Reward-Conditioned Attention: How Reward Design Shapes What Autonomous Driving Agents See
Pith reviewed 2026-06-25 23:55 UTC · model grok-4.3
The pith
Reward design directly determines which scene elements autonomous driving agents prioritize in their attention mechanisms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
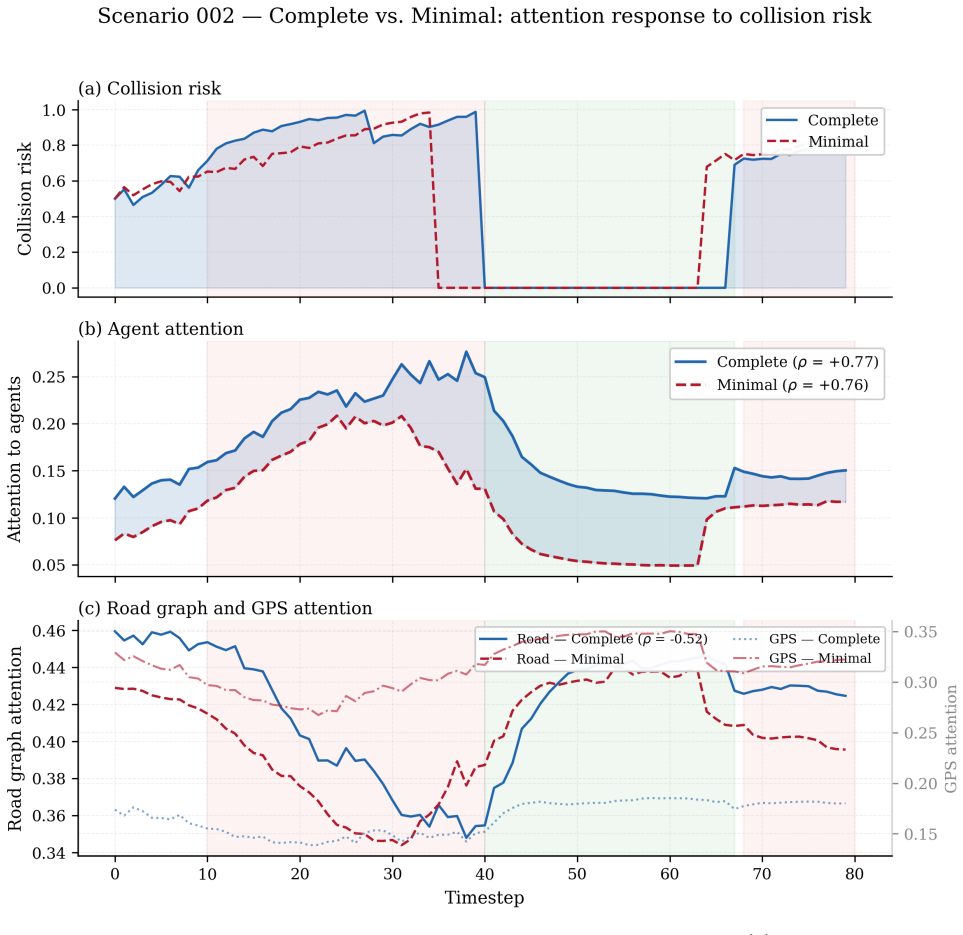
Reward content directly determines which scene elements the encoder prioritizes, and continuous time-to-collision penalties create a learned vigilance prior—elevated resting agent surveillance maintained throughout collision-free phases. In several scenarios, the complete-reward and minimal-reward models exhibit opposite attention–risk correlation directions, demonstrating that reward design can qualitatively reverse attentional strategy rather than merely modulating its magnitude.
What carries the argument
Reward-conditioned cross-attention allocation in the Perceiver encoder, which shifts focus among scene tokens according to the reward terms present during training.
If this is right
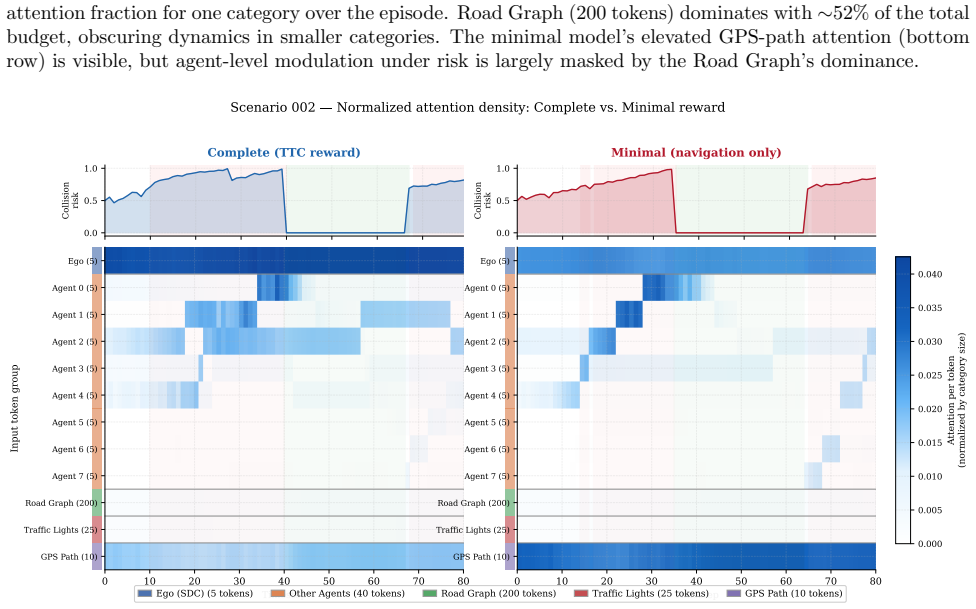
- Agents trained with navigation rewards allocate up to 2.0 times more attention to GPS-path tokens than agents with added proximity penalties.
- Continuous time-to-collision penalties produce elevated baseline surveillance that persists through collision-free periods.
- Complete-reward and minimal-reward agents can display opposite directions of attention-risk correlation in the same scenarios.
- Within-episode correlation combined with Fisher z-transform aggregation is required to detect the true attention-risk relationship.
- Attention analysis functions as a diagnostic tool to confirm that a chosen reward produces the intended representational behavior.
Where Pith is reading between the lines
- Designers could deliberately engineer rewards to create specific perceptual priorities in other reinforcement-learning domains beyond driving.
- The reversal effect suggests testing whether attention patterns can be tuned to suppress or amplify focus on particular hazard types.
- One could check whether the vigilance prior persists when the same reward structure is applied to non-driving control tasks.
- Hybrid reward schedules might be explored to achieve balanced attention between navigation and constant risk monitoring.
Load-bearing premise
All observed differences in attention can be credited to the reward configurations alone because the three agents share identical architectures, training data, and optimization details.
What would settle it
Retraining the three agents after swapping their reward functions and finding that the attention patterns do not swap accordingly.
Figures




read the original abstract
We investigate how reward design shapes the internal attention patterns of reinforcement learning agents trained for autonomous driving. Using three Perceiver-based agents that share identical architectures and training data but differ only in their reward configurations$\unicode{x2014}$ranging from basic violation penalties to continuous proximity penalties$\unicode{x2014}$we analyze cross-attention allocation across 50 real-world scenarios from the Waymo Open Motion Dataset. A central methodological finding is that na\"ive pooling of timesteps across episodes substantially underestimates the attention$\unicode{x2013}$risk relationship; within-episode correlation with Fisher z-transform aggregation is the appropriate statistic and reveals a robustly positive link between collision risk and agent-directed attention. Building on this validated methodology, we demonstrate two reward-conditioned effects: agents trained with navigation rewards allocate up to $2.0\times$ more attention to GPS-path tokens than those trained with additional proximity penalties$\unicode{x2014}$and $4.7\times$ more than agents with no navigation incentive$\unicode{x2014}$revealing that reward content directly determines which scene elements the encoder prioritizes, and continuous time-to-collision penalties create a $\textit{learned vigilance prior}$$\unicode{x2014}$elevated resting agent surveillance maintained throughout collision-free phases. In several scenarios, the complete-reward and minimal-reward models exhibit opposite attention$\unicode{x2013}$risk correlation directions, demonstrating that reward design can qualitatively reverse attentional strategy rather than merely modulating its magnitude. These results suggest that attention analysis is a practical diagnostic for verifying that a reward function produces the intended representational behaviour in safety-critical RL systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates how reward design influences internal attention patterns in reinforcement learning agents for autonomous driving. It trains three Perceiver-based agents on the Waymo Open Motion Dataset that share identical architectures and data but use different reward configurations (basic violation penalties, continuous proximity penalties, and navigation incentives). The authors report that reward content determines attention allocation to scene elements (e.g., up to 2.0× and 4.7× differences in GPS-path token attention), that continuous time-to-collision penalties induce a 'learned vigilance prior' with elevated surveillance in collision-free phases, and that complete-reward versus minimal-reward agents can exhibit opposite attention-risk correlation directions. They also claim that within-episode Fisher z-transform aggregation is required to correctly measure attention-risk relationships, as naive timestep pooling underestimates them.
Significance. If the attribution of attention differences to reward design holds after controlling for training stochasticity, the work is significant for safety-critical RL: it shows reward functions can qualitatively reverse representational strategies rather than merely scaling them, and positions attention analysis as a practical diagnostic for verifying intended agent behavior. The methodological point on correlation aggregation is a useful secondary contribution for similar empirical studies.
major comments (1)
- [Abstract / experimental setup] Abstract / experimental setup description: The central claim requires that all reported attention differences (including qualitative reversals in attention-risk correlations and the learned vigilance prior) are caused by reward configurations rather than training stochasticity. The setup asserts identical architectures, data, and optimization except for rewards, but provides no indication of multiple independent seeds, run averaging, or determinism controls. In RL, single trajectories per condition can produce divergent internal representations due to exploration and optimization noise, so the qualitative effects cannot be confidently attributed to reward content alone.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of distinguishing reward-induced effects from training stochasticity in our experimental design. This is a substantive concern for RL studies, and we address it directly below.
read point-by-point responses
-
Referee: [Abstract / experimental setup] Abstract / experimental setup description: The central claim requires that all reported attention differences (including qualitative reversals in attention-risk correlations and the learned vigilance prior) are caused by reward configurations rather than training stochasticity. The setup asserts identical architectures, data, and optimization except for rewards, but provides no indication of multiple independent seeds, run averaging, or determinism controls. In RL, single trajectories per condition can produce divergent internal representations due to exploration and optimization noise, so the qualitative effects cannot be confidently attributed to reward content alone.
Authors: We agree that the absence of multiple independent seeds is a limitation that weakens the attribution of attention differences solely to reward design. The manuscript describes three agents trained with identical architectures, data, and optimization hyperparameters except for the reward functions, but reports results from single training runs per condition without explicit mention of seed averaging or determinism controls. While the observed differences are large (up to 4.7× in attention allocation) and directionally consistent across 50 scenarios, this does not fully rule out stochastic effects. In the revised manuscript we will (1) explicitly state that results are from single runs, (2) add a limitations paragraph acknowledging that multiple seeds would be required for stronger causal claims, and (3) if compute permits, include a small-scale multi-seed verification for the most striking qualitative reversal. We do not claim the current evidence is conclusive on this point. revision: partial
Circularity Check
No significant circularity; empirical observations from controlled model comparisons.
full rationale
The paper reports empirical results from training three Perceiver-based RL agents that differ only in reward configurations, then measuring attention allocation on Waymo scenarios. No equations, predictions, or first-principles derivations are presented that reduce by construction to fitted inputs, self-citations, or renamed known results. The methodology (within-episode Fisher z-transform correlation) is described as validated but does not make the observed attention differences (e.g., 2.0× or 4.7× multipliers, opposite correlation directions) tautological with the reward definitions. All load-bearing claims rest on direct experimental contrasts rather than any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Three Perceiver-based agents share identical architectures and training data but differ only in reward configurations
invented entities (1)
-
learned vigilance prior
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Reinforcement Learning Journal , year=
Charraut, Valentin and Doulazmi, Wa. Reinforcement Learning Journal , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[3]
Proceedings of the 38th International Conference on Machine Learning , pages=
Perceiver: General Perception with Iterative Attention , author=. Proceedings of the 38th International Conference on Machine Learning , pages=. 2021 , publisher=
2021
-
[4]
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Attention is not Explanation , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=. 2019 , publisher=
2019
-
[5]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing , pages=
Attention is not not Explanation , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing , pages=. 2019 , publisher=
2019
-
[6]
Advances in Neural Information Processing Systems , volume=
Attention is All you Need , author=. Advances in Neural Information Processing Systems , volume=. 2017 , url=
2017
-
[7]
Proceedings of the 35th International Conference on Machine Learning , pages=
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author=. Proceedings of the 35th International Conference on Machine Learning , pages=. 2018 , publisher=
2018
-
[8]
International Conference on Learning Representations , year=
Explain Your Move: Understanding Agent Actions Using Specific and Relevant Feature Attribution , author=. International Conference on Learning Representations , year=
-
[9]
Visualizing and Understanding
Greydanus, Samuel and Koul, Anurag and Dodge, Jonathan and Fern, Alan , booktitle=. Visualizing and Understanding. 2018 , publisher=
2018
-
[10]
IEEE Transactions on Intelligent Transportation Systems , volume=
Deep Reinforcement Learning for Autonomous Driving: A Survey , author=. IEEE Transactions on Intelligent Transportation Systems , volume=. 2022 , url=
2022
-
[11]
and Zhou, Yin and Yang, Zoey and Chouard, Aur
Ettinger, Scott and Cheng, Shuyang and Caine, Benjamin and Liu, Chenxi and Zhao, Hang and Pradhan, Sabeek and Chai, Yuning and Sapp, Ben and Qi, Charles R. and Zhou, Yin and Yang, Zoey and Chouard, Aur. Large Scale Interactive Motion Forecasting for Autonomous Driving: The. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=. ...
2021
-
[12]
2023 IEEE International Conference on Robotics and Automation , pages=
Wayformer: Motion Forecasting via Simple & Efficient Attention Networks , author=. 2023 IEEE International Conference on Robotics and Automation , pages=. 2023 , url=
2023
-
[13]
2024 , url=
Shi, Shaoshuai and Jiang, Li and Dai, Dengxin and Schiele, Bernt , journal=. 2024 , url=
2024
-
[14]
Proceedings of the 34th International Conference on Machine Learning , pages=
Axiomatic Attribution for Deep Networks , author=. Proceedings of the 34th International Conference on Machine Learning , pages=. 2017 , publisher=
2017
-
[15]
PLoS ONE , volume=
On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation , author=. PLoS ONE , volume=. 2015 , url=
2015
-
[16]
2023 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Imitation Is Not Enough: Robustifying Imitation with Reinforcement Learning for Challenging Driving Scenarios , author=. 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2023 , url=
2023
-
[17]
Proceedings of The 7th Conference on Robot Learning , pages=
Parting with Misconceptions about Learning-based Vehicle Motion Planning , author=. Proceedings of The 7th Conference on Robot Learning , pages=. 2023 , publisher=
2023
-
[18]
2018 , publisher=
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
2018
-
[19]
Metron , volume=
On the ``Probable Error'' of a Coefficient of Correlation Deduced from a Small Sample , author=. Metron , volume=. 1921 , url=
1921
-
[20]
2022 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Hierarchical Model-Based Imitation Learning for Planning in Autonomous Driving , author=. 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2022 , url=
2022
-
[21]
Towards Learning-Based Planning: The
Karnchanachari, Napat and Geromichalos, Dimitris and Tan, Kok Seang and Li, Nanxiang and Eriksen, Christopher and Yaghoubi, Shakiba and Mehdipour, Noushin and Bernasconi, Gianmarco and Fong, Whye Kit and Guo, Yiluan and Caesar, Holger , booktitle=. Towards Learning-Based Planning: The. 2024 , url=
2024
-
[22]
arXiv preprint arXiv:2502.03349 , year=
Robust Autonomy Emerges from Self-Play , author=. arXiv preprint arXiv:2502.03349 , year=
-
[23]
Bradbury, James and Frostig, Roy and Hawkins, Peter and Johnson, Matthew James and Leary, Chris and Maclaurin, Dougal and Necula, George and Paszke, Adam and VanderPlas, Jake and Wanderman-Milne, Skye and Zhang, Qiao , year=
-
[24]
AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society , year=
Transparency and Explanation in Deep Reinforcement Learning Neural Networks , author=. AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society , year=
-
[25]
International Conference on Learning Representations , year=
Exploratory Not Explanatory: Counterfactual Analysis of Saliency Maps for Deep Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[26]
2025 International Conference on Intelligent Robots and Systems (IROS) , publisher=
Grislain, Cl. 2025 International Conference on Intelligent Robots and Systems (IROS) , publisher=. 2025 , url=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.