Zero-shot Transfer of Reinforcement Learning Control Policies for the Swing-Up and Stabilization of a Cart-Pole System
Pith reviewed 2026-06-26 11:37 UTC · model grok-4.3
The pith
Reinforcement learning policies for cart-pole swing-up and stabilization transfer zero-shot from simulation to hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that pairing a bandwidth-aware first-order action smoothing filter with sensitivity-guided domain randomization and a simple linear curriculum learning schedule produces a swing-up policy that injects enough energy for handoff into the stabilizer's region of attraction; the stabilization policy then rejects disturbances within the tested range on hardware, and the swing-up policy can re-engage after larger perturbations to restore the inverted position.
What carries the argument
The combination of first-order action smoothing filter, sensitivity-guided domain randomization, and linear curriculum learning schedule that together enable zero-shot sim-to-real transfer of the two independently trained RL policies.
If this is right
- The swing-up policy consistently reaches the region where the stabilizer can take over.
- The stabilization policy maintains the inverted position against disturbances inside the tested range.
- After larger disturbances the swing-up policy can resume and restore the pendulum to the upright position without manual intervention.
Where Pith is reading between the lines
- The separation into two policies with explicit handoff logic may simplify learning compared with training a single policy for the entire task.
- Sensitivity-guided randomization could be applied to other underactuated systems where a few key parameters dominate uncertainty.
- The bandwidth-aware filter might be necessary for any high-frequency RL policy that must run on torque-limited hardware.
Load-bearing premise
The simulation environment with sensitivity-guided domain randomization and curriculum learning sufficiently captures the essential dynamics, uncertainties, and hardware variations of the physical cart-pole system.
What would settle it
Running the transferred swing-up policy on the physical hardware and observing that it fails to inject sufficient energy to reach the stabilizer's region of attraction, or that the stabilization policy cannot reject small tested disturbances.
Figures



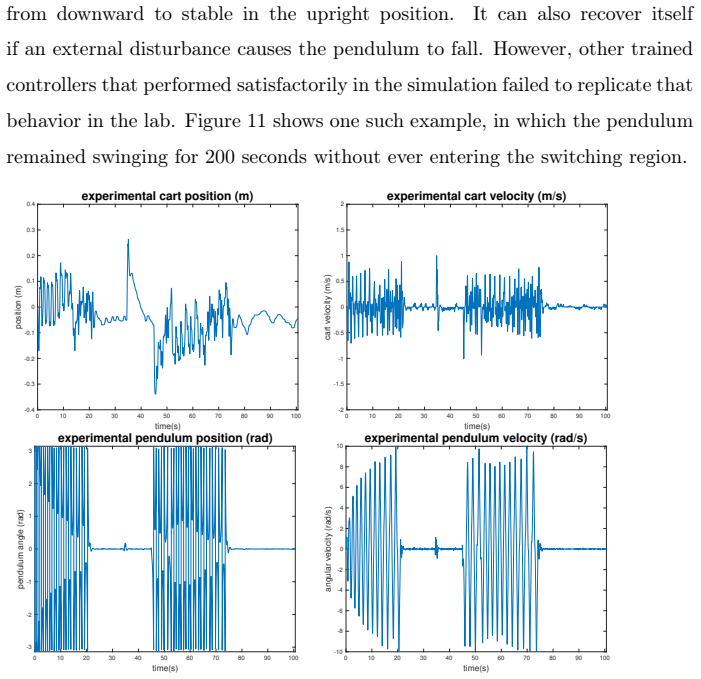
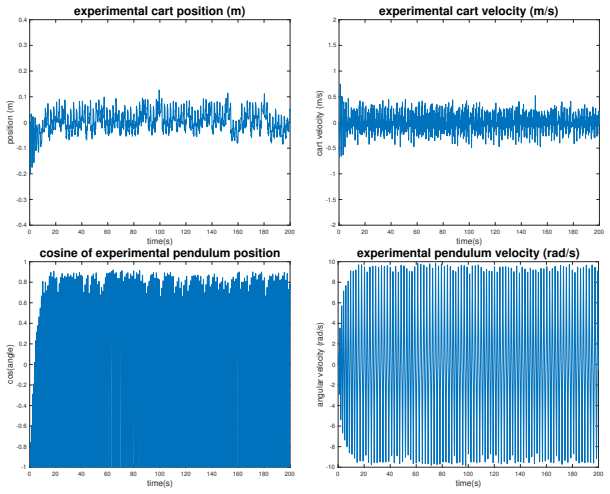
read the original abstract
Reinforcement learning (RL) is a powerful and convenient tool to modernize controller design. In this work, we study the zero-shot transfer of RL-based control policies from simulation to hardware for cart-pole swing-up and stabilization. The two policies are trained independently, and the handoff is implemented in Simulink via switching logic. We apply a first-order action smoothing filter to prevent hardware damage from high-frequency oscillatory actuation. Pairing this bandwidth-aware filtering with sensitivity-guided domain randomization (DR) and a simple linear curriculum learning (CL) schedule, we obtain a swing-up policy that in all of our experiments injects sufficient energy for handoff into the stabilizer's region of attraction. The stabilization policy rejects disturbances within the tested range, and the swing-up policy can re-engage after larger perturbations and restores the pendulum to the inverted position.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that two independently trained RL policies for cart-pole swing-up and stabilization, using sensitivity-guided domain randomization, linear curriculum learning, and a first-order action smoothing filter, achieve reliable zero-shot transfer to hardware. The swing-up policy is asserted to always inject sufficient energy for handoff into the stabilizer's region of attraction, while the stabilizer rejects tested disturbances and the swing-up policy can re-engage after larger perturbations.
Significance. If the zero-shot transfer claims were supported by quantitative evidence, the work would offer a concrete demonstration of practical sim-to-real RL control for an underactuated system, showing how filtering, targeted DR, and simple CL can enable handoff and disturbance rejection without fine-tuning.
major comments (2)
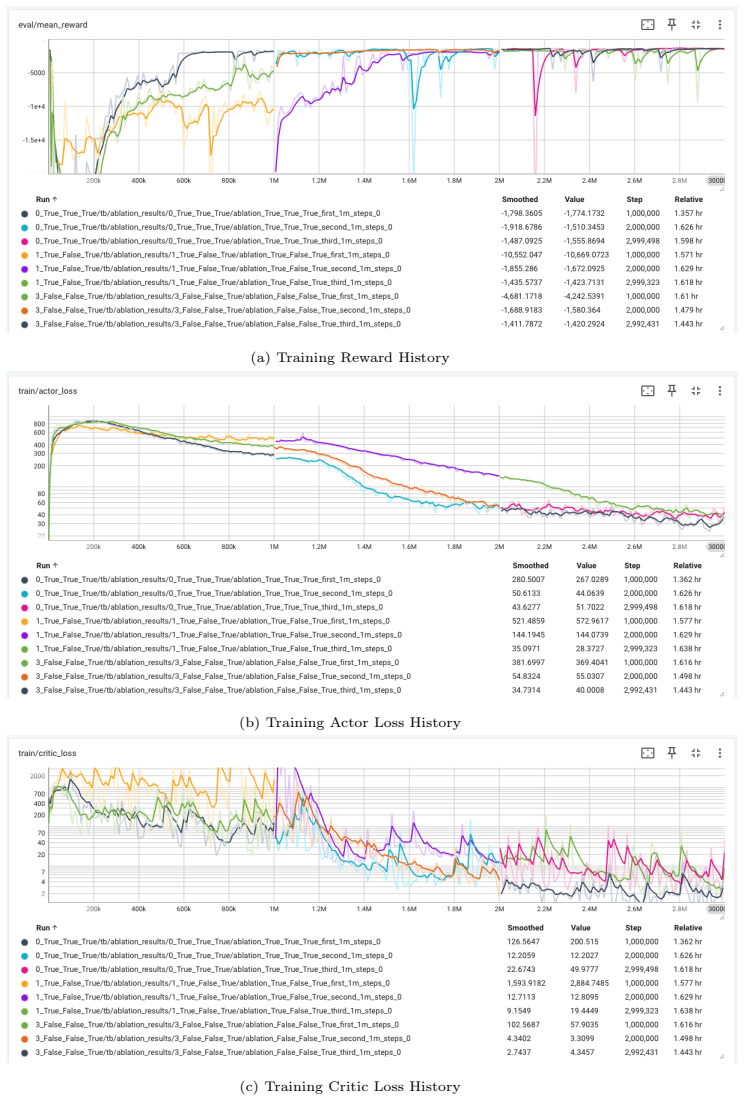
- [Abstract] Abstract: The assertion that the policies succeed 'in all of our experiments' for energy injection, disturbance rejection, and re-engagement supplies no quantitative metrics, trial counts, success rates, error bars, or specific disturbance ranges. This absence makes the central zero-shot transfer claim impossible to evaluate.
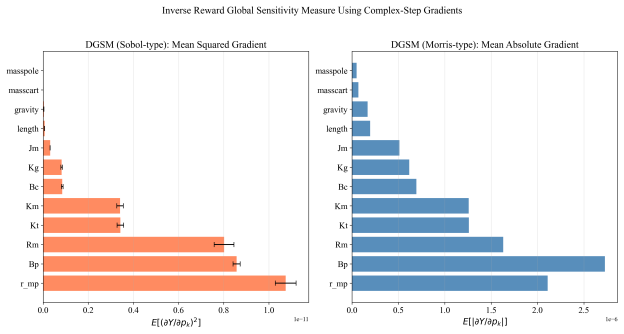
- [Domain Randomization / Methods] The description of sensitivity-guided domain randomization provides no details on which parameters were selected by the sensitivity analysis, the numerical ranges or distributions used for randomization, or any validation against measured hardware values (cart mass, pole inertia, friction, motor constant, sensor noise). Without this mapping, it cannot be determined whether the reported transfer reflects genuine robustness or coincidence with the physical system lying inside the randomized envelope.
minor comments (1)
- [Abstract] The abstract refers to 'bandwidth-aware filtering' without defining the filter's cutoff frequency, implementation details, or how bandwidth awareness is achieved.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in quantitative reporting and methodological detail that limit evaluation of the zero-shot transfer claims. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the policies succeed 'in all of our experiments' for energy injection, disturbance rejection, and re-engagement supplies no quantitative metrics, trial counts, success rates, error bars, or specific disturbance ranges. This absence makes the central zero-shot transfer claim impossible to evaluate.
Authors: We agree that the abstract and main text currently rely on qualitative statements without supporting quantitative data. In the revised manuscript we will add explicit metrics, including the total number of hardware trials performed, success rates for swing-up energy injection and stabilization, the specific disturbance ranges and magnitudes tested, and any available statistical measures or error bars. revision: yes
-
Referee: [Domain Randomization / Methods] The description of sensitivity-guided domain randomization provides no details on which parameters were selected by the sensitivity analysis, the numerical ranges or distributions used for randomization, or any validation against measured hardware values (cart mass, pole inertia, friction, motor constant, sensor noise). Without this mapping, it cannot be determined whether the reported transfer reflects genuine robustness or coincidence with the physical system lying inside the randomized envelope.
Authors: We acknowledge the methods section is insufficiently detailed on this point. The revised version will specify the parameters chosen via sensitivity analysis, the exact numerical ranges and probability distributions used for each randomized parameter, and any direct comparisons or validation steps performed against measured hardware quantities such as cart mass, pole inertia, friction, motor constant, and sensor noise. revision: yes
Circularity Check
No circularity: purely empirical RL transfer study with no derivations or self-referential reductions
full rationale
The paper reports an empirical RL experiment on cart-pole swing-up and stabilization using domain randomization, curriculum learning, and action filtering. No equations, parameter fits, uniqueness theorems, or derivation chains are present in the provided text. The central claim is a measured hardware transfer success rate under the stated training procedure; this does not reduce to any input by construction, self-citation, or renaming. The work is self-contained against external benchmarks (physical hardware runs) and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (2)
- Sensitivity-guided DR parameters
- Linear CL schedule parameters
axioms (1)
- domain assumption The physical cart-pole dynamics and uncertainties are adequately represented by the sensitivity-guided randomized simulation model
Reference graph
Works this paper leans on
-
[1]
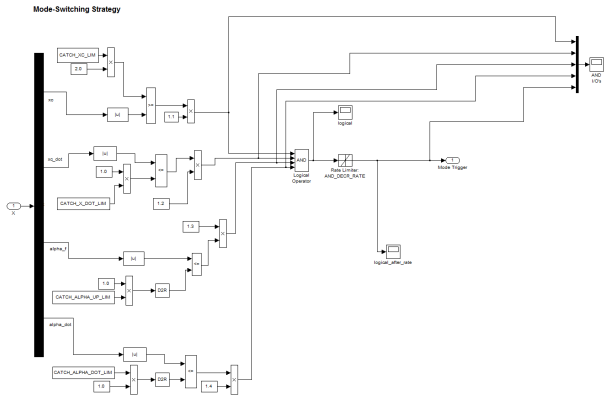
K. J. Åström, K. Furuta, Swinging up a pendulum by energy control, Au- tomatica 36 (2) (2000) 287–295.doi:10.1016/S0005-1098(99)00140-5. URLhttps://www.sciencedirect.com/science/article/pii/ S0005109899001405 33
-
[2]
M.-S. Park, D. Chwa, Swing-Up and Stabilization Control of Inverted- Pendulum Systems via Coupled Sliding-Mode Control Method, IEEE Transactions on Industrial Electronics 56 (9) (2009) 3541–3555.doi: 10.1109/TIE.2009.2012452. URLhttps://ieeexplore.ieee.org/document/4752767/
-
[3]
M. Tum, G. Gyeong, J. H. Park, Y. S. Lee, Swing-up control of a sin- gle inverted pendulum on a cart with input and output constraints, in: 2014 11th International Conference on Informatics in Control, Automa- tion and Robotics (ICINCO), Vol. 01, 2014, pp. 475–482.doi:10.5220/ 0005018604750482. URLhttps://ieeexplore.ieee.org/document/7049813
arXiv 2014
-
[4]
E. Kennedy, E. King, H. Tran, Real-time implementation and analysis of a modified energy based controller for the swing-up of an inverted pendulum on a cart, European Journal of Control 50 (2019) 176–187. doi:10.1016/j.ejcon.2019.05.002. URLhttps://www.sciencedirect.com/science/article/pii/ S0947358018301201
-
[5]
J. L. C. Miranda, Application of Kalman Filtering and PID Control for Direct Inverted Pendelum Control
-
[6]
S. Ozana, M. Pies, Z. Slanina, R. Hajovsky, Design and implementation of LQR controller for inverted pendulum by use of REX control system, in: 2012 12th International Conference on Control, Automation and Systems, 2012, pp. 343–347. URLhttps://ieeexplore.ieee.org/document/6393459
arXiv 2012
-
[7]
E. A. Kennedy, H. T. Tran, Real-Time Stabilization of a Single Inverted Pendulum Using a Power Series Based Controller, in: G.-C. Yang, S.-I. Ao, X. Huang, O. Castillo (Eds.), Transactions on Engineering Technologies, Springer, Singapore, 2016, pp.1–14.doi:10.1007/978-981-10-0551-0_1. 34
-
[8]
A. Jezierski, J. Mozaryn, D. Suski, A Comparison of LQR and MPC Con- trol Algorithms of an Inverted Pendulum, in: W. Mitkowski, J. Kacprzyk, K. Oprzedkiewicz, P. Skruch (Eds.), Trends in Advanced Intelligent Con- trol, Optimization and Automation, Springer International Publishing, Cham, 2017, pp. 65–76.doi:10.1007/978-3-319-60699-6_8
-
[9]
Abeysekera, I
B. Abeysekera, I. L. Wanniarachchi, Modelling and Implementation of PID Control for Balancing of an Inverted Pendulum, 2018. URLhttps://api.semanticscholar.org/CorpusID:189859429
2018
-
[10]
M. Riedmiller, Neural reinforcement learning to swing-up and balance a real pole, in: 2005 IEEE International Conference on Systems, Man and Cybernetics, Vol. 4, 2005, pp. 3191–3196 Vol. 4.doi:10.1109/ICSMC. 2005.1571637. URLhttps://ieeexplore.ieee.org/document/1571637
-
[11]
J. Mattner, S. Lange, M. Riedmiller, Learn to Swing Up and Balance a Real Pole Based on Raw Visual Input Data, in: T. Huang, Z. Zeng, C. Li, C. S. Leung (Eds.), Neural Information Processing, Springer, Berlin, Heidelberg, 2012, pp. 126–133.doi:10.1007/978-3-642-34500-5_16
-
[12]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Sil- ver, D. Wierstra, Continuous control with deep reinforcement learning, arXiv:1509.02971 [cs, stat] (Jul. 2019). URLhttp://arxiv.org/abs/1509.02971
Pith/arXiv arXiv 2019
-
[13]
R. Sutton, A. Barto, R. Williams, Reinforcement learning is direct adaptive optimal control, IEEE Control Systems Magazine 12 (2) (1992) 19–22, con- ference Name: IEEE Control Systems Magazine.doi:10.1109/37.126844. URLhttps://ieeexplore.ieee.org/abstract/document/126844
-
[14]
F. L. Lewis, D. L. Vrabie, V. L. Syrmos, Optimal Control, 3rd Edition, Wiley, 2012.doi:10.1002/9781118122631. URLhttps://onlinelibrary.wiley.com/doi/book/10.1002/ 9781118122631 35
-
[15]
A. S. Polydoros, L. Nalpantidis, Survey of Model-Based Reinforcement Learning: Applications on Robotics, Journal of Intelligent & Robotic Sys- tems 86 (2) (2017) 153–173.doi:10.1007/s10846-017-0468-y. URLhttps://doi.org/10.1007/s10846-017-0468-y
-
[16]
B. Recht, A Tour of Reinforcement Learning: The View from Continuous Control, Annual Review of Control, Robotics, and Autonomous Systems 2 (Volume 2, 2019) (2019) 253–279.doi: 10.1146/annurev-control-053018-023825. URLhttps://www.annualreviews.org/content/journals/10.1146/ annurev-control-053018-023825
-
[17]
W. Zhao, J. P. Queralta, T. Westerlund, Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: a Survey, in: 2020 IEEE Sympo- sium Series on Computational Intelligence (SSCI), 2020, pp. 737–744. doi:10.1109/SSCI47803.2020.9308468. URLhttps://ieeexplore.ieee.org/document/9308468/?arnumber= 9308468
-
[18]
F. Muratore, F. Ramos, G. Turk, W. Yu, M. Gienger, J. Peters, Robot Learning From Randomized Simulations: A Review, Frontiers in Robotics and AI 9 (Apr. 2022).doi:10.3389/frobt.2022.799893. URLhttps://www.frontiersin.org/journals/robotics-and-ai/ articles/10.3389/frobt.2022.799893/full
-
[19]
Pinto, J
L. Pinto, J. Davidson, R. Sukthankar, A. Gupta, Robust Adversarial Rein- forcement Learning, in: Proceedings of the 34th International Conference on Machine Learning, PMLR, 2017, pp. 2817–2826. URLhttps://proceedings.mlr.press/v70/pinto17a.html
2017
-
[20]
A. A. Rusu, M. Vecerik, T. Rothörl, N. Heess, R. Pascanu, R. Had- sell, Sim-to-Real Robot Learning from Pixels with Progressive Nets, arXiv:1610.04286 [cs] (May 2018).doi:10.48550/arXiv.1610.04286. URLhttp://arxiv.org/abs/1610.04286 36
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1610.04286 2018
-
[23]
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, P. Abbeel, Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World, arXiv:1703.06907 [cs] (Mar. 2017).doi:10.48550/arXiv. 1703.06907. URLhttp://arxiv.org/abs/1703.06907
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2017
-
[24]
X. B. Peng, M. Andrychowicz, W. Zaremba, P. Abbeel, Sim-to-Real Trans- fer of Robotic Control with Dynamics Randomization, in: 2018 IEEE In- ternational Conference on Robotics and Automation (ICRA), 2018, pp. 3803–3810, arXiv:1710.06537 [cs].doi:10.1109/ICRA.2018.8460528. URLhttp://arxiv.org/abs/1710.06537
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/icra.2018.8460528 2018
-
[25]
Muratore, F
F. Muratore, F. Treede, M. Gienger, J. Peters, Domain Randomization for Simulation-Based Policy Optimization with Transferability Assessment, in: Proceedings of The 2nd Conference on Robot Learning, PMLR, 2018, pp. 700–713. URLhttps://proceedings.mlr.press/v87/muratore18a.html
2018
-
[26]
F. Muratore, C. Eilers, M. Gienger, J. Peters, Data-efficient Domain Ran- domization with Bayesian Optimization, IEEE Robotics and Automation Letters 6 (2) (2021) 911–918, arXiv:2003.02471 [cs].doi:10.1109/LRA. 2021.3052391. URLhttp://arxiv.org/abs/2003.02471 37
work page doi:10.1109/lra 2021
-
[27]
Imbalanced data problem in machine learning: A review,
A. Shakerimov, T. Alizadeh, H. A. Varol, Efficient Sim-to-Real Transfer in Reinforcement Learning Through Domain Randomization and Domain Adaptation, IEEEAccess11(2023)136809–136824.doi:10.1109/ACCESS. 2023.3339568. URLhttps://ieeexplore.ieee.org/abstract/document/10343164
-
[28]
Y. Bengio, J. Louradour, R. Collobert, J. Weston, Curriculum learning, in: Proceedings of the 26th Annual International Conference on Machine Learning, ICML’09, AssociationforComputingMachinery, NewYork, NY, USA, 2009, pp. 41–48.doi:10.1145/1553374.1553380. URLhttps://dl.acm.org/doi/10.1145/1553374.1553380
-
[29]
S. Narvekar, B. Peng, M. Leonetti, J. Sinapov, M. E. Taylor, P. Stone, Cur- riculum Learning for Reinforcement Learning Domains: A Framework and Survey, arXiv:2003.04960 [cs] (Sep. 2020).doi:10.48550/arXiv.2003. 04960. URLhttp://arxiv.org/abs/2003.04960
-
[30]
I. Marougkas, D. M. Ramesh, J. H. Doerr, E. Granados, A. Sivaramakr- ishnan, A. Boularias, K. E. Bekris, Integrating Model-based Control and RL for Sim2Real Transfer of Tight Insertion Policies, arXiv:2505.11858 [cs] (May 2025).doi:10.48550/arXiv.2505.11858. URLhttp://arxiv.org/abs/2505.11858
-
[31]
X. Chen, J. Hu, C. Jin, L. Li, L. Wang, Understanding Domain Ran- domization for Sim-to-real Transfer, arXiv:2110.03239 [cs] (Mar. 2022). doi:10.48550/arXiv.2110.03239. URLhttp://arxiv.org/abs/2110.03239
- [32]
-
[33]
T. Westenbroek, F. Castaneda, A. Agrawal, S. Sastry, K. Sreenath, Lya- punov Design for Robust and Efficient Robotic Reinforcement Learning, arXiv:2208.06721 [cs] (Nov. 2022).doi:10.48550/arXiv.2208.06721. URLhttp://arxiv.org/abs/2208.06721
-
[34]
Wagenmaker, K
A. Wagenmaker, K. Huang, L. Ke, K. Jamieson, A. Gupta, Overcoming the Sim-to-Real Gap: Leveraging Simulation to Learn to Explore for Real-World RL, Advances in Neural Information Processing Systems 37 (2024) 78715–78765. URLhttps://proceedings.neurips.cc/paper_files/paper/2024/ hash/8fa068ffe59817175d176bd75641fe16-Abstract-Conference. html
2024
-
[35]
N. Xu, H. Tran, Control Synthesis with Reinforcement Learning: A Mod- eling Perspective, arXiv:2510.25063 [eess] (Dec. 2025).doi:10.48550/ arXiv.2510.25063. URLhttp://arxiv.org/abs/2510.25063
Pith/arXiv arXiv 2025
-
[36]
W. H. Hayt, J. E. Kemmerly, S. M. Durbin, J. E. Kemmerly, Engineering circuit analysis, 8th Edition, McGraw-Hill, New York, NY, 2012
2012
-
[37]
BayesSim: adaptive domain randomization via probabilistic inference for robotics simulators
F. Ramos, R. C. Possas, D. Fox, BayesSim: adaptive domain randomiza- tion via probabilistic inference for robotics simulators, arXiv:1906.01728 [cs] (Jun. 2019).doi:10.48550/arXiv.1906.01728. URLhttp://arxiv.org/abs/1906.01728
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.01728 1906
-
[38]
F. Muratore, M. Gienger, J. Peters, Assessing Transferability From Simu- lation to Reality for Reinforcement Learning, IEEE Transactions on Pat- tern Analysis and Machine Intelligence 43 (4) (2021) 1172–1183.doi: 10.1109/TPAMI.2019.2952353. URLhttps://ieeexplore.ieee.org/abstract/document/8894399
-
[39]
Y. Zhong, W. Zhou, Z. Wang, A Survey of Data Augmentation in Domain Generalization, Neural Processing Letters 57 (2) (2025) 34.doi:10.1007/ 39 s11063-025-11747-9. URLhttps://doi.org/10.1007/s11063-025-11747-9
-
[40]
Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, K. Sreenath, Reinforce- ment Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control, arXiv:2401.16889 [cs] (Aug. 2024).doi:10.48550/arXiv.2401. 16889. URLhttp://arxiv.org/abs/2401.16889
-
[41]
https://doi.org/10.48550/arXiv.2502.08844
K. Zakka, B. Tabanpour, Q. Liao, M. Haiderbhai, S. Holt, J. Y. Luo, A. Allshire, E. Frey, K. Sreenath, L. A. Kahrs, C. Sferrazza, Y. Tassa, P. Abbeel, MuJoCo Playground, arXiv:2502.08844 [cs] version: 1 (Feb. 2025).doi:10.48550/arXiv.2502.08844. URLhttp://arxiv.org/abs/2502.08844
-
[42]
2019).doi:10.48550/ arXiv.1909.10449
Y.Zhong, A.A.Deshmukh, C.Scott, PACReinforcementLearningwithout Real-World Feedback, arXiv:1909.10449 [cs] (Oct. 2019).doi:10.48550/ arXiv.1909.10449. URLhttp://arxiv.org/abs/1909.10449
arXiv 1909
-
[43]
M. Towers, J. K. Terry, A. Kwiatkowski, J. U. Balis, G. De Cola, T. Deleu, M.Goulão, A.Kallinteris, A.KG,M.Krimmel, R.Perez-Vicente, A.Pierré, S. Schulhoff, J. J. Tai, A. T. J. Shen, O. G. Younis, Gymnasium, language: en (Mar. 2023).doi:10.5281/ZENODO.8127026. URLhttps://zenodo.org/record/8127026
-
[44]
R. J. Williams, Simple statistical gradient-following algorithms for con- nectionist reinforcement learning, Machine Learning 8 (3) (1992) 229–256. doi:10.1007/BF00992696. URLhttps://doi.org/10.1007/BF00992696
-
[45]
Dozat, Incorporating Nesterov Momentum into Adam (Feb
T. Dozat, Incorporating Nesterov Momentum into Adam (Feb. 2016). URLhttps://openreview.net/forum?id=OM0jvwB8jIp57ZJjtNEZ 40
2016
-
[46]
Addressing Function Approximation Error in Actor-Critic Methods
S. Fujimoto, H. v. Hoof, D. Meger, Addressing Function Approximation Error in Actor-Critic Methods, arXiv:1802.09477 [cs] (Oct. 2018).doi: 10.48550/arXiv.1802.09477. URLhttp://arxiv.org/abs/1802.09477
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.09477 2018
-
[47]
Raffin, A
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, N. Dor- mann, Stable-Baselines3: Reliable Reinforcement Learning Implementa- tions, Journal of Machine Learning Research 22 (268) (2021) 1–8. URLhttp://jmlr.org/papers/v22/20-1364.html
2021
-
[48]
J. N. Lyness, C. B. Moler, Numerical Differentiation of Analytic Functions, SIAM Journal on Numerical Analysis 4 (2) (1967) 202–210. URLhttps://www.jstor.org/stable/2949389
arXiv 1967
-
[49]
W. Squire, G. Trapp, Using Complex Variables to Estimate Derivatives of Real Functions, SIAM Review 40 (1) (1998) 110–112.doi:10.1137/ S003614459631241X. URLhttps://epubs.siam.org/doi/abs/10.1137/S003614459631241X
-
[50]
J. R. R. A. Martins, I. Kroo, J. Alonso, An automated method for sen- sitivity analysis using complex variables, in: 38th Aerospace Sciences Meeting and Exhibit, American Institute of Aeronautics and Astronau- tics, Reno,NV,U.S.A., 2000.doi:10.2514/6.2000-689. URLhttps://arc.aiaa.org/doi/10.2514/6.2000-689
-
[51]
H. T. Banks, K. Bekele-Maxwell, L. Bociu, M. Noorman, K. Tillman, The complex-step method for sensitivity analysis of non-smooth problems aris- ing in biology, Eurasian Journal of Mathematical and Computer Applica- tions 3 (2015) 15–68
2015
-
[52]
Bradbury, R
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, Y. Katariya, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, Q. Zhang, JAX: composable transformations of Python+NumPy programs (2018). URLhttp://github.com/jax-ml/jax 41
2018
-
[53]
I. M. Sobol’, S. Kucherenko, Derivative based global sensitiv- ity measures and their link with global sensitivity indices, Math- ematics and Computers in Simulation 79 (10) (2009) 3009–3017. doi:10.1016/j.matcom.2009.01.023. URLhttps://www.sciencedirect.com/science/article/pii/ S0378475409000354
-
[54]
S. Kucherenko, S. Song, Derivative-Based Global Sensitivity Measures and Their Link with Sobol’ Sensitivity Indices, in: R. Cools, D. Nuyens (Eds.), Monte Carlo and Quasi-Monte Carlo Methods, Springer International Pub- lishing, Cham, 2016, pp. 455–469.doi:10.1007/978-3-319-33507-0_23
-
[55]
A. Alexanderian, P. A. Gremaud, R. C. Smith, Variance-based sensitivity analysis for time-dependent processes, Reliability Engineering & System Safety 196 (2020) 106722.doi:10.1016/j.ress.2019.106722. URLhttps://www.sciencedirect.com/science/article/pii/ S0951832019303837
-
[56]
K. Chatzilygeroudis, V. Vassiliades, F. Stulp, S. Calinon, J.-B. Mouret, A Survey on Policy Search Algorithms for Learning Robot Controllers in a Handful of Trials, IEEE Transactions on Robotics 36 (2) (2020) 328–347, conference Name: IEEE Transactions on Robotics.doi:10.1109/TRO. 2019.2958211. URLhttps://ieeexplore.ieee.org/abstract/document/8944013
work page doi:10.1109/tro 2020
-
[57]
D. Liberzon, Switching in Systems and Control, Systems & Control: Foun- dations & Applications, Birkhäuser, Boston, MA, 2003.doi:10.1007/ 978-1-4612-0017-8. URLhttp://link.springer.com/10.1007/978-1-4612-0017-8 42
-
[58]
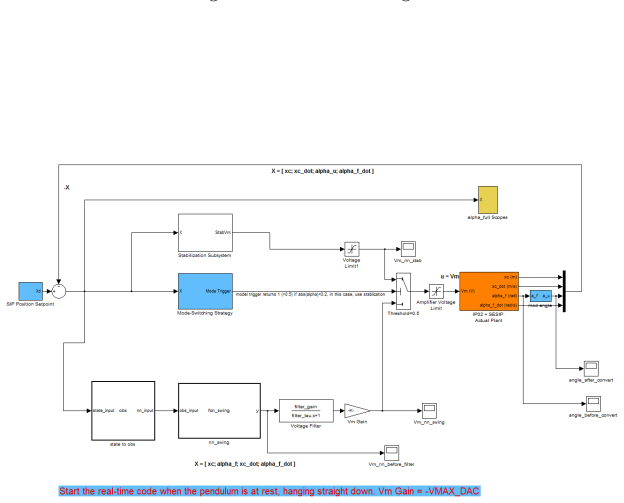
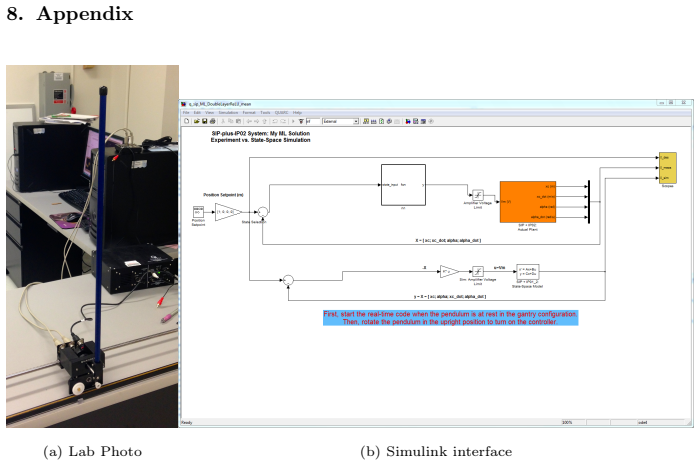
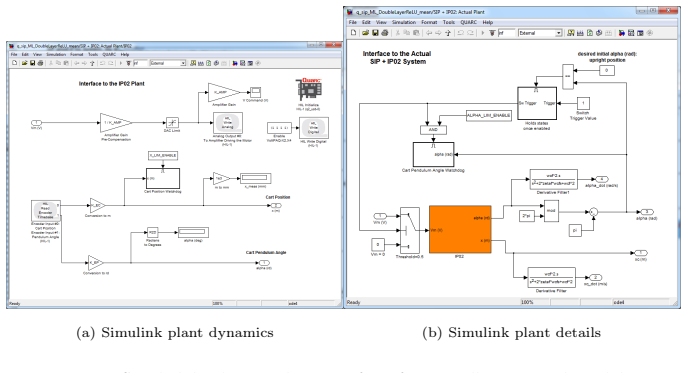
Appendix (a) Lab Photo (b) Simulink interface Figure 12: Inverted pendulum in the lab and the hardware-in-loop interface with Simulink 43 (a) Simulink plant dynamics (b) Simulink plant details Figure 13: Simulink hardware-in-loop interfaces for controlling inverted pendulum 44
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.