FAST: A Framework for Aligned Sampling and Training in Parallel Reinforcement Learning for Autonomous Driving
Pith reviewed 2026-06-26 14:07 UTC · model grok-4.3
The pith
FAST aligns parallel episode sampling in reinforcement learning by virtually continuing terminated runs and masking padding data to remove straggler delays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
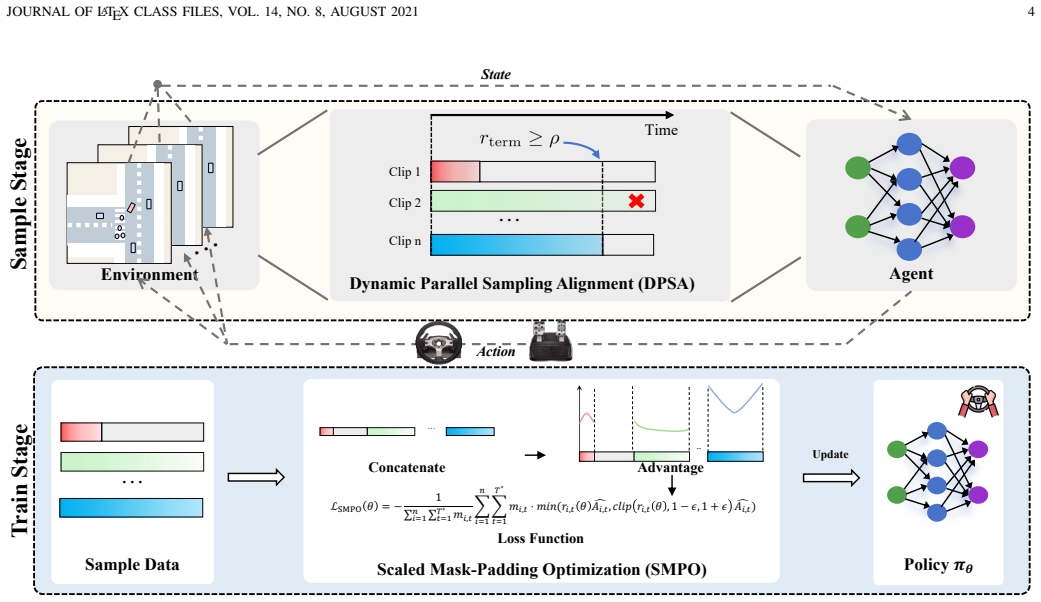
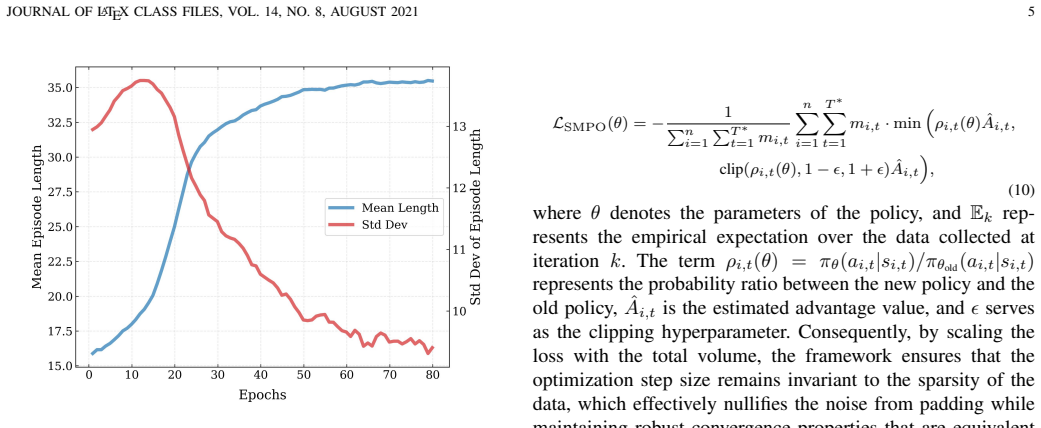
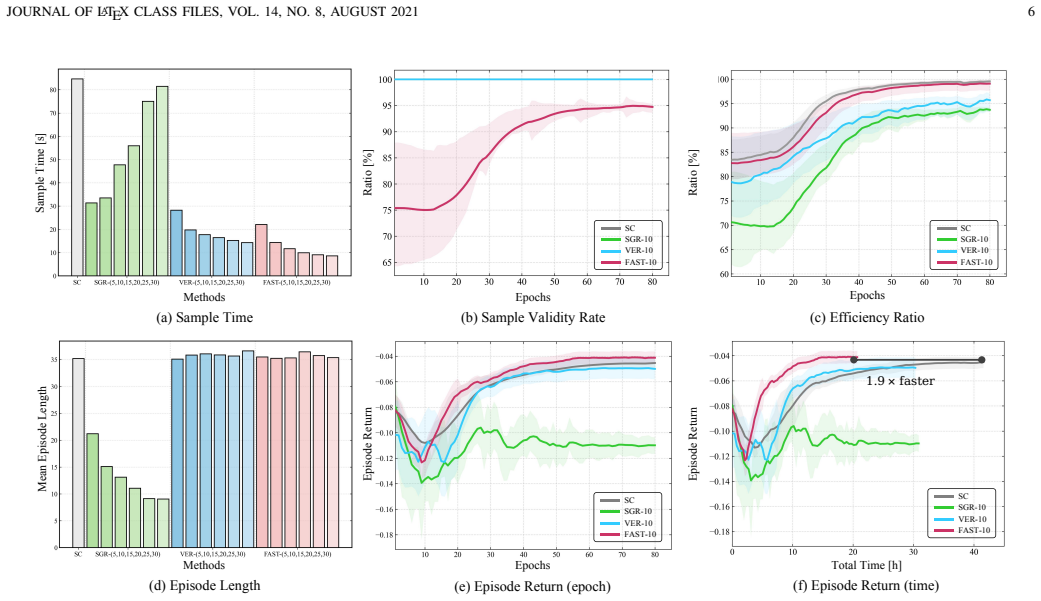
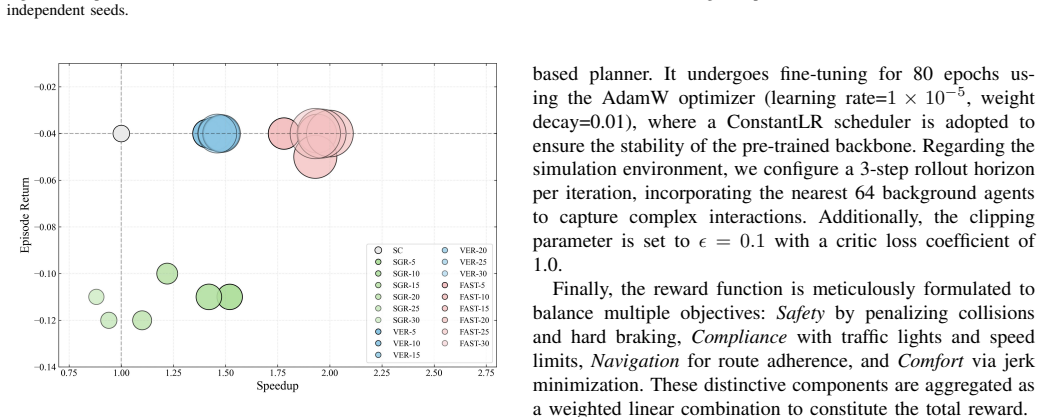
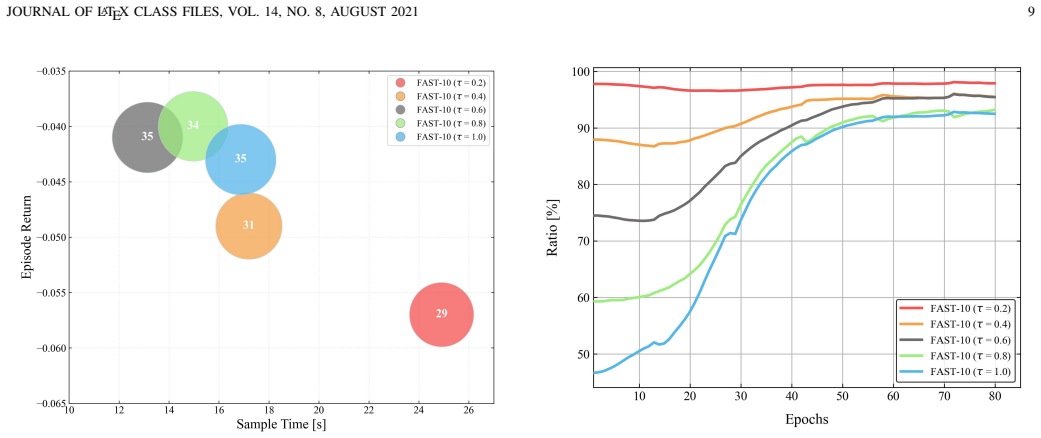
FAST achieves at least a 1.78 times wall-clock speedup over the single-clip baseline while preserving statistical unbiasedness by combining Dynamic Parallel Sampling Alignment, which extends terminated episodes via virtual continuation and applies dynamic global truncation, with Scaled Mask-Padding Optimization that uses validity masking and adaptive loss normalization to eliminate bias from the padding data.
What carries the argument
Dynamic Parallel Sampling Alignment (DPSA) that maintains vectorized synchronization through virtual episode continuation and termination-rate-based global truncation, paired with Scaled Mask-Padding Optimization (SMPO) that nullifies padding bias via validity masks and loss rescaling.
If this is right
- Wall-clock training time drops by a factor of at least 1.78 relative to the single-clip baseline.
- Statistical properties of the collected trajectories remain identical to those of unbiased single-clip sampling.
- Synchronization overhead from premature episode resets disappears while data diversity is retained.
- The framework applies directly to any closed-loop simulation that requires batched, synchronized rollouts.
Where Pith is reading between the lines
- The same alignment pattern could be tested on other variable-length parallel RL tasks such as robotics or game environments.
- Scaling the number of parallel environments beyond the reported setting would show whether the speedup remains linear.
- If virtual continuations systematically change the distribution of long-horizon returns, downstream policy quality could degrade even if short-term statistics appear unbiased.
Load-bearing premise
Extending terminated episodes with virtual continuation together with scaled mask-padding fully removes bias and keeps data diversity intact without creating new statistical artifacts.
What would settle it
A side-by-side run in which the policy trained on FAST data produces measurably different closed-loop driving performance or return distribution than the policy trained on standard single-clip data would show that the unbiasedness claim does not hold.
Figures

read the original abstract
Deep reinforcement learning is pivotal for closed-loop autonomous driving yet remains constrained by severe bottlenecks in sampling efficiency. Standard parallel sampling mitigates this but suffers from the straggler effect, where the premature termination of a single environment necessitates a synchronized batch re-initialization, leading to suboptimal sample utilization and prohibitive re-initialization latency. To address this, we propose FAST, a synchronous parallel framework tailored for closed-loop simulation. Specifically, FAST employs Dynamic Parallel Sampling Alignment (DPSA) to maintain vectorization synchronization by extending terminated episodes via virtual continuation, thereby decoupling the sampling loop from individual terminations. By dynamically triggering global truncation based on the termination rate of parallel clips, FAST effectively eliminates the bottleneck of premature resets without sacrificing data diversity. Furthermore, to strictly preserve theoretical consistency, we incorporate a Scaled Mask-Padding Optimization (SMPO) that leverages validity masking and adaptive loss normalization to nullify the bias from auxiliary padding data. Empirical evaluations demonstrate that FAST achieves at least a 1.78 times wall-clock speedup over the single-clip baseline while preserving statistical unbiasedness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FAST, a synchronous parallel RL framework for closed-loop autonomous driving. It introduces Dynamic Parallel Sampling Alignment (DPSA) that extends terminated episodes via virtual continuation to eliminate straggler-induced resets, and Scaled Mask-Padding Optimization (SMPO) that applies validity masking plus adaptive loss normalization to remove bias from the auxiliary padding data. The central empirical claim is a wall-clock speedup of at least 1.78× relative to a single-clip baseline while preserving statistical unbiasedness.
Significance. If the unbiasedness guarantee can be rigorously established, the approach would meaningfully improve sample utilization and wall-clock efficiency in vectorized simulators where episode lengths vary, a common bottleneck in autonomous-driving RL.
major comments (2)
- [Abstract / §3] Abstract and §3 (SMPO description): the claim that adaptive loss normalization 'nullifies the bias from auxiliary padding data' and restores theoretical consistency is asserted without a derivation. No equation is shown establishing that the scale factor computed from observed termination rates yields E[scaled loss | padding] = E[original loss] under the true episode-length measure; this is load-bearing for the unbiasedness claim.
- [§4] §4 (experimental setup): the reported 1.78× speedup is presented without controls that isolate the contribution of SMPO versus DPSA, nor verification that the padding distribution does not alter the effective sampling measure; the statistical tests confirming unbiasedness are not described.
minor comments (2)
- [§3] Notation for the validity mask and the adaptive normalization factor should be introduced with explicit definitions before their use in the loss.
- [Figures] Figure captions should state the number of random seeds and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and commit to revisions that strengthen the presentation of the unbiasedness guarantee and experimental controls.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (SMPO description): the claim that adaptive loss normalization 'nullifies the bias from auxiliary padding data' and restores theoretical consistency is asserted without a derivation. No equation is shown establishing that the scale factor computed from observed termination rates yields E[scaled loss | padding] = E[original loss] under the true episode-length measure; this is load-bearing for the unbiasedness claim.
Authors: We agree that the current manuscript lacks an explicit derivation for the unbiasedness property of SMPO. In the revised version we will insert a formal derivation in §3 that defines the scale factor from the observed termination rates and proves that E[scaled loss | padding] equals E[original loss] under the true episode-length distribution, including all intermediate equations. revision: yes
-
Referee: [§4] §4 (experimental setup): the reported 1.78× speedup is presented without controls that isolate the contribution of SMPO versus DPSA, nor verification that the padding distribution does not alter the effective sampling measure; the statistical tests confirming unbiasedness are not described.
Authors: We accept that the experimental section would benefit from additional controls and documentation. The revision will add ablation experiments in §4 that separately quantify the contributions of DPSA and SMPO, include explicit verification that the padding distribution preserves the original sampling measure, and describe the statistical tests (including test statistics and significance levels) used to confirm unbiasedness. revision: yes
Circularity Check
No significant circularity; claims rest on empirical evaluation and method description without self-referential reduction.
full rationale
The abstract and provided text describe DPSA for alignment via virtual continuation and SMPO for bias nullification via masking and normalization, asserting preservation of statistical unbiasedness and a 1.78x speedup. No equations, derivations, or self-citations are exhibited that reduce the unbiasedness claim or speedup to a fitted parameter renamed as prediction, a self-definition, or a load-bearing self-citation chain. The result is framed as an empirical outcome of the proposed framework rather than a mathematical identity forced by construction. This matches the default expectation for non-circular papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Reinforcement learning for sequential decision and optimal control,
S. E. Li, “Reinforcement learning for sequential decision and optimal control,” 2023. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10
2023
-
[2]
Long-and short-term constraint-driven safe reinforcement learning for autonomous driving,
X. Hu, P. Chen, Y . Wen, B. Tang, and L. Chen, “Long-and short-term constraint-driven safe reinforcement learning for autonomous driving,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2026
2026
-
[3]
Vlm-rl: A unified vision language models and reinforcement learning framework for safe autonomous driving,
Z. Huang, Z. Sheng, Y . Qu, J. You, and S. Chen, “Vlm-rl: A unified vision language models and reinforcement learning framework for safe autonomous driving,”Transportation Research Part C: Emerging Technologies, vol. 180, p. 105321, 2025
2025
-
[4]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[5]
Addressing corner cases in autonomous driving: A world model-based approach with mixture of experts and llms,
H. Liao, B. Wang, J. Yang, C. Wang, Z. He, G. Zhang, C. Xu, and Z. Li, “Addressing corner cases in autonomous driving: A world model-based approach with mixture of experts and llms,”Transportation Research Part C: Emerging Technologies, vol. 183, p. 105456, 2026
2026
-
[6]
Beyond patterns: harnessing causal logic for autonomous driving trajectory prediction,
B. Wang, H. Liao, C. Wang, B. Rao, Y . Guan, G. Yu, J. Zhang, S. Lai, C. Xu, and Z. Li, “Beyond patterns: harnessing causal logic for autonomous driving trajectory prediction,” inProceedings of the Thirty- Fourth International Joint Conference on Artificial Intelligence, 2025, pp. 9918–9926
2025
-
[7]
Carplanner: Consistent auto-regressive trajectory planning for large-scale reinforcement learning in autonomous driving,
D. Zhang, J. Liang, K. Guo, S. Lu, Q. Wang, R. Xiong, Z. Miao, and Y . Wang, “Carplanner: Consistent auto-regressive trajectory planning for large-scale reinforcement learning in autonomous driving,” inProceed- ings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 239–17 248
2025
-
[8]
Huang,Distributed reinforcement learning for autonomous driving
Z. Huang,Distributed reinforcement learning for autonomous driving. Carnegie Mellon University, 2022
2022
-
[9]
Centralized cooperation for connected and automated vehicles at intersections by proximal policy optimization,
Y . Guan, Y . Ren, S. E. Li, Q. Sun, L. Luo, and K. Li, “Centralized cooperation for connected and automated vehicles at intersections by proximal policy optimization,”IEEE Transactions on Vehicular Tech- nology, vol. 69, no. 11, pp. 12 597–12 608, 2020
2020
-
[10]
End-to-end driving via conditional imitation learning,
F. Codevilla, M. M ¨uller, A. L ´opez, V . Koltun, and A. Dosovitskiy, “End-to-end driving via conditional imitation learning,” in2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 4693–4700
2018
-
[11]
Carla: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “Carla: An open urban driving simulator,” inConference on robot learning. PMLR, 2017, pp. 1–16
2017
-
[12]
Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning,
Q. Li, Z. Peng, L. Feng, Q. Zhang, Z. Xue, and B. Zhou, “Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning,”IEEE transactions on pattern analysis and machine intelli- gence, vol. 45, no. 3, pp. 3461–3475, 2022
2022
-
[13]
Seed rl: Scalable and efficient deep-rl with accelerated central inference,
L. Espeholt, R. Marinier, P. Stanczyk, K. Wang, and M. Michalski, “Seed rl: Scalable and efficient deep-rl with accelerated central inference,” arXiv preprint arXiv:1910.06591, 2019
-
[14]
Impala: Scalable dis- tributed deep-rl with importance weighted actor-learner architectures,
L. Espeholt, H. Soyer, R. Munos, K. Simonyan, V . Mnih, T. Ward, Y . Doron, V . Firoiu, T. Harley, I. Dunninget al., “Impala: Scalable dis- tributed deep-rl with importance weighted actor-learner architectures,” inInternational conference on machine learning. PMLR, 2018, pp. 1407–1416
2018
-
[15]
Sample factory: Egocentric 3d control from pixels at 100000 fps with asynchronous reinforcement learning,
A. Petrenko, Z. Huang, T. Kumar, G. Sukhatme, and V . Koltun, “Sample factory: Egocentric 3d control from pixels at 100000 fps with asynchronous reinforcement learning,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 7652–7662
2020
-
[16]
Off-policy deep reinforcement learning without exploration,
S. Fujimoto, D. Meger, and D. Precup, “Off-policy deep reinforcement learning without exploration,” inInternational conference on machine learning. PMLR, 2019, pp. 2052–2062
2019
-
[17]
On-policy actor-critic re- inforcement learning for multiple unmanned aerial vehicle exploration,
A. M. Farid, J. Roshanian, and M. Mouhoub, “On-policy actor-critic re- inforcement learning for multiple unmanned aerial vehicle exploration,” Expert Systems with Applications, p. 131496, 2026
2026
-
[18]
Direct and indirect reinforcement learning,
Y . Guan, S. E. Li, J. Duan, J. Li, Y . Ren, Q. Sun, and B. Cheng, “Direct and indirect reinforcement learning,”International Journal of Intelligent Systems, vol. 36, no. 8, pp. 4439–4467, 2021
2021
-
[19]
Asmafl: Adaptive staleness-aware momentum asynchronous federated learning in edge computing,
D. Qiao, S. Guo, J. Zhao, J. Le, P. Zhou, M. Li, and X. Chen, “Asmafl: Adaptive staleness-aware momentum asynchronous federated learning in edge computing,”IEEE Transactions on Mobile Computing, vol. 24, no. 4, pp. 3390–3406, 2024
2024
-
[20]
Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,
E. Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essa, D. Parikh, M. Savva, and D. Batra, “Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,”arXiv preprint arXiv:1911.00357, 2019
-
[21]
Ray: A distributed framework for emerging{AI}applications,
P. Moritz, R. Nishihara, S. Wang, A. Tumanov, R. Liaw, E. Liang, M. Elibol, Z. Yang, W. Paul, M. I. Jordanet al., “Ray: A distributed framework for emerging{AI}applications,” in13th USENIX symposium on operating systems design and implementation (OSDI 18), 2018, pp. 561–577
2018
-
[22]
Time limits in reinforcement learning,
F. Pardo, A. Tavakoli, V . Levdik, and P. Kormushev, “Time limits in reinforcement learning,” inInternational Conference on Machine Learning. PMLR, 2018, pp. 4045–4054
2018
-
[23]
G. Brockman, V . Cheung, L. Pettersson, J. Schneider, J. Schul- man, J. Tang, and W. Zaremba, “Openai gym,”arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Gpudrive: Data-driven, multi-agent driving simulation at 1 million fps,
S. Kazemkhani, A. Pandya, D. Cornelisse, B. Shacklett, and E. Vinitsky, “Gpudrive: Data-driven, multi-agent driving simulation at 1 million fps,” arXiv preprint arXiv:2408.01584, 2024
-
[25]
Urban driver: Learning to drive from real-world demonstrations using policy gradients,
O. Scheel, L. Bergamini, M. Wolczyk, B. Osi ´nski, and P. Ondruska, “Urban driver: Learning to drive from real-world demonstrations using policy gradients,” inConference on Robot Learning. PMLR, 2022, pp. 718–728
2022
-
[26]
Parting with misconceptions about learning-based vehicle motion planning,
D. Dauner, M. Hallgarten, A. Geiger, and K. Chitta, “Parting with misconceptions about learning-based vehicle motion planning,” inCon- ference on Robot Learning. PMLR, 2023, pp. 1268–1281
2023
-
[27]
Nocturne: a scalable driving benchmark for bringing multi-agent learning one step closer to the real world,
E. Vinitsky, N. Lichtl ´e, X. Yang, B. Amos, and J. Foerster, “Nocturne: a scalable driving benchmark for bringing multi-agent learning one step closer to the real world,”Advances in neural information processing systems, vol. 35, pp. 3962–3974, 2022
2022
-
[28]
Smarts: Scalable multi-agent reinforcement learning training school for autonomous driving,
M. Zhou, J. Luo, J. Villella, Y . Yang, D. Rusu, J. Miao, W. Zhang, M. Alban, I. Fadakar, Z. Chenet al., “Smarts: Scalable multi-agent reinforcement learning training school for autonomous driving,”arXiv preprint arXiv:2010.09776, 2020
-
[29]
Envpool: A highly parallel reinforcement learning environment execution engine,
J. Weng, M. Lin, S. Huang, B. Liu, D. Makoviichuk, V . Makoviychuk, Z. Liu, Y . Song, T. Luo, Y . Jianget al., “Envpool: A highly parallel reinforcement learning environment execution engine,”Advances in Neural Information Processing Systems, vol. 35, pp. 22 409–22 421, 2022
2022
-
[30]
Brax-a differentiable physics engine for large scale rigid body simulation, 2021,
C. D. Freeman, E. Frey, A. Raichuk, S. Girgin, I. Mordatch, and O. Bachem, “Brax-a differentiable physics engine for large scale rigid body simulation, 2021,”URL http://github. com/google/brax, vol. 6, 2021
2021
-
[31]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano- Munoz, X. Yao, R. Zurbr ¨ugg, N. Rudinet al., “Isaac lab: A gpu- accelerated simulation framework for multi-modal robot learning,”arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Phasic policy gradient,
K. W. Cobbe, J. Hilton, O. Klimov, and J. Schulman, “Phasic policy gradient,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 2020–2027
2021
-
[33]
Ver: Scaling on-policy rl leads to the emergence of navigation in embodied rearrangement,
E. Wijmans, I. Essa, and D. Batra, “Ver: Scaling on-policy rl leads to the emergence of navigation in embodied rearrangement,”Advances in Neural Information Processing Systems, vol. 35, pp. 7727–7740, 2022
2022
-
[34]
Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
R. Qin, W. He, W. Huang, Y . Zhang, Y . Zhao, B. Pang, X. Xu, Y . Shan, Y . Wu, and M. Zhang, “Seer: Online context learning for fast syn- chronous llm reinforcement learning,”arXiv preprint arXiv:2511.14617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Resampling data: Using a statistical jackknife,
S. Sawyer, “Resampling data: Using a statistical jackknife,”Washington Univ.,¡ www. math. wustl. edu/˜ sawyer/handouts/jackknife. pdf, 2005
2005
-
[37]
Jackknife model averaging,
B. E. Hansen and J. S. Racine, “Jackknife model averaging,”Journal of Econometrics, vol. 167, no. 1, pp. 38–46, 2012. Bonan Wangis a research assistant at the School of Vehicle and Mobility, Tsinghua University, Beijing, China. Prior to this, he received his M.S. degree from the State Key Laboratory of Internet of Things for Smart City and the Department ...
2012
-
[38]
degree in Data Science and Big Data Technology from Shaanxi University of Science & Technology in 2023
He earned his B.S. degree in Data Science and Big Data Technology from Shaanxi University of Science & Technology in 2023. His research primarily focuses on autonomous driving and rein- forcement learning. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11 Letian Taoreceived the B.S. degree from the School of Vehicle and Mobility, Tsinghua Unive...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.