Reinforcement learning to improve large language model-based automated code compliance systems
Pith reviewed 2026-06-26 10:08 UTC · model grok-4.3
The pith
P4IR combines supervised fine-tuning with group relative policy optimization to produce more accurate code skeletons for automated building code compliance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
P4IR demonstrates that applying Group Relative Policy Optimization after supervised fine-tuning lets an LLM generate higher-fidelity intermediate code skeletons for building regulation compliance, cutting structural and token-level edit distances relative to SFT alone while also lowering false positives and outperforming leading LLMs in zero-shot settings.
What carries the argument
The P4IR two-stage framework: supervised fine-tuning to instill domain knowledge, followed by Group Relative Policy Optimization (GRPO) to optimize the generated code skeletons directly against domain-specific objectives.
If this is right
- Lower tree edit and Levenshtein distances produce code skeletons that better preserve both structure and semantics of the target regulations.
- Zero-shot performance exceeding few-shot frontier models reduces the need for prompt engineering when deploying the system.
- The GRPO stage's reduction in false positives improves the precision of the downstream compliance checker.
- Direct optimization for domain objectives via GRPO offers a general recipe for improving LLM outputs on other structured generation tasks in regulatory domains.
Where Pith is reading between the lines
- The same SFT-plus-GRPO pipeline could be tested on generating full executable compliance rules rather than skeletons alone.
- Integration of the improved skeletons into an actual design-checking engine would provide a direct test of whether the distance metrics correlate with practical compliance accuracy.
- The method may transfer to other code-generation settings where an intermediate structured representation must match a regulatory or specification template.
Load-bearing premise
Reductions in edit distance between generated code skeletons and reference skeletons will produce higher accuracy when those skeletons are used to check actual building designs against real regulations.
What would settle it
An end-to-end evaluation that runs the generated skeletons on a held-out set of real building designs and regulations and measures the rate of correct compliance decisions against a human-annotated ground truth.
Figures




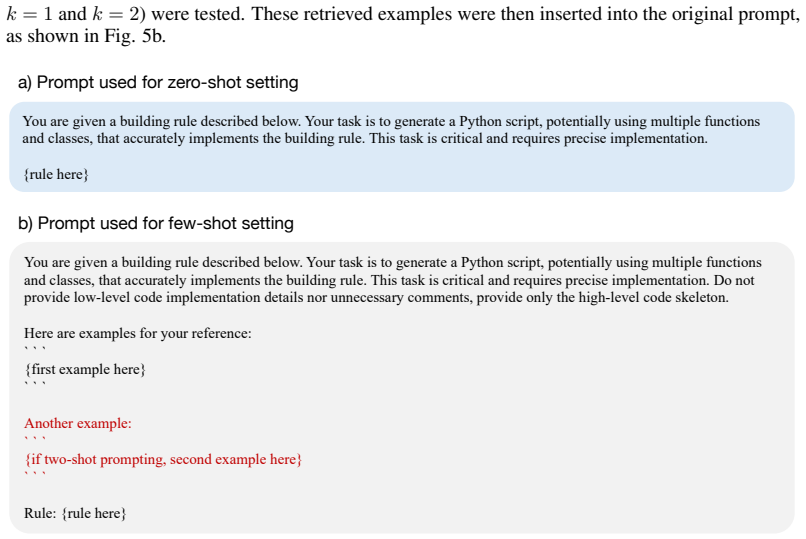
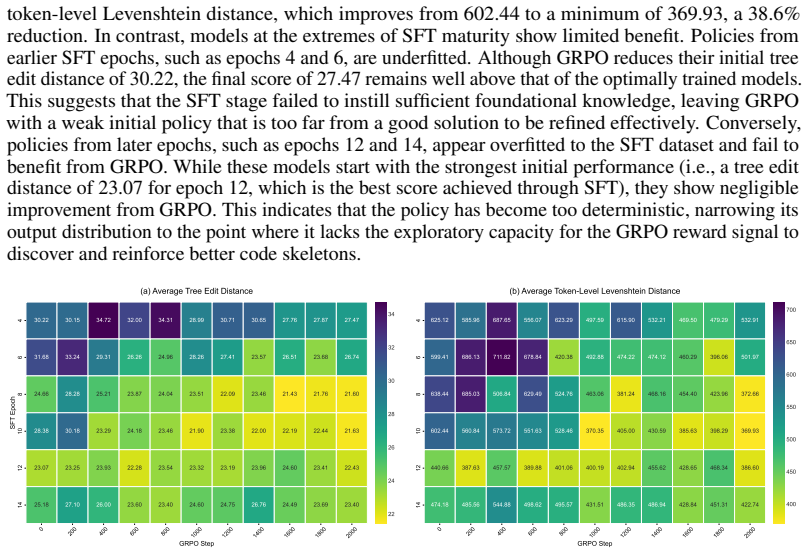
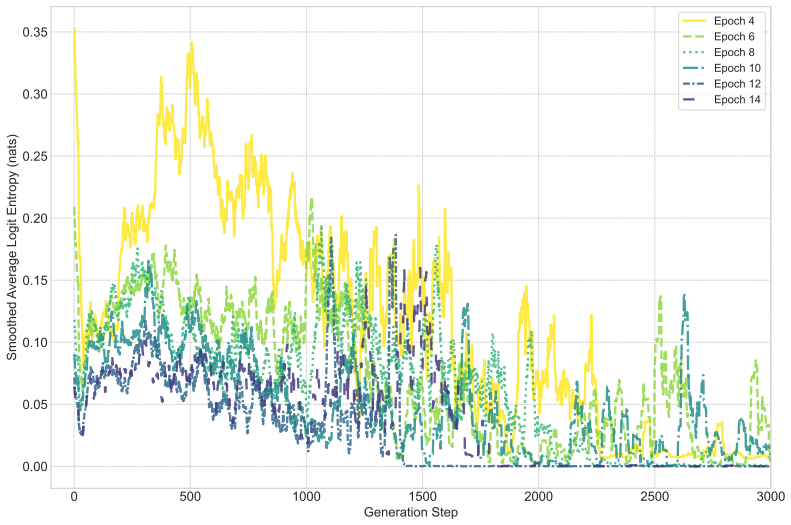
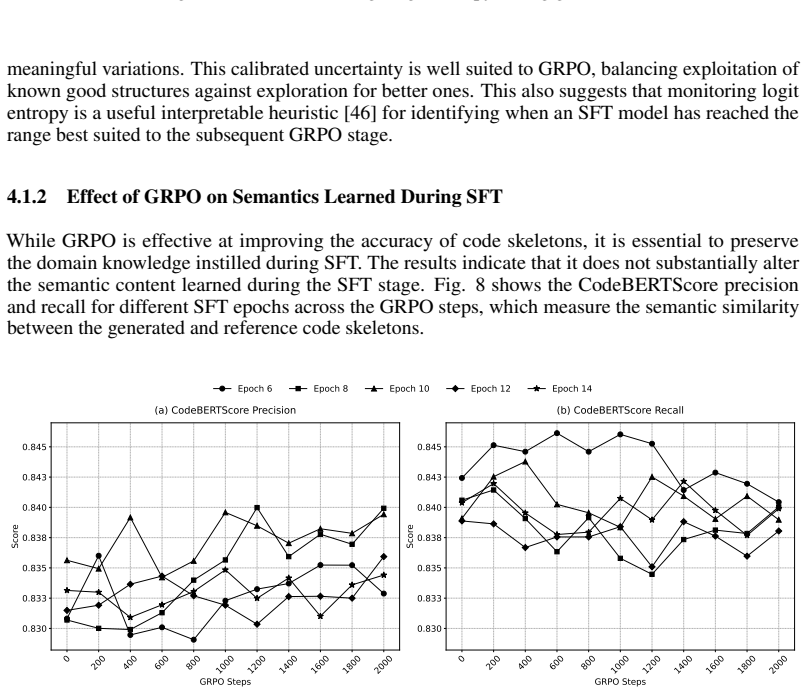




read the original abstract
Large language model (LLM)-based approaches for automated code compliance (ACC) of building regulations are prone to generating incorrect and hallucinated computer-processable rules. This paper introduces P4IR, a two-stage framework that uses supervised fine-tuning (SFT) to instill domain knowledge in an LLM, followed by Group Relative Policy Optimization (GRPO) to improve the accuracy of the generated intermediate representations in the form of high-level code skeletons. The framework achieved reductions of up to 23.8% and 38.6% in tree edit distance and token-level Levenshtein distance respectively, relative to the SFT baselines. Comparative analysis demonstrates that this approach in a zero-shot setting outperforms leading LLMs in both code structure and semantics, specifically Claude Opus and Sonnet 4.5, GPT-5.2, Qwen-3-Max, and GLM-4.7, evaluated via few-shot prompting. Additionally, the GRPO stage produced a small yet statistically significant reduction in false positives. By combining SFT with GRPO to optimize directly for domain-specific objectives, this approach offers a path toward more accurate and reliable LLM-based ACC systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces P4IR, a two-stage framework that applies supervised fine-tuning (SFT) to instill domain knowledge in an LLM, followed by Group Relative Policy Optimization (GRPO) to refine high-level code skeletons for LLM-based automated code compliance (ACC) checking of building regulations. It reports up to 23.8% and 38.6% reductions in tree edit distance and token-level Levenshtein distance versus SFT baselines, zero-shot outperformance over Claude Opus/Sonnet 4.5, GPT-5.2, Qwen-3-Max, and GLM-4.7 (evaluated few-shot), and a small but statistically significant false-positive reduction after GRPO.
Significance. If the proxy improvements in skeleton fidelity demonstrably increase end-to-end compliance accuracy on real building designs, the work would provide a concrete route to more reliable LLM-based ACC by directly optimizing for domain-specific structural and semantic objectives via GRPO. The absence of that linkage currently confines the contribution to intermediate metrics.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The central claim is that P4IR improves LLM-based ACC systems. This requires that lower tree edit distance and Levenshtein distance on generated skeletons produce higher accuracy when the skeletons are used to check actual building designs against regulations. The manuscript reports only skeleton-reference comparisons plus an unspecified false-positive reduction; no end-to-end evaluation on real designs is supplied, leaving the headline performance numbers without demonstrated connection to the stated goal.
- [Methods / Experimental setup] Methods / Experimental setup: The abstract states concrete percentage reductions and statistical significance, yet supplies no information on dataset size, exclusion rules, baseline implementation details, or how the distance metrics were computed. These omissions prevent verification that the reported numbers support the comparative claims against SFT and other LLMs.
minor comments (2)
- [Abstract] Abstract: Model names such as 'GPT-5.2' and 'Sonnet 4.5' are non-standard; clarify the exact versions or checkpoints used.
- [Evaluation] Notation: 'token-level Levenshtein distance' and 'tree edit distance' should be defined with explicit formulas or references on first use to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The central claim is that P4IR improves LLM-based ACC systems. This requires that lower tree edit distance and Levenshtein distance on generated skeletons produce higher accuracy when the skeletons are used to check actual building designs against regulations. The manuscript reports only skeleton-reference comparisons plus an unspecified false-positive reduction; no end-to-end evaluation on real designs is supplied, leaving the headline performance numbers without demonstrated connection to the stated goal.
Authors: The manuscript's contribution centers on improving the quality of high-level code skeletons as an intermediate representation, which the abstract and introduction identify as a key source of hallucinations in LLM-based ACC. The GRPO stage is explicitly optimized for tree edit distance and token-level Levenshtein distance to these skeletons, and the reported false-positive reduction supplies limited but statistically significant evidence of a downstream effect. We acknowledge that a full end-to-end evaluation on complete building designs would provide a stronger link to final compliance accuracy; however, the current scope demonstrates that direct optimization of domain-specific structural and semantic objectives via GRPO yields measurable gains over SFT and frontier LLMs on the skeleton task itself. The headline claims are therefore tied to skeleton fidelity rather than end-to-end accuracy, which is stated as an intended future direction. revision: no
-
Referee: [Methods / Experimental setup] Methods / Experimental setup: The abstract states concrete percentage reductions and statistical significance, yet supplies no information on dataset size, exclusion rules, baseline implementation details, or how the distance metrics were computed. These omissions prevent verification that the reported numbers support the comparative claims against SFT and other LLMs.
Authors: We agree that the current manuscript lacks sufficient methodological detail for full reproducibility. In the revised version we will expand the Experimental Setup and Evaluation sections to report dataset size and any exclusion criteria, precise baseline prompting and fine-tuning configurations, and the exact implementations used to compute tree edit distance and token-level Levenshtein distance (including any normalization or tokenization steps). revision: yes
Circularity Check
No circularity; purely empirical comparisons with no derivations or self-referential predictions
full rationale
The paper reports measured reductions in tree edit distance and Levenshtein distance from SFT+GRPO versus baselines, plus comparisons to other LLMs, all obtained through direct experimental evaluation on held-out data. No equations, parameter fitting presented as prediction, uniqueness theorems, or self-citation chains appear in the provided text or abstract. The central claims rest on observable performance deltas against external references rather than any reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://www1.bca.gov.sg/ about-us/news-and-publications/media-releases/2025/01/23/ construction-demand-to-remain-strong-for-2025(accessed August 4, 2025)
Building and Construction Authority (BCA), Construction demand to remain strong for 2025, BCA (2025). https://www1.bca.gov.sg/ about-us/news-and-publications/media-releases/2025/01/23/ construction-demand-to-remain-strong-for-2025(accessed August 4, 2025)
2025
-
[2]
Z. Zheng, J. Han, K.-Y . Chen, X.-Y . Cao, X.-Z. Lu, J.-R. Lin, Translating regulatory clauses into executable codes for building design checking via large language model driven function matching and composing, Eng. Appl. Artif. Intell. 163 (2026) 112823. https://doi.org/10. 1016/j.engappai.2025.112823
arXiv 2026
-
[3]
R. Zhang, N. El-Gohary, Hierarchical representation and deep learning–based method for auto- matically transforming textual building codes into semantic computable requirements, J. Com- put. Civ. Eng. 36 (2022) 04022022. https://doi.org/10.1061/(ASCE)CP.1943-5487. 0001014
-
[4]
S. Fuchs, J. Dimyadi, M. Witbrock, R. Amor, Intermediate representations to improve the semantic parsing of building regulations, Adv. Eng. Inform. 62 (2024) 102735. https://doi. org/10.1016/j.aei.2024.102735
-
[5]
Zhang, How can ChatGPT help in automated building code compliance checking?, Int
J. Zhang, How can ChatGPT help in automated building code compliance checking?, Int. Symp. Autom. Robot. Constr. ISARC Proc. 2023 Proceedings of the 40th ISARC, Chennai, India (2023) 63–70.https://doi.org/10.22260/ISARC2023/0011
-
[6]
S. Fuchs, M. Witbrock, J. Dimyadi, R. Amor, Using large language models for the interpretation of building regulations, (2024).https://doi.org/10.48550/arXiv.2407.21060
-
[7]
S. Lin, J. Hilton, O. Evans, TruthfulQA: measuring how models mimic human falsehoods, in: S. Muresan, P. Nakov, A. Villavicencio (Eds.), Proc. 60th Annu. Meet. Assoc. Comput. Linguist. V ol. 1 Long Pap., Association for Computational Linguistics, Dublin, Ireland, 2022: pp. 3214–3252.https://doi.org/10.18653/v1/2022.acl-long.229
-
[8]
Huang, W
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, T. Liu, A survey on hallucination in large language models: principles, taxonomy, challenges, and open questions, ACM Trans. Inf. Syst. 43 (2025) 1–55. https://doi.org/10.1145/ 3703155
2025
-
[9]
S. Fuchs, M. Witbrock, J. Dimyadi, R. Amor, Neural semantic parsing of building regulations for compliance checking, IOP Conf. Ser. Earth Environ. Sci. 1101 (2022) 092022. https: //doi.org/10.1088/1755-1315/1101/9/092022
-
[10]
K. Tian, E. Mitchell, H. Yao, C. Manning, C. Finn, Fine-tuning language models for factuality, in: NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023. https: //openreview.net/forum?id=kEK08VdSO5(accessed November 10, 2025)
2023
-
[11]
P. Roit, J. Ferret, L. Shani, R. Aharoni, G. Cideron, R. Dadashi, M. Geist, S. Girgin, L. Hussenot, O. Keller, N. Momchev, S. Ramos Garea, P. Stanczyk, N. Vieillard, O. Bachem, G. Elidan, A. Hassidim, O. Pietquin, I. Szpektor, Factually consistent summarization via reinforcement learning with textual entailment feedback, in: A. Rogers, J. Boyd-Graber, N. ...
-
[12]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y .K. Li, Y . Wu, D. Guo, DeepSeekMath: pushing the limits of mathematical reasoning in open language models, (2024). https://doi.org/10.48550/arXiv.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[13]
J.W.L. Shi, W. Solihin, J.K.W. Yeoh, Fine-tuning a large language model for automated code compliance of building regulations, Adv. Eng. Inform. 68 (2025) 103676. https://doi.org/ 10.1016/j.aei.2025.103676 19
-
[15]
C. Eastman, J. Lee, Y . Jeong, J. Lee, Automatic rule-based checking of building designs, Autom. Constr. 18 (2009) 1011–1033.https://doi.org/10.1016/j.autcon.2009.07.002
-
[16]
Hjelseth, N
E. Hjelseth, N. Nisbet, Capturing normative constraints by use of semantic mark-up RASE methodology, Proc. CIB W78-W102 Conf. Pp 1-10 (2011). https://itc.scix.net/pdfs/ w78-2011-Paper-45.pdf
2011
-
[17]
I. Fitkau, T. Hartmann, An ontology-based approach of automatic compliance checking for structural fire safety requirements, Adv. Eng. Inform. 59 (2024) 102314. https://doi.org/ 10.1016/j.aei.2023.102314
-
[18]
J.-K. Lee, C.M. Eastman, Y .C. Lee, Implementation of a BIM domain-specific language for the building environment rule and analysis, J. Intell. Robot. Syst. 79 (2015) 507–522. https://doi.org/10.1007/s10846-014-0117-7
-
[19]
H. Kim, J.-K. Lee, J. Shin, J. Choi, Visual language approach to representing KBimCode-based korea building code sentences for automated rule checking, J. Comput. Des. Eng. 6 (2019) 143–148.https://doi.org/10.1016/j.jcde.2018.08.002
-
[20]
J. Zhang, N.M. El-Gohary, Semantic NLP-based information extraction from construction regulatory documents for automated compliance checking, J. Comput. Civ. Eng. 30 (2016) 04015014.https://doi.org/10.1061/(ASCE)CP.1943-5487.0000346
-
[21]
J. Song, J.-K. Lee, J. Choi, I. Kim, Deep learning-based extraction of predicate-argument structure (PAS) in building design rule sentences, J. Comput. Des. Eng. 7 (2020) 563–576. https://doi.org/10.1093/jcde/qwaa046
-
[22]
D. Guo, E. Onstein, A.D.L. Rosa, A semantic approach for automated rule compliance check- ing in construction industry, IEEE Access 9 (2021) 129648–129660. https://doi.org/10. 1109/ACCESS.2021.3108226
arXiv 2021
-
[23]
Z. Zheng, Y .-C. Zhou, X.-Z. Lu, J.-R. Lin, Knowledge-informed semantic alignment and rule interpretation for automated compliance checking, Autom. Constr. 142 (2022) 104524. https://doi.org/10.1016/j.autcon.2022.104524
-
[24]
J. Peng, X. Liu, Automated code compliance checking research based on BIM and knowledge graph, Sci. Rep. 13 (2023) 7065.https://doi.org/10.1038/s41598-023-34342-1
-
[25]
P. Zhou, N. El-Gohary, Ontology-based automated information extraction from building en- ergy conservation codes, Autom. Constr. 74 (2017) 103–117. https://doi.org/10.1016/j. autcon.2016.09.004
work page doi:10.1016/j 2017
-
[26]
Zhang, N.M
J. Zhang, N.M. El-Gohary, Integrating semantic NLP and logic reasoning into a unified system for fully-automated code checking, Autom. Constr. 73 (2017) 45–57. https://doi.org/10. 1016/j.autcon.2016.08.027
2017
-
[27]
J. Wu, X. Xue, J. Zhang, Invariant signature, logic reasoning, and semantic natural language processing (NLP)-based automated building code compliance checking (I-SNACC) framework, J. Inf. Technol. Constr. 28 (2023) 1–18.https://doi.org/10.36680/j.itcon.2023.001
-
[28]
N. Wang, R.R.A. Issa, C.J. Anumba, NLP-based query-answering system for information extraction from building information models, J. Comput. Civ. Eng. 36 (2022) 04022004.https: //doi.org/10.1061/(ASCE)CP.1943-5487.0001019
-
[29]
Okonkwo, Leveraging word embeddings and transformers to extract semantics from building regulations text, 11th Linked Data Archit
O. Okonkwo, Leveraging word embeddings and transformers to extract semantics from building regulations text, 11th Linked Data Archit. Constr. Workshop June 11–15 2023 Matera Italy (2023).https://ceur-ws.org/Vol-3633/paper14.pdf
2023
-
[30]
Z. Zheng, Y .-C. Zhou, K.-Y . Chen, X.-Z. Lu, Z.-T. She, J.-R. Lin, A text classification-based approach for evaluating and enhancing the machine interpretability of building codes, Eng. Appl. Artif. Intell. 127 (2024) 107207.https://doi.org/10.1016/j.engappai.2023.107207 20
-
[31]
S. Iranmanesh, H. Saadany, E. Vakaj, LLM-assisted graph-RAG information extraction from IFC data, in: Proceedings of the 2025 European Conference on Computing in Construction, Porto, Portugal, 2025: pp. 263–270.https://doi.org/10.35490/EC3.2025.366
-
[32]
X. Xue, J. Zhang, Y . Chen, Question-answering framework for building codes using fine- tuned and distilled pre-trained transformer models, Autom. Constr. 168 (2024) 105730. https: //doi.org/10.1016/j.autcon.2024.105730
-
[33]
Shields, and Lori Graham-Brady
B. Zhong, W. He, Z. Huang, P.E.D. Love, J. Tang, H. Luo, A building regulation question answering system: a deep learning methodology, Adv. Eng. Inform. 46 (2020) 101195. https: //doi.org/10.1016/j.aei.2020.101195
-
[34]
H. Ying, R. Sacks, From automatic to autonomous: a large language model- driven approach for generic building compliance checking, Proc. 41st Int. Conf. CIB W78 Marrakech Moroc. 2-3 Oct. ISSN 2706-6568 ISSN 2706-6568 (2024).http://itc.scix.net/paper/w78-2024-59
2024
-
[35]
Training language models to follow instructions with human feedback
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C.L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, R. Lowe, Training language models to follow instructions with human feedback, (2022).https://doi.org/10.48550/arXiv.2203.02155
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.02155 2022
-
[36]
Y . Zhai, H. Zhang, Y . Lei, Y . Yu, K. Xu, D. Feng, B. Ding, H. Wang, Uncertainty-penalized reinforcement learning from human feedback with diverse reward LoRA ensembles, (2023). https://doi.org/10.48550/arXiv.2401.00243
-
[37]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, X. Yu, Y . Wu, Z.F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Ding, H. Gao, H. Qu, H. Li, J. Gu...
-
[38]
Biomistral: A collection of open-source pretrained large language models for medical domains
Y . Labrak, A. Bazoge, E. Morin, P.-A. Gourraud, M. Rouvier, R. Dufour, BioMistral: a collection of open-source pretrained large language models for medical domains, (2024). https://doi.org/10.48550/arXiv.2402.10373
-
[39]
B. Lefort, E. Benhamou, J.-J. Ohana, D. Saltiel, B. Guez, Optimizing performance: how compact models match or exceed GPT’s classification capabilities through fine-tuning, (2024). https://doi.org/10.48550/arXiv.2409.11408
-
[40]
Y . Lai, J. Zhong, M. Li, S. Zhao, X. Yang, Med-R1: reinforcement learning for generalizable medical reasoning in vision-language models, (2025). https://doi.org/10.48550/arXiv. 2503.13939
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[41]
A.P. Gema, A. Hägele, R. Chen, A. Arditi, J. Goldman-Wetzler, K. Fraser-Taliente, H. Sleight, L. Petrini, J. Michael, B. Alex, P. Minervini, Y . Chen, J. Benton, E. Perez, Inverse scaling in test-time compute, (2025).https://doi.org/10.48550/arXiv.2507.14417 21
-
[42]
R. Zhang, N. El-Gohary, Clustering-based approach for building code computability anal- ysis, J. Comput. Civ. Eng. 35 (2021) 04021021. https://doi.org/10.1061/(ASCE)CP. 1943-5487.0000967
-
[43]
X. Xue, J. Zhang, Regulatory information transformation ruleset expansion to support automated building code compliance checking, Autom. Constr. 138 (2022) 104230. https://doi.org/ 10.1016/j.autcon.2022.104230
-
[44]
N.N. Minh, A. Baker, C. Neo, A.G. Roush, A. Kirsch, R. Shwartz-Ziv, Turning up the heat: min-p sampling for creative and coherent LLM outputs, in: 2024.https://openreview.net/ forum?id=FBkpCyujtS(accessed January 26, 2026)
2024
-
[45]
M. Uhm, J. Kim, S. Ahn, H. Jeong, H. Kim, Effectiveness of retrieval augmented generation- based large language models for generating construction safety information, Autom. Constr. 170 (2025) 105926.https://doi.org/10.1016/j.autcon.2024.105926
-
[46]
J.W.L. Shi, M. Dang, W. Solihin, J.K.W. Yeoh, LLM attribution analysis across different fine- tuning strategies and model scales for automated code compliance, in: The 21st International Conference on Computing in Civil and Building Engineering (ICCCBE 2026), Taipei, Taiwan, 2026.https://doi.org/10.48550/arXiv.2604.15589 22
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.15589 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.