Open-Vocabulary BEV Segmentation with 3D-Aware Geometric Constraints
Pith reviewed 2026-06-26 00:38 UTC · model grok-4.3
The pith
A three-stage geometric constraint system lifts 2D vision-language model outputs into consistent open-vocabulary bird's-eye-view maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
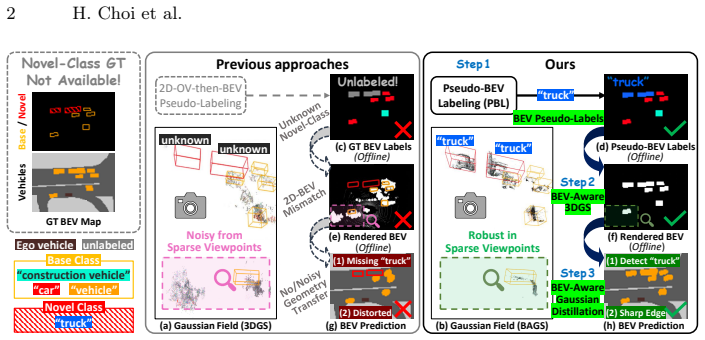
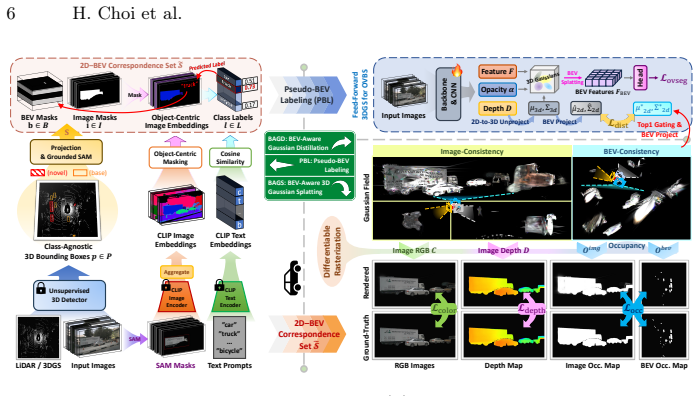
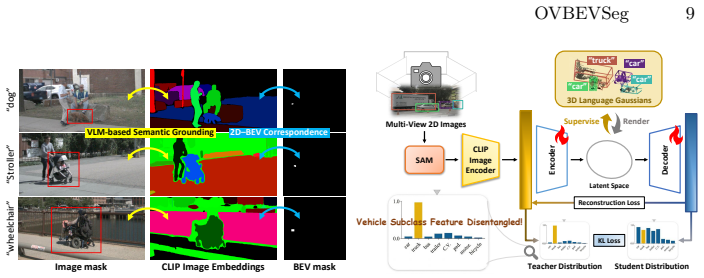
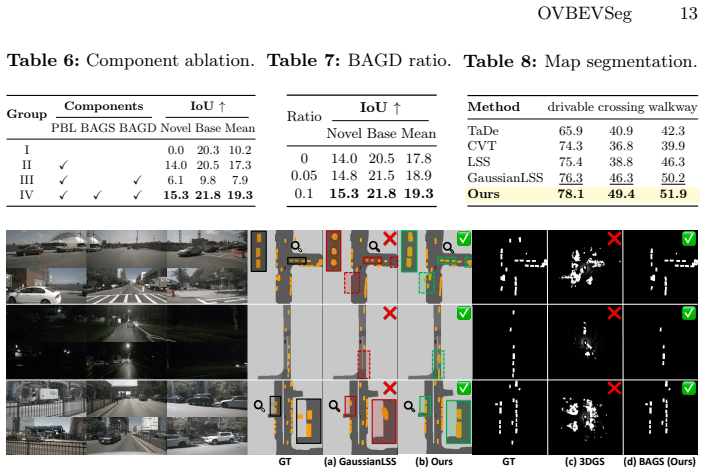
OVBEVSeg enhances efficient Gaussian splatting unprojection through three progressive stages of 3D geometric constraints: 2D-to-BEV pseudo-labeling via reliable 3D projection for open-vocabulary generalization, joint 2D-BEV per-scene optimization with BEV structural constraints for geometric consistency, and 3D geometric distillation for online efficiency. On the nuScenes dataset this produces state-of-the-art open-vocabulary BEV segmentation that outperforms closed-set methods by 15.3 mIoU on unseen categories, remains competitive with self- and semi-supervised baselines trained on up to 40 percent ground-truth annotations, and delivers 2.5 times faster inference at 0.22 times the memory of
What carries the argument
Three-stage progressive application of 3D geometric constraints to Gaussian splatting unprojection that enforces consistency when lifting 2D VLM semantics into BEV space.
If this is right
- Open-vocabulary recognition becomes possible in BEV perception without any ground-truth labels for new classes.
- Performance on unseen categories exceeds that of closed-set trained models by a large margin.
- Accuracy stays competitive with methods that require up to 40 percent labeled data while using none for novel classes.
- Inference runs 2.5 times faster and uses 0.22 times the memory of prior projection-based approaches.
Where Pith is reading between the lines
- The same constraint stages could be applied to other multi-camera tasks such as 3D object detection or occupancy prediction where 2D semantics must be lifted consistently.
- Reduced reliance on dense novel-class annotations could lower the data-collection cost for training perception stacks in new geographic regions.
- If the constraints generalize, they might allow a single model to handle both known and unknown road users without retraining.
Load-bearing premise
Reliable 3D projection for pseudo-labeling together with BEV structural constraints and distillation can remove the geometric inconsistency of lifting 2D VLM semantics into BEV without introducing new systematic errors or needing novel-class ground truth.
What would settle it
A test set of scenes containing novel objects at multiple depths where the produced BEV maps show persistent misalignment or label leakage between objects would show that the geometric constraints do not resolve the inconsistency.
Figures

read the original abstract
Bird's-eye view (BEV) perception fuses multi-camera images into a unified top-down representation for autonomous driving. Despite recent progress, state-of-the-art methods remain confined to closed-set scenarios, making them vulnerable to unpredictable real-world environments. In this work, we introduce open-vocabulary BEV segmentation (OVBS), which leverages vision-language models (VLMs) to recognize categories beyond the training set while maintaining precise BEV perception and real-time efficiency. A key challenge in OVBS lies in the 3D geometric inconsistency inherent in the ill-posed lifting of 2D VLM semantics into BEV. To address this, we propose OVBEVSeg, a geometry-aware OVBS framework that enhances efficient Gaussian splatting (GS)-based unprojection by leveraging robust 3D geometric constraints across three progressive stages: (1) 2D-to-BEV pseudo-labeling via reliable 3D projection for OV generalization; (2) joint 2D-BEV per-scene optimization with BEV structural constraints for 3D geometric consistency; and (3) 3D geometric distillation for online efficiency. On the nuScenes dataset, OVBEVSeg achieves state-of-the-art performance, outperforming closed-set methods by 15.3 mIoU on unseen categories. Remarkably, even with no novel-class ground-truth labels, it remains competitive with self- and semi-supervised baselines trained with up to 40% of ground-truth annotations. Furthermore, it achieves 2.5x faster inference with only 0.22x the memory consumption of projection-based methods. Project page: https://hchoi256.github.io/projects/ovbevseg/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OVBEVSeg, a three-stage geometry-aware framework for open-vocabulary BEV segmentation that lifts 2D VLM semantics into BEV using efficient Gaussian splatting unprojection enhanced by reliable 3D projection for pseudo-labeling, BEV structural constraints in joint per-scene optimization, and 3D geometric distillation for efficiency. On nuScenes it claims SOTA open-vocabulary performance with a 15.3 mIoU gain on unseen categories over closed-set methods, competitiveness with self-/semi-supervised baselines using up to 40% ground-truth annotations, and 2.5x faster inference at 0.22x memory of projection-based approaches.
Significance. If the geometric consistency claims hold with the reported gains, the work would meaningfully advance open-vocabulary 3D perception for autonomous driving by enabling generalization to novel classes without novel-class labels while preserving real-time efficiency; the combination of pseudo-labeling, structural constraints, and distillation is a plausible route to mitigating lifting inconsistencies.
major comments (2)
- [Abstract, §3] Abstract and §3 (method overview): the central claim that the three-stage pipeline resolves 3D geometric inconsistency without systematic errors or novel-class GT rests on the reliability of the 3D projection step and the effectiveness of the BEV constraints, yet no quantitative ablation isolating each stage's contribution to mIoU on unseen classes is described, which is load-bearing for attributing the 15.3 mIoU gain.
- [Abstract] Abstract: the efficiency claims (2.5x faster inference, 0.22x memory) and competitiveness with 40%-annotation baselines are presented without reported variance, exact baseline definitions, or per-scene optimization details, preventing verification that the distillation stage preserves the consistency achieved in stage 2.
minor comments (1)
- [Abstract] The project page URL is given but no supplementary material or code link is referenced in the abstract, which would aid reproducibility of the GS-based unprojection and constraint implementation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below with point-by-point responses.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method overview): the central claim that the three-stage pipeline resolves 3D geometric inconsistency without systematic errors or novel-class GT rests on the reliability of the 3D projection step and the effectiveness of the BEV constraints, yet no quantitative ablation isolating each stage's contribution to mIoU on unseen classes is described, which is load-bearing for attributing the 15.3 mIoU gain.
Authors: We agree that isolating the per-stage contributions specifically to mIoU on unseen classes is important for rigorously attributing the reported 15.3 mIoU gain. The manuscript includes component ablations in Section 4.3, but these do not provide a dedicated breakdown of unseen-class mIoU gains per stage. We will add a quantitative ablation table focused on unseen categories (with and without each stage) to the revised manuscript or supplementary material. revision: yes
-
Referee: [Abstract] Abstract: the efficiency claims (2.5x faster inference, 0.22x memory) and competitiveness with 40%-annotation baselines are presented without reported variance, exact baseline definitions, or per-scene optimization details, preventing verification that the distillation stage preserves the consistency achieved in stage 2.
Authors: We will revise the abstract and relevant sections to include exact baseline definitions (specifying the self-/semi-supervised methods and annotation percentages used) and report standard deviations for the efficiency metrics where multiple runs are available. Per-scene optimization details are already described in Section 3.2; we will add a cross-reference and a brief analysis showing that the distilled model in stage 3 retains the geometric consistency metrics from stage 2. If variance was not computed in the original experiments, we will note this limitation explicitly. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and available description outline a three-stage pipeline relying on external geometric projection, VLM features, and optimization constraints drawn from standard computer vision techniques. No equations, self-citations, or fitted quantities are shown that reduce predictions or uniqueness claims to the paper's own inputs by construction. The performance claims are benchmarked against independent datasets and baselines, keeping the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Bhat,S.F.,Birkl,R.,Wofk,D.,Wonka,P.,Müller,M.:Zoedepth:Zero-shottransfer by combining relative and metric depth. CoRRabs/2302.12288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. pp. 11618–11628 (2020)
2020
-
[3]
Cao, Y., Jv, Y., Xu, D.: 3dgs-det: Empower 3d gaussian splatting with boundary guidance and box-focused sampling for 3d object detection (2024)
2024
-
[4]
In: IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2025, Tucson, AZ, USA, February 26 - March 6, 2025
Chabot, F., Granger, N., Lapouge, G.: Gaussianbev: 3d gaussian representation meets perception models for bev segmentation. In: IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2025, Tucson, AZ, USA, February 26 - March 6, 2025. pp. 2250–2259 (2025)
2025
-
[5]
Chambon, L., Zablocki, É., Chen, M., Bartoccioni, F., Pérez, P., Cord, M.: Point- bev:Asparseapproachtobevpredictions.In:IEEE/CVFConferenceonComputer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 15195–15204 (2024)
2024
-
[6]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024
Charatan, D., Li, S.L., Tagliasacchi, A., Sitzmann, V.: Pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 19457–19467 (2024)
2024
-
[7]
Chen, Q., Yang, S., Du, S., Tang, T., Chen, P., Huo, Y.: Lidar-gs:real-time lidar re-simulation using gaussian splatting. CoRRabs/2410.05111(2024)
-
[8]
In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, Septem- ber 29-October 4, 2024, Proceedings, Part XXI
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T., Cai, J.: Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, Septem- ber 29-October 4, 2024, Proceedings, Part XXI. vol. 15079, pp. 370–386 (2024)
2024
-
[9]
Choi, H., Lim, Y., Shin, J., Shim, H.: Cot-pl: Visual chain-of-thought reasoning meets pseudo-labeling for open-vocabulary object detection (2025)
2025
-
[10]
In: IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2024 - Workshops, Seattle, WA, USA, June 17-18, 2024
Chung, J., Oh, J., Lee, K.M.: Depth-regularized optimization for 3d gaussian splat- ting in few-shot images. In: IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2024 - Workshops, Seattle, WA, USA, June 17-18, 2024. pp. 811–820 (2024)
2024
-
[11]
In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XL
Etchegaray, D., Huang, Z., Harada, T., Luo, Y.: Find n’ propagate: Open- vocabulary 3d object detection in urban environments. In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XL. vol. 15098, pp. 133–151 (2024)
2024
-
[12]
Fan, Z., Cong, W., Wen, K., Wang, K., Zhang, J., Ding, X., Xu, D., Ivanovic, B., Pavone, M., Pavlakos, G., Wang, Z., Wang, Y.: Instantsplat: Sparse-view gaussian splatting in seconds (2025)
2025
-
[13]
In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part LXXVII
Fang,G.,Wang,B.:Mini-splatting:Representingsceneswithaconstrainednumber of gaussians. In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part LXXVII. vol. 15135, pp. 165–181. Springer (2024)
2024
-
[14]
In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part LXXVII
Fang,G.,Wang,B.:Mini-splatting:Representingsceneswithaconstrainednumber of gaussians. In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part LXXVII. vol. 15135, pp. 165–181. Springer (2024) 16 H. Choi et al
2024
-
[15]
In: ECCV (2024)
Gosala, N., Petek, K., Kiran, B.R., Yogamani, S.K., Drews-Jr, P.L.J., Burgard, W., Valada, A.: Letsmap: Unsupervised representation learning for label-efficient semantic BEV mapping. In: ECCV (2024)
2024
-
[16]
In: The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 (2022)
Gu, X., Lin, T., Kuo, W., Cui, Y.: Open-vocabulary object detection via vision and language knowledge distillation. In: The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 (2022)
2022
-
[17]
Harley, A.W., Fang, Z., Li, J., Ambrus, R., Fragkiadaki, K.: Simple-bev: What really matters for multi-sensor BEV perception? In: IEEE International Conference on Robotics and Automation, ICRA 2023, London, UK, May 29 - June 2, 2023. pp. 2759–2765 (2023)
2023
-
[18]
In: IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2024, Waikoloa, HI, USA, January 3-8, 2024
Hess,G.,Tonderski,A.,Petersson,C.,Åström,K.,Svensson,L.:Lidarclipor:HowI learned to talk to point clouds. In: IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2024, Waikoloa, HI, USA, January 3-8, 2024. pp. 7423–7432 (2024)
2024
-
[19]
In: 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021
Hu, A., Murez, Z., Mohan, N., Dudas, S., Hawke, J., Badrinarayanan, V., Cipolla, R.,Kendall,A.:FIERY:futureinstancepredictioninbird’s-eyeviewfromsurround monocular cameras. In: 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021. pp. 15253–15262 (2021)
2021
-
[20]
In: Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXXVIII
Hu, S., Chen, L., Wu, P., Li, H., Yan, J., Tao, D.: ST-P3: end-to-end vision-based autonomous driving via spatial-temporal feature learning. In: Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXXVIII. vol. 13698, pp. 533–549 (2022)
2022
-
[21]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., Lu, L., Jia, X., Liu, Q., Dai, J., Qiao, Y., Li, H.: Planning-oriented autonomous driving. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. pp. 17853– 17862 (2023)
2023
-
[22]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Huang, J., Huang, G., Zhu, Z., Du, D.: Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. CoRRabs/2112.11790(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023
Jia, X., Gao, Y., Chen, L., Yan, J., Liu, P.L., Li, H.: Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving. In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. pp. 7919–7929 (2023)
2023
-
[24]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42, 139:1–139:14 (2023)
2023
-
[25]
In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W., Dollár, P., Girshick, R.B.: Segment anything. In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. pp. 3992–4003 (2023)
2023
-
[26]
In: IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24,
Li, S., Fischer, T., Ke, L., Ding, H., Danelljan, M., Yu, F.: Ovtrack: Open- vocabulary multiple object tracking. In: IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24,
2023
-
[27]
5567–5577 (2023)
pp. 5567–5577 (2023)
2023
-
[28]
Li, Y., Ge, Z., Yu, G., Yang, J., Wang, Z., Shi, Y., Sun, J., Li, Z.: Bevdepth: Ac- quisition of reliable depth for multi-view 3d object detection. In: Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence, IAAI 2023, Thirteenth Sympo- sium on Educational Advance...
2023
-
[29]
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Qiao, Y., Dai, J.: Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotem- poraltransformers.In:ComputerVision-ECCV2022-17thEuropeanConference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part IX. pp. 1–18 (2022)
2022
-
[30]
Lin, Y., Wang, C., Chang, C., Sun, H.: An efficient framework for counting pedes- trians crossing a line using low-cost devices: the benefits of distilling the knowledge in a neural network. Multim. Tools Appl.80(3), 4037–4051 (2021)
2021
-
[31]
In: IEEE/CVF International Con- ference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023
Liu, H., Teng, Y., Lu, T., Wang, H., Wang, L.: Sparsebev: High-performance sparse 3d object detection from multi-camera videos. In: IEEE/CVF International Con- ference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. pp. 18534–18544 (2023)
2023
-
[32]
In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XLVII
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., Zhu, J., Zhang, L.: Grounding DINO: marrying DINO with grounded pre- training for open-set object detection. In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XLVII. vol. 15105, pp. 38–55 (2024)
2024
-
[33]
In: IEEE/CVF Interna- tional Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6,
Liu, Y., Yan, J., Jia, F., Li, S., Gao, A., Wang, T., Zhang, X.: Petrv2: A unified framework for 3d perception from multi-camera images. In: IEEE/CVF Interna- tional Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6,
2023
-
[34]
3239–3249 (2023)
pp. 3239–3249 (2023)
2023
-
[35]
In: 7th Inter- national Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: 7th Inter- national Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 (2019)
2019
-
[36]
IEEE Robotics Autom
Lu, C., van de Molengraft, M.J.G., Dubbelman, G.: Monocular semantic oc- cupancy grid mapping with convolutional variational encoder-decoder networks. IEEE Robotics Autom. Lett.4(2), 445–452 (2019)
2019
-
[37]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025
Lu, S., Tsai, Y., Chen, Y.: Toward real-world BEV perception: Depth uncertainty estimation via gaussian splatting. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 17124–17133 (2025)
2025
-
[38]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024
Lu, T., Yu, M., Xu, L., Xiangli, Y., Wang, L., Lin, D., Dai, B.: Scaffold-gs: Struc- tured 3d gaussians for view-adaptive rendering. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. IEEE (2024)
2024
-
[39]
Lu, Y., Xu, C., Wei, X., Xie, X., Tomizuka, M., Keutzer, K., Zhang, S.: Open- vocabulary 3d detection via image-level class and debiased cross-modal contrastive learning. CoRRabs/2207.01987(2022)
-
[40]
IEEE Robotics Autom
Pan, B., Sun, J., Leung, H.Y.T., Andonian, A., Zhou, B.: Cross-view semantic segmentation for sensing surroundings. IEEE Robotics Autom. Lett.5(3), 4867– 4873 (2020)
2020
-
[41]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023
Peng, S., Genova, K., Jiang, C.M., Tagliasacchi, A., Pollefeys, M., Funkhouser, T.A.: Openscene: 3d scene understanding with open vocabularies. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. pp. 815–824 (2023)
2023
-
[42]
In: Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XIV
Philion, J., Fidler, S.: Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In: Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XIV. vol. 12359, pp. 194–210 (2020)
2020
-
[43]
In: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, CVPR 2024, Seattle, WA, USA, June 16-22, 2024
Qin, M., Li, W., Zhou, J., Wang, H., Pfister, H.: Langsplat: 3d language gaussian splatting. In: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 20051–20060 (2024) 18 H. Choi et al
2024
-
[44]
In: Proceedings of the 38th In- ternational Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Proceedings of the 38th In- ternational Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event. vol. 139, pp. 8748–8...
2021
-
[45]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., Zeng, Z., Zhang, H., Li, F., Yang, J., Li, H., Jiang, Q., Zhang, L.: Grounded SAM: assembling open-world models for diverse visual tasks. CoRR abs/2401.14159(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020
Roddick, T., Cipolla, R.: Predicting semantic map representations from images using pyramid occupancy networks. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. pp. 11135–11144 (2020)
2020
-
[47]
Tan,K.,Shen,Y.,Tu,M.,Zhu,H.,Wang,B.,Chen,G.,Ye,H.,Sun,H.:Ufo:Unify- ing feed-forward and optimization-based methods for large driving scene modeling (2026)
2026
-
[48]
In: Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA
Tan, M., Le, Q.V.: Efficientnet: Rethinking model scaling for convolutional neu- ral networks. In: Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA. vol. 97, pp. 6105–6114 (2019)
2019
-
[49]
de Vries Lentsch, T., Caesar, H., Gavrila, D.: UNION: unsupervised 3d object detection using object appearance-based pseudo-classes. In: Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 (2024)
2024
-
[50]
In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023
Wang, S., Liu, Y., Wang, T., Li, Y., Zhang, X.: Exploring object-centric temporal modeling for efficient multi-view 3d object detection. In: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023. pp. 3598–3608 (2023)
2023
-
[51]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 20310–20320 (2024)
2024
-
[52]
IEEE Trans
Wu, J., Li, X., Xu, S., Yuan, H., Ding, H., Yang, Y., Li, X., Zhang, J., Tong, Y., Jiang, X., Ghanem, B., Tao, D.: Towards open vocabulary learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell.46(7), 5092–5113 (2024)
2024
-
[53]
IEEE Trans
Wu, J., Li, X., Xu, S., Yuan, H., Ding, H., Yang, Y., Li, X., Zhang, J., Tong, Y., Jiang, X., Ghanem, B., Tao, D.: Towards open vocabulary learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell.46, 5092–5113 (2024)
2024
-
[54]
Wu, Y., Meng, J., Li, H., Wu, C., Shi, Y., Cheng, X., Zhao, C., Feng, H., Ding, E., Wang, J., Zhang, J.: Opengaussian: Towards point-level 3d gaussian-based open vocabulary understanding. In: Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December ...
2024
-
[55]
Xie, E., Yu, Z., Zhou, D., Philion, J., Anandkumar, A., Fidler, S., Luo, P., Álvarez, J.M.: M2bev: Multi-camera joint 3d detection and segmentation with unified birds- eye view representation. CoRRabs/2204.05088(2022)
-
[56]
In: IEEE/CVF Conference on OVBEVSeg 19 Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025
Xu, H., Peng, S., Wang, F., Blum, H., Barath, D., Geiger, A., Pollefeys, M.: Depth- splat: Connecting gaussian splatting and depth. In: IEEE/CVF Conference on OVBEVSeg 19 Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 16453–16463 (2025)
2025
-
[57]
In: CVPR (2023)
Yang,L.,Qi,L.,Feng,L.,Zhang,W.,Shi,Y.:Revisitingweak-to-strongconsistency in semi-supervised semantic segmentation. In: CVPR (2023)
2023
-
[58]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020
Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F., Madhavan, V., Darrell, T.: BDD100K: A diverse driving dataset for heterogeneous multitask learning. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. pp. 2633–2642 (2020)
2020
-
[59]
In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021
Zareian, A., Rosa, K.D., Hu, D.H., Chang, S.: Open-vocabulary object detection using captions. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. pp. 14393–14402 (2021)
2021
-
[60]
ISPRS Int
Zeng, Z., Boehm, J.: Exploration of an open vocabulary model on semantic seg- mentation for street scene imagery. ISPRS Int. J. Geo Inf.13(5), 153 (2024)
2024
-
[61]
In: Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part IX
Zhao,S.,Zhang,Z.,Schulter,S.,Zhao,L.,Kumar,B.G.V.,Stathopoulos,A.,Chan- draker, M., Metaxas, D.N.: Exploiting unlabeled data with vision and language models for object detection. In: Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part IX. vol. 13669, pp. 159–175 (2022)
2022
-
[62]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024
Zhao, T., Chen, Y., Wu, Y., Liu, T., Du, B., Xiao, P., Qiu, S., Yang, H., Li, G., Yang, Y., Lin, Y.: Improving bird’s eye view semantic segmentation by task decom- position. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 15512–15521 (2024)
2024
-
[63]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022
Zhou,B.,Krähenbühl,P.:Cross-viewtransformersforreal-timemap-viewsemantic segmentation. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 13750–13759 (2022)
2022
-
[64]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024
Zhou, H., Shao, J., Xu, L., Bai, D., Qiu, W., Liu, B., Wang, Y., Geiger, A., Liao, Y.: HUGS: holistic urban 3d scene understanding via gaussian splatting. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 21336–21345 (2024)
2024
-
[65]
In: IEEE/CVFConferenceonComputerVisionandPatternRecognition,CVPR2024, Seattle, WA, USA, June 16-22, 2024
Zhou, X., Lin, Z., Shan, X., Wang, Y., Sun, D., Yang, M.: Drivinggaussian: Com- posite gaussian splatting for surrounding dynamic autonomous driving scenes. In: IEEE/CVFConferenceonComputerVisionandPatternRecognition,CVPR2024, Seattle, WA, USA, June 16-22, 2024. pp. 21634–21643 (2024)
2024
-
[66]
Zhu, J., Liu, L., Tang, Y., Wen, F., Li, W., Liu, Y.: Semi-supervised learning for visual bird’s eye view semantic segmentation (2024)
2024
-
[67]
truck,” “bus,
Zou, J., Tian, K., Zhu, Z., Ye, Y., Wang, X.: Diffbev: Conditional diffusion model for bird’s eye view perception. In: Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.