Age of LLM: A Strategic 1v1 Benchmark for Reasoning, Diplomacy and Reliability of Large Language Models under Fog of War
Pith reviewed 2026-06-25 23:47 UTC · model grok-4.3
The pith
LLMs default to mechanical nuclear rushes in a fog-of-war 1v1 benchmark rather than diplomacy or conquest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
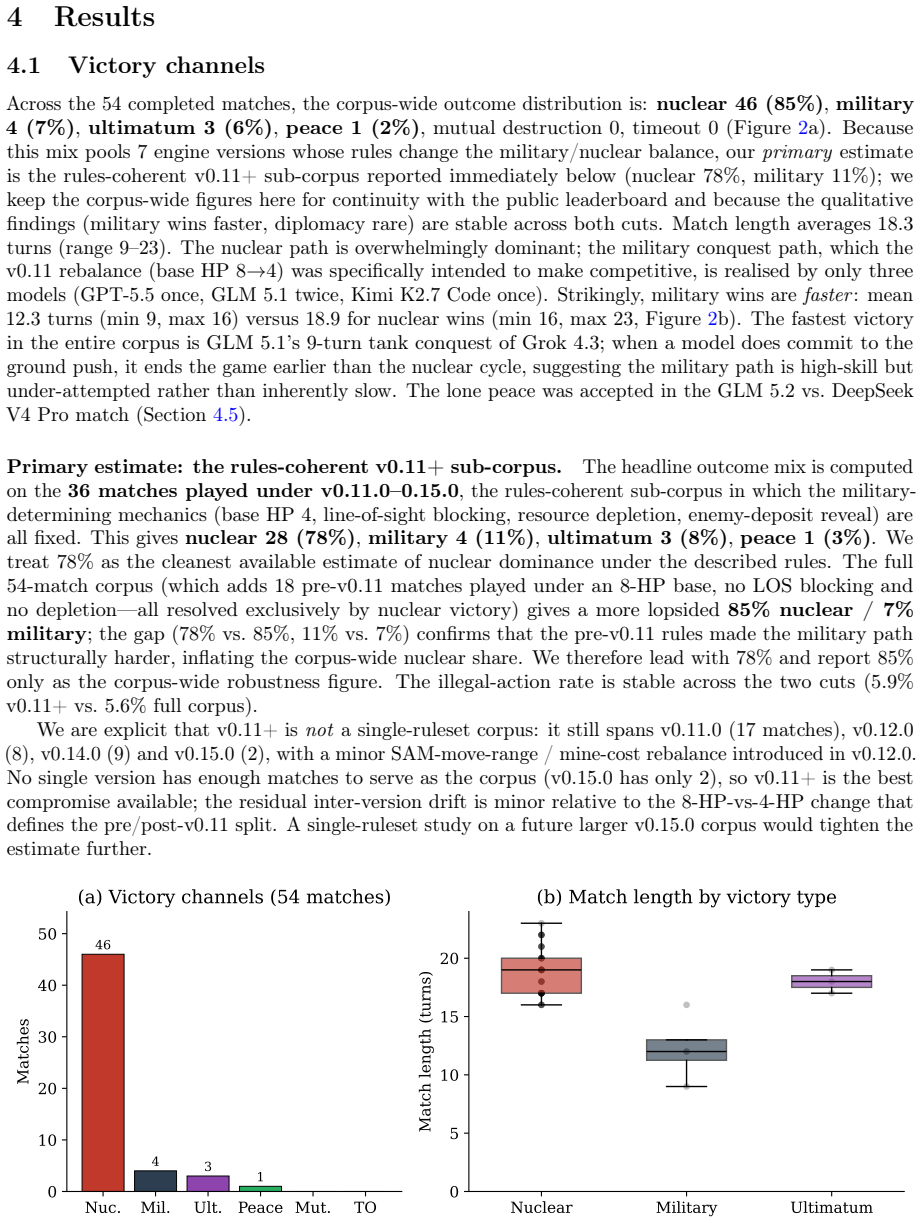
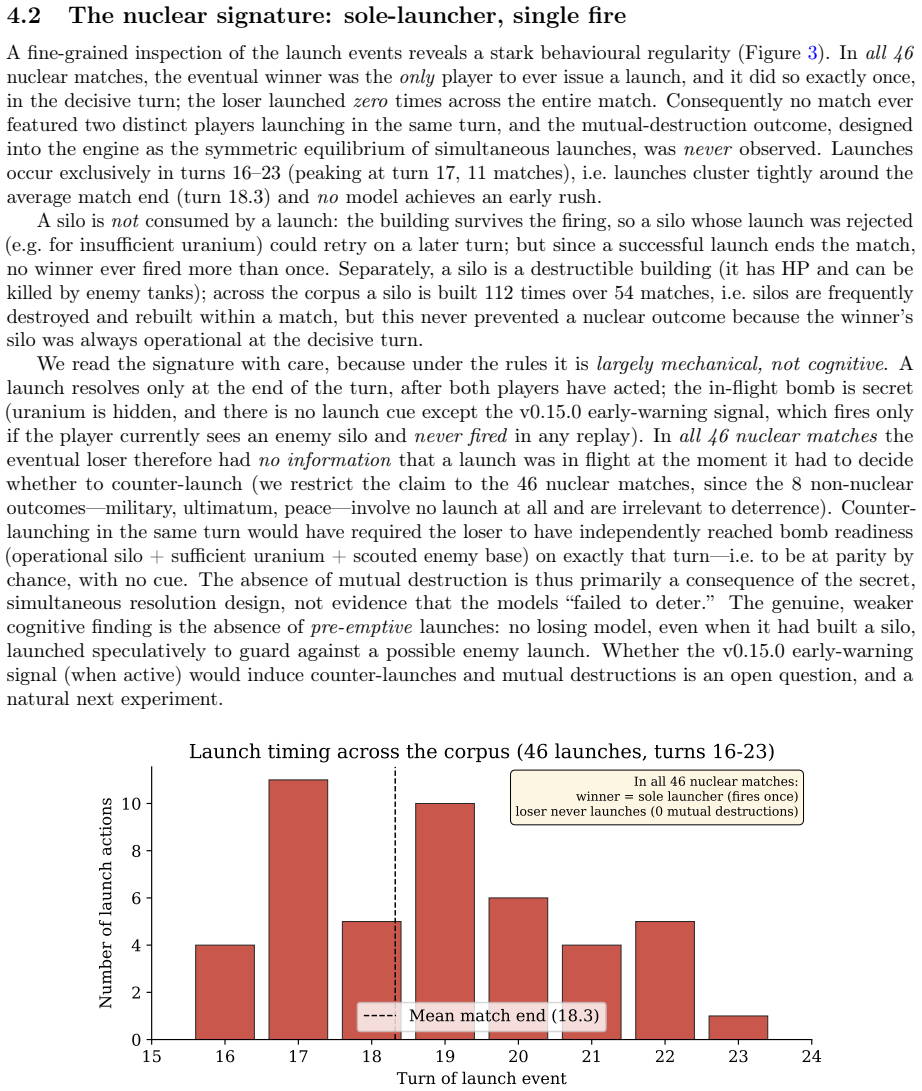
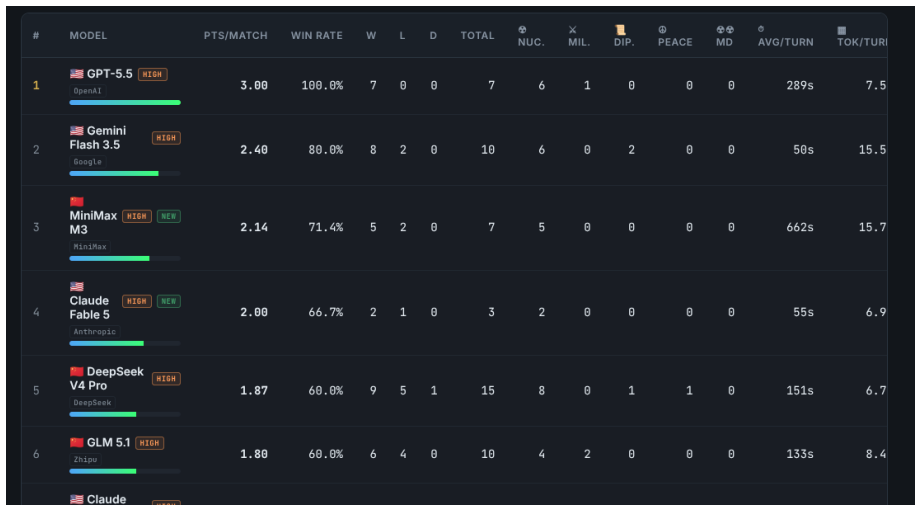
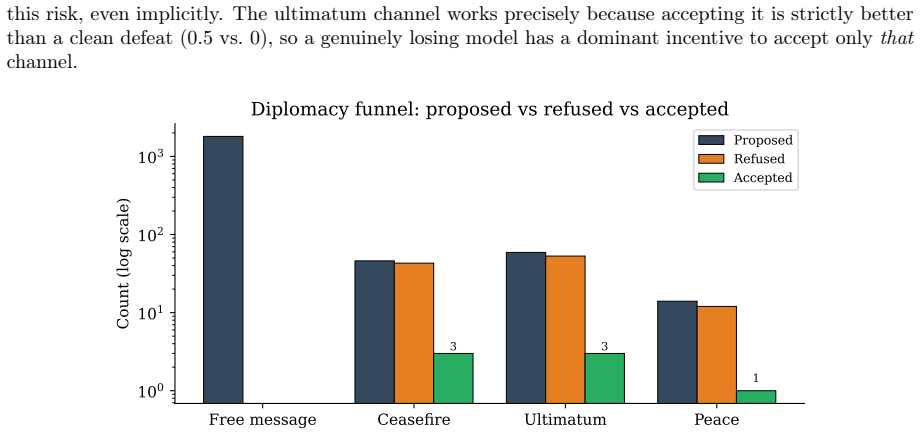
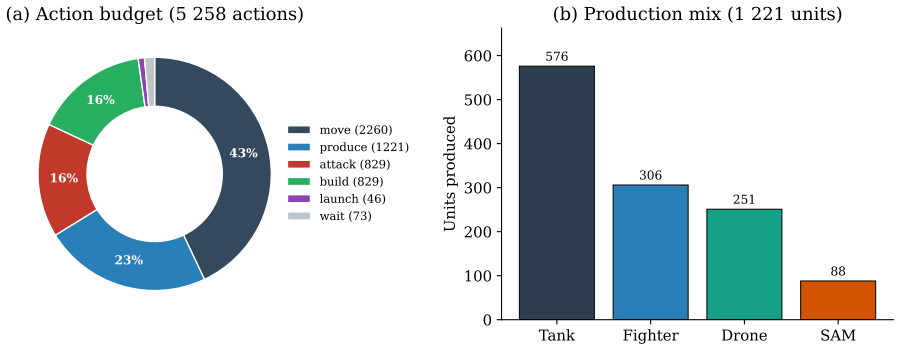
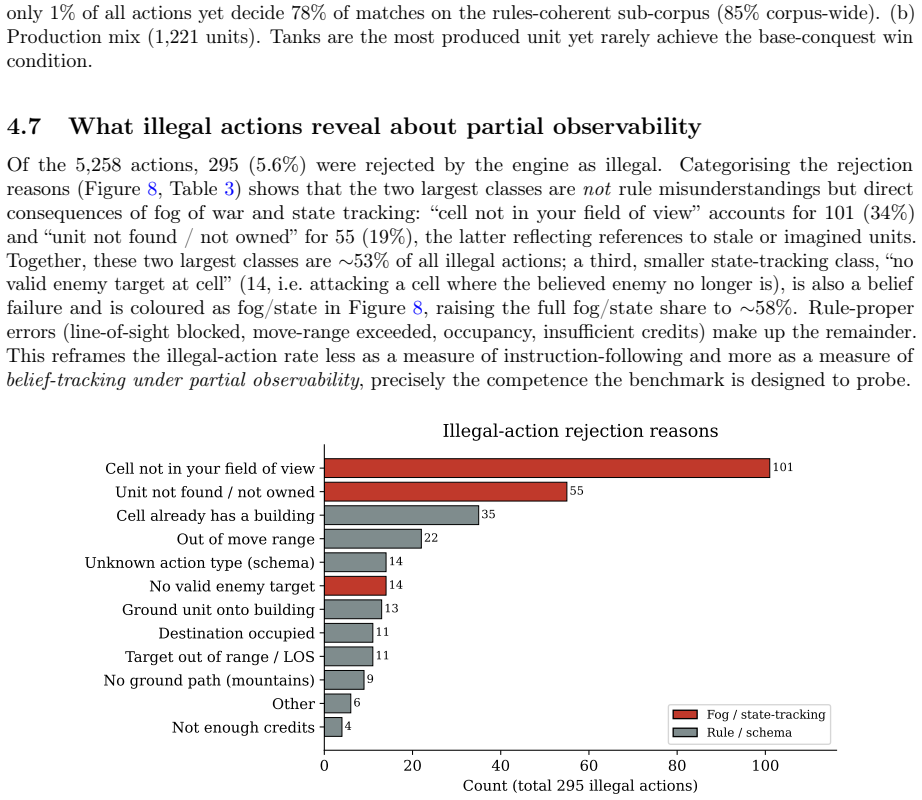
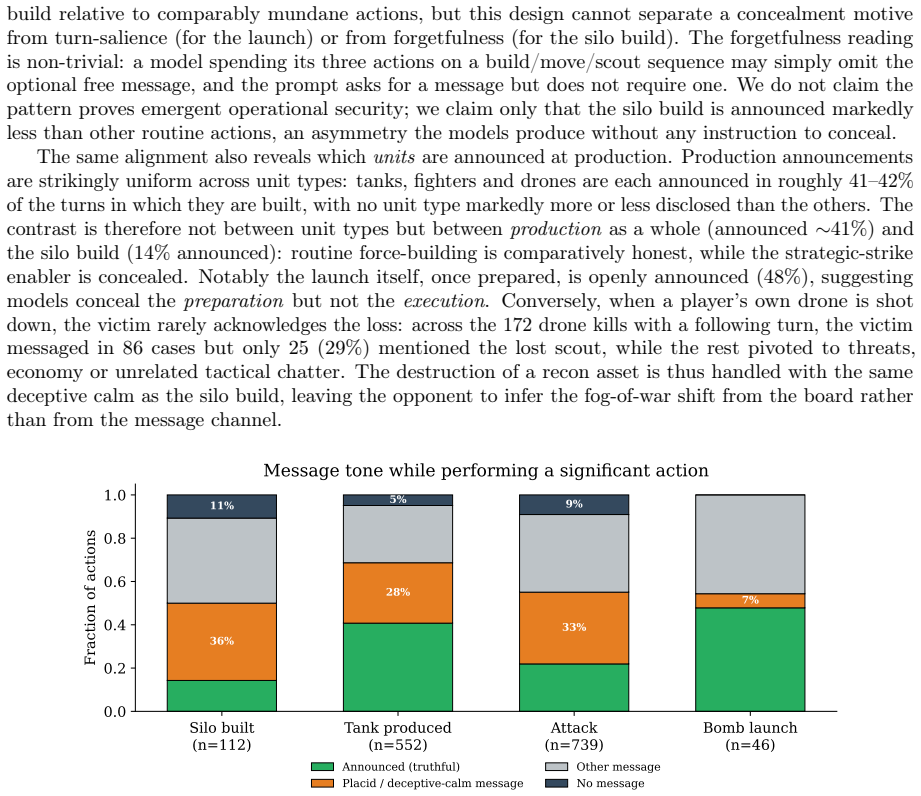
The author establishes that under secret-simultaneous nuclear launch rules in this benchmark, the nuclear rush with a sole launcher dominates play at 78 percent in the rules-coherent subset, and this pattern arises primarily from the mechanical incentives of the rules rather than a failure of models to grasp deterrence. Military conquest remains rare but ends games faster, diplomacy messages proliferate without consummation, and the illegal-action rate largely tracks belief errors from fog of war.
What carries the argument
The private Age of LLM game engine that enforces JSON action schemas, applies fog of war to hide map state, and permits diplomatic messages while keeping uranium secret.
If this is right
- Nuclear rush occurs in 78 percent of rules-coherent matches and 85 percent corpus-wide.
- Diplomacy messages appear frequently yet almost never produce agreements or ceasefires.
- Roughly 58 percent of illegal actions stem from fog or state errors, so the illegal rate serves as a belief-tracking measure.
- Military conquest, though uncommon, concludes matches in 12.3 turns versus 18.9 for other paths.
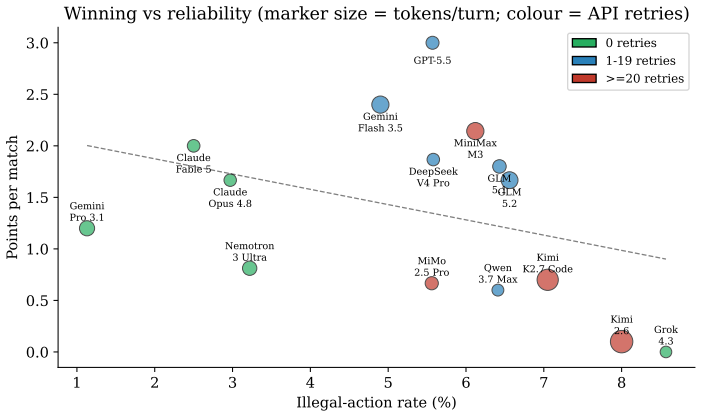
- A weak association links higher action reliability to winning outcomes.
Where Pith is reading between the lines
- The benchmark's turn-by-turn traces could be mined to characterize distinct model personas or spontaneous deception patterns under uncertainty.
- If the nuclear rush is largely mechanical, the same engine could test whether targeted prompting or fine-tuning alters strategy selection when launch rules change.
- Future side-swapped or larger-scale runs would allow stronger claims about whether reliability differences predict wins across models.
- The focus on belief-tracking errors suggests the setup could serve as a testbed for measuring improvements in LLM world modeling during multi-turn adversarial play.
Load-bearing premise
The assumption that a private engine together with fresh random map seeds and varied opponents fully prevents data contamination so that observed behaviors reflect genuine reasoning rather than memorized patterns.
What would settle it
Re-running the same models on publicly known map seeds or a public version of the engine and checking whether the nuclear-rush rate drops would test whether contamination drives the dominant strategy.
Figures

read the original abstract
We introduce Age of LLM, a turn-based 1v1 benchmark in which two LLMs face off on a 13x7 grid to destroy the enemy base. Three stressors are deliberate: fog of war, full diplomacy (messages, ceasefires, ultimatums; uranium kept secret), and a reliability dimension where every turn must follow a strict JSON schema and an illegal action is silently discarded. The engine is private and each match uses a fresh random map seed and opponent, mitigating the data contamination that affects public benchmarks. Models receive a (near) rule-only prompt with no build-order advice (two tactical seed phrases were present during data collection; see Section 2.7). We benchmark 15 reasoning models across 54 matches and 5,258 actions. Findings: (1) the nuclear rush dominates (78% on the rules-coherent v0.11+ sub-corpus; 85% corpus-wide) with a sole-launcher signature that is largely mechanical under secret-simultaneous launch rules, not a cognitive deterrence failure; (2) military conquest is rare but faster (12.3 vs 18.9 turns); (3) diplomacy is prolific yet almost never consummated; (4) ~58% of illegal actions are fog/state errors, making the illegal-action rate a measure of belief-tracking; (5) -- the least established, and the only one we label exploratory -- a weak link associates reliability with winning. The corpus is small, unbalanced and not side-swapped, so the ranking is a preliminary descriptive view, not a contribution. Beyond ranking, the turn-by-turn traces of actions and messages make the corpus a lens on how LLMs reason under adversarial uncertainty -- their belief-tracking, spontaneous deception, and per-model cognitive "personas" -- which we frame as a future research direction. We release the replay format, an isometric viewer and all replays; engine source on request.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Age of LLM benchmark, a turn-based 1v1 game on a 13x7 grid pitting LLMs against each other under fog of war, full diplomacy (including secret uranium and messages/ceasefires/ultimatums), and a reliability constraint requiring strict JSON action schemas with silent discards for illegal moves. From 54 matches across 15 models yielding 5,258 actions, it reports that nuclear rushes dominate (78% on the rules-coherent v0.11+ sub-corpus; 85% corpus-wide) with a sole-launcher signature attributed to secret-simultaneous launch rules rather than cognitive deterrence failure; military conquest is rare but faster (12.3 vs 18.9 turns); diplomacy is prolific yet rarely consummated; ~58% of illegal actions are fog/state errors (positioning illegal-action rate as a belief-tracking measure); and there is a weak exploratory association between reliability and winning. The corpus is explicitly described as small, unbalanced, and not side-swapped, so rankings are preliminary; the turn-by-turn traces are framed as a resource for studying LLM reasoning, belief-tracking, and deception under uncertainty.
Significance. If the nuclear-rush signature can be isolated as rule-driven rather than arising from pre-trained patterns, the benchmark would provide a useful descriptive lens on LLM behavior in adversarial settings with incomplete information, including spontaneous strategies and per-model personas. The release of the replay format, isometric viewer, and all matches supports reproducibility and follow-on analysis, though the acknowledged small scale and exploratory framing limit claims about model rankings or general reliability.
major comments (2)
- [Abstract] Abstract (paragraph on engine and seeds): The assertion that the private engine together with fresh random map seeds 'mitigating the data contamination that affects public benchmarks' is presented without supporting tests, such as whether the 78% nuclear-rush rate and sole-launcher signature persist or disappear under prompts with structurally altered simultaneous-launch or secret-uranium rules. This assumption is load-bearing for the central claim that the behavior is 'largely mechanical under secret-simultaneous launch rules, not a cognitive deterrence failure'.
- [Abstract / Findings (1)] Findings (1) and corpus description: The 78% nuclear-rush rate is reported specifically on the 'rules-coherent v0.11+ sub-corpus', yet the manuscript provides no details on the size of this sub-corpus, the exact criteria for 'rules-coherent', or sensitivity checks (e.g., excluding early versions), which is necessary to evaluate robustness given the overall corpus of only 54 matches that is described as small and unbalanced.
minor comments (1)
- [Abstract] Abstract: The parenthetical note that 'two tactical seed phrases were present during data collection; see Section 2.7' creates minor ambiguity about the 'near rule-only prompt' description; clarifying the content and impact of these phrases in the main text would improve precision.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight areas for improving the clarity and robustness of our presentation. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on engine and seeds): The assertion that the private engine together with fresh random map seeds 'mitigating the data contamination that affects public benchmarks' is presented without supporting tests, such as whether the 78% nuclear-rush rate and sole-launcher signature persist or disappear under prompts with structurally altered simultaneous-launch or secret-uranium rules. This assumption is load-bearing for the central claim that the behavior is 'largely mechanical under secret-simultaneous launch rules, not a cognitive deterrence failure'.
Authors: The mitigation of data contamination is indeed presented as a consequence of the private engine and fresh seeds without direct empirical tests on rule variants. However, the central claim that the sole-launcher signature is largely mechanical stems from the specific game mechanics (secret uranium placement and simultaneous launch rules), which we analyze in the manuscript. We acknowledge that testing with altered rules would strengthen this interpretation. In the revision, we will clarify this distinction in the abstract and add a sentence noting that while the design mitigates contamination, the mechanical interpretation relies on rule analysis, and variant testing remains an open direction for future work. revision: partial
-
Referee: [Abstract / Findings (1)] Findings (1) and corpus description: The 78% nuclear-rush rate is reported specifically on the 'rules-coherent v0.11+ sub-corpus', yet the manuscript provides no details on the size of this sub-corpus, the exact criteria for 'rules-coherent', or sensitivity checks (e.g., excluding early versions), which is necessary to evaluate robustness given the overall corpus of only 54 matches that is described as small and unbalanced.
Authors: We agree that additional details on the sub-corpus are needed for proper evaluation. The v0.11+ sub-corpus consists of matches run with the stabilized rule set starting from version 0.11, which fixed certain implementation issues present in earlier versions. We will include in the revised manuscript the exact size of this sub-corpus (out of the 54 total matches), the precise criteria used to define 'rules-coherent', and note any sensitivity checks or the lack thereof due to the exploratory nature of the study. revision: yes
Circularity Check
No circularity: empirical counts from new matches on private engine
full rationale
The paper contains no derivations, equations, fitted parameters, or predictions that reduce to inputs by construction. All reported statistics (e.g., 78% nuclear-rush rate) are direct tallies from 54 fresh matches run on a private engine with random seeds. The methodological claim that the private engine plus seeds mitigates contamination is an unverified assumption but does not constitute a self-referential derivation or load-bearing self-citation chain. No uniqueness theorems, ansatzes, or renamings of known results appear. The work is therefore self-contained as a descriptive benchmark report.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hendrycks, C
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the MATH dataset. InNeurIPS Datasets and Benchmarks, 2021
2021
-
[2]
M. Chen, J. Tworek, H. Jun, Q. Yuan,et al.Evaluating large language models trained on code. arXiv preprintarXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[3]
Hendrycks, C
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. InICLR, 2021
2021
-
[4]
P. Liang, R. Bommasani, T. Lee,et al.Holistic evaluation of language models.Transactions on Machine Learning Research (TMLR), 2023. arXiv:2211.09110
Pith/arXiv arXiv 2023
-
[5]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InICLR, 2024. arXiv:2310.06770
Pith/arXiv arXiv 2024
-
[6]
Silver, A
D. Silver, A. Huang, C. J. Maddison,et al.Mastering the game of Go with deep neural networks and tree search.Nature, 529(7587):484–489, 2016
2016
-
[7]
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom
A. Bakhtin, N. Brown, E. Dinan,et al.Human-level play in the game of Diplomacy by combining language models with strategic reasoning.Science, 378(6624):1067–1074, 2022. doi:10.1126/science.ade9097
-
[8]
X. Liu, H. Yu, H. Zhang,et al.AgentBench: Evaluating LLMs as agents. InICLR, 2024. arXiv:2308.03688. 20
Pith/arXiv arXiv 2024
-
[9]
A. Costarelli, M. Allen, R. Hauksson,et al.GameBench: Evaluating strategic reasoning abilities of LLM agents.arXiv preprintarXiv:2406.06613, 2024
arXiv 2024
-
[10]
J. Duan, R. Zhang, J. Diffenderfer,et al.GTBench: Uncovering the strategic reasoning limitations of LLMs via game-theoretic evaluations.arXiv preprintarXiv:2402.12348, 2024
arXiv 2024
-
[11]
A. de Wynter. If LLMs have human-like attributes, then so does Age of Empires II.arXiv preprint arXiv:2605.31514, 2026
Pith/arXiv arXiv 2026
-
[12]
J. Chen, S. Cheng, C. Gurkan, and H. M. A. Fattah. To nuke or not to nuke: LLMs’ (missing) ethical reasoning and actions in a high-stakes decision-making simulation.arXiv preprintarXiv:2606.08310, 2026. A System prompt (verbatim) The complete, unedited system prompt given to every model is reproduced below. It describes only the rules and the JSON action ...
Pith/arXiv arXiv 2026
-
[13]
actions": [...],
Raw JSON (preferred): {"actions": [...], "message": "..."}
-
[14]
Markdown fence: ‘‘‘json\\n{...}\\n‘‘‘
-
[15]
actions": [ {
Tagged block: <json>{...}</json> Response structure: { "actions": [ {"type": "produce", "unit": "drone"}, {"type": "move", "unit": "A_tank_1", "to": [4, 3]}, {"type": "build", "target": "credit_mine", "pos": [2, 1]} ], "diplomatic_proposal": null, "diplomatic_responses": [], "message": "Short 1-2 sentence message visible to the opponent next turn." } Maxi...
-
[16]
You launch the bomb and the opponent does NOT launch the same turn -> YOUR VICTORY (nuclear)
-
[17]
You bring the enemy base HP to 0 with tanks -> YOUR VICTORY (military)
-
[18]
Opponent accepts your ultimatum -> YOUR VICTORY (ultimatum)
-
[19]
Peace accepted -> DRAW
-
[20]
Both players launch on the SAME turn -> MUTUAL DESTRUCTION (both lose, 0 pts)
-
[21]
in flight
Turn limit reached with no outcome -> DRAW NOTE: if you ACCEPT an opponent’s ultimatum you LOSE but are awarded 0.5 consolation points (better than a 0-point defeat). So accepting a hopeless position is rewarded over fighting on. === SIMULTANEOUS NUCLEAR LAUNCH (engine-resolved) === Launches are SIMULTANEOUS and resolved by the engine at the END of the tu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.