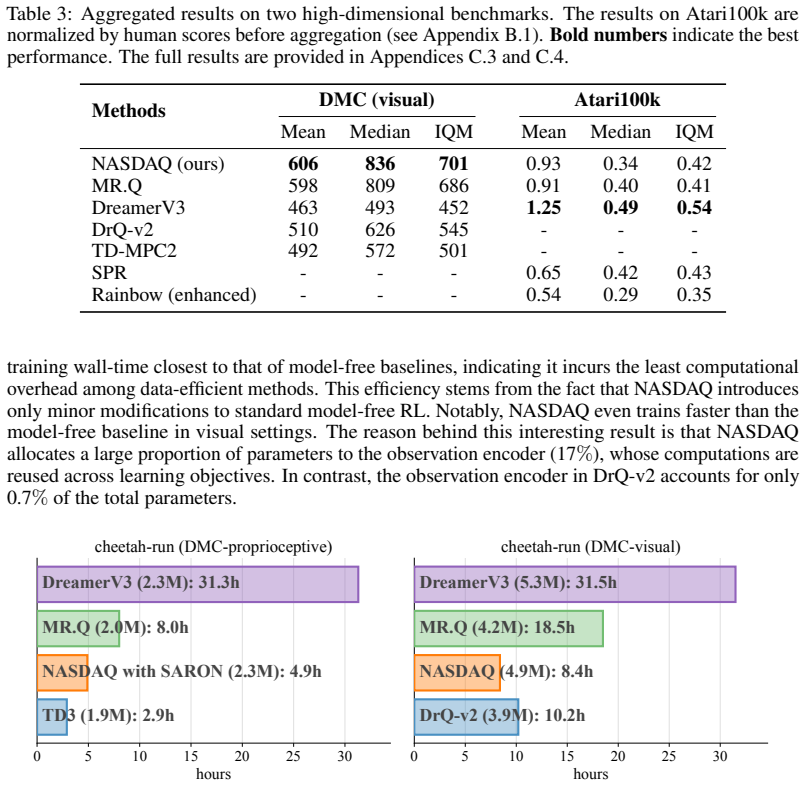
Significance. If the performance claims survive controls that isolate normalization from capacity, exploration, and weighting choices, the work supplies a lightweight, domain-agnostic engineering fix that unifies low- and high-dimensional observation handling in dynamics-augmented RL while preserving sample efficiency.
major comments (2)
- [Abstract and §1] Abstract and §1: the diagnosis that unbalanced reconstruction losses constitute the dominant cause of prior performance gaps is asserted without evidence that alternative explanations (representation capacity, exploration policy, optimizer dynamics, or auxiliary-task weighting) were controlled for in the reported experiments.
- [§4 (Experiments)] §4 (Experiments): no ablation is described that removes or reweights the normalization while keeping all other NASDAQ components fixed, so it is impossible to verify that the reported gains are attributable to loss balancing rather than the auxiliary tasks or other design choices.
minor comments (1)
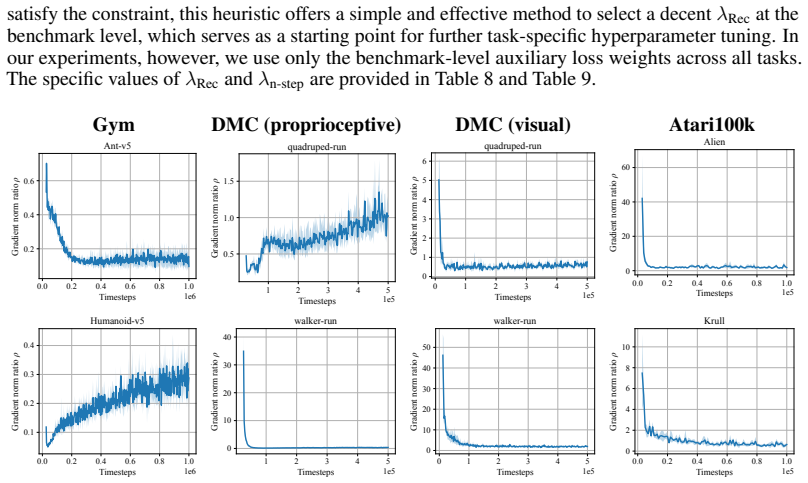
- [§3] Notation for the normalized observation space and the two auxiliary losses should be introduced with explicit equations early in §3 to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The two major comments highlight important points about evidence and experimental controls. We address each below and commit to revisions that strengthen the manuscript without misrepresenting the current results.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: the diagnosis that unbalanced reconstruction losses constitute the dominant cause of prior performance gaps is asserted without evidence that alternative explanations (representation capacity, exploration policy, optimizer dynamics, or auxiliary-task weighting) were controlled for in the reported experiments.
Authors: The diagnosis originates from direct inspection of per-dimension reconstruction losses in low-dimensional tasks, where scale differences cause certain dimensions to dominate (detailed in §3). We agree that the manuscript does not present explicit controls isolating this factor from representation capacity, exploration, or optimizer choices. In revision we will expand §1 with additional loss-component analysis and a clearer statement of the evidential limits, while noting that comparisons are to published SOTA methods that already vary in capacity and weighting. revision: partial
-
Referee: [§4 (Experiments)] §4 (Experiments): no ablation is described that removes or reweights the normalization while keeping all other NASDAQ components fixed, so it is impossible to verify that the reported gains are attributable to loss balancing rather than the auxiliary tasks or other design choices.
Authors: We concur that an ablation isolating normalization is necessary to attribute gains specifically to loss balancing. Although NASDAQ is compared against baselines lacking normalization, the current experiments do not hold auxiliary tasks fixed while toggling only the normalization. We will add this ablation to the revised §4, reporting performance with and without normalization under otherwise identical NASDAQ components. revision: yes
Circularity Check
No significant circularity; empirical engineering contribution with independent content
full rationale
The paper presents NASDAQ as an empirical method that normalizes observations to balance reconstruction losses in observation-predictive RL. No equations, fitted parameters, or self-citations are described that reduce the reported performance gains or the normalization step to inputs by construction. The central performance claims rest on experimental comparisons rather than a mathematical derivation chain. The diagnosis of unbalanced losses as the primary cause is presented as an observation motivating the method, but does not create a self-referential loop in any derivation. This is a standard case of an engineering contribution without load-bearing circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement learning - an introduction, 2nd Edition. MIT Press, 2018. URLhttp://www.incompleteideas.net/book/the-book-2nd.html
2018
-
[2]
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin A. Riedmiller, Andreas Fidjeland, Georg Ostrovski, Stig Pe- tersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep rein- forcem...
-
[3]
Proximal policy optimization algorithms.CoRR, abs/1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.CoRR, abs/1707.06347, 2017. URL http://arxiv.org/ abs/1707.06347
Pith/arXiv arXiv 2017
-
[4]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods. In Jennifer G. Dy and Andreas Krause, editors,Proceedings of the 35th In- ternational Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Swe- den, July 10-15, 2018, volume 80 ofProceedings of Machine Learning Research, pages 1582–
2018
-
[5]
URLhttp://proceedings.mlr.press/v80/fujimoto18a.html
PMLR, 2018. URLhttp://proceedings.mlr.press/v80/fujimoto18a.html
2018
-
[6]
Lillicrap, Jimmy Ba, and Mohammad Norouzi
Danijar Hafner, Timothy P. Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. In8th International Conference on Learning Repre- sentations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020. URL https://openreview.net/forum?id=S1lOTC4tDS
2020
-
[7]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy P. Lillicrap. Mastering diverse domains through world models.CoRR, abs/2301.04104, 2023. doi: 10.48550/ARXIV .2301. 04104. URLhttps://doi.org/10.48550/arXiv.2301.04104
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[8]
Temporal difference learning for model predictive control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Temporal difference learning for model predictive control. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors,International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 ofProceedings of Machine Learning Resear...
2022
-
[9]
TD-MPC2: scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: scalable, robust world models for continuous control. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview. net/forum?id=Oxh5CstDJU
2024
-
[10]
Mastering Atari, Go, chess and shogi by planning with a learned model , volume=
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy P. Lillicrap, and David Silver. Mastering atari, go, chess and shogi by planning with a learned model.Nat., 588(7839):604–609, 2020. doi: 10.1038/S41586-020-03051-4. URL https: //doi.or...
work page internal anchor Pith review doi:10.1038/s41586-020-03051-4 2020
-
[11]
Stable reinforcement learning with autoencoders for tactile and visual data
Herke van Hoof, Nutan Chen, Maximilian Karl, Patrick van der Smagt, and Jan Peters. Stable reinforcement learning with autoencoders for tactile and visual data. In2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2016, Daejeon, South Korea, October 9-14, 2016, pages 3928–3934. IEEE, 2016. doi: 10.1109/IROS.2016.7759578. URL ht...
-
[12]
Decoupling dynamics and reward for transfer learning
Amy Zhang, Harsh Satija, and Joelle Pineau. Decoupling dynamics and reward for transfer learning. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Workshop Track Proceedings. OpenReview.net, 2018. URLhttps://openreview.net/forum?id=H1aoddyvM
2018
-
[13]
Bellemare
Carles Gelada, Saurabh Kumar, Jacob Buckman, Ofir Nachum, and Marc G. Bellemare. Deep- mdp: Learning continuous latent space models for representation learning. In Kamalika 10 Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Con- ference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97...
2019
-
[14]
Jha, Toshisada Mariyama, and Daniel Nikovski
Kei Ota, Tomoaki Oiki, Devesh K. Jha, Toshisada Mariyama, and Daniel Nikovski. Can increasing input dimensionality improve deep reinforcement learning? InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceedings of Machine Learning Research, pages 7424–7433. PMLR,
2020
-
[15]
URLhttp://proceedings.mlr.press/v119/ota20a.html
-
[16]
Bootstrap latent-predictive representations for multitask reinforcement learning
Zhaohan Daniel Guo, Bernardo Ávila Pires, Bilal Piot, Jean-Bastien Grill, Florent Altché, Rémi Munos, and Mohammad Gheshlaghi Azar. Bootstrap latent-predictive representations for multitask reinforcement learning. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceedings of ...
2020
-
[17]
Devon Hjelm, Aaron C
Max Schwarzer, Ankesh Anand, Rishab Goel, R. Devon Hjelm, Aaron C. Courville, and Philip Bachman. Data-efficient reinforcement learning with self-predictive representations. In9th Inter- national Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7,
2021
-
[18]
URLhttps://openreview.net/forum?id=uCQfPZwRaUu
OpenReview.net, 2021. URLhttps://openreview.net/forum?id=uCQfPZwRaUu
2021
-
[19]
Smith, Shixiang Gu, Doina Precup, and David Meger
Scott Fujimoto, Wei-Di Chang, Edward J. Smith, Shixiang Gu, Doina Precup, and David Meger. For SALE: state-action representation learning for deep reinforcement learning. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Info...
2023
-
[20]
Towards general-purpose model-free reinforcement learning
Scott Fujimoto, Pierluca D’Oro, Amy Zhang, Yuandong Tian, and Michael Rabbat. Towards general-purpose model-free reinforcement learning. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URLhttps://openreview.net/forum?id=R1hIXdST22
2025
-
[21]
Batch normalization: Accelerating deep network training by reducing internal covariate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Francis R. Bach and David M. Blei, editors,Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015, volume 37 ofJMLR Workshop and Conference Proceedings, pages 448–456. ...
2015
-
[22]
URLhttp://proceedings.mlr.press/v37/ioffe15.html
-
[23]
Lei Jimmy Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.CoRR, abs/1607.06450, 2016. URLhttp://arxiv.org/abs/1607.06450
Pith/arXiv arXiv 2016
-
[24]
Gomes, and Kilian Q
Johan Bjorck, Carla P. Gomes, and Kilian Q. Weinberger. Towards deeper deep rein- forcement learning with spectral normalization. In Marc’Aurelio Ranzato, Alina Beygelz- imer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors,Ad- vances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing System...
2021
-
[25]
Spectral normalisation for deep reinforcement learning: An optimisation perspective
Florin Gogianu, Tudor Berariu, Mihaela Rosca, Claudia Clopath, Lucian Busoniu, and Razvan Pascanu. Spectral normalisation for deep reinforcement learning: An optimisation perspective. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 ofProceed...
2021
-
[26]
Normaliza- tion enhances generalization in visual reinforcement learning
Lu Li, Jiafei Lyu, Guozheng Ma, Zilin Wang, Zhenjie Yang, Xiu Li, and Zhiheng Li. Normaliza- tion enhances generalization in visual reinforcement learning. In Mehdi Dastani, Jaime Simão 11 Sichman, Natasha Alechina, and Virginia Dignum, editors,Proceedings of the 23rd Inter- national Conference on Autonomous Agents and Multiagent Systems, AAMAS 2024, Auck...
-
[27]
Image augmentation is all you need: Regular- izing deep reinforcement learning from pixels
Denis Yarats, Ilya Kostrikov, and Rob Fergus. Image augmentation is all you need: Regular- izing deep reinforcement learning from pixels. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URLhttps://openreview.net/forum?id=GY6-6sTvGaf
2021
-
[28]
Mastering visual continu- ous control: Improved data-augmented reinforcement learning
Denis Yarats, Rob Fergus, Alessandro Lazaric, and Lerrel Pinto. Mastering visual continu- ous control: Improved data-augmented reinforcement learning. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. Open- Review.net, 2022. URLhttps://openreview.net/forum?id=_SJ-_yyes8
2022
-
[29]
Stable-baselines3: Reliable reinforcement learning implementations.J
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-baselines3: Reliable reinforcement learning implementations.J. Mach. Learn. Res., 22:268:1–268:8, 2021. URLhttps://jmlr.org/papers/v22/20-1364.html
2021
-
[30]
Bridging state and history representations: Understanding self-predictive RL
Tianwei Ni, Benjamin Eysenbach, Erfan Seyedsalehi, Michel Ma, Clement Gehring, Aditya Mahajan, and Pierre-Luc Bacon. Bridging state and history representations: Understanding self-predictive RL. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview. net/...
2024
-
[31]
When does self-prediction help? understanding auxiliary tasks in reinforcement learning.RLJ, 4: 1567–1597, 2024
Claas V oelcker, Tyler Kastner, Igor Gilitschenski, and Amir-massoud Farahmand. When does self-prediction help? understanding auxiliary tasks in reinforcement learning.RLJ, 4: 1567–1597, 2024. URLhttps://rlj.cs.umass.edu/2024/papers/Paper197.html
2024
-
[32]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Jennifer G. Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 of...
2018
-
[33]
Balis, Gianluca De Cola, Tristan Deleu, Manuel Goulão, Andreas Kallinteris, Markus Krimmel, Arjun KG, Rodrigo Perez-Vicente, J
Mark Towers, Ariel Kwiatkowski, John U. Balis, Gianluca De Cola, Tristan Deleu, Manuel Goulão, Andreas Kallinteris, Markus Krimmel, Arjun KG, Rodrigo Perez-Vicente, J. K. Terry, Andrea Pierré, Sander Schulhoff, Jun Jet Tai, Hannah Tan, and Omar G. Younis. Gymnasium: A standard interface for reinforcement learning environments. In Danielle Belgrave, Cheng ...
2025
-
[34]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, Timothy P. Lillicrap, and Martin A. Riedmiller. Deepmind control suite.CoRR, abs/1801.00690, 2018. URL http://arxiv.org/ abs/1801.00690
Pith/arXiv arXiv 2018
-
[35]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http://arxiv.org/abs/1412.6980
Pith/arXiv arXiv 2015
-
[36]
Rainbow: Com- bining improvements in deep reinforcement learning
Matteo Hessel, Joseph Modayil, Hado van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Gheshlaghi Azar, and David Silver. Rainbow: Com- bining improvements in deep reinforcement learning. In Sheila A. McIlraith and Kilian Q. 12 Weinberger, editors,Proceedings of the Thirty-Second AAAI Conference on Artificial Intelli- ...
-
[37]
Robust estimation of a location parameter
Peter J Huber. Robust estimation of a location parameter. InBreakthroughs in statistics: Methodology and distribution, pages 492–518. Springer, 1992
1992
-
[38]
An equivalence between loss functions and non-uniform sampling in experience replay
Scott Fujimoto, David Meger, and Doina Precup. An equivalence between loss functions and non-uniform sampling in experience replay. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors,Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, ...
2020
-
[39]
Ried- miller
David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin A. Ried- miller. Deterministic policy gradient algorithms. InProceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 June 2014, volume 32 ofJMLR Workshop and Conference Proceedings, pages 387–395. JMLR.org, 2014. URL http://proce...
2014
-
[40]
Gomes, and Kilian Q
Johan Bjorck, Carla P. Gomes, and Kilian Q. Weinberger. Is high variance unavoidable in rl? A case study in continuous control. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=9xhgmsNVHu
2022
-
[41]
Multi-agent actor-critic for mixed cooperative-competitive environments
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference on N...
2017
-
[42]
Discrete off-policy policy gradient using continuous relaxations.Unpublished
Andre Cianflone, Zafarali Ahmed, Riashat Islam, Avishek Joey Bose, and William L Hamilton. Discrete off-policy policy gradient using continuous relaxations.Unpublished. https://joeybose. github. io/assets/Gradient_estimator. pdf, 2019
2019
-
[43]
Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling
Marc G. Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents (extended abstract). In Qiang Yang and Michael J. Wooldridge, editors,Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, July 25-31, 2015...
2015
-
[44]
Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Z. Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-pe...
2019
-
[45]
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2012, Vilamoura, Algarve, Portugal, October 7-12, 2012, pages 5026–5033. IEEE, 2012. doi: 10.1109/IROS.2012.6386109. URLhttps://doi.org/10.1109/IROS.2012.6386109. 13
-
[46]
Spectral normalization for generative adversarial networks
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. In6th International Conference on Learning Representa- tions, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceed- ings. OpenReview.net, 2018. URLhttps://openreview.net/forum?id=B1QRgziT-
2018
-
[47]
Dueling network architectures for deep reinforcement learning
Ziyu Wang, Tom Schaul, Matteo Hessel, Hado van Hasselt, Marc Lanctot, and Nando de Freitas. Dueling network architectures for deep reinforcement learning. In Maria-Florina Balcan and Kilian Q. Weinberger, editors,Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, volume 48 of JMLR Wor...
2016
-
[48]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman- Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URLhttps://github.com/jax-ml/jax
2018
-
[49]
Fast and accurate deep network learning by exponential linear units (elus)
Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). In Yoshua Bengio and Yann LeCun, editors,4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, 2016. URL http://arxiv.org/abs/1511. 07289
2016
-
[50]
Vinod Nair and Geoffrey E. Hinton. Rectified linear units improve restricted boltzmann machines. In Johannes Fürnkranz and Thorsten Joachims, editors,Proceedings of the 27th International Conference on Machine Learning (ICML-10), June 21-24, 2010, Haifa, Israel, pages 807–814. Omnipress, 2010. URL https://icml.cc/Conferences/2010/papers/ 432.pdf
2010
-
[51]
Deep sparse rectifier neural networks
Xavier Glorot, Antoine Bordes, and Yoshua Bengio. Deep sparse rectifier neural networks. In Geoffrey J. Gordon, David B. Dunson, and Miroslav Dudík, editors,Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2011, Fort Lauderdale, USA, April 11-13, 2011, volume 15 ofJMLR Proceedings, pages 315–323. JM...
2011
-
[52]
Lu Lu, Yeonjong Shin, Yanhui Su, and George E. Karniadakis. Dying relu and initialization: Theory and numerical examples.CoRR, abs/1903.06733, 2019. URL http://arxiv.org/ abs/1903.06733
arXiv 1903
-
[53]
Yann LeCun, Bernhard E. Boser, John S. Denker, Donnie Henderson, Richard E. Howard, Wayne E. Hubbard, and Lawrence D. Jackel. Backpropagation applied to handwritten zip code recognition.Neural Comput., 1(4):541–551, 1989. doi: 10.1162/NECO.1989.1.4.541. URL https://doi.org/10.1162/neco.1989.1.4.541
-
[54]
Proceedings of the IEEE , author =
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proc. IEEE, 86(11):2278–2324, 1998. doi: 10.1109/5.726791. URLhttps://doi.org/10.1109/5.726791
-
[55]
Zeiler, Dilip Krishnan, Graham W
Matthew D. Zeiler, Dilip Krishnan, Graham W. Taylor, and Robert Fergus. Deconvolutional networks. InThe Twenty-Third IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, CA, USA, 13-18 June 2010, pages 2528–2535. IEEE Computer Society, 2010. doi: 10.1109/CVPR.2010.5539957. URL https://doi.org/10.1109/CVPR. 2010.5539957. 14...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.